一、从用户态开始:open()
在 Linux 用户空间中,open() 是最基础也是最频繁使用的系统调用之一。几乎所有程序都会通过 open() 打开文件,例如读取配置文件、写日志、加载动态库、访问设备节点等。对于应用开发者而言,open() 只是一个简单的 API 调用,但在操作系统内部,这个调用会触发一整套复杂的文件访问流程。
Linux 采用 用户态(User Space)与内核态(Kernel Space)隔离的设计。应用程序无法直接访问文件系统或设备,而必须通过系统调用接口进入内核,由内核完成资源管理和安全控制。因此,open() 本质上是一个 用户态到内核态的入口。
在 glibc 中,open() 实际上并不是一个真正的系统调用,而只是一个封装函数。现代 Linux 内核已经将 open() 统一为 openat() 系统调用,这样做的原因是为了支持 相对目录文件描述符(dirfd) 的路径解析机制,从而提升安全性和灵活性。例如,容器运行时或沙箱环境可以通过 openat() 限制进程只能访问某个目录树。
因此,当应用程序执行 open() 时,真正发生的事情是:
glibc 封装函数被调用
glibc 转换为 openat() 系统调用
通过 syscall 指令进入内核
这只是整个文件打开流程的第一步。
二、系统调用入口
系统调用是 Linux 内核向用户空间提供服务的主要方式。应用程序无法直接执行内核代码,而是必须通过系统调用接口进入内核。对于 open() 而言,这个入口就是 openat() 系统调用。
在 x86_64 架构上,系统调用通常通过 syscall 指令触发。执行 syscall 后,CPU 会切换到内核态,并跳转到内核预定义的系统调用入口地址。内核随后根据系统调用号(syscall number)查找对应的处理函数。
Linux 内核中所有系统调用都有统一的入口处理流程。首先,内核会保存当前寄存器状态,然后从系统调用表(sys_call_table)中查找对应的函数。例如 openat 的系统调用号在 x86_64 上通常是 257。系统调用表会将该编号映射到 __x64_sys_openat 函数。
在进入真正的文件打开逻辑之前,内核还会执行一些通用检查,例如:
验证用户态指针是否合法
检查系统调用参数
记录审计信息(audit subsystem)
处理 seccomp 安全策略
这些检查的存在是为了确保用户程序无法通过恶意参数破坏内核稳定性。
完成这些准备工作之后,系统调用流程才会进入文件系统相关逻辑,即 do_sys_open() 函数。
三、open() 整体调用流程
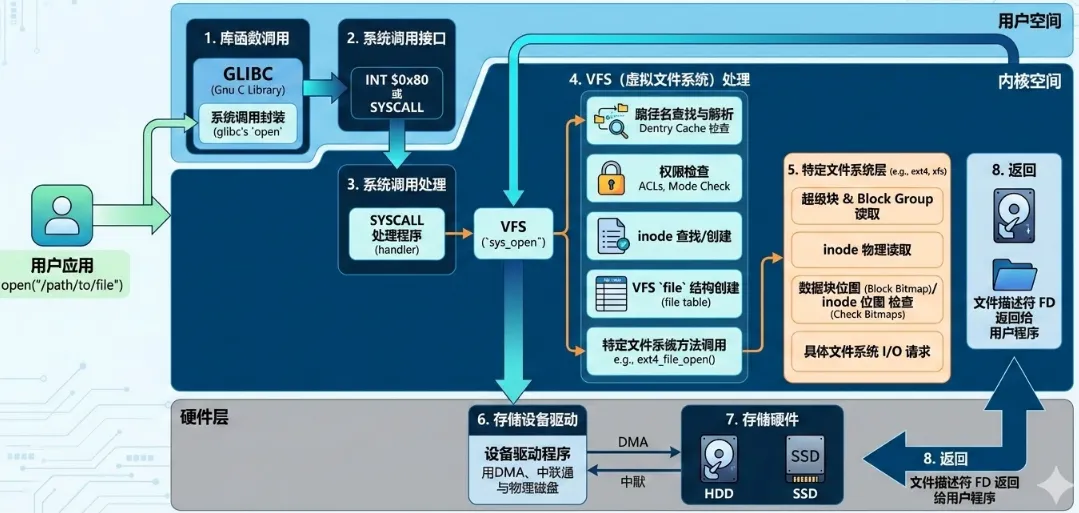
从宏观角度看,一次 open() 调用会穿越 Linux 内核多个核心子系统,包括文件描述符管理、VFS(虚拟文件系统)、路径解析、缓存系统以及具体文件系统实现。整个调用链涉及几十个函数,因此理解整体架构比单纯阅读源码更重要。
Linux 文件访问架构采用 VFS(Virtual File System)抽象层。VFS 的核心思想是:为所有文件系统提供统一接口,使得 ext4、xfs、btrfs、NFS 等文件系统能够在同一套 API 下工作。应用程序调用 open() 时,并不知道底层使用的是哪种文件系统,而 VFS 会负责将操作分发给对应的文件系统驱动。
open() 的整体流程大致可以分为几个阶段:
分配文件描述符(fd)
创建 struct file 对象
解析路径(path lookup)
查找 dentry(目录项缓存)
获取 inode(文件元数据)
权限检查
调用具体文件系统 open 方法
其中最复杂的部分是 路径解析和 dentry 查找。Linux 为了提高性能,引入了多层缓存机制,例如 dentry cache 和 inode cache,这使得大量 open() 调用可以在不访问磁盘的情况下完成。
因此,从系统架构角度来看,open() 实际上是 Linux 文件系统访问流程的核心入口。
四、fd 是如何分配的
在 Linux 中,文件描述符(File Descriptor,fd)是用户程序访问文件的主要句柄。应用程序并不会直接操作内核中的 file 结构,而是通过一个整数类型的 fd 与内核对象建立关联。
每个进程都有一个独立的文件描述符表。这个表存储在 task_struct 中的 files_struct 结构里。files_struct 内部又维护了一个 fdtable,用于保存所有打开文件的指针。
当进程调用 open() 时,内核首先需要在 fdtable 中找到一个空闲位置。这个过程由 get_unused_fd_flags() 完成。Linux 会从最小可用 fd 开始搜索,一般情况下返回值是 3 或更大的整数,因为:
0 → stdin
1 → stdout
2 → stderr
如果当前 fdtable 已满,内核还会动态扩展 fdtable。Linux 的 fdtable 设计采用 可扩展数组 + 位图管理 的方式,这样既能支持大量文件描述符,又能保持查找效率。
需要注意的是,fd 只是一个索引值,它本身并不包含任何文件信息。真正的文件状态存储在 struct file 结构中。fdtable 只是将 fd 映射到对应的 file 对象。
这种设计的优点是:
用户空间接口简单
内核对象可复用
支持 fork 继承文件描述符
五、file 结构体创建
在 Linux 内核中,真正表示“一个打开文件实例”的对象是 struct file。每次成功执行 open(),内核都会创建一个新的 file 结构体,并将其与文件描述符关联。
需要注意的是:file 并不代表文件本身,而是一次“打开行为”。
举个例子:
两个进程同时 open 同一个文件
会产生:两个 file,一个 inode
file 结构体记录了与文件访问相关的运行时状态,例如:
当前文件偏移(f_pos)
打开标志(O_RDONLY / O_RDWR)
文件操作函数(file_operations)
关联的 dentry 和 inode
这种设计使得 Linux 可以支持:
多个进程同时访问同一文件
同一文件不同偏移读写
独立的文件访问权限
此外,file 结构还维护引用计数。当多个 fd 指向同一个 file(例如 dup() 调用)时,引用计数会增加。只有当引用计数降为 0 时,内核才会释放该对象。
六、路径解析(最复杂部分)
路径解析是 open() 调用中最复杂的环节之一。Linux 需要将用户提供的路径字符串转换为内核中的对象,例如 dentry 和 inode。这个过程被称为 Path Resolution。
路径解析的核心函数是 link_path_walk()。它会逐级解析路径中的每一个组件。例如路径:/home/user/file.txt
内核需要执行以下步骤:
找到根目录 /
在 / 下查找 home
在 home 下查找 user
在 user 下查找 file.txt
每一级查找都可能涉及缓存查找或文件系统访问。为了提升性能,Linux 引入了 dcache(目录项缓存)。如果路径组件已经存在于 dcache 中,内核可以直接获取对应对象,而无需访问磁盘。
此外,路径解析还需要处理多种特殊情况,例如:
符号链接(symbolic link)
. 当前目录
.. 父目录
mount point(挂载点)
Linux 通过复杂的状态机来处理这些情况,以保证路径解析既正确又高效。
七、dcache:路径缓存
为了避免每次 open() 都访问磁盘,Linux 在 VFS 层实现了一个非常重要的缓存系统:dentry cache(dcache)。dcache 的作用是缓存目录项,从而加速路径解析。
在传统文件系统中,查找文件通常需要读取目录文件,然后在目录项列表中搜索目标文件名。这种方式在目录很大时效率很低。dcache 通过在内存中维护一棵目录树,使得文件查找可以直接在内存中完成。
每个 dentry 结构体表示一个目录项,它包含:
dcache 的结构类似于一棵树:
/ └── home └── user └── file.txt
当 open() 调用发生时,内核首先在 dcache 中查找路径。如果命中缓存,则无需访问磁盘。只有当缓存未命中时,内核才会调用底层文件系统进行查找。
dcache 还实现了 LRU 回收机制,当系统内存不足时,内核会回收不常使用的目录项。
八、inode 获取
inode 是 Linux 文件系统中最核心的数据结构之一。每个文件在磁盘上都有一个唯一的 inode,用于存储文件的元数据,例如:
当 VFS 解析路径并找到对应的 dentry 后,下一步就是获取该文件的 inode。通常情况下,inode 会从 inode cache 中获取。如果缓存中不存在,内核就需要从磁盘读取 inode 信息。
inode 本身并不包含文件名。文件名存储在目录项中,而 inode 表示文件实体。这也是为什么 Linux 支持 硬链接(hard link):多个目录项可以指向同一个 inode。
inode 结构中还包含一组函数指针,例如 inode_operations。这些函数定义了文件系统特定的操作,例如创建文件、删除文件、重命名等。
九、权限检查
在成功找到 inode 之后,内核必须执行权限检查。Linux 文件系统采用经典的 Unix 权限模型,每个文件都有三个权限集合:
owner(文件所有者)
group(所属组)
others(其他用户)
每个集合包含三种权限:
read (r)write (w)exec (x)
当进程调用 open() 时,内核会根据当前进程的 UID 和 GID 判断是否具有访问权限。这个检查由 inode_permission() 完成。
此外,Linux 还支持更复杂的权限控制机制,例如:
这些安全模块通过 LSM(Linux Security Module)框架 插入到权限检查流程中,从而实现更细粒度的安全策略
 10个月宝宝每天需要喝多少奶粉?
10个月宝宝每天需要喝多少奶粉?
