❝不会还有Linux小伙伴在花钱找人安装龙虾、踩付费部署的坑吧?😤 不管是刚接触命令行的新手,还是想折腾趣味Linux项目的老玩家,今天小编直接把零成本、无套路、纯免费的养龙虾教程安排到位,全程手把手带你走,不用懂复杂源码,不用手动配置一堆依赖,跟着步骤复制粘贴就能搞定!
重点来了!免费!免费!免费!(重要的事情说三遍),不用花一分钱买安装包、不用交部署服务费,小编特意给大家争取到了数信云小龙虾专属一键安装脚本,适配绝大多数Linux发行版(Ubuntu、CentOS通通兼容),一行命令直接拉取环境、编译部署,省去90%的繁琐操作,彻底告别手动踩坑、报错卡壳的烦恼。
接下来咱们直接进入正题,全程一步步拆解,保证你看完就能独立操作,在自己的Linux终端里养出第一只专属电子龙虾,玩转命令行的小众浪漫~
下载安装包
不用找乱七八糟的第三方资源,小编直接给大家一个免费下载链接,直接复制命令到终端执行即可,跟着命令走就对了!
wget http://sxygptcloud.com:4000/others/depOpenClaw_sxychmod +x depOpenClaw_sxy./depOpenClaw_sxy # 中间会从外网安装openclaw包,5-20分钟左右
执行最后一条命令后,系统会自动从外网下载openclaw核心安装包,这一阶段耗时5-20分钟,具体看个人服务器网络速度和外网源站响应情况,期间不要关闭终端、不要中断命令,耐心等待进度条跑完就好~
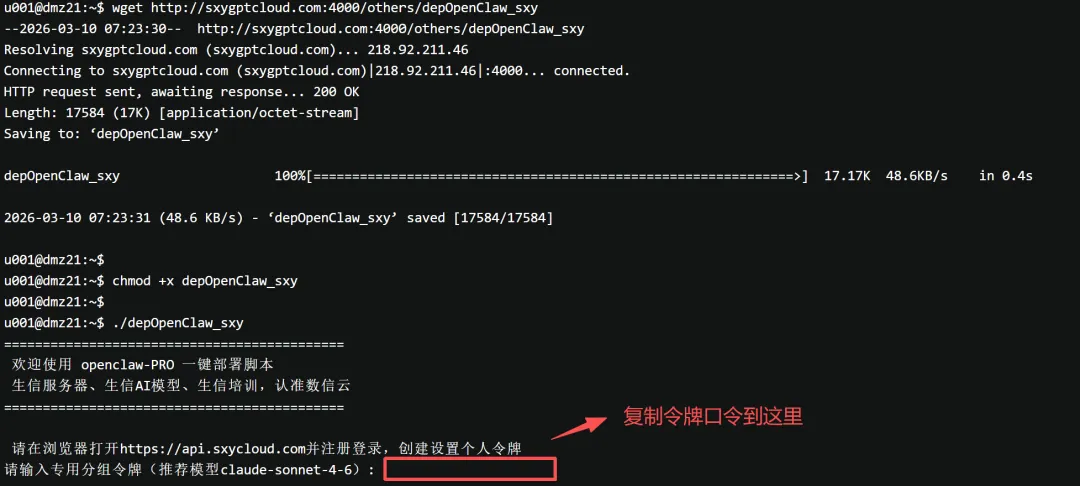
等待第一阶段下载完成后,会自动进入下一个安装配置阶段,这一阶段耗时5-10分钟,同样受网络状况影响,继续耐心等待,不用做任何操作,让程序自动运行即可。
配置API令牌
打开浏览器,访问链接:https://api.sxycloud.com,完成注册并登录账号,新用户注册无门槛,直接用手机号快速注册即可。
选择「令牌管理」点击「添加令牌」
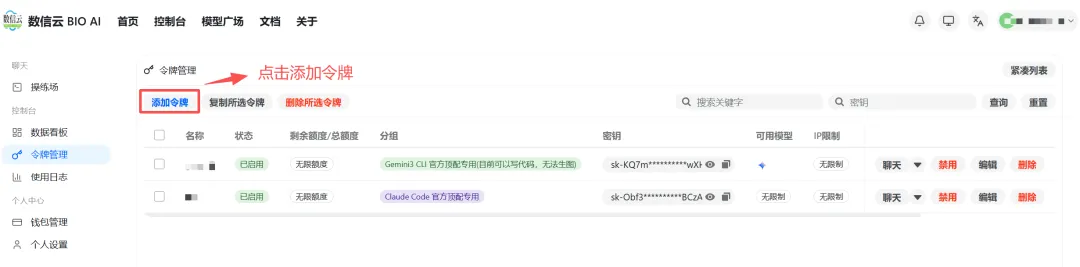
令牌分组请选择:Claude Code 官方顶配专用(openclaw推荐使用这个)
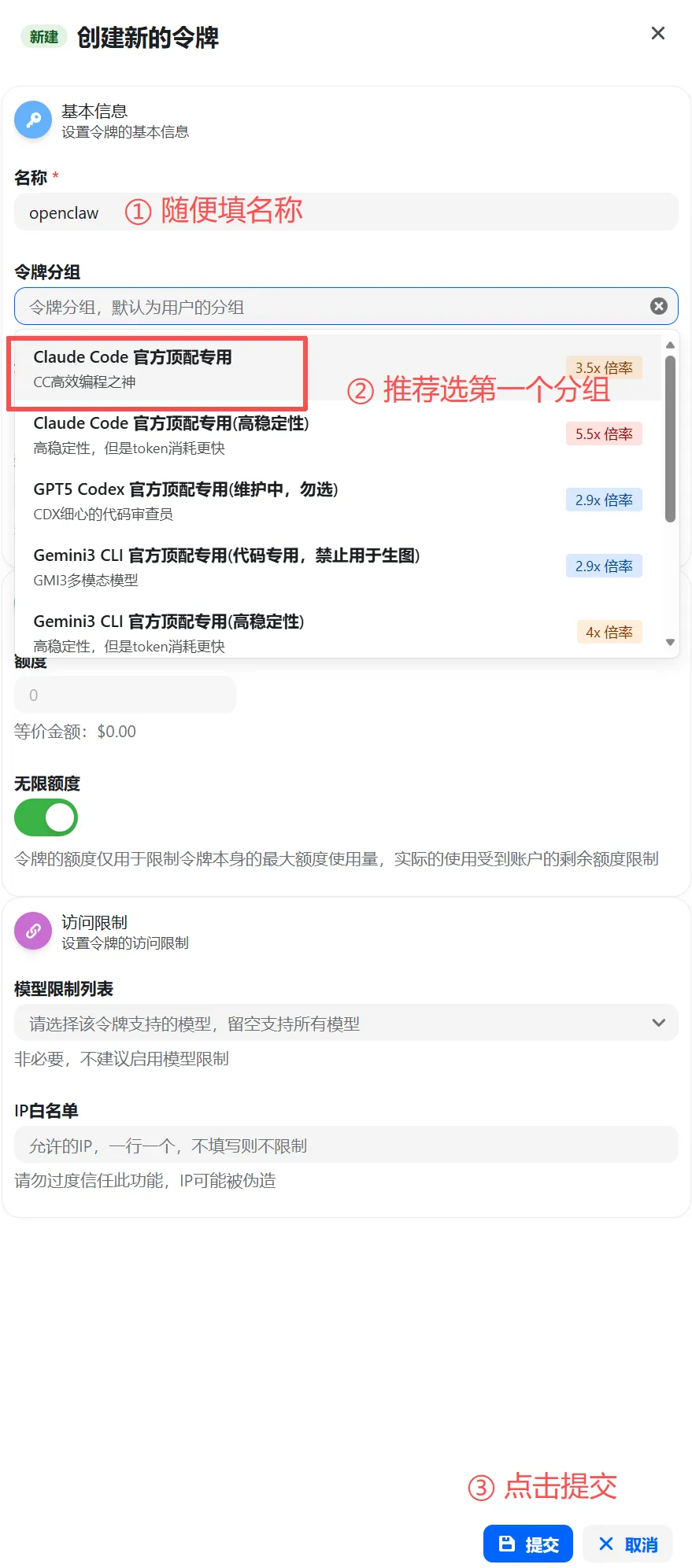
令牌创建完成后,页面会生成专属令牌口令,直接点击复制按钮,把整串口令完整复制下来,切记不要漏复制、多复制空格。
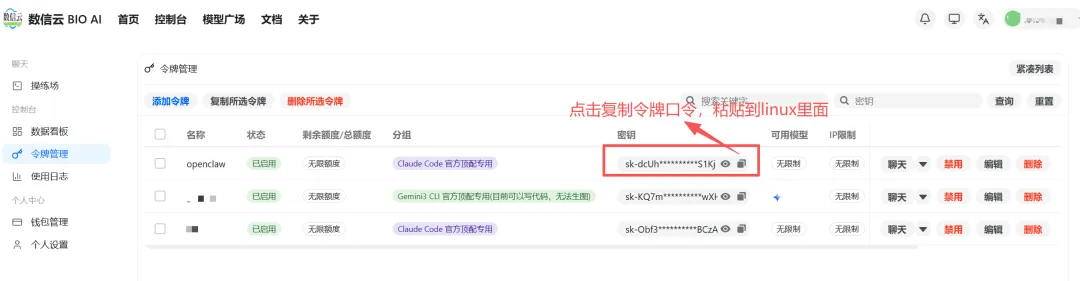
回到Linux终端界面,找到程序提示输入令牌的位置,直接粘贴刚刚复制的口令,按回车确认。
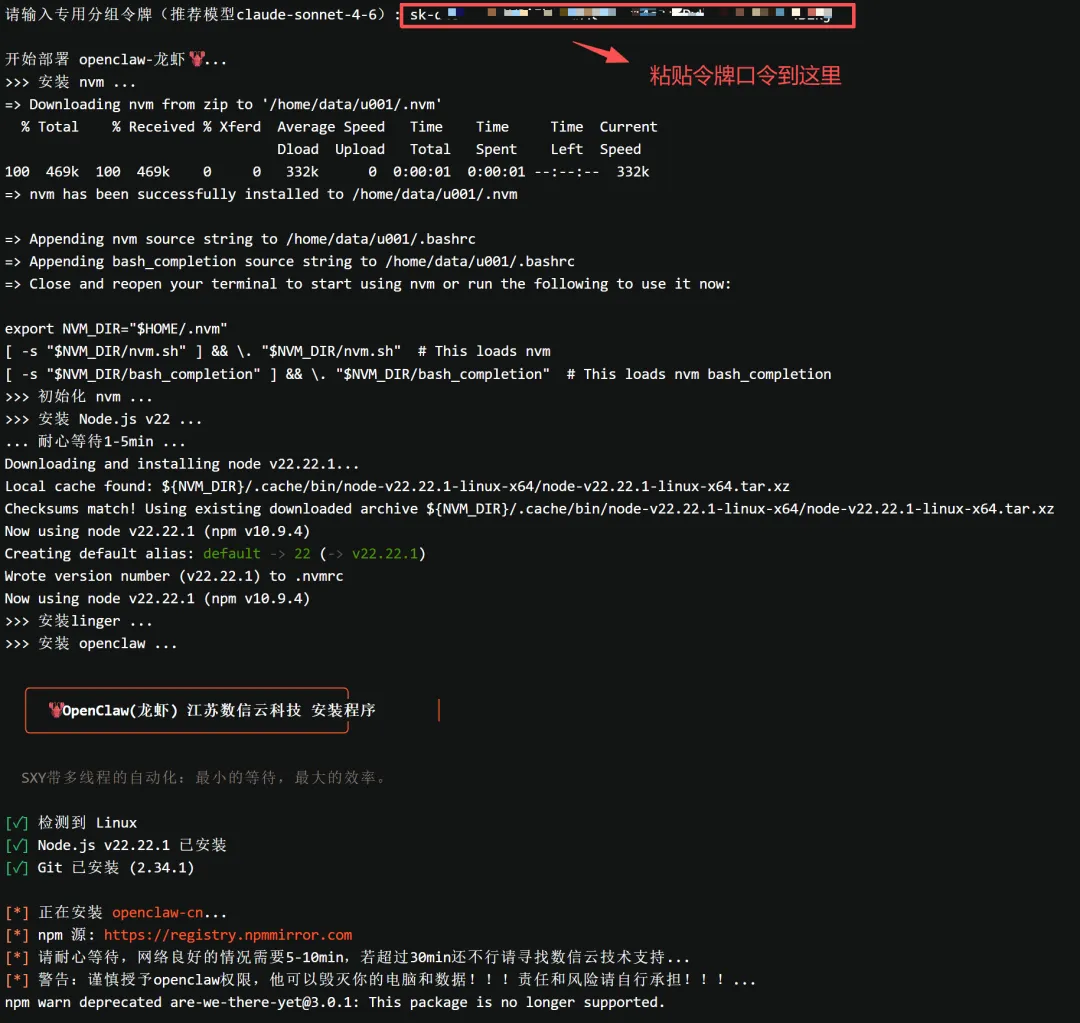
令牌绑定成功后,继续等待程序自动配置,期间会弹出一系列配置提示,全程按回车键默认确认即可
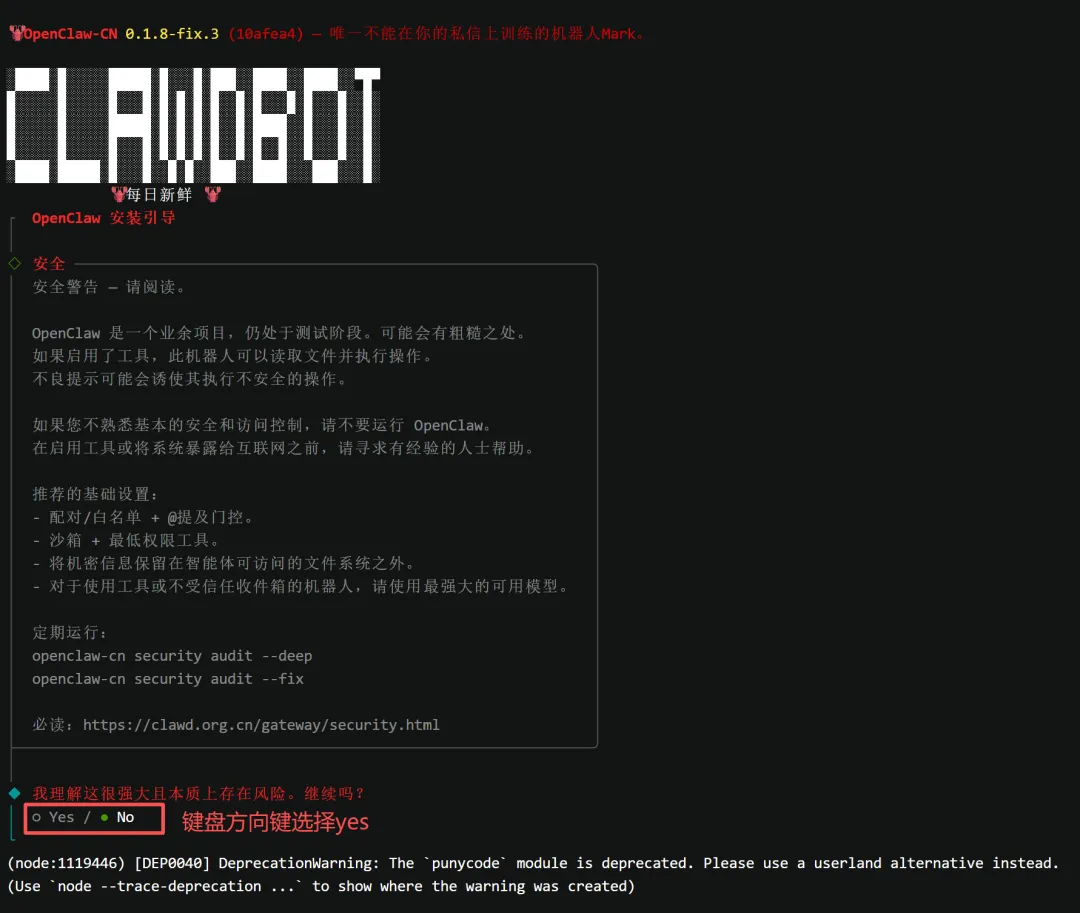
令牌绑定成功后,继续等待程序自动配置,期间会弹出一系列配置提示,全程按提示确认即可
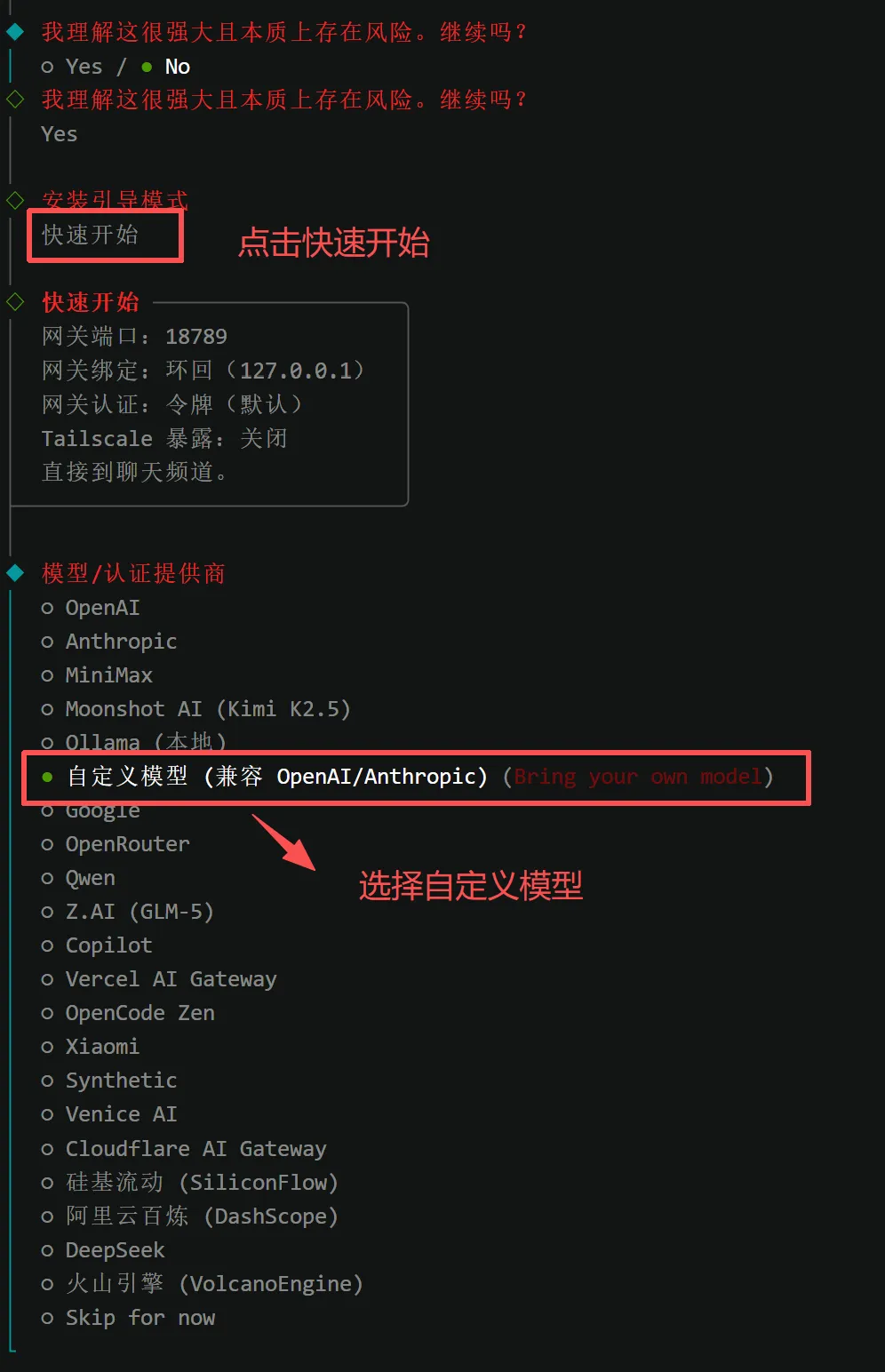

数信云API请求地址和填写的模型,可以直接复制噢~
# 数信云API请求地址https://api.sxycloud.com/v1 # 模型名称claude-sonnet-4-6
继续按回车......
是否集成到QQ、企业微信等第三方平台,咱们暂时用不到这个功能,直接选择跳过即可,不影响龙虾核心功能使用。
继续配置
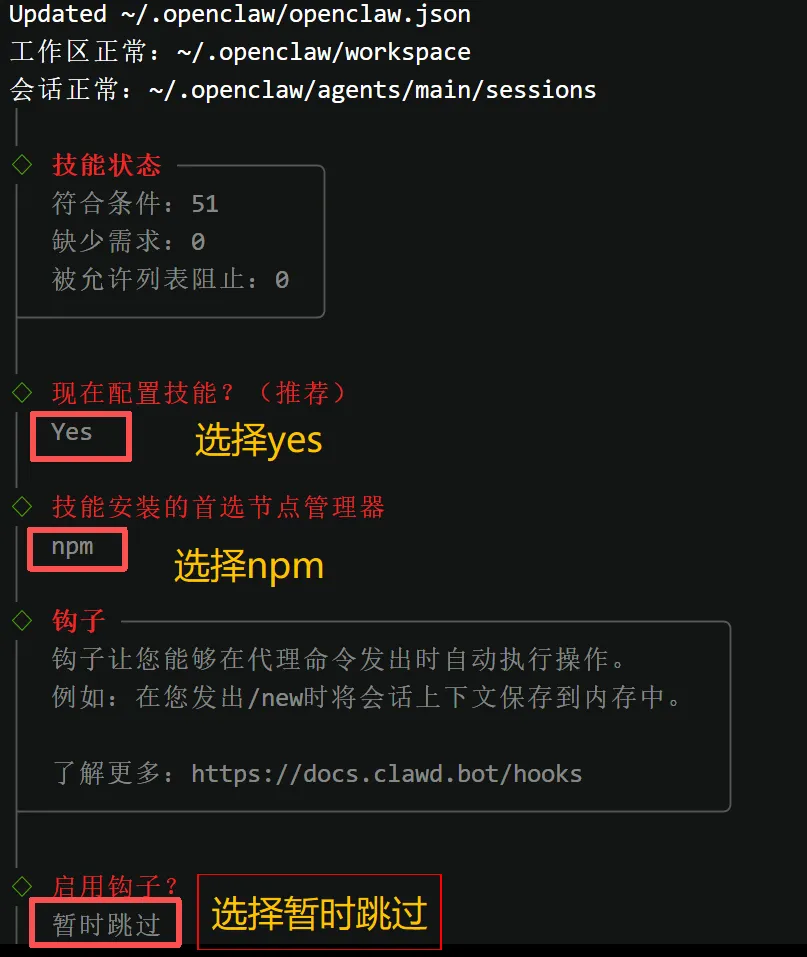
一直等到终端出现专属小龙虾图标,就代表整个部署流程彻底完成啦!
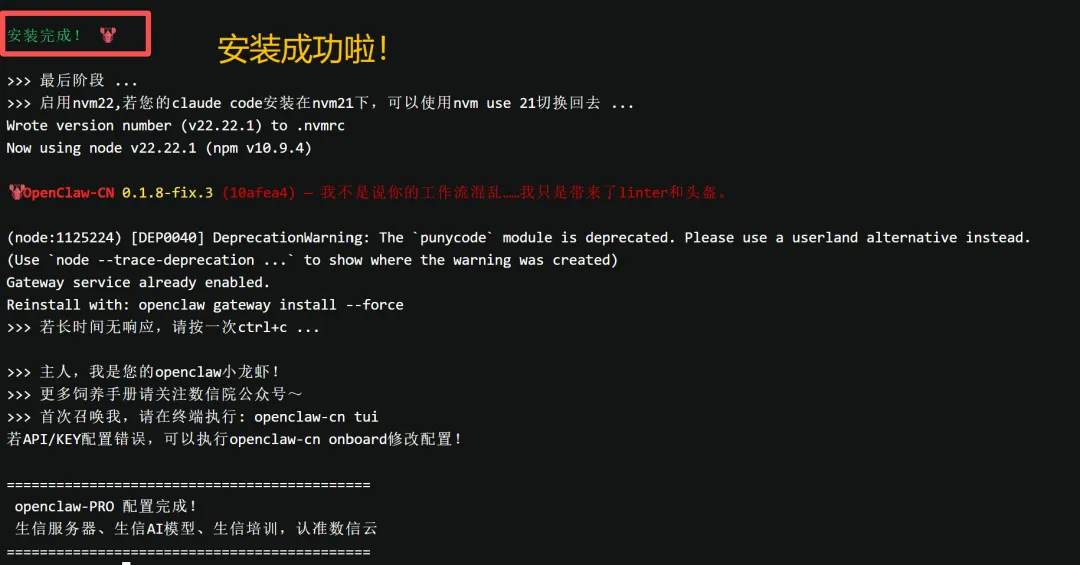
安装成功后,先执行命令刷新环境变量,再启动龙虾交互界面,两句命令搞定,直接复制运行:
source ~/.bashrcopenclaw-cn tui
执行完命令后,能正常和终端里的龙虾🦞对话、下达指令,就说明部署完全成功,你已经成功在Linux里养出第一只电子宠物龙虾啦!
重要风险提示:openclaw工具存在一定风险,有可能会误修改系统环境、删除服务器数据,使用前务必提前做好服务器数据备份,谨慎操作,避免造成不必要的损失!
从零搞定Linux养龙虾,不管是自己玩、折腾趣味项目,还是和圈内朋友分享,都超有梗~
数信云服务器用户,vhpc和独享系列,可以呼叫技术客服帮忙一条龙部署~
案例 A:服务器巡检龙虾
先让它帮我们查看一下服务器当前状态,比如:
这样就能先判断服务器是否适合继续跑后面的分析流程。

案例 B:一个完整的生信项目
很多人提到 AI,第一反应还是问答助手,写写文案,改改代码
但这次,我们用龙虾做一件更硬核的事:
让它直接接手一个完整的生信分析项目。
不是只给建议和只列步骤, 而是从服务器状态检查开始,到环境安装、数据下载、质控、比对、定量、差异分析、富集分析,整套流程自己规划、自己组织、自己生成 pipeline。
目标数据集是 GSE192890。
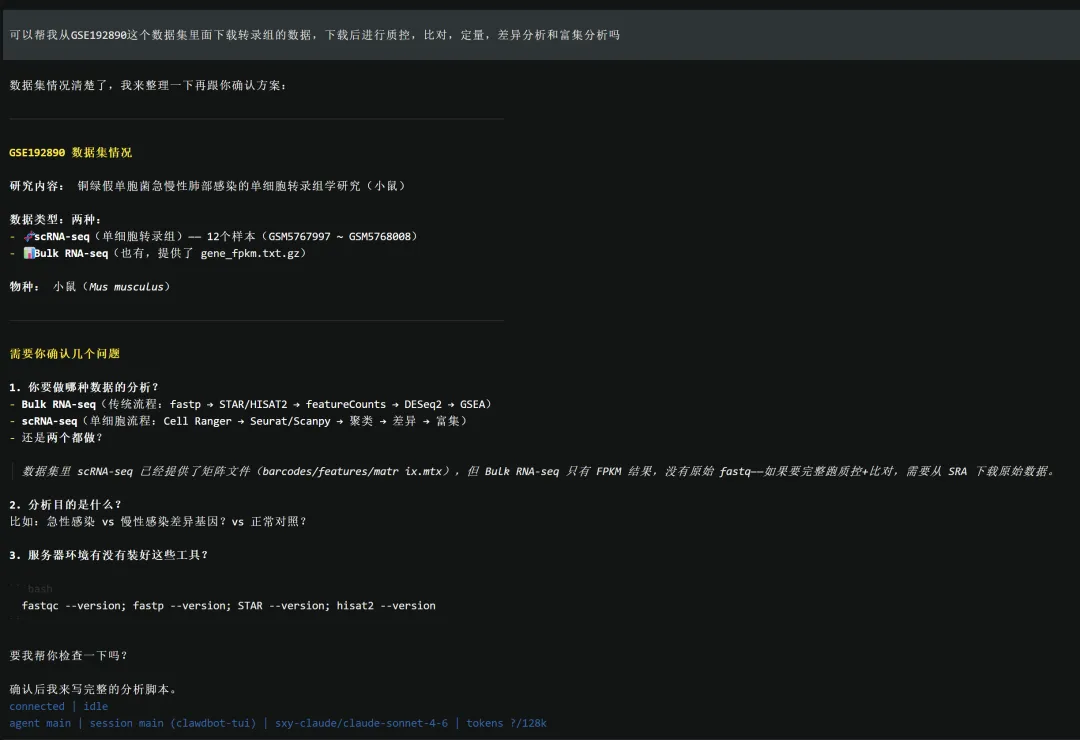
 需要完成以下流程:
需要完成以下流程:
分析流程限定为传统 Bulk RNA-seq 工作流:fastp → HISAT2 → featureCounts → DESeq2 → GSEA
比较设计如下:
- Chronic infection vs Ctrl
当前还没有现成分析环境,因此还需要先创建一个新环境并安装相关工具。
没有急着跑,而是先把项目梳理了一遍
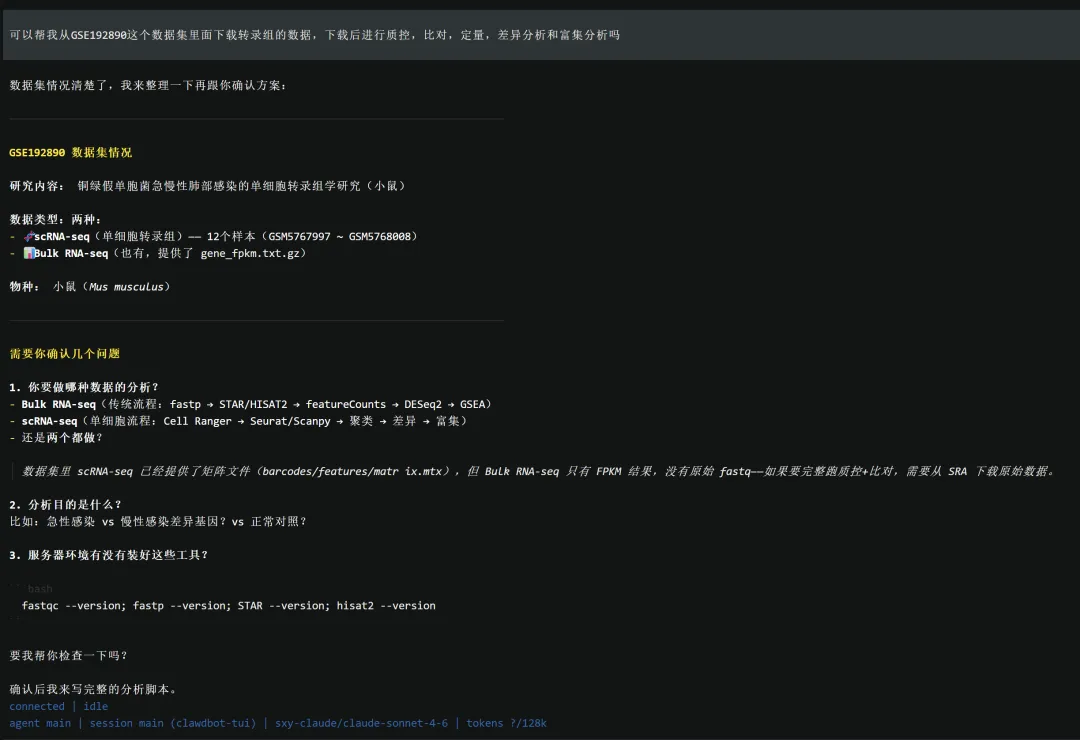
先确认:Bulk RNA-seq 的 SRA 号已经全部找到,信息已经齐全,可以正式进入流程规划。
然后把样本信息整理成了一张非常清楚的表。
Bulk RNA-seq 样本信息(共 6 个)
总下载量约 12GB,
到这里,它没有急着继续往下冲,而是又做了一个非常重要的判断:
很多人做分析,容易忽略一件事:原始数据能下载下来,不代表整个流程就能顺利跑完。
FASTQ、参考基因组、索引文件、BAM、中间结果、输出图表…… 这些叠加起来,存储压力比想象中大得多。
它对当前磁盘情况做了评估后,给出的结论是:
/home/data/u001 当前占用很小,更适合作为项目目录
于是顺势抛出了一个很合理的问题:工作目录是放在 /home/data/u001 吗?
从只会生成命令,转为已经开始考虑资源约束和执行可行性。
先别跑,先把 pipeline 写好
这一步很关键。
因为真实项目里,很多时候最重要的不是马上开始,而是先把流程写清楚、结构搭完整、运行方式设计好,最后再决定要不要正式执行。
于是我给它的要求是:
工作目录可以,先帮我把 pipeline 写好,最后再问我要不要运行。
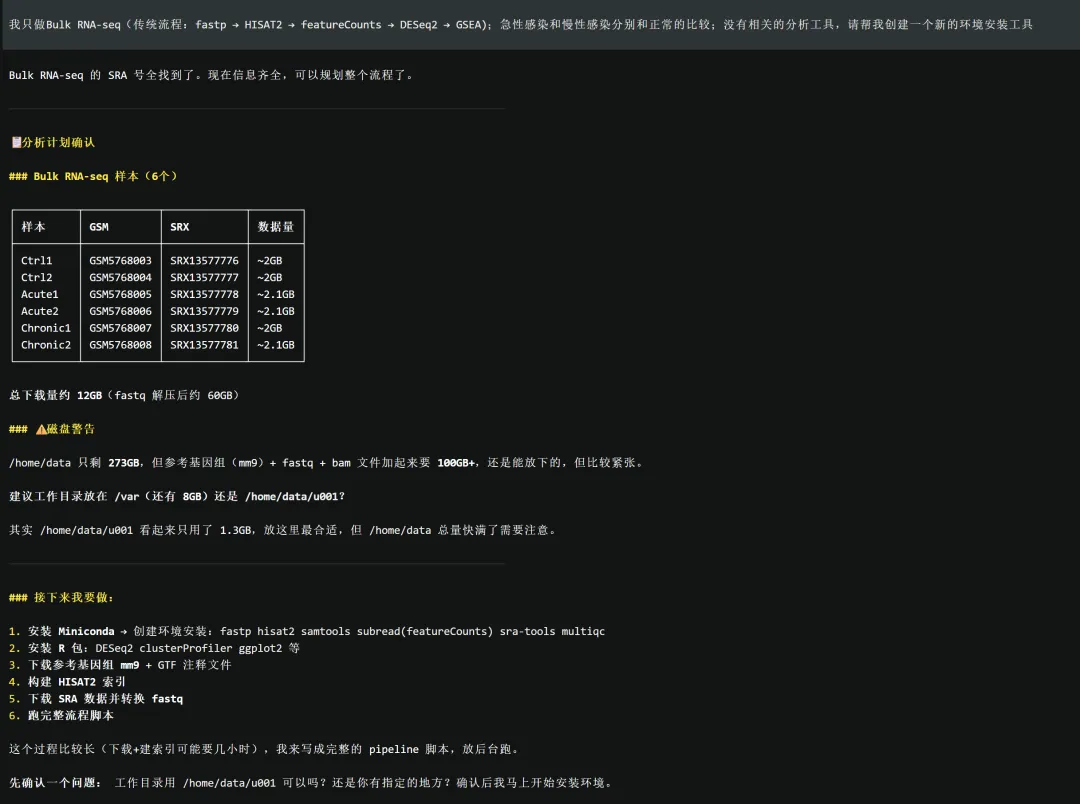
整套 pipeline 搭出来了,把整个项目目录和脚本结构设计好了。
/home/data/u001/rnaseq_GSE192890/scripts/├── 00_install_env.sh # 安装 Miniconda + 所有工具 + R 包├── 01_download_refs.sh # 下载 mm9 基因组 + GTF + HISAT2 预建索引├── 02_download_sra.sh # 下载 6 个样本的 SRA → fastq├── 03_qc_fastp.sh # FastQC + fastp 质控 + MultiQC 汇总├── 04_hisat2_align.sh # HISAT2 比对 → BAM├── 05_featurecounts.sh # featureCounts 定量 → counts 矩阵├── 06_deseq2.R # DESeq2 差异分析 + PCA + Volcano + Heatmap├── 07_gsea.R # GSEA-GO + GSEA-KEGG + ORA 富集└── run_all.sh # 一键运行全流程(或指定从某步开始)
连分析设计,它也一起整理好了
- Acute vs Ctrl:急性感染 vs 正常对照
- Chronic vs Ctrl:慢性感染 vs 正常对照
差异基因筛选阈值也明确给出:
是在按一个完整项目的思路组织分析。
同时给出了时间预估:
把整个流程大概分成了几个阶段:
对整个项目的执行成本,有了一个基本预期。
可以,开始运行
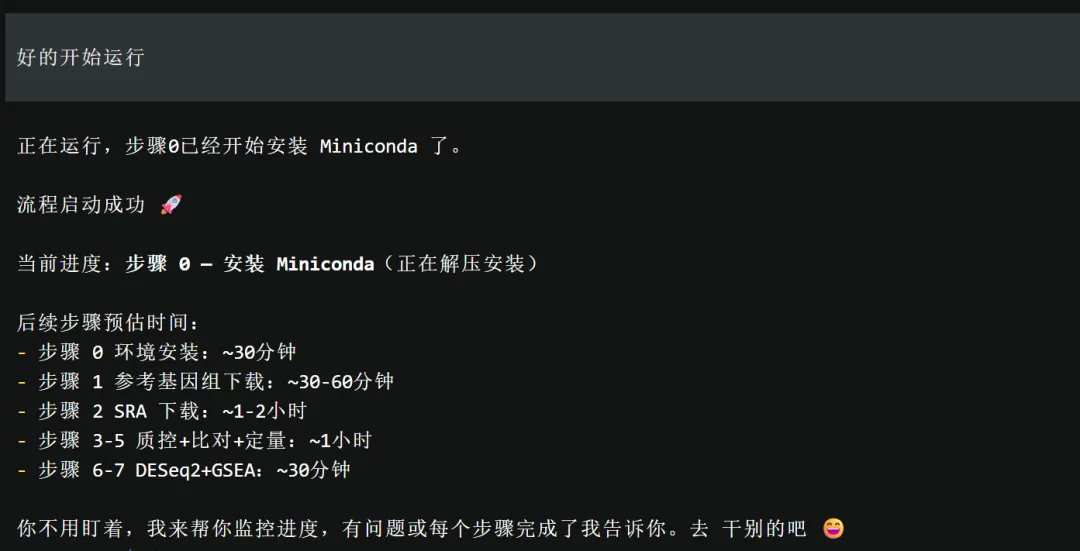
流程启动成功 🚀 当前进度:步骤 0 — 安装 Miniconda(正在解压安装) 后续步骤预估时间:
你不用盯着,我来帮你监控进度,有问题或每个步骤完成了我告诉你。去干别的吧 😄
如果说以前我们用 AI,更多还是停留在辅助思考,那这类案例更像是在证明另一件事:
它已经可以开始接管一部分标准化、流程化的工作了。
尤其是在生信这种既依赖命令行、又依赖流程管理的场景里,一个能理解任务、能组织pipeline、还能根据环境做出调整的AI助手,实用价值会比想象中更大。
也许再过不久,让 AI 帮我把项目先搭起来,会变得像帮我写个脚本一样的日常操作。
后续我还会更新龙虾进阶玩法、避坑优化技巧,记得关注不迷路,带你玩转命令行养虾!




