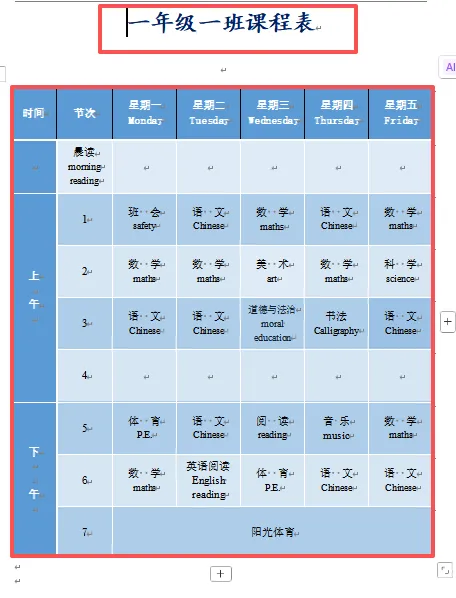
其实,这样的场景太熟悉不过了。为了验证这个问题,特意复现了一位读者的问题:从几十个Word文档的班级课表中提取数据,汇总到一个Excel表格中。有一个Word文档,一页为一个班级的课程表,标题为“某年级某班课程表”。需要提取每个班级、每个节次的课程名称,然后把这些信息按固定格式汇总到Excel里,每个班级占一行,节次课程按列排列。from docx import Documentfrom collections import defaultdictimport times_t = time.time()docx_path = r"E:\2025-2026学年班级课程表(2).docx"doc = Document(docx_path)banji = [p.text.strip() for p in doc.paragraphs if "课程表" in p.text]dict_bj = defaultdict(lambda : defaultdict(dict))for index,table in enumerate(doc.tables): bj = banji[index] for r in range(2,9): jieci = table.cell(r,1).text for c in range(2,7): xingqi = table.cell(0,c).text dict_bj[bj][jieci][xingqi] = table.cell(r,c).textprint(f"用时{time.time()-s_t}") # 用时7.632585763931274
仅从74个Word表格中提取数据,到字典,用时竟超7秒。这种代码为什么会这么低效?经过一番比对和测试,原因如下:一是table.cell的调用。在docx库中调用table.cell需要访问底层的XML节点,是相对耗时的操作。优化方式:一次性获取整行所有的cell对象,后续直接通过索引访问。二是defaultdict(lambda : defaultdict(dict))嵌套字典的创建。每次访问时都要动态创建子字典,额外增加消耗。优化方式:可以通过普通字典直接赋值,减少动态创建。三是dict_bj[bj][jieci][xingqi]字典层级的动态访问。dict_bj[bj][jieci][xingqi]三级字典需要三次字典查找。优化方式:直接赋值,仅一次字典查找。四是doc.tables表格遍历的无效筛选。全量遍历会做大量无效运算,可以通过切片形式,避免遍历多余的表格,减少无效循环。from docx import Documentfrom openpyxl import load_workbookimport times_t = time.time()doc = Document(r"E:\2025-2026学年班级课程表(2).docx")banji = [p.text.strip().replace("课程表","") for p in doc.paragraphs if"课程表"in p.text]tables = doc.tables[:len(banji)]dict_kebiao = {}for idx, table inenumerate(tables): bj = banji[idx] dict_kebiao[bj] = bj_dict = {} for c inrange(2, 7): col_cells = table.column_cells(c) jieci = col_cells[0].text.strip() kecheng = [col_cells[r].text.strip() for r inrange(1, 9)] bj_dict[jieci] = kechengprint(f"用时{time.time()-s_t}")
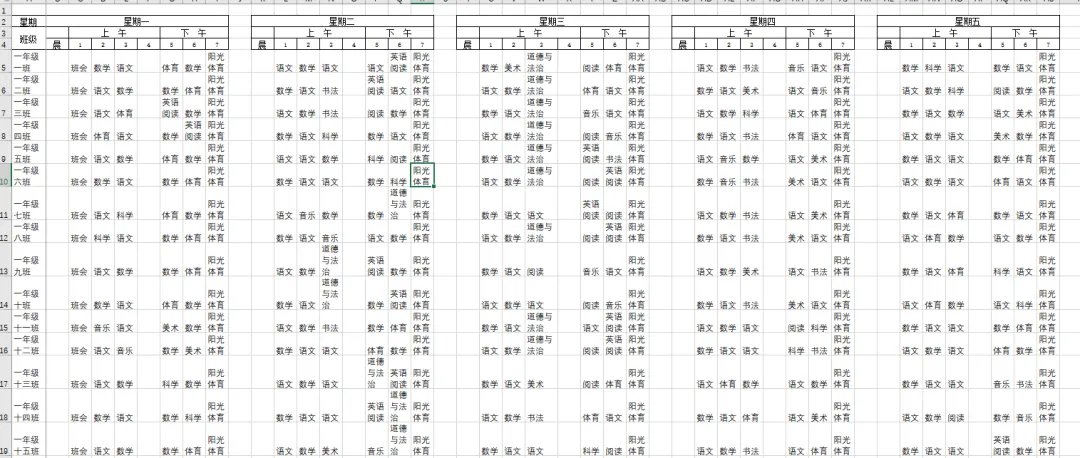
运行代码,用时仅1秒钟,性能提升约6.63倍,效果非常明显。from docx import Documentfrom openpyxl import load_workbookimport timeimport res_t = time.time()doc = Document(r"E:\2025-2026学年班级课程表(2).docx")banji = [p.text.strip().replace("课程表","") for p in doc.paragraphs if "课程表" in p.text]tables = doc.tables[:len(banji)]dict_kebiao = {}for idx, table in enumerate(tables): bj = banji[idx] dict_kebiao[bj] = bj_dict = {} for c in range(2, 7): col_cells = table.column_cells(c) jieci = col_cells[0].text.strip() kecheng = [col_cells[r].text.strip() for r in range(1, 9)] bj_dict[jieci] = kechengwb = load_workbook(r"E:2022-2023学年玉兰街校区总课表.xlsx")ws = wb.activeinput_row = 5input_col = 2for bj,value_ke in dict_kebiao.items(): ws.cell(input_row,1).value = bj k = 0 for week_num,value in enumerate(value_ke.values()): for jie,ke in enumerate(value): if match := re.search(r"[\u4e00-\u9fff ]+",ke.replace(" ","")): kc = match.group() else: kc = ke ws.cell(input_row,input_col+jie+week_num*7+k).value = kc k += 2 input_row += 1wb.save(r"E:\2022-2023学年玉兰街校区总课表_汇总.xlsx")print(f"用时{time.time()-s_t}")
办公自动化就是在资源有限的情况下,寻找最优的解决过程,也许就是短短的几个字符,就能提高解决问题的效率,希望今天的分享能帮你省下那宝贵的6.63秒钟,甚至更多。