下篇|Al挖Java Oday不再靠运气!这套Skill让审计覆盖率100%、幻觉率趋近0
- 2026-07-03 03:38:48

AI挖Java 0day不再靠运气!这套Skill让审计覆盖率100%、幻觉率趋近0(上篇)
上篇我们拆解了AI代码审计Skill体系的流水线设计与资源分配机制:
问题诊断:LLM不是没能力,而是缺纪律——它需要的不是知识,而是工作方法和质量标准
6阶段流水线:Phase 0(代码度量)→ Phase 1(项目侦察)→ Phase 2(全量审计)→ Phase 2.5(覆盖率门禁)→ Phase 3(漏洞验证)→ Phase 4(规则沉淀)→ Phase 5(报告生成)。其中 Phase 0 是工程度量层,Phase 4/5 是产物输出层,Phase 1-3 是核心审计流程。
EALOC资源分配:Tier分层(T1/T2/T3)+ EALOC公式,削减67% Agent成本但不降质量
三层审计架构:机器扫广度(Layer 1)+ AI挖深度 (Layer 2双轨模型)+ 语义追链条(Layer 3)
这些机制解决了"如何高效审计"的问题。但光有流水线还不够,下篇将深入质量保障机制:覆盖率门禁、反幻觉铁律、漏洞成立条件判断、DKTSS评分体系,并对比现有AI审计方案的不足。
覆盖率门禁:LLM最严厉的"父亲"-Phase 2.5
Phase 2.5 是整篇文章中最"反 LLM 天性"的设计。
无论是claude code还是什么其他的AI产品经常使用就会发现:LLM 有一个天然倾向-对感兴趣的代码深挖,对"看起来不重要"的代码跳过。在代码审计中,这是致命的因为漏洞恰恰喜欢藏在"看起来不重要"的地方。
覆盖矩阵:让"遗漏"无处藏身
覆盖率门禁的基础设施是一张模块覆盖矩阵。它在 Phase 1 侦察结束时生成,贯穿整个审计生命周期。
例如:矩阵
| # | 模块路径 | LOC | EALOC | Controller数 | 风险评估 | 分配 Agent | Phase2 状态 | Phase3 状态 ||---|---------|-----|-------|-------------|---------|-----------|------------|------------|| 1 | module-auth | 8,000 | 5,200 | 6 | HIGH | Agent 1 | 完成 | 完成 || 2 | module-gateway | 12,000 | 7,800 | 8 | HIGH | Agent 2 | 完成 | 进行中 || 3 | module-biz | 131,000 | 37,700 | 40 | HIGH | Agent 3a~3c | 部分完成(需补扫) | 未开始 || 4 | module-common | 3,000 | 600 | 0 | LOW | Agent 4 | 完成 | 未开始 || 5 | module-parent | 0 | 0 | 0 | - | - | 跳过 纯POM | - |
每个含代码的模块都必须有一行。 包括那些"看起来不重要"的工具模块。纯父 POM、无代码模块标记为 跳过 并注明原因,但不能直接省略——省略了就没人知道它被跳过了。
大模块必须拆分追踪。 当一个模块的 EALOC 超过单 Agent 预算(15,000),它会被拆成多个子任务。矩阵里需要额外的拆分追踪表:
### module-biz (131K LOC → 3 个 Agent)| 子任务 | Agent | 文件范围 | 文件数 | 状态 | 覆盖率 ||--------|-------|---------|-------|------|-------|| 3a | Agent 3a | controller/ + service/ | 147 | 完成 | 100% || 3b | Agent 3b | dao/ + mapper/ + util/ | 200 | 完成 | 100% || 3c | Agent 3c | entity/ + vo/ + query/ | 500 | 部分完成 | 87% |
Agent 3c 覆盖率只有 87%——这意味着有 65 个文件没被审阅。门禁会立即为这 65 个文件启动补扫 Agent,而不是等到所有模块都审完才发现。
状态必须实时更新。 不是审完所有模块再统一填表,而是每完成一个 Agent 的审计就立即更新对应行。这样任何时候看矩阵,都能知道当前进度和缺口在哪。
文件级覆盖率:比模块级更细的网
模块级覆盖率能防止整个模块被遗漏,但还不够。一个模块标记为 完成,不代表里面每个文件都被审过——Agent 可能声称"完成了 module-auth 的审计",但实际上只读了 Controller 层,跳过了 Filter 和配置文件。
所以每个 Agent 的输出必须包含一份审阅文件清单:
| # | 文件路径 | Tier | 状态 | 发现数 ||---|---------|------|------|-------|| 1 | AuthController.java | T1 | 完成 已审阅 | 2 || 2 | ShiroConfig.java | T1 | 完成 已审阅 | 1 || 3 | UserServiceImpl.java | T2 | 完成 已审阅 | 0 || 4 | User.java | T3 | 完成 已审阅 | 0 || 5 | com/alibaba/fastjson/JSON.java | SKIP | 跳过 第三方库 | - |
门禁检查时,拿这份清单和 find 命令的实际文件列表做 diff。清单里没出现的文件 = 漏审。这是对抗 LLM "虚假覆盖"的最后一道防线。
在实际审计开源项目时发现一个有意思的现象:LLM Agent 在声称 100% 覆盖时,实际覆盖率通常在 70-85% 之间。缺口主要集中在 T3 层(Entity/VO)和配置文件——恰好是 LLM 觉得"不重要"的部分。没有文件级追踪,这种系统性遗漏很难被发现。
门禁判断逻辑
收到每个 Agent 结果后立即执行:1. 读取 Agent 输出的「文件统计」和「审阅文件清单」2. 与实际文件列表交叉验证3. 覆盖率 = 100% → 该 Agent 通过覆盖率 < 100% → 立即为未覆盖文件启动补扫 Agent(不等其他 Agent 完成)4. 更新覆盖矩阵所有 Agent 完成后:全部模块 Phase2 = 完成 → 进入 Phase 3存在 未开始 或 部分完成 → 启动补充 Agent → 重新过门禁 → 循环直到 100%禁止在覆盖率 < 100% 时进入 Phase 3。没有例外。
"没有发现也是有效结果"——这个是关键。即使一个模块完全安全,也必须在记录里留下"已审阅,无发现",而不是静默跳过。这个设计防止了"选择性遗忘":审计员(无论是人还是 AI)总是倾向于跳过看起来不重要的模块。没有显式的"无发现"记录,你根本就分不清"确认安全"和"压根没审"。
禁止在覆盖率 < 100% 时进入 Phase 3。没有例外。
反幻觉机制:5条铁律(解决"编代码、造行号"的致命误报)
覆盖率门禁解决了LLM"漏审"的核心问题,但LLM做代码审计还有另一个致命风险——幻觉:编造不存在的代码片段、错误的行号、虚假的调用链。一份充满假阳性的报告比漏报更糟,不仅会消耗开发团队的信任,还会让审计结果彻底失去参考价值。因此,在覆盖率达标的基础上,我们必须通过强制规则约束LLM的"编造欲",这就是5条反幻觉铁律的核心设计:
1. 报告漏洞前必须用 Glob/Read 验证文件存在
2. 代码片段必须来自实际 Read 输出,不得编造
3. 调用链每一跳必须标注 文件:行号
4. 不确定的发现标记为 Hypothesis,不得标记为 Confirmed
5. 宁可漏报,不可误报
第 4 条尤其重要传统审计报告只有"有漏洞"和"没漏洞"两种状态,但 AI 审计需要第三种状态 — Hypothesis(假设)。当 LLM 发现一个可疑模式但无法完全确认可利用性时(比如调用链中间有一跳追不到,或者不确定某个检测是否有效),标记为 Hypothesis 而不是硬说 Confirmed。这些 Hypothesis 需要人工验证,这样至少不会污染报告的可信度。
漏洞成立条件:告别"看到危险函数就报漏洞" -Phase 3
这个也是十分重要的因素,主要是为了避免"假阳性"的情况。
市面上大多数 AI 审计方案的逻辑是:看到 Runtime.exec() → 报命令注入。但实际情况远比这复杂。看到 JSON.parseObject() 就报 Fastjson 反序列化?那得先看版本号。看到 Velocity.evaluate() 就报 SSTI?那得先看 SecureUberspector 有没有配置。或者说一些就算是安全版本的组件可能他会直接忽视,但是可能咱自己有研究成果能绕过。例如:前段时间爆的Themleaf的绕过,就是针对安全版本的绕过。
一个好的审计方法论会为每类漏洞定义精确的成立条件判断表。以下是几个例子:
Fastjson 反序列化
发现 JSON.parseObject() / JSON.parse() 调用↓检查版本:< 1.2.68 → 直接可利用(多条公开利用链)1.2.68-1.2.80 → 检查 classpath 是否有特定依赖:groovy → 可利用jython + postgresql → 可利用aspectj → 可利用commons-io ≥ 2.x → 可利用≥ 1.2.83 → 检查 safeMode 配置:safeMode = true → 不可利用safeMode = false + autoType = true → 可利用safeMode = false + autoType = false → 需要进一步分析 expectClass 绕过
JNDI 注入
发现 InitialContext.lookup(userInput) 调用↓检查 JDK 版本:< 8u191 → 直接可利用(远程类加载)≥ 8u191 → trustURLCodebase 默认 false,需要本地 Gadget:classpath 有 Tomcat → BeanFactory + ELProcessor 可利用classpath 有 Groovy → GroovyClassLoader 可利用有 SecurityManager → 检查权限配置
Velocity SSTI
发现 Velocity.evaluate() / VelocityEngine.evaluate() 调用↓检查 SecureUberspector 配置:未配置 → 可利用(反射调用 Runtime.exec)已配置 → 检查自定义 Uberspector 是否有绕过↓检查模板内容来源:来自用户输入 → 可利用来自数据库(用户可写) → 可利用硬编码模板 → 不可利用(但检查是否有模板注入点)
这种精细度的判断,能够直接把"假阳性"率砍掉了一大截。但是这个就需要人为去主动维护。
DKTSS评分:更贴合实战的漏洞优先级标准-Phase 3
DKTSS(DarkKnight Threat Scoring System)的核心公式:
Score = Base - Friction + Weapon + VerBase Score 不是简单的"RCE = 10 分",而是按实际影响细分:
| 漏洞类型 | 条件 | Base |
|---|---|---|
| RCE / 反序列化 | 可执行系统命令 | 10 |
| SQL 注入 | 可脱库 / 可写文件 | 8 |
| SQL 注入 | 仅可读有限数据 | 6 |
| SSRF | 可访问内网 / 云元数据 | 7 |
| SSRF | 仅 HTTP 协议无回显 | 4 |
| 认证绕过 | 可访问管理后台 | 8 |
| XSS (Stored) | 可窃取 Cookie | 6 |
Friction(实战阻力) 是 DKTSS 与 CVSS 最大的差异。它把"利用难度"拆成三个独立维度:
访问路径:互联网(0) / 内网(-2) / 物理(-4)权限门槛:无需认证(0) / 低权限(-1) / 高权限(-3)交互复杂度:零交互(0) / 弱交互(-1) / 强交互(-3)
Weapon(武器化程度):有成熟 EXP(Metasploit/Nuclei 已集成)+1,仅有 PoC +0,纯理论/竞态条件 -2。
看一个实际案例:
漏洞:后台管理系统的 SQL 注入(可脱库)Base = 8(SQL 注入,可脱库)Friction = -3(需要管理员登录:权限门槛 -3)Weapon = +1(SQLMap 可直接利用)Ver = 0(当前版本)─────────────DKTSS = 8 - 3 + 1 + 0 = 6(Medium)CVSS 评分:8.8(High)
标准化漏洞报告:让每个漏洞都有完整证据链-Phase 3
Phase 3 漏洞验证完成后,每个确认的漏洞都需要按统一格式记录到文件中,也就是一定需要落地文件。这不是简单的"发现列表",而是最终报告的唯一数据源——Phase 5 生成报告时直接从落地文件中搬运,不允许从 Agent 原始输出中复制。
为什么需要标准化报告格式
传统 AI 审计的一个致命问题:报告质量参差不齐。同一个 LLM,今天给你一个完美的 PoC,明天连漏洞类型都标错。没有统一的输出标准,每次审计的报告格式都不一样,开发团队根本无法信任。
Skill 体系通过强制字段约束解决这个问题:每个漏洞必须包含 9 个必填字段组,缺少任何一个 = 验证不完整,禁止进入最终报告。这些必须字段也是代审人员以及攻防人员会关注的一些内容,也方便进一步确认漏洞真实性。
漏洞报告的9个必填字段
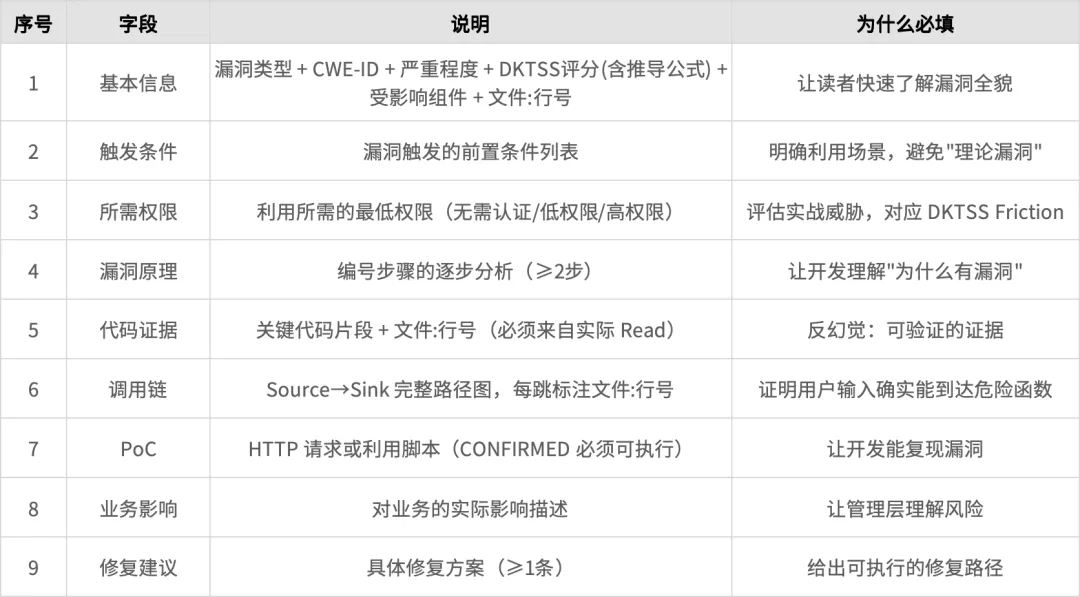
一个完整的漏洞报告示例
### VULN-001: Velocity SSTI 导致远程代码执行#### 基本信息| 属性 | 值 || -------------- | ------------------------------------------------------------ || **状态** | CONFIRMED || **漏洞类型** | 服务端模板注入 (SSTI) || **CWE-ID** | CWE-94 || **严重程度** | Critical || **DKTSS评分** | 9 (Base=10, Friction=-1, Weapon=0, Ver=0) || **受影响组件** | module-template-engine || **文件位置** | TemplateController.java:45 |#### 触发条件1. 应用使用 Velocity 模板引擎2. 用户可控的输入被直接传入 `Velocity.evaluate()`3. 未配置 SecureUberspector 或配置不当#### 所需权限无需认证(前台接口)#### 漏洞原理1. `TemplateController.renderTemplate()` 接收用户输入的 `template` 参数2. 直接将用户输入传入 `Velocity.evaluate(context, writer, "userTemplate", template)`3. Velocity 默认允许反射调用,攻击者可构造 `#set($x='')#set($rt=$x.class.forName('java.lang.Runtime'))` 执行任意代码#### 代码证据**TemplateController.java:45-52**```java@PostMapping("/render")public String renderTemplate(@RequestParam String template) {VelocityContext context = new VelocityContext();StringWriter writer = new StringWriter();// 危险:用户输入直接作为模板内容Velocity.evaluate(context, writer, "userTemplate", template);return writer.toString();}
调用链
用户输入 (template 参数)↓TemplateController.renderTemplate() [TemplateController.java:46]↓Velocity.evaluate() [velocity-1.7.jar]↓Runtime.getRuntime().exec() [通过反射调用]
PoC
POST /api/template/render HTTP/1.1Host: target.comContent-Type: application/x-www-form-urlencodedtemplate=%23set($x%3D%27%27)%23set($rt%3D$x.class.forName(%27java.lang.Runtime%27))%23set($chr%3D$x.class.forName(%27java.lang.Character%27))%23set($str%3D$x.class.forName(%27java.lang.String%27))%23set($ex%3D$rt.getRuntime().exec(%27whoami%27))
验证结果:成功执行 whoami 命令,返回当前用户名。
业务影响
攻击者可执行任意系统命令,完全控制服务器
可读取敏感配置文件(数据库密码、API密钥等)
可横向移动至内网其他系统
可植入后门实现持久化控制
修复建议
立即修复:配置 SecureUberspector 限制反射调用,例如:
VelocityEngine ve = new VelocityEngine();ve.setProperty("runtime.introspector.uberspect","org.apache.velocity.util.introspection.SecureUberspector");
架构优化:不要将用户输入直接作为模板内容,改用预定义模板 + 参数注入。例如:
// 安全做法Template template = ve.getTemplate("predefined-template.vm");context.put("userContent", sanitizedInput);template.merge(context, writer);
纵深防御:添加 WAF 规则检测 Velocity 注入特征(
#set、$rt.getRuntime())
在报告中也会提及之前提及的CONFIRMED和HYPOTHESIS。
### 9.5.4 CONFIRMED vs HYPOTHESIS 的区别| 状态 | 定义 | 要求 | 典型场景 ||------|------|------|---------|| **CONFIRMED** | 已验证可利用 | PoC 必须可执行,调用链完整,影响明确 | 成功执行 RCE、完成 SQL 注入脱库、绕过认证访问后台 || **HYPOTHESIS** | 疑似漏洞,需人工验证 | 发现可疑模式但无法完全确认 | 调用链中间有一跳追不到、不确定某个过滤是否有效、版本信息不明确 |**关键原则**:宁可标记为 HYPOTHESIS 让人工验证,也不要把不确定的发现标记为 CONFIRMED 污染报告可信度。
缺少任何必填字段 = 报告生成失败,强制回到 Phase 3 补充信息。
报告的价值:可信度+可复现性
标准化报告的核心价值不是"好看",而是:
可信度:9 个必填字段 + 字段完整性检查 = 每个漏洞都有完整证据链,开发团队不会质疑"这是不是 AI 编的"
可复现性:PoC + 调用链 + 代码证据 = 开发可以快速复现漏洞,而不是花一天时间理解"AI 到底在说什么"
可追溯性:文件:行号 + 版本信息 = 半年后回看报告,依然能定位到具体代码位置
可度量性:DKTSS 评分 + 业务影响 = 管理层可以量化风险,合理分配修复资源
没有标准化报告,AI 审计的输出就是"一次性消耗品"——看完就扔,无法沉淀、无法复用、无法信任。有了标准化报告,每次审计的产出都是"可交付的专业报告",这才是 AI 审计真正的价值。
剩余的一个Phase,Phase 5就不赘述了,并不是核心能力点。
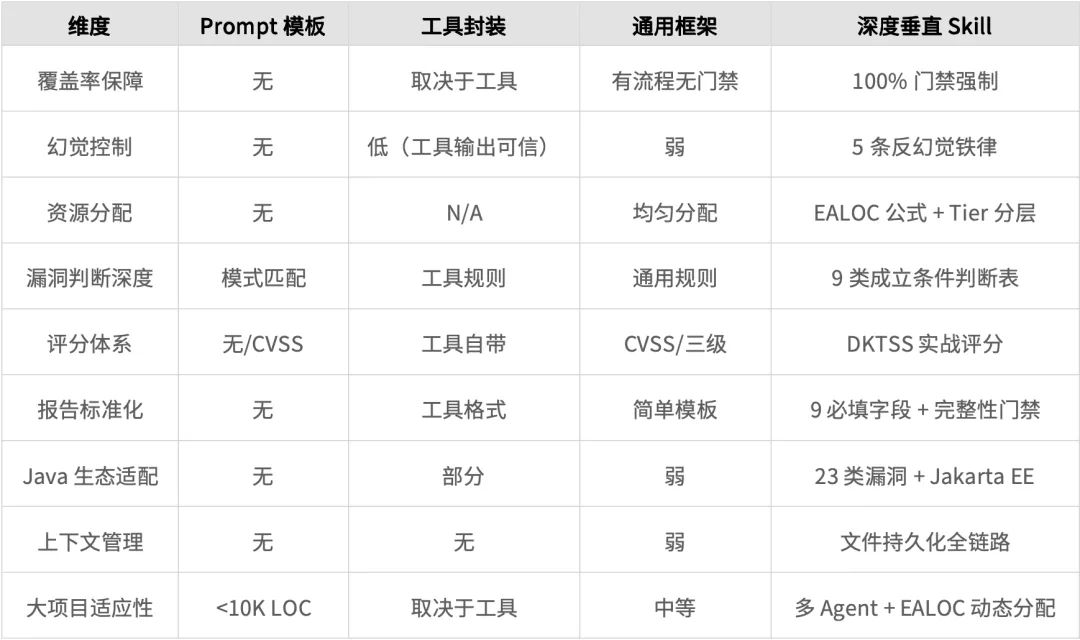
现有AI审计方案的不足与Skill体系的优势
Prompt 模板类
最常见的做法:写一个长 prompt,告诉 LLM"你是一个安全专家,请审计以下代码,关注 OWASP Top 10"。
问题很明显:没有流程控制、没有覆盖率保障、没有上下文管理、没有质量门禁。适合审计单个文件,面对企业级代码库基本不可用。
工具封装类
把 Semgrep、CodeQL 的输出喂给 LLM,让 LLM 做"结果解读"。比纯 prompt 好一些,但 LLM 只是在做翻译工作。静态分析工具能发现的漏洞类型是有限的——认证绕过、业务逻辑漏洞、竞态条件这些需要理解业务语义的漏洞,工具基本发现不了。LLM 最大的价值——理解代码语义——在这种方案里被浪费了。
通用审计框架类
一些更成熟的方案会定义审计流程,但通常存在几个共性问题:
语言无关导致深度不足:为了适配多种语言,只能定义通用流程,无法针对 Java 生态的特殊性做深度适配(MyBatis
${}注入、Spring Security 路径匹配器差异、Fastjson autoType、Jakarta EE 双命名空间等)缺少漏洞成立条件判断:发现一个
Velocity.evaluate()就报 SSTI,但没有检查 SecureUberspector 是否配置。大量假阳性缺少实战评分体系:要么用 CVSS(不贴合实战),要么用 High/Medium/Low 三级(太粗糙)
差异化总结
整体回顾:让AI审计从"靠运气"到"可复制"
全文拆解的这套Java代码审计Skill体系,核心逻辑可总结为"一个核心、一套流水线、六大关键设计",本质是把资深审计员的实战经验编码成LLM可执行的"审计协议":
一个核心:给LLM立"纪律"
LLM并非没有代码审计能力,而是缺少资深审计员的"工作方法和质量标准"。Skill的核心不是教LLM"什么是漏洞",而是把十几年实战沉淀的审计流程、资源分配、质量护栏编码成可执行的协议——让LLM的"知识储备"有"骨架"可依,从"天赋异禀但无章法"变成"专业且可控"。
一套流水线:6阶段闭环
Phase 0(代码库度量)→ Phase 1(项目侦察)→ Phase 2(三层审计架构)→ Phase 2.5(覆盖率门禁)→ Phase 3(漏洞验证+DKTSS评分)→ Phase 4(规则沉淀)→ Phase 5(标准化报告),每个阶段有明确的输入、输出和质量门禁,中间结果全量持久化解决上下文丢失问题,彻底告别"随机审计",实现"闭环可控"。
六大关键设计:精准解决核心痛点
EALOC+Tier分层:解决"大项目资源浪费"——70%低风险代码(如Entity)不做无效深挖,资源聚焦攻击面(T1)和核心逻辑(T2),削减67%Agent成本但不降低质量;
三层审计架构:机器扫(全覆盖)+AI审(双轨分析)+语义追(调用链验证),兼顾"广度"(不遗漏文件)与"深度"(不遗漏逻辑漏洞);
覆盖率门禁:100%文件级覆盖验证,杜绝LLM"选择性跳过",让"遗漏"无处藏身;
反幻觉铁律:5条规则约束编造行为,新增"Hypothesis"状态区分"不确定"与"确认",大幅降低误报率;
漏洞成立条件判断:告别"看到危险函数就报漏洞",按版本、配置、依赖精准判断可利用性,砍掉80%以上假阳性;
DKTSS评分:比CVSS更贴合实战,按"利用难度+实际影响"评分,让漏洞修复优先级更合理;
标准化报告:9个必填字段 + 完整性门禁,确保每个漏洞都有完整证据链(代码证据、调用链、PoC、修复建议),从"一次性消耗品"变成"可交付的专业报告"。
对从业者的启示
审计工程师无需恐惧AI:AI替代的是"重复扫模式、逐行读代码"的基础工作,而"设计审计流程、定义漏洞成立条件、维护Skill规则、人工验证Hypothesis"的核心能力,仍是人不可替代的;
未来方向:Skill需持续适配Java的生态变化(如Jakarta EE迁移、新漏洞利用链),结合多Agent协作、LSP语义分析等技术,让AI审计的精度和效率持续提升。
归根结底,这套Skill体系的价值不是"让AI替代人",而是"让人+AI的组合发挥最大效能"——人定规则、控质量,AI做重复、提效率,最终实现"日审百个项目、稳定挖0day"的实战目标。

-END-


