今天用来练手的是一个基于LINUX平台的题目,难度被官方评为1颗⭐。就是入门级了解一般概念
本次笔记从简单开始,主要是熟悉在linux平台上的GDB逆向相关操作,以及简单了解Linux系统上程序运行的机制。GDB是一个LINUX平台的基于命令行的逆向工具,一般可以通过Linux发行版的安装工具直接安装。其功能非常强大,由于是基于命令行界面的,所以学习曲线稍微有点陡,但常用的可以快速记住,不超过10个命令。GDB的使用方法,将在后续的逆向操作中介绍。相信我,不难,就是需要硬记一些命令。在Linux上逆向不一定使用GDB,可以使用IDA,GRITRA(限LINUX平台)等图形化界面来进行分析,但在观看国外的一些论坛和会议的时候,大部分都是使用GDB来进行演示的,所以我也由GDB开始来学习LINUX上的逆向。而Linux环境的准备,如果使用windows 10/11 系统的推荐使用系统自带的WSL环境,可以一键快速启动,并且可以与windows共享磁盘空间,不需要将文件拷来拷去,也不需要特意去装一个虚拟机。如果是mac的,就可能需要装个虚拟机了。
通过网盘分享的文件:657_5ab77f5633c5d40ad448c2b7链接: https://pan.baidu.com/s/1p3dSU9BCLTfAVsFNDv3rFA?pwd=16te 提取码: 16te
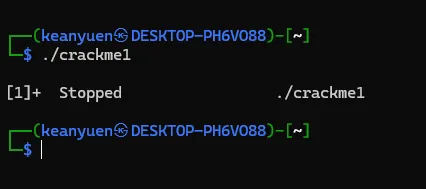
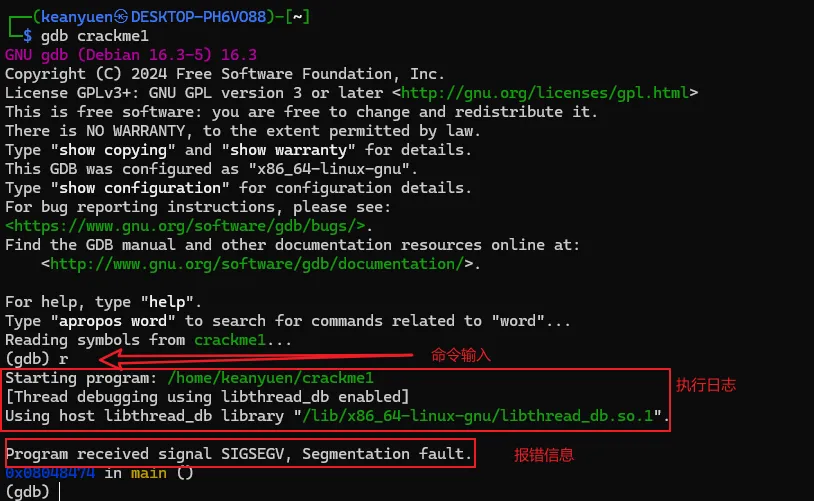
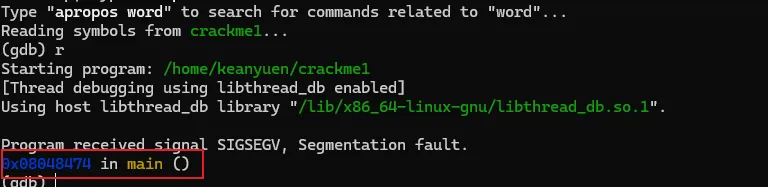
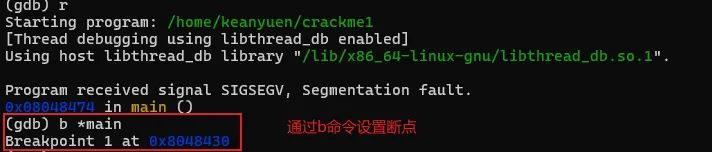
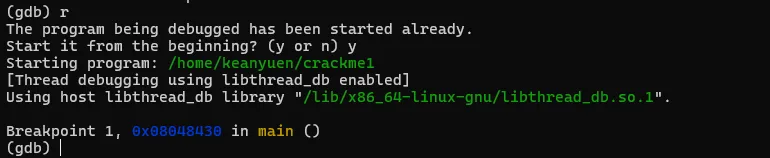
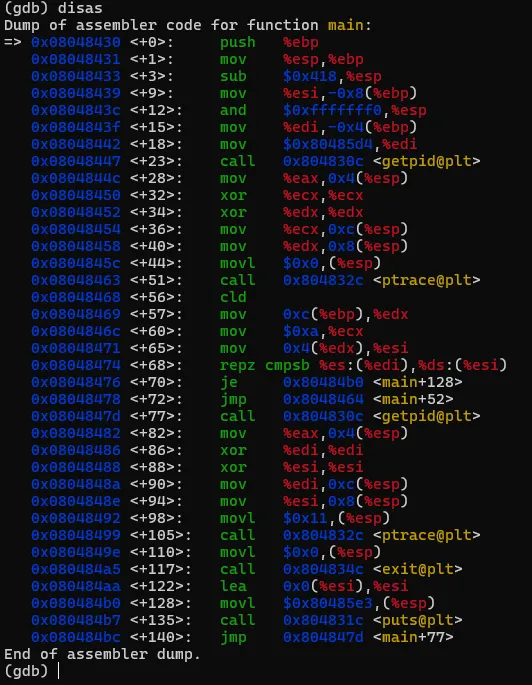
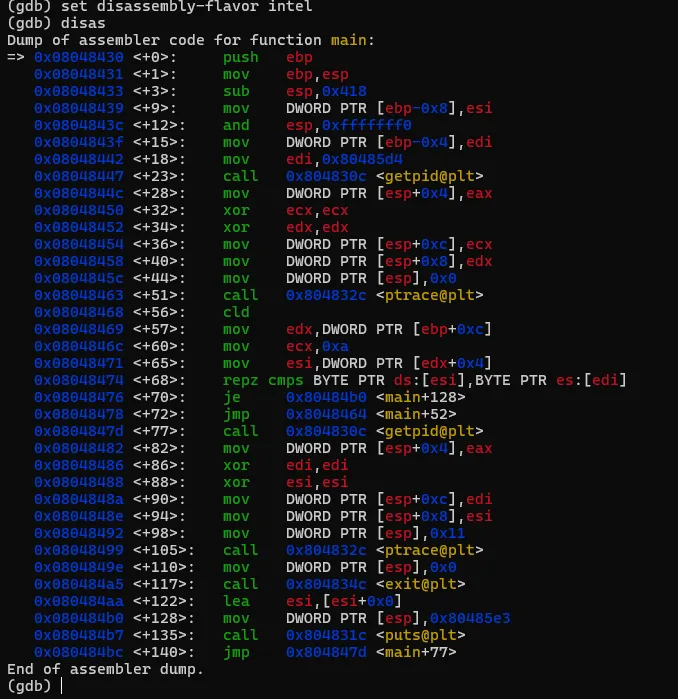
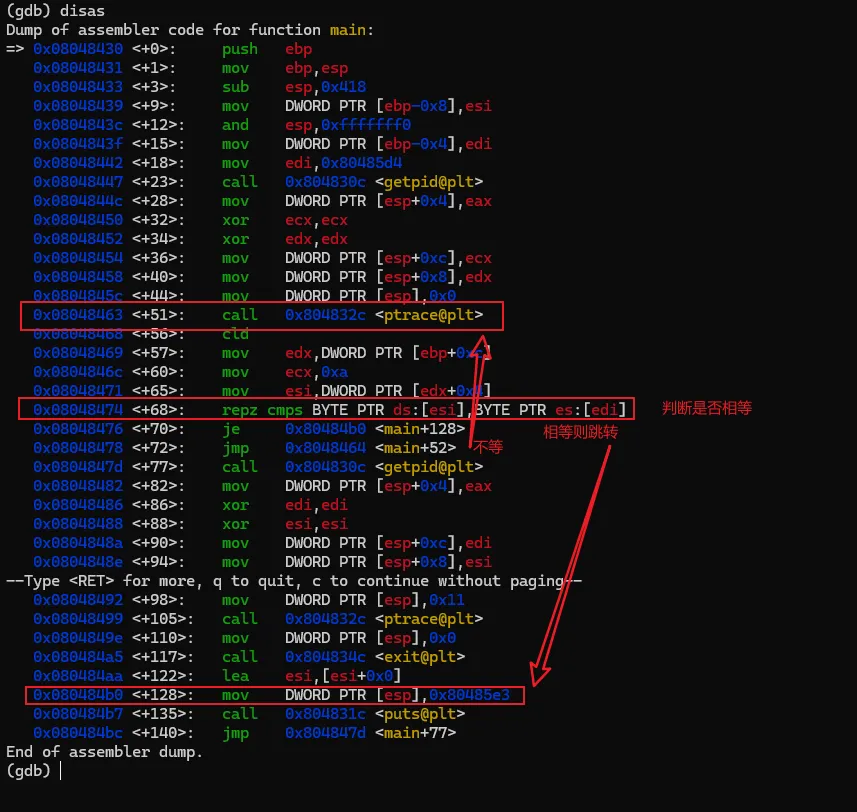
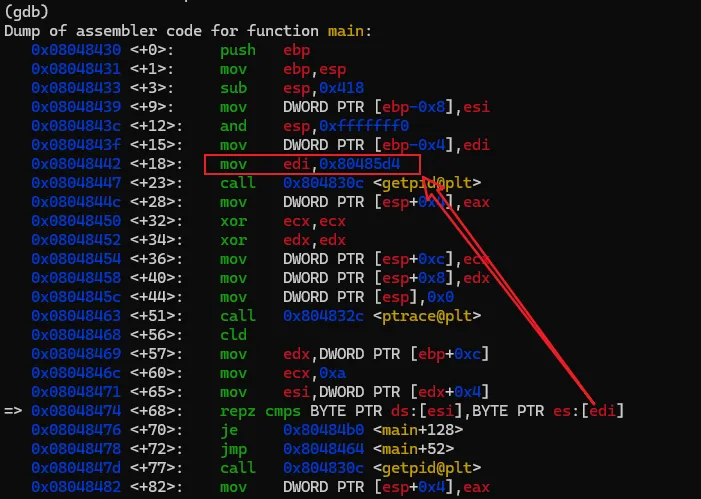
将文件解压后,有一个名为"crackme1"的可执行文件,先尝试运行一下看看大概的执行逻辑。直接退出了,在这过程中没有要求任何的输入信息。接着就使用GDB来一探究竟。直接在命令行输入"gdb <文件名>",打开gdb的同时将破解的执行文件加载到gdb进程中。此时crackme1只是加载到gdb中,并未执行任务逻辑。如果要执行crackme1程序,可以输入"run"命令,或者使用"run"的简化版命令"r"。gdb中的命令基本都有简化版,可以记忆一下。在界面中输入"run"或"r"命令后,gdb就执行crackme1程序,结果如图。当输入"r"命令后,程序开始执行,同时打印出了一些日志信息,大概是说程序加载了系统的什么库之类的内容。可以先忽略。最后程序报了一个异常,然后中止了。而这个异常信息与直接执行程序所报的信息不一致,可能的原因是程序有进程是否调试的判断 。上面是在GDB中直接执行了程序,我们有没有方法将让程序中断在程序入口,然后分析其中的具体逻辑呢?答案肯定是有的,我们可以先在程序入口设置一个断点,然后再执行程序。当程序中断后,我们将程序的汇编代码打印出来分析。完成上面的步骤我们首先需要一个设置断点的命令:"break"、"b"。其中"b"中"break"命令的简写。命令有了,但加在哪个位置呢。这里可以使得小技巧,在上面的执行信息中的最后,有这么一句信息:这个信息主要描述的是当前执行的函数范围。0x08048474 是报错的地址,main就是我们写c程序时熟悉的入口函数名称了。能显示main()的信息,则代表了程序在编译的时候保留了一些符号信息。我们可以使用"b"命令通过main符号来设置断点。设置断点的格式如下,注意前面的*号是必须的。当设置成功后,gdb会反馈断点1设置在在 0x08048430的地址上。此时输入"r"命令,重新执行程序,gdb会要求确认是否重新执行,输入y 回车即可。程序重新执行后,如无意外,会提示程序停止在我们刚设置的断点上:此时,我们可以执行反汇编命令,打印出汇编代码作进入步的分析了。“disassemble”就是我们需要的命令了,同样,该命令也有简称,就是前面的头5个字母:"disas"。输入该命令后gdb就会进行反汇编操作了。如图,gdb会将整个main函数打印出来,最上端的"=>"箭头指向的就是当前的指令位置,也就是我们的main函数。每一行都包括一个16进制的内存地址;"<+xx>"形式的偏移地址,该偏移是从当前函数开始算的,一般可忽略;再接着就是具体的汇编指令了。但这里有个问题,打印出来的汇编格式AT&T的风格,但我熟悉的是intel风格的代码,所以需要转换一下,如果不熟悉AT&T风格代码的同学可以通过以下命令转换一下。set disassembly-flavor intel
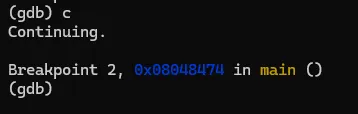
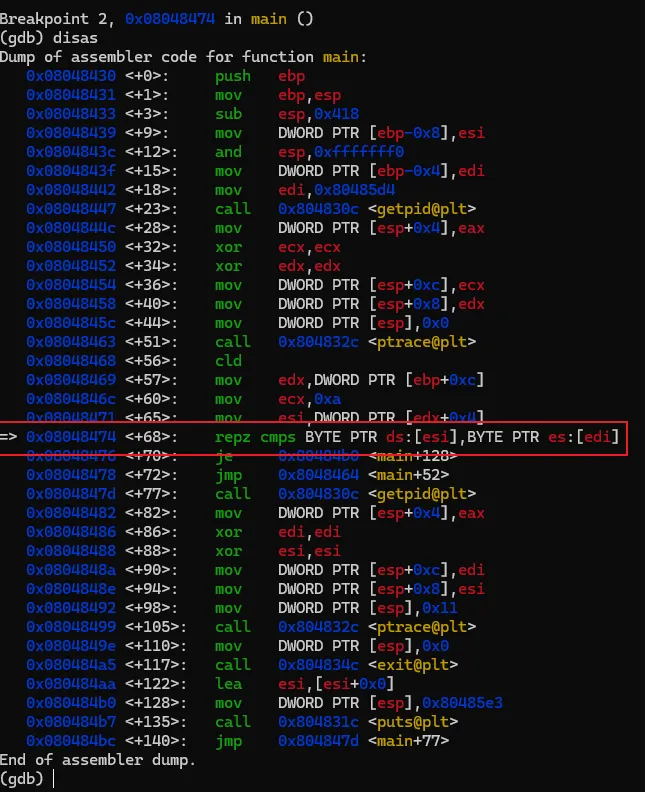
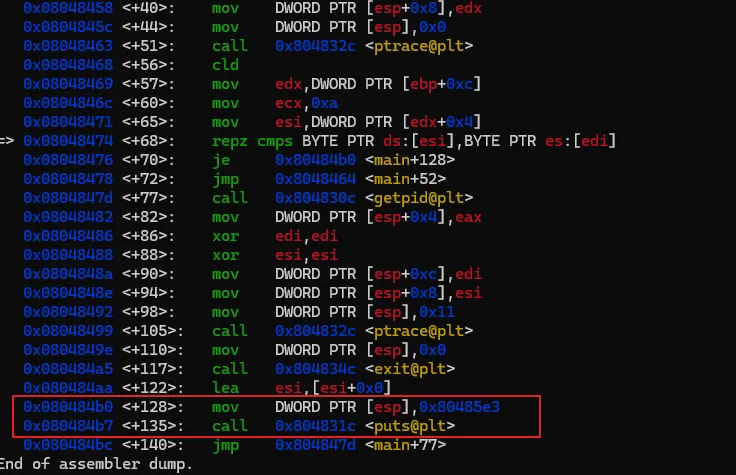
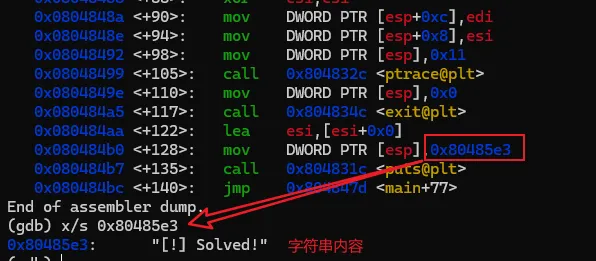
输入上述命令重新反汇编,我们熟悉的风格就又回来了。为了避免每次重新打开gdb要手工设置,可以在用户目录下建一个名为".gdbinit"的文件,然后将上述命令写入该文件后保存,那么gdb每次启动都会将汇编风格应用在intel风格上了。汇编代码有了,现在开始进行具体的分析,本次的汇编命令不多,可以先找关键比较命令及关键跳。可以很快地找到,因为带比较逻辑的命令就那么1个,在0x08048474地址上的 repz cmps 指令,如下图。可能该指令对新手比较陌生,不过没关系,见到陌生的命令可以搜一下看是怎么用的。这个指令大概意思是,比较两个字符串是否相等。如果相等,则跳到0x080484b0 继续指行;如果不等则跳到 0x8048464,但明显是找不到指令是从该地址开始的,只找到0x80484643。我们可以继续执行看一下结果会怎样。我们先通过"b"命令把断点设置在 repz cmps 指令处,再执行看能不能断下来。设置完成后,程序还继续停留在原来的地方没动,通过"continue"或简称"c"命令,让程序继续执行。gdb会打印出Continuing信息,然后输出断点信息,表示命中了。再使用"disas"命令验证一下这个repz cmps命令可能 比较陌生,可以分开这样记,cmps 中的cmp是比较的意思,后面的s 代表的是字符串,所以整个cmps就是比较字符串的意思,而repz的rep是重复的意思 ,z代表的是为0。整个命令的意思是逐个比较两个字符串的字符,如果相等就继续,如果不等就停止。而ecx就比较的次数,也就是字符串的长度。结合上面的命令解读,就是比较esi 和 edi 中保存的字符串中头10个字符,如果相等,则执行 je 0x80484b0 指令,跳到0x80484b0地址处执行,如果不等,则执行jmp 0x8048464,无条件跳到0x8048464处执行。由于相等则执行 je 0x80484b0 指令,我们有必要看一下0x80484b0地址的指令处是处理了什么内容。也就是下图红框的位置。这里需要补充一个额外知识点,在32位系统中,一般都是遵循cdecl 和stdcall的程序调用约定,大概意思就是当调用函数时,会先将最后的参数压入栈中,再从后往前依次将参数入栈,然后再调用函数。而cdecl和stdcall调用约定的唯一区别是,一个是调用者平栈,一个是被调用者平栈。从上面的汇编代码来看,call 后面并没有平栈的操作,那可以认为这里都是使用stdcall约定。但我们关注的是参数的使用方式,参数是从后往前入栈的。 mov DWORD PTR [esp],0x80485e3
该指令是将立即数 0x80485e3 传进esp寄存器指向的地址中,而esp寄存器是永远指向栈顶的,所以这个指令也相当于"push 0x80485e3" 。然后后面接着一个函数调用,0x80485e3 就是一个指针,是puts函数的参数 call 0x804831c <puts@plt>
这里就相当于 call puts(*p)。可以用关键字 "c puts"搜一下该函数的定义验证一下。那么该函数的入参内容是什么呢。可以使用强大"examin"或简称"x"命令查一下该地址指向的是什么内容,该命令可以以多种格式查看某地址任意字节的内容,需要多使用熟练。大概格式如下,"x/"是固定格式,后面的个数、格式、单位可以任意组合。x/[个数][格式][单位] 地址个数:任意整数格式:x-16进制、c-ascii字符、s-字符串(可不需要单位,自动找到0x00为止)单位:b-1字节、w-字(4字节)、g-双字(8字节)
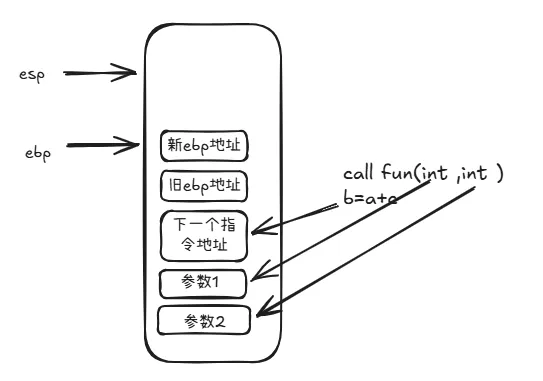
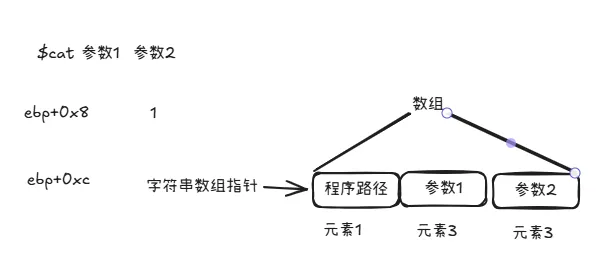
回到汇编上,从定义上可以看到参数是一个字符串指针,用下列命令检查一下内容。命令后面接的"s"代表检查的这个地址是字符串,gdb会一直查询直到字节内容是"0x00"时停止。如上图所示,0x80485e3 地址的内容就是"[!] Solved!"字符串,显示的内容翻译过来就是“解决了”。所以如果"repz cmps"指令处的比较结果是相等,就会跳到这里来,就完成了该题目了。回到"repz cmps"指令处,esi 和edi分别保存着两个地址,分别 指向两个字符串。先看edi指向的是什么内容。从分析得出,在0x08048442地址处,edi只经过了一次赋值就直接用来作比较了。我们继续用"x"命令查看0x80485d4地址的具体内容同时也可以通过edi再次确认一次。通过"$"+edi替换上面命令的具体地址,这是代表取取寄存器的值作为地址使用。可以看到两个内容是一样的。所以edi指向的就是0x80485d4地址指向的字符串 "__gmon_start__"。esi的内容主要由上图两个命令组成,[ebp+0xc]的内容传入到edx,再从[edx+0x4]处传一个双字(4个字节)内容到esi。这是典型的使用对象传值的处理方式,[ebp+0xc]是一个对象指针,然后丙从这个对象指针偏移4个字节取值。在汇编中,数组就是这种取值逻辑。假如有一个数组a,[ebp+0xc]指向的就是数组的开始位置,同时第一个元素的值 ,[ebp+0xc]=a[0]的值,然后偏移4个字节,那么[ebp+0xc+0x4]=a[1]了,如此类推,[ebp+0xc+0x4+0x4]=a[2]。知道这两条命令的逻辑后,最后就剩下ebp+0xc的值是哪里来的。由于我们现在分析的程序的main函数,在这之前是没有用户输入的了,那么我们可以联想到会不会跟程序调用时的参数有关。还真没错。在32位的逆向过程中,有些规律我们可以先记着。就是在一个程序代码中,ebp+0x8 是第一个入参,ebp+0xc是第二个入参。由于篇幅关系,这里只简单带过一下。那为什么不是直接从ebp开始呢,因为每一次的函数调用,都会形成一个栈桢,在系统层面,我们写的main函数,也只是相当是一个函数,只是该函数是被系统调用的。然后每个栈桢会依次由三部分组成,第一个是被调用函数的参数,然后是返回地址,最后是保存当前栈桢的栈底地址。大概示意图如下图我们回忆一下,在我们写c/c++的时间,main函数是这样写的main(int argc, char **argv)
在linux机制中,当在shell 里执行程序时,第一个是传入参数的个数,也就是argc。第二个参数是一个数组,这个数组保存的是字符串指针,这些指针就是指向我们执行命令时的参数,但我们输入的参数是从数组的第二个元素、下标为1的位置开始。而第一个元素、下标为0的元素,保存的是程序的路径。那么我们确定的是ebp+0xc是main函数的第二个参数,而这个参数是一个数组,esi取的是这个数组的第二个元素。也就是程序调用时的第一个参数。结合我们在edi上读到的内容 "__gmon_start__",可以得出repz cmps指令那一行,就是需要将程序调用时的第一个输入参数与"__gmon_start__"字符串的前10位比较(repz cmps 指令前的 mov ecx 0xa)。如果相等,则提示"[!] Solved!",如果不等则报错。要解决这个题目,需要一些基本的Linux知识,因为全都是基于命令行的,包括程序的执行都是基于命令行的,跟我们一般使用的Windows有些许不一样;另外就是需要了解一些基于Linux的一些反汇编程序,而本文使用的是GDB命令行工具,当然如果装了图形界面,可以使用其他的一些如Ghidra 这样的图形软件 。最后一点就是需要了解linux上程序的汇编知识,如程序参数是怎样传递的,这点反而比windows简单多。再加上汇编语言上程序调用的约定,这一点哪个平台都基本适用的。







 10个月宝宝每天需要喝多少奶粉?
10个月宝宝每天需要喝多少奶粉?
