对于 Linux 操作系统而言,图形与显示系统是一套极为复杂且精妙的体系,它之所以能够如此 “神通广大”,关键在于依托OpenGL、Vulkan等标准化图形API,应用程序通过这些API即可表达图形绘制需求,比如复杂3D模型的绘制、高清视频的渲染等。与此同时,统一的内核驱动接口DRM/KMS承担着指令传递与硬件协调的作用,能够将应用程序的需求精准传递至底层硬件,同时协调硬件高效运行。只要硬件遵循DRM/KMS接口规范,就能与系统无缝对接,从而实现对各类硬件和显示协议的支持。
一、架构全景
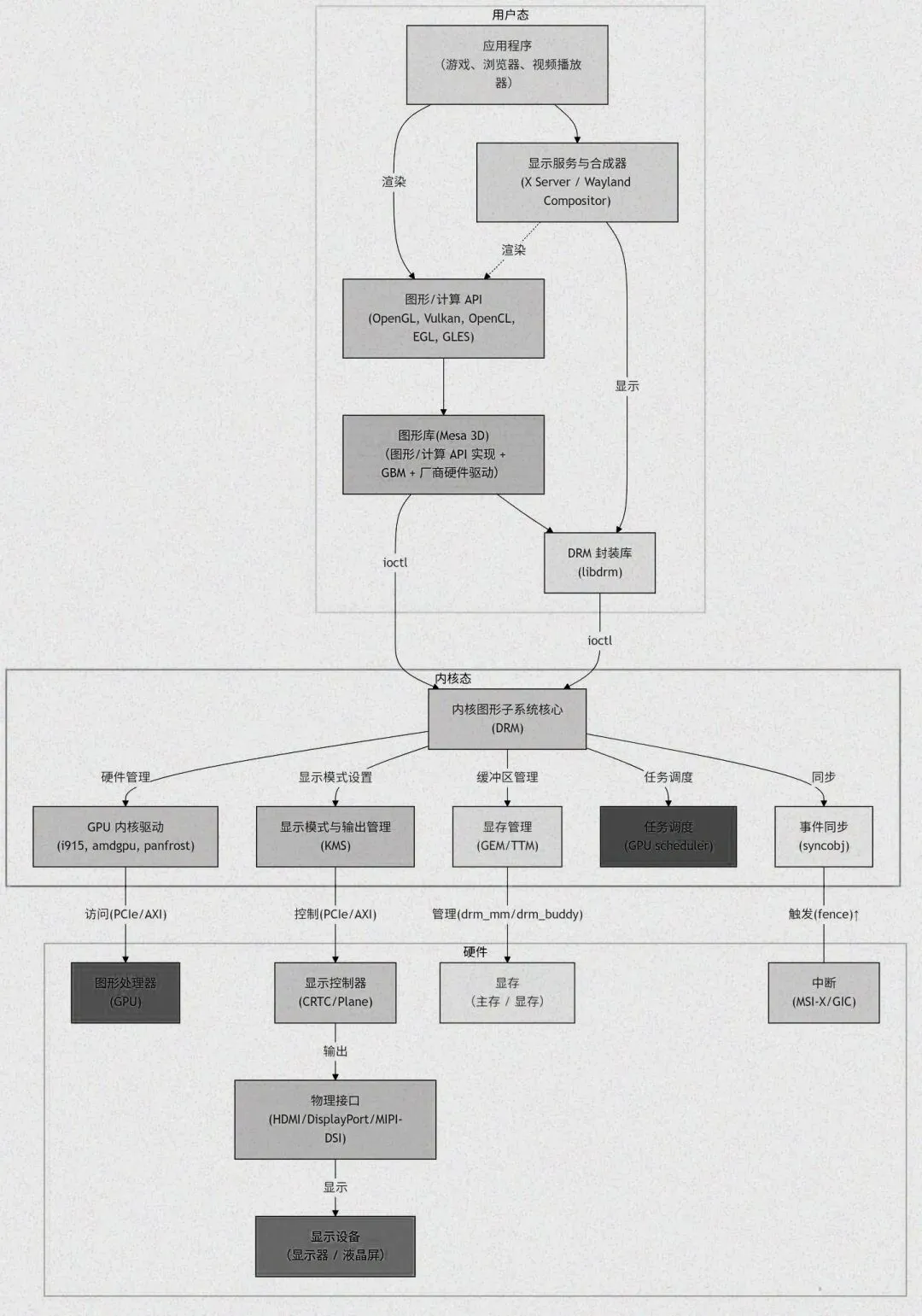
我们可以把 Linux 的图形栈想象成两个紧密合作的团队:用户态(User Space)和内核态(Kernel Space)。每个团队内部都有多个成员各司其职,而它们之间则通过一套可靠的‘对话机制’——主要是 ioctl 系统调用——来顺畅沟通。
1.1 用户态 (User Space) 与内核态 (Kernel Space) 分层设计
在Linux图形与显示系统的软件栈架构中,用户态与内核态的分层设计是系统高效、稳定运行的关键。这种分层模式实现了职责分工,各层协同完成复杂的图形处理和显示任务。
1.1.1 用户态职责:图形 API 实现、逻辑控制
用户态位于软件栈上层,直接面向应用程序,包含多个关键组件。其中,以Mesa 3D为代表的图形API库,主要负责将应用程序使用的OpenGL或Vulkan等图形API指令,转换为GPU能够理解的硬件指令。例如3D建模软件绘制复杂机械零件模型时,Mesa 3D会将软件发出的图形API指令,精准转换为GPU可执行的指令,明确图形绘制的具体要求。
显示服务器是用户态的核心组件之一,X11和Wayland是最常用的两种类型,主要负责窗口的创建、布局和销毁,同时处理鼠标点击、键盘输入等用户操作。比如同时打开多个应用窗口时,显示服务器会合理分配各窗口的屏幕位置和大小,方便用户操作;当用户在绘图软件中用鼠标绘制线条时,显示服务器会捕捉该操作,并传递给对应的应用程序进行处理。
DRM封装库则负责对底层DRM接口进行封装,为上层应用程序提供更简洁、易用的接口,降低应用程序与内核态交互的难度,方便应用程序获取所需的硬件资源和服务。
总体而言,用户态的核心职责是将应用程序的抽象渲染需求,转换为具体、可执行的硬件指令,同时处理窗口管理、用户交互等与用户直接相关的逻辑,为用户提供友好、高效的图形交互环境。
1.1.2 内核态职责:硬件抽象、资源管理
内核态位于软件栈底层,是硬件的直接管理者,核心组件包括DRM/KMS框架和硬件厂商驱动。
DRM/KMS框架是内核态的核心,承担着显存分配与管理、显示模式配置、GPU命令提交与中断响应等关键工作。在显存分配与管理方面,通过GEM(Graphics Execution Manager)和TTM(Translation Table Maps)等机制,实现显存资源的高效、安全分配与管理。当多个应用程序同时运行并需要使用显存时,GEM和TTM会根据各应用的需求,合理划分显存空间,避免资源冲突和浪费。
显示模式配置是DRM/KMS框架的重要功能,它会根据连接的显示设备特性,如分辨率、刷新率等,智能设置最佳显示模式,确保输出图像的显示效果达到最优。
在GPU命令提交与中断响应方面,DRM/KMS框架会将用户态传递的GPU指令准确提交给GPU执行;当GPU完成任务或出现异常时,框架会及时响应并处理相关中断信号,确保图像能够及时显示,保障系统稳定运行。
硬件厂商驱动是内核态与具体硬件设备之间的桥梁,根据不同厂商硬件的特性,实现对硬件的底层控制。例如NVIDIA的GPU驱动,能够充分发挥NVIDIA GPU的性能优势,为用户提供高质量的图形渲染效果。
内核态通过硬件抽象层,屏蔽了不同厂商硬件之间的差异,使得上层应用程序无需关注底层硬件的具体细节,只需通过统一接口即可操作不同硬件设备。同时,内核态还能保障多进程环境下的资源隔离和安全访问,避免因资源竞争导致系统崩溃或数据损坏。
1.2 通信机制:DRM IOCTL 接口详解
在Linux图形栈中,DRM IOCTL接口是用户态与内核态通信的核心桥梁,作为一种特殊的系统调用接口,承担着两者之间所有数据交互和指令传递的任务。
当用户态组件(如Mesa 3D)需要与内核态的DRM/KMS框架交互时,必须通过DRM IOCTL接口实现。例如渲染指令提交时,应用程序通过Mesa 3D发起3D场景渲染任务,Mesa 3D会将渲染指令封装为特定格式,通过DRM IOCTL接口传递给内核态的DRM/KMS框架,指令中包含顶点坐标、颜色、纹理等详细渲染信息。
显存缓冲区申请也需要通过DRM IOCTL接口完成。应用程序需要使用显存存储图形数据时,会通过Mesa 3D向DRM IOCTL接口发送申请请求;内核态的DRM/KMS框架收到请求后,会根据当前显存使用情况,通过GEM或TTM机制分配合适的显存缓冲区,并通过DRM IOCTL接口将结果返回给用户态。
显示模式设置同样依赖DRM IOCTL接口。当连接新显示器或更改显示模式时,用户态的显示服务器会通过DRM IOCTL接口,向内核态发送设置请求;内核态的DRM/KMS框架会根据请求调整显示模式,并将结果反馈给用户态。
DRM IOCTL接口提供了统一的调用规范,无论底层硬件属于哪个品牌、哪种型号,只要遵循该规范,用户态与内核态就能实现稳定、可靠的通信,保证了跨硬件平台的交互一致性,是连接图形栈上下层的关键组件,对Linux图形与显示系统的正常运行至关重要。
1.3 从宏观到微观的架构层次图解
为了让读者更直观地理解Linux图形栈的架构层次及各组件之间的协作关系,以下将详细拆解架构分层及数据流转过程。
最上层为应用层,是各类图形应用程序的运行空间,包括3D游戏、图形设计软件、视频播放器等。这些应用程序通过调用OpenGL、Vulkan等图形API,表达自身的图形绘制需求。
应用层之下是API层,核心组件为Mesa 3D,其主要功能是将应用程序的图形API调用,转换为具体的硬件指令,实现应用程序与GPU之间的指令适配。
显示服务层位于API层之下,包含X11、Wayland等显示服务器,主要负责窗口管理、用户输入事件处理,以及应用程序渲染结果的合成与显示。
再往下是内核态的DRM/KMS层:DRM框架为用户态提供统一的硬件访问接口,KMS负责显示功能的管理,包括显示器识别、显示模式设置等,是控制和管理硬件设备运行的核心层。
硬件驱动层位于DRM/KMS层之下,包含各硬件厂商提供的GPU/DPU驱动,直接与硬件设备交互,实现对硬件的底层控制。
最底层为GPU/显示设备层,是图形渲染和显示任务的实际执行层,GPU负责图形数据的处理与渲染,显示设备则将渲染后的图像呈现给用户。
数据流转路径清晰且有序:应用程序的渲染指令从应用层出发,经过API层转换后,传递至显示服务层,再通过DRM IOCTL接口进入内核态的DRM/KMS层和硬件驱动层,最终到达GPU/显示设备层进行处理和显示。各层组件协同配合,共同完成从渲染需求到图像显示的整个过程。
二、核心组件
2.1 DRM/KMS 框架
2.1.1 作为 Linux 图形显示的基石
DRM(Direct Rendering Manager,直接渲染管理器)是Linux内核图形驱动的核心框架,也是整个Linux图形显示系统的基础。它为用户态程序提供了直接与GPU硬件通信的通道,确保图形任务能够高效处理。
在Linux系统中,当多个程序同时需要使用GPU资源时,DRM的协调作用尤为重要。例如同时运行3D游戏和视频编辑软件时,3D游戏需要GPU渲染复杂场景,视频编辑软件需要GPU加速特效处理,DRM会合理分配GPU资源,确保两个程序有序使用,避免因资源冲突导致系统不稳定或崩溃。
KMS(Kernel Mode Setting,内核模式设置)是DRM框架的核心子模块,其核心作用是将显示模式配置功能从用户空间迁移至内核空间,这一改进带来了诸多优势。早期Linux图形系统中,显示模式配置由用户空间程序负责,稳定性差、用户体验不佳,且存在安全隐患;KMS的出现,有效解决了这些问题,提升了显示模式配置的可靠性和安全性。
KMS主要负责设置显示器的分辨率、刷新率、色彩深度等关键参数。例如连接新的4K显示器时,KMS会自动识别显示器参数,将系统显示模式配置为4K分辨率,并根据显示器特性合理设置刷新率和色彩深度,保障最佳视觉体验。
系统启动时,KMS能提前将显示器设置为合适的分辨率,避免了传统方式中从内核fbdev切换到用户空间显示程序时出现的屏幕闪烁问题,使启动画面与图形桌面的过渡更加流畅。此外,KMS将显示控制权限集中到内核,用户态程序无需以root权限直接操作硬件,只需通过DRM提供的标准ioctl接口发送请求即可,大幅降低了系统攻击面,提升了系统安全性。
2.1.2 模式设置 (KMS) 与内存管理 (GEM/TTM)
KMS在显示模式设置过程中,主要完成显示器枚举、显示参数配置等关键环节。显示器枚举是指KMS自动识别系统中连接的所有显示设备,包括普通液晶显示器、专业绘图显示器、投影仪等,并获取各设备的型号、支持的显示模式等信息。
获取显示器信息后,KMS会结合显示器的物理特性和用户使用需求,配置最合适的分辨率、刷新率和色彩深度。例如对于支持144Hz高刷新率的电竞显示器,KMS会优先将刷新率设置为144Hz,满足游戏玩家对高帧率的需求;同时根据显示器的最佳分辨率(如2560×1440)进行配置,确保画面清晰度和细节表现。
在显示管线中,KMS主要管理CRTC(显示控制器)、Encoder(编码器)和Connector(连接器)三个关键对象。CRTC负责将帧缓冲区中的图像数据,转换为显示器能够识别的信号;Encoder对CRTC输出的信号进行编码,使其能够通过HDMI、DP等接口传输至显示器;Connector是连接显示器与系统的物理接口,KMS通过对其进行管理,确保显示器与系统连接稳定可靠。
显存管理方面,GEM(Graphics Execution Manager)和TTM(Translation Table Maps)是两种常用的显存管理器,二者特性不同,适用于不同场景。
GEM设计简洁高效,主要适用于集成显卡的显存共享管理场景——这类场景中,系统内存与显卡共享,以满足图形处理需求。GEM通过普通、匿名的用户空间内存分配图形缓冲对象,这些缓冲区在必要时可交换出物理内存,提升内存使用的灵活性。例如系统内存紧张时,GEM会将暂时不用的图形缓冲对象交换至磁盘,释放物理内存供其他程序使用;需要时再将其交换回物理内存。这种管理方式还能使系统挂起和恢复时,通过恢复所有缓冲对象自动完成,提升系统响应速度和稳定性。
TTM更适用于独立显卡的复杂显存管理需求,它能够同时管理显存(VRAM)和系统内存(RAM),实现CPU/GPU内存空间的动态映射,还支持NUMA架构下的非对称内存访问。例如在多GPU环境中,TTM能根据各GPU的显存需求和访问模式,合理分配显存和系统内存,实现多GPU间的显存共享;同时支持PCIe BAR重映射,提升内存访问效率。在处理4K/8K纹理数据等大内存负载时,TTM能动态交换超过物理显存容量的数据,确保图形处理流畅进行。
2.1.3 跨硬件平台兼容性保障
DRM/KMS之所以能成为Linux图形显示系统的核心,关键在于其强大的跨硬件平台兼容性。
DRM/KMS通过标准化的硬件抽象接口,屏蔽了不同厂商GPU、显示控制器之间的硬件差异。不同厂商的GPU在内部架构、指令集、显存管理方式上可能存在显著差异,显示控制器的功能和接口也各不相同,但DRM/KMS提供了统一的接口规范,为各类硬件提供了一致的交互标准。
无论是Intel的集成显卡、AMD的独立显卡,还是ARM架构SoC中的GPU,DRM/KMS都能使其在Linux系统中正常运行。应用程序开发者无需深入了解每种硬件的具体细节,只需通过DRM/KMS提供的统一接口进行操作,即可控制不同的硬件设备,这大幅降低了跨平台开发的难度和成本,使开发者能够更专注于应用程序的功能实现和优化。
例如开发一款跨平台3D游戏时,开发者通过DRM/KMS接口实现图形渲染和显示功能,无论是在Intel显卡的笔记本、AMD显卡的台式机,还是ARM架构的嵌入式设备上,游戏都能通过DRM/KMS与底层硬件交互,实现高质量渲染和稳定显示,无需针对不同硬件编写大量适配代码。这种标准化的硬件抽象接口和资源管理机制,为同一套用户态代码在不同硬件平台上的运行提供了保障,也为Linux图形显示系统的广泛应用奠定了基础。
2.2 Mesa 3D
2.2.1 Gallium3D 架构与 OpenGL/Vulkan 驱动
Gallium3D是Mesa 3D的核心架构,其设计理念为图形驱动开发提供了全新思路,大幅提升了驱动开发的效率和灵活性。
Gallium3D的核心设计是将图形API逻辑与硬件驱动实现解耦,定义了统一的pipe_context和pipe_screen抽象接口,作为连接图形API与硬件驱动的桥梁。
从开发者角度来看,pipe_context抽象接口主要负责管理图形渲染的上下文环境,包含一系列与渲染相关的状态和操作。例如进行3D图形渲染时,pipe_context会记录当前的渲染状态,包括正在使用的纹理、着色器程序、顶点数据等。开发者通过操作pipe_context接口,即可方便地控制渲染过程中的各项参数和状态,无需关注底层硬件的具体实现。例如切换纹理时,只需调用pipe_context接口中的对应函数,即可完成操作。
pipe_screen抽象接口主要负责管理与屏幕相关的信息及操作,能够访问、设置显示器的分辨率、刷新率、显示模式等参数,同时负责图形设备资源(如显存)的分配和回收。例如应用程序需要获取当前显示器分辨率时,可通过pipe_screen接口实现;分配显存存储图形数据时,也可通过该接口完成。
这种抽象接口设计,使开发者在开发硬件后端驱动时,只需专注于实现硬件特定的功能,无需过多关注图形API的具体实现细节。例如开发NVIDIA GPU驱动时,开发者只需根据NVIDIA GPU的硬件特性,实现pipe_context和pipe_screen接口中与NVIDIA GPU相关的部分,即可使Mesa 3D支持NVIDIA GPU的OpenGL/Vulkan驱动。这不仅提高了驱动开发效率、降低了开发成本,还使Mesa 3D能够轻松支持OpenGL、Vulkan等多种图形API,提升了应用程序的兼容性。
2.2.2 连接上层 API 与底层内核驱动的枢纽
Mesa 3D在Linux图形显示系统中,承担着连接上层API与底层内核驱动的关键作用,是整个图形显示架构中不可或缺的中转组件。
Mesa 3D是一个开源的用户态图形驱动集合,其核心功能是将上层应用程序使用的OpenGL、Vulkan等图形API调用,准确转换为特定GPU能够理解的硬件指令。例如3D建模软件通过OpenGL API绘制复杂机械零件模型时,Mesa 3D会解析软件发送的OpenGL调用,将其中的绘图命令(如绘制三角形、四边形,设置颜色、纹理、光照等),转换为GPU可执行的具体硬件指令,这些指令包含顶点坐标、颜色值、纹理坐标等详细信息,GPU根据这些指令进行渲染,最终生成高质量的3D模型画面。
将图形API调用转换为硬件指令后,Mesa 3D需要将这些指令提交给内核驱动处理,此时libdrm封装库发挥作用。libdrm是专门为Linux内核DRM子系统提供支持的用户空间库,作为连接用户空间与内核空间的桥梁,Mesa 3D通过libdrm封装库调用DRM IOCTL接口,将生成的硬件指令提交至内核。DRM IOCTL接口作为用户态与内核态通信的核心通道,传递各类控制命令和数据;内核收到指令后,DRM/KMS框架会进一步处理、调度,将指令发送给对应的GPU硬件执行。
总体而言,Mesa 3D的核心作用是承上启下:将上层应用程序的抽象图形需求,转换为底层硬件可理解、可执行的具体指令,同时通过与libdrm、DRM/KMS的协同工作,确保指令能够顺利提交至内核并被GPU执行,保障整个图形显示流程的顺畅运行。
2.3 显示服务器与合成器
2.3.1 X11 架构及其局限性
X11(X Window System)是Linux图形显示系统中历史悠久、曾广泛应用的显示服务器架构,采用经典的客户端-服务器模型。在该模型中,X11服务器负责管理所有显示资源,客户端应用程序通过Xlib或XCB库与服务器通信,实现图形界面的绘制与交互。
X11架构的显著优势是网络透明性,即应用程序可以在远程服务器上运行,其图形界面能够在本地显示器上显示,与本地运行的应用程序体验一致。这种特性在远程办公、远程教学等场景中非常实用,例如远程办公时,员工通过网络连接公司服务器,在本地电脑上操作服务器上的应用程序,实现远程协作,提升工作灵活性和便捷性。
但随着技术发展和用户对图形显示性能要求的提升,X11架构的局限性逐渐凸显。多层级通信是导致其性能延迟的主要原因之一:应用程序产生的图形绘制请求,需要经过应用程序→Xlib/XCB库→X11服务器→图形硬件等多个层级的传递和处理,每一层级的传递都会消耗时间和系统资源,导致图形绘制延迟增加。例如进行实时视频会议时,可能出现画面卡顿、延迟等问题,影响沟通效果。
此外,X11自身不具备合成能力,要实现窗口透明、阴影等特效,必须依赖额外的扩展组件。这些扩展组件的工作方式通常是持续从X11服务器获取所有窗口内容,合成后再提交给显卡显示,这不仅增加了系统复杂性,还会导致窗口内容被多次复制、处理,进一步增加延迟和内存带宽占用。例如同时打开多个窗口进行切换时,可能出现闪烁、切换不流畅等问题,影响用户体验。
2.3.2 Wayland 协议与现代合成器优势
Wayland协议的出现,对Linux图形显示系统进行了革新,其采用扁平化架构,与传统X11架构有明显区别。在Wayland架构中,应用程序无需通过复杂的中间层与显示服务器通信,而是直接与合成器交互,大幅简化了图形显示流程,提升了运行效率。
现代合成器(如Weston、KWin)在Wayland协议的支持下,同时具备窗口管理和GPU加速合成功能。以KWin为例,在窗口管理方面,能够实现窗口的创建、布局、大小调整和销毁的智能管理,例如同时打开多个应用窗口时,KWin会根据用户操作习惯和屏幕空间,合理分配各窗口的位置和大小,方便用户进行多任务处理。在GPU加速合成方面,KWin能够充分利用GPU的计算能力,直接访问应用程序绘制好的缓冲区,通过零拷贝技术避免数据多次复制,大幅提升合成效率。例如播放高清视频时,KWin能快速将视频画面与其他窗口内容合成,保障播放流畅性。
Wayland协议原生支持V-Sync,这是其核心性能优势之一。V-Sync技术能够实现显示器刷新率与GPU渲染帧率的同步,有效消除画面撕裂。例如运行3D游戏时,若GPU渲染帧率高于显示器刷新率,容易出现画面撕裂,影响游戏体验;而Wayland的V-Sync功能通过与显示器同步信号的协同,使GPU在合适的时机进行渲染和画面更新,确保画面完整、流畅。
安全机制是Wayland的另一大优势。它通过严格的进程隔离机制,确保每个应用程序只能访问自身的图形缓冲区,无法获取其他应用程序的内容,有效防止恶意应用程序通过监听键盘、截屏等方式获取敏感信息,提升了系统安全性。例如处理金融、医疗等敏感数据时,Wayland的安全机制能够更好地保护数据安全和用户隐私。
2.3.3 LinuxFB 帧缓冲直通模式
LinuxFB(Linux Frame Buffer)是Linux图形显示系统中最基础的显示驱动模式,其工作原理简单,在特定场景中具有独特优势。
LinuxFB的工作方式十分直接:应用程序可以直接读写内核帧缓冲设备(通常为/dev/fb0),无需中间中转环节。例如应用程序需要显示图像时,直接将图像数据写入帧缓冲设备,显示设备再将这些数据呈现出来。这种直接操作方式使得LinuxFB架构简单,几乎没有额外的系统开销,资源占用极低。
正因为架构简单、资源占用低,LinuxFB非常适合嵌入式极简显示场景。例如工业控制领域的嵌入式设备,大多只需显示简单的文本信息或少量图形(如设备状态指示灯、简单操作菜单),对图形处理能力要求不高,LinuxFB能够满足这些需求,同时降低设备成本和功耗。
但LinuxFB也存在明显的局限性:它仅支持CPU软件渲染,图形绘制完全依赖CPU的计算能力。与GPU相比,CPU的图形处理能力较弱,尤其是处理复杂图形、高分辨率图像时,CPU的性能瓶颈会导致绘制速度缓慢,无法满足现代图形应用对实时性、流畅性的要求。例如播放高清视频时,可能出现卡顿、掉帧等问题,影响观看体验。
此外,LinuxFB不具备GPU加速和多窗口管理能力。现代图形应用中,GPU加速能够大幅提升图形处理效率和质量,实现更逼真的图形和流畅的动画;多窗口管理则是多任务处理的基础,方便用户同时运行多个应用并灵活切换。而LinuxFB缺乏这些功能,无法适应复杂图形应用和多任务场景的需求。
三、渲染与显示完整流程
3.1 应用层渲染指令生成
Linux图形显示系统中,渲染与显示是一个有序的完整过程,应用层渲染指令生成是整个流程的起点。当用户打开3D游戏、图形设计软件或播放高清视频时,这些应用程序会根据自身业务需求,生成相应的渲染指令,明确图形绘制的具体要求。
以3D游戏为例,游戏场景包含山川、河流、建筑、角色等各类元素,应用程序需要为每个元素定义形状、位置、颜色、纹理等属性。例如角色模型的渲染指令,会描述角色的骨骼结构、皮肤材质和动作动画:骨骼结构决定角色动作的灵活性,指令会控制骨骼的旋转、位移,实现奔跑、跳跃、攻击等动作;皮肤材质则涉及纹理的加载和映射,指令会指定纹理来源、分辨率,以及纹理在角色模型表面的映射方式,呈现逼真的皮肤效果。
这些渲染指令均基于OpenGL/Vulkan等标准图形API编写。OpenGL和Vulkan作为通用的图形API,为应用程序提供了统一的图形绘制规范,应用程序只需遵循这些规范,即可表达自身的绘制需求,无需关注底层硬件的具体实现。这种标准化特性使得应用程序具备良好的跨平台性,只要设备支持相应的API,即可在不同硬件设备上运行。
应用层渲染指令生成是图形显示流程的基础,直接决定了最终呈现在屏幕上的画面内容和质量,为后续的图形处理和显示提供了原始素材和核心指导。
3.2 图形 API 调用与 Mesa 处理
应用程序生成渲染指令后,会进入图形API调用与Mesa处理环节。应用程序通过调用图形API接口,将渲染指令传递给Mesa 3D,由Mesa 3D对指令进行一系列处理,转换为GPU可执行的指令。
Mesa 3D内部的Gallium3D架构,是处理图形API调用的核心。其中的状态跟踪器负责维护OpenGL状态机,记录当前的渲染状态,包括正在使用的纹理、着色器程序、顶点数据等。状态跟踪器会实时监控渲染状态的变化,将应用程序的API调用转换为标准化的、与硬件无关的命令。例如应用程序调用OpenGL函数切换纹理时,状态跟踪器会捕捉该操作,将其转换为Gallium3D内部的通用命令,并更新渲染状态。
这些通用命令能够被不同的硬件后端驱动理解,硬件后端驱动会将其进一步转换为特定GPU能够理解的指令集。例如NVIDIA GPU驱动会将通用命令转换为适配NVIDIA GPU架构的指令,充分发挥其性能优势;AMD GPU驱动则会将通用命令转换为AMD GPU可执行的指令,确保指令能够高效执行。
简单来说,Mesa 3D通过Gallium3D架构,将应用程序的图形API调用逐步转换为特定GPU的指令,为后续GPU执行渲染任务做好准备,是连接应用程序与GPU硬件的重要桥梁。
3.3 渲染指令提交与 GPU 执行
经过Mesa 3D处理后,渲染指令已转换为特定GPU能够理解的指令集,接下来进入渲染指令提交与GPU执行环节。Mesa 3D通过libdrm调用DRM IOCTL接口,将转换后的GPU指令提交至内核态的DRM框架。
DRM框架在这一过程中承担着审核与调度的职责。首先,DRM框架会对提交的指令进行合法性校验,确保指令格式正确、参数合理,无潜在错误或风险,避免非法指令影响渲染流程的正常进行。校验通过后,DRM框架会根据系统资源使用情况,合理调度指令,结合GPU当前负载、显存使用状态等因素,将指令安排在合适的时间和资源上处理,确保系统高效运行。
指令通过DRM框架的审核与调度后,会下发给GPU执行。GPU作为强大的并行计算硬件,拥有多个计算核心和高速内存带宽,能够充分利用并行计算能力,高效处理渲染指令。例如处理3D场景渲染时,GPU会并行计算每个像素的颜色、光照等信息,通过复杂算法和高速运算,快速生成图像数据,将抽象的渲染指令转换为具体的图像信息,为后续显示环节提供高质量的图像数据。
3.4 多图层合成与显示控制器处理
GPU完成渲染计算后,生成的图像数据会存储在显存缓冲区中。此时,显存缓冲区中可能包含多个应用程序的图像数据,每个应用程序对应独立的窗口和图层,需要通过多图层合成与显示控制器处理,将这些图像数据组合成完整的画面。
显示服务器或合成器负责多图层的合成工作,根据窗口的层级关系,对多个应用的图层数据进行混合、叠加处理。例如同时打开浏览器、音乐播放器和文档编辑器时,显示服务器会根据各窗口的前后顺序和大小,合理组合图层,上层窗口覆盖下层窗口,同时处理窗口的透明度、阴影等效果,确保合成后的画面真实、美观。
合成后的帧数据会传递给显示控制器(DPU/VOP),由显示控制器进行进一步的图像后处理。常见的后处理操作包括色彩校正、图像增强等:色彩校正用于调整画面的亮度、对比度和色彩饱和度,使颜色更鲜艳、逼真;图像增强用于去除画面中的噪点、模糊等瑕疵,提升画面清晰度和质量。例如播放高清视频时,显示控制器会对视频帧进行优化,确保画面流畅、稳定,提升用户视觉体验。
3.5 V-Sync 时页面翻转与显示
显示控制器完成图像后处理后,进入最后的V-Sync页面翻转与显示环节。显示控制器会与显示器的垂直刷新信号(V-Sync)保持同步,确保画面更新时机与显示器刷新节奏一致。
显示器进行垂直刷新时,会存在一个短暂的间隙,显示控制器会在这个间隙完成显存缓冲区的页面翻转操作。显存缓冲区可理解为存储图像数据的“页面”,页面翻转就是将当前显示的缓冲区切换为存储新帧数据的缓冲区,确保显示器能够及时显示最新的画面。这一过程类似于电影院播放电影时切换胶片帧,通过快速切换实现连续的画面展示。
页面翻转完成后,帧数据会输出至编码器,转换为HDMI/DP等标准显示信号,这些信号能够被显示器识别和播放。最终,标准显示信号传输至显示器,将画面呈现在用户面前——无论是3D游戏的激烈场景,还是高清视频的细腻画面,都是通过这一流程实现的,为用户提供沉浸式的视觉体验。
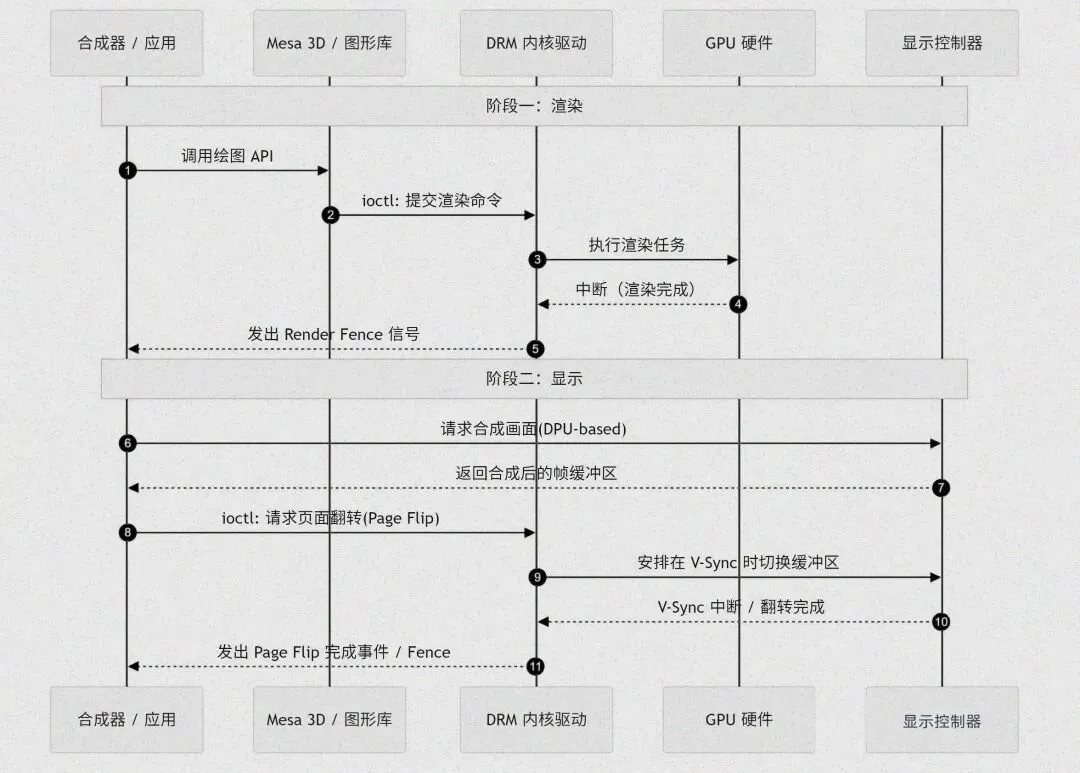
3.6 完整数据流转路径图解
为了让读者更直观地掌握从应用指令生成到屏幕显示的全链路数据流转过程,以下详细梳理各环节的数据流及组件交互方式。
首先,应用层的应用程序根据业务需求,生成基于OpenGL/Vulkan等图形API的渲染指令;随后,应用程序调用图形API接口,将渲染指令传递给Mesa 3D。
Mesa 3D通过Gallium3D架构的状态跟踪器,维护OpenGL状态机,将应用程序的API调用转换为标准化的、与硬件无关的命令;再由对应硬件后端驱动,将这些通用命令转换为特定GPU的指令集。之后,Mesa 3D通过libdrm调用DRM IOCTL接口,将转换后的GPU指令提交至内核态的DRM框架。
DRM框架对指令进行合法性校验和资源调度后,将指令下发给GPU;GPU完成并行化渲染计算,生成图像数据并存储在显存缓冲区中。
显示服务器/合成器根据窗口层级关系,对多个应用的图层数据进行混合、叠加处理,将合成后的帧数据传递给显示控制器(DPU/VOP)。显示控制器对帧数据进行图像后处理,同步显示器的垂直刷新信号(V-Sync),在刷新间隙完成显存缓冲区的页面翻转。
最后,合成后的帧数据输出至编码器,转换为HDMI/DP等标准显示信号,最终呈现在屏幕上。
通过这一数据流转路径,读者能够清晰了解各环节的核心组件及交互方式,深入掌握渲染与显示的协同工作机制,进一步理解Linux图形显示系统的工作原理。
四、SoC 与 PC 平台架构差异
4.1 内存架构对比
SoC平台采用统一内存架构,CPU、GPU、VPU等核心组件共享同一块物理内存。这种架构无需为每个核心组件单独分配显存,不仅降低了显存分配的复杂性和资源浪费,还大幅减少了数据访问延迟。
以手机、平板电脑等移动设备为例,使用相机应用拍照时,SoC中的VPU(视频处理单元)会实时处理拍摄的图像(如降噪、色彩校正),处理后的图像数据直接存储在共享内存中,GPU可直接读取这些数据进行渲染显示,无需进行繁琐的数据拷贝,有效提升了图像渲染的速度和用户体验。
PC平台则大多采用独立显存架构,GPU拥有专属的显存。GPU处理图形数据时,需要先从系统内存读取数据,再将数据拷贝至自身显存中进行处理。例如运行大型3D游戏时,游戏的场景模型、纹理等数据先存储在系统内存中,GPU渲染时再将这些数据拷贝至显存,这种拷贝操作会产生额外的系统开销,耗时且占用资源。随着游戏画面复杂度提升、数据量增大,拷贝开销会进一步增加,可能导致游戏帧率下降、画面卡顿,影响使用体验。
4.2 组件集成度差异
SoC平台的核心特点是高度集成,CPU、GPU、显示控制器、编解码器等核心组件均集成在一个芯片内,这些组件通过内部高速总线(如AXI总线)实现紧密连接,数据传输速度快,能够高效协同工作。
这种高度集成的设计,使得SoC平台体积小、功耗低,非常适合对体积和功耗有严格要求的嵌入式设备。例如智能手表、智能音箱等物联网设备,SoC芯片能够在有限的空间内,提供完整的计算、图形处理和显示控制功能,同时保持低功耗,延长设备续航时间。
PC平台的组件则相对独立,GPU、显示器等外设通过PCIe、HDMI等接口与主板连接。这种设计使得PC平台具备较强的扩展性,用户可以根据自身需求,灵活选择、更换不同性能的组件,例如根据预算和使用场景,选择合适的GPU、显示器,满足游戏、图形设计、办公等不同需求。
但独立组件设计也存在不足:数据在不同组件之间的传输路径相对复杂,需要经过多个接口和总线,可能导致传输延迟增加,影响系统整体性能;同时,独立组件会使PC的体积更大、功耗更高,不适用于对便携性和功耗要求较高的场景。
4.3 功耗管理策略
4.3.1 SoC: 精细的 DVFS、时钟门控和功耗岛技术
SoC平台主要面向嵌入式场景,对功耗控制要求较高,因此采用了一系列精细的功耗管理技术,力求在保证性能的前提下,最大限度降低功耗。动态电压频率调节(DVFS)技术是其中的核心,能够根据系统负载变化,实时调整核心的工作频率和电压。
例如智能手表待机时,系统负载较低,DVFS会自动降低CPU和GPU的工作频率及供电电压——由于功耗与电压的平方、频率成正比,这种调整能够显著降低核心功耗,延长手表续航;当用户打开游戏应用时,系统负载增加,DVFS会迅速提高核心频率和电压,满足游戏的性能需求,确保游戏流畅运行。
时钟门控技术也是SoC常用的功耗管理手段,当核心模块处于闲置状态时,会关闭该模块的时钟信号,使其进入低功耗状态,几乎不消耗能量。例如手机的音频处理模块,当没有音频数据需要处理时,时钟门控会关闭该模块的时钟,降低功耗;一旦有新的音频数据到来,时钟信号立即恢复,模块快速投入工作,确保音频处理不延迟。
功耗岛技术则将芯片划分为多个独立的功耗区域,每个区域可根据负载情况独立控制供电和时钟,进一步提升功耗管理的精细化程度。例如当SoC中的某一功能模块(如相机模块)不使用时,可单独关闭该模块所在的功耗区域,避免不必要的能量消耗,同时不影响其他模块的正常运行。这种精细化的功耗管理技术,使得SoC平台能够在有限的电池容量下,实现更长的续航时间,满足嵌入式设备的使用需求。
4.3.2 PC: 粗放式管理与动态功耗调节结合
与SoC平台不同,PC平台主要面向桌面、工作站等场景,电源供应相对稳定,对功耗的敏感度低于嵌入式设备,因此其功耗管理策略相对粗放,以“性能优先、兼顾功耗”为核心,结合动态功耗调节技术,平衡性能与能耗。
PC平台的功耗管理主要依赖CPU和GPU自身的动态调节机制,以及系统层面的电源计划配置。例如Intel的SpeedStep、AMD的Cool'n'Quiet技术,都是CPU层面的动态功耗调节技术,能够根据CPU的负载变化,自动调整工作频率和电压——当PC处于办公、浏览网页等轻负载场景时,CPU自动降频降压,降低功耗;当运行大型游戏、视频渲染等重负载任务时,CPU自动升频升压,全力释放性能。
GPU层面,NVIDIA的Max-Q、AMD的PowerPlay技术,同样能根据GPU的负载动态调整功耗。例如播放普通视频时,GPU处于低功耗模式,仅维持基础的图形渲染需求;运行3A游戏时,GPU自动提升功耗上限,充分发挥硬件性能,确保游戏流畅运行。但这种调节的精细化程度远低于SoC平台,无法实现像功耗岛那样的独立模块功耗控制。
系统层面,PC的电源计划(如Windows的平衡、高性能、节能模式,Linux的powertop工具)为用户提供了简单的功耗调节选项。用户可根据使用场景手动选择:高性能模式下,系统优先保障性能,功耗相对较高,适合游戏、专业渲染等场景;节能模式下,系统强制降低各硬件的运行频率,限制性能输出,以降低功耗,适合笔记本电脑未接电源时使用;平衡模式则兼顾性能与功耗,适用于日常办公、浏览等大多数场景。
此外,PC平台还会通过硬件层面的散热设计辅助功耗控制,例如增加散热风扇、散热鳍片,或采用水冷散热方案。当硬件功耗升高、温度上升时,散热系统自动提速,及时排出热量,避免硬件因过热降频,确保性能稳定输出。但这种方式本质上是被动适配功耗变化,而非主动精细化控制功耗,与SoC平台的功耗管理思路有明显区别。
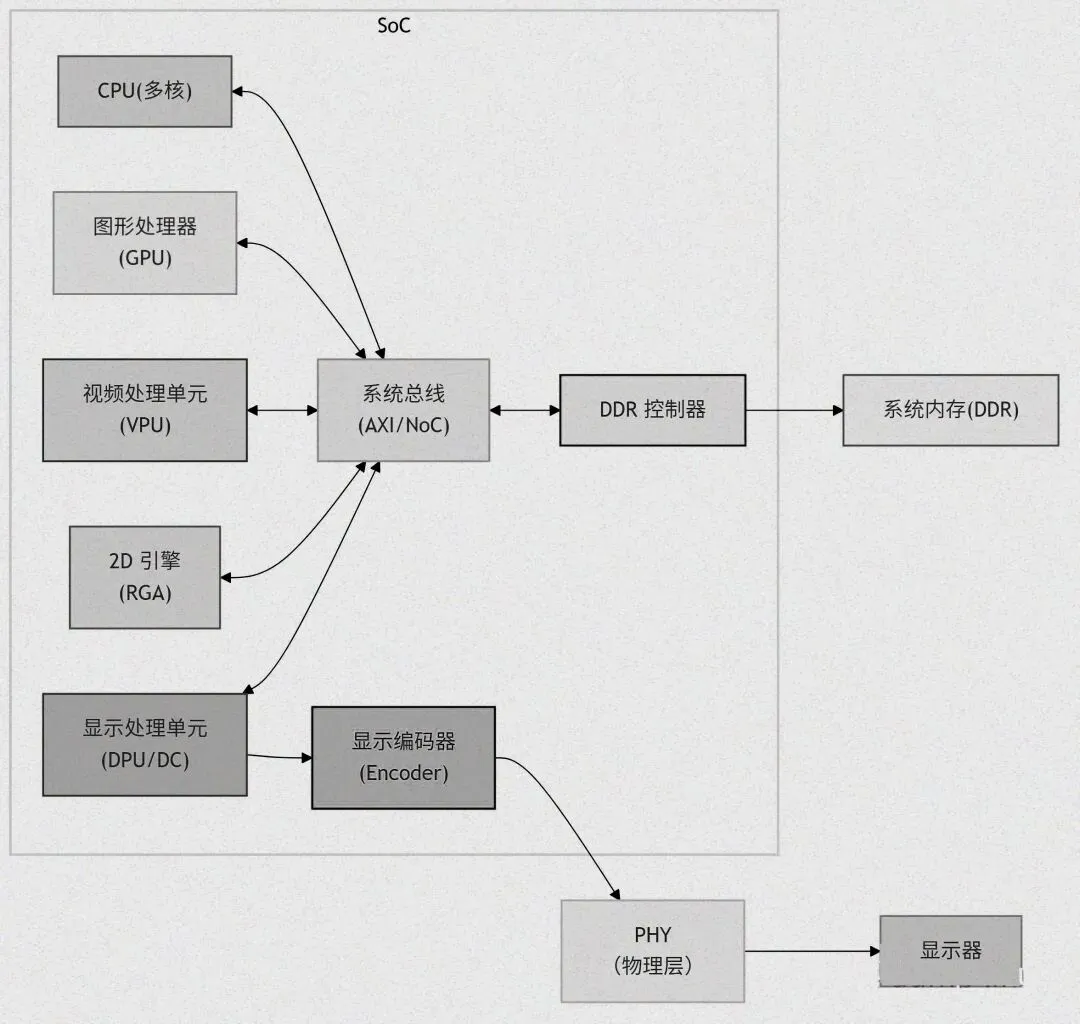
4.4 SoC 硬件连接拓扑(以典型嵌入式平台为例)
典型嵌入式SoC平台的硬件连接拓扑呈现高度集成、精简高效的特点,核心组件通过内部高速总线连接,减少外部接口,降低功耗和体积,适配嵌入式设备的使用需求。
以常见的ARM架构SoC为例,核心组件包括CPU集群(如Cortex-A系列)、GPU(如Mali系列)、显示控制器(DPU/VOP)、编解码器(VPU)、内存控制器、外设接口控制器等,所有组件均集成在单一芯片内,通过AXI/AHB等内部高速总线实现数据交互。其中,AXI总线作为高性能总线,负责CPU、GPU、内存控制器等高速组件之间的高速数据传输,确保图形渲染、视频处理等任务的高效进行;AHB总线则负责连接低速外设,如UART、I2C等,保障基础外设的正常工作。
内存控制器直接与共享内存连接,CPU、GPU、VPU等组件通过内存控制器访问共享内存,无需额外的接口转换,大幅减少数据传输延迟。例如GPU渲染图像时,可通过内存控制器直接读取共享内存中的纹理数据、顶点数据,处理完成后再将图像数据写回共享内存,整个过程无需数据拷贝,提升了渲染效率,同时降低了功耗。
显示控制器(DPU/VOP)通过内部总线与GPU、内存控制器连接,直接从共享内存中读取合成后的帧数据,经过色彩校正、图像增强等后处理后,通过HDMI、LVDS等外部显示接口输出至显示器。编解码器(VPU)与GPU、内存控制器协同工作,负责视频的编码与解码,处理后的视频数据可直接存储在共享内存中,供GPU渲染显示,实现视频播放、录制等功能。
此外,SoC还集成了GPIO、SPI等外设接口,用于连接触摸屏、摄像头、传感器等外部设备,满足嵌入式设备的多样化需求。这种高度集成的拓扑结构,使得SoC平台的硬件连接简单、数据传输高效,同时大幅降低了设备的体积和功耗,非常适合嵌入式、移动等场景的应用。
五、SoC硬件连接拓扑详解(以RK3588为例)
RK3588作为一款高性能ARM架构SoC,广泛应用于嵌入式、边缘计算、智能终端等场景,其硬件连接拓扑高度集成且布局合理,核心组件通过高速总线实现高效协同,充分发挥各模块的性能优势。
5.1 核心硬件模块关系
RK3588内部集成了CPU、GPU、DPU、VPU、RGA等多个核心功能模块,所有模块通过内部高速AXI总线(Advanced eXtensible Interface)实现互连,形成统一的系统架构,且所有核心模块共享同一块系统内存(LPDDR4/LPDDR5),大幅提升数据传输效率,减少数据拷贝开销。
从模块互连逻辑来看,CPU集群(采用ARM Cortex-A76+A55异构架构)作为系统核心,通过AXI总线与其他所有模块建立通信,负责全局任务调度、指令执行和资源管理;GPU(Mali-G610 MP4)作为图形渲染核心,直接与CPU、DPU、内存控制器连接,可快速获取CPU下发的渲染指令,读取内存中的纹理、顶点等数据,完成图形渲染后将结果传输至DPU进行后处理;DPU(显示处理单元)作为显示核心,连接GPU、VPU、RGA和TCON,负责图层合成、图像缩放等显示相关处理;VPU(视频编解码单元)与GPU、内存控制器互连,可快速读取内存中的视频数据进行编解码,也能将处理后的视频帧直接传输至DPU用于显示;RGA(图像加速单元)则与CPU、GPU、内存控制器连接,负责图像旋转、裁剪、色彩转换等轻量化图像处理任务,减轻GPU和CPU的负载。
AXI总线作为整个SoC的“数据高速公路”,采用多通道、高带宽设计,支持突发传输和乱序传输,能够满足CPU、GPU、DPU等模块同时进行高速数据交互的需求,避免总线成为性能瓶颈。例如GPU进行3D渲染时,可通过AXI总线快速从内存中读取纹理数据,同时将渲染完成的帧数据传输至DPU,整个过程无需CPU干预,大幅提升渲染和显示效率。
5.2 显示控制器(VOP)架构
RK3588的显示控制器(VOP,Video Output Processor)是显示链路的核心组件,采用多层叠加(Overlay/Alpha Blending)架构,支持多图层并行处理,能够实现复杂的显示效果,同时集成图层混合、缩放、色彩空间转换等功能,为高质量显示提供保障。
多层叠加(Overlay/Alpha Blending)是VOP的核心功能之一,RK3588的VOP支持最多8层图层叠加,每层可独立配置分辨率、像素格式、透明度等参数。不同图层对应不同的显示内容,例如底层为桌面背景图层,中间层为应用窗口图层,顶层为状态栏、弹窗等交互图层,VOP通过Alpha Blending技术将各图层按照预设的透明度和层级关系进行混合,最终生成完整的显示画面。这种架构的优势在于,不同应用的显示内容可独立渲染和更新,无需重新渲染整个画面,大幅降低系统负载,提升显示流畅度。
图层混合(Blender)与图像后处理模块是VOP的重要组成部分。图层混合模块负责将多个图层的像素数据按照Alpha通道值进行混合计算,确保图层叠加后的画面自然、过渡流畅,支持不同像素格式(如RGB、YUV)图层之间的混合,适配不同类型的显示内容;图像后处理模块则负责对混合后的画面进行优化,包括降噪、锐化、对比度调整等,提升画面显示质量。
缩放器(Scaler)与颜色空间转换器(CSC)是VOP实现多分辨率适配和色彩适配的关键模块。缩放器支持任意分辨率的缩放,能够将不同分辨率的图层(如4K应用窗口、1080P状态栏)缩放至统一的显示分辨率,确保画面无拉伸、无失真;颜色空间转换器则负责将不同颜色空间(如RGB、YUV420、YUV444)的图像数据转换为显示设备支持的颜色空间,解决不同模块输出数据的色彩适配问题,确保显示画面色彩准确、逼真。
RK3588的VOP通过内部总线与GPU、内存控制器、TCON直接连接,可快速读取内存中的图像数据和图层配置信息,完成处理后将数据传输至TCON,实现从图像数据到显示信号的转换,为后续显示输出做好准备。
5.3 时序控制器(TCON)功能
时序控制器(TCON,Timing Controller)是RK3588显示输出链路的关键组件,位于VOP与显示接口(HDMI、LVDS、eDP等)之间,核心功能是时钟生成与同步信号处理,确保显示信号与显示设备的时序要求一致,实现稳定、清晰的画面输出。
时钟生成是TCON的基础功能,TCON内部集成高精度时钟发生器,能够根据显示设备的分辨率和刷新率,生成对应的像素时钟、行同步时钟、场同步时钟等。不同显示设备的时序参数存在差异,例如4K@60Hz显示器的像素时钟约为594MHz,1080P@144Hz显示器的像素时钟约为240MHz,TCON可根据VOP下发的显示模式参数,自动生成匹配的时钟信号,确保显示数据的传输速率与显示设备的接收速率一致。
同步信号处理是TCON的核心职责,主要包括行同步(HSYNC)、场同步(VSYNC)信号的生成与校准。行同步信号用于控制显示设备逐行扫描像素,场同步信号用于控制显示设备逐帧更新画面,TCON通过精准控制同步信号的时序(如同步脉冲宽度、同步间隔),确保显示设备能够准确接收和解析VOP传输的图像数据,避免出现画面错位、撕裂、闪烁等问题。
此外,RK3588的TCON还支持多显示接口输出,可同时连接多个显示设备(如HDMI+LVDS双屏显示),并为每个显示设备独立生成时钟和同步信号,实现多屏同步显示。同时,TCON还具备信号缓冲和驱动功能,能够增强显示信号的驱动能力,延长信号传输距离,确保显示设备(尤其是大尺寸显示器、远距离连接的显示设备)能够稳定接收信号,提升显示可靠性。
六、LinuxFB、X11、Wayland 三大显示模式深度解析
6.1 三种显示模式核心特性对比
LinuxFB、X11、Wayland是Linux系统中最常用的三种显示模式,以下从架构、渲染方式、性能、安全性、适用场景五个维度,对三者进行全面对比。
| 对比维度 | LinuxFB | X11 | Wayland |
|---|
| 架构设计 | 极简帧缓冲直通模式,无分层设计,应用直接操作帧缓冲设备 | 客户端-服务器模型,多层级架构,应用→Xlib/XCB→X11服务器→硬件 | 扁平化架构,应用直接与合成器交互,无中间中转层 |
| 渲染方式 | 仅支持CPU软件渲染,无GPU加速能力 | 支持CPU软件渲染和GPU硬件渲染,需通过扩展实现合成功能 | 原生支持GPU加速合成,应用自主渲染,合成器负责图层叠加 |
| 性能表现 | 资源占用极低,无额外开销,但渲染效率低,不支持复杂图形 | 多层级通信导致延迟较高,多窗口合成开销大,存在画面撕裂风险 | 无中间层,延迟低,GPU加速合成效率高,原生支持V-Sync,无画面撕裂 |
| 安全性 | 无进程隔离,应用可直接访问帧缓冲,存在安全隐患 | 进程隔离较弱,应用可通过X11服务器获取其他应用窗口内容,安全性一般 | 严格进程隔离,应用仅能访问自身缓冲区,无法获取其他应用内容,安全性高 |
| 适用场景 | 嵌入式极简场景(如工业控制、智能手环),仅需显示简单文本/图形 | 传统桌面、远程办公场景,需兼容旧版应用,依赖X11扩展功能 | 现代桌面、高性能嵌入式场景,对延迟、安全性、流畅度要求高 |
6.2 开发实践:显示模式选型与性能优化
嵌入式极简场景(如工业控制终端、智能穿戴设备):优先选择LinuxFB。此类场景对图形处理需求低,仅需显示简单的文本、图标或状态信息,LinuxFB资源占用极低、架构简单的特点能够适配设备的低功耗、低配置需求。优化方向:关闭不必要的帧缓冲刷新,减少CPU占用;采用合适的像素格式(如8位灰度图),降低内存占用;避免频繁写入帧缓冲,减少系统开销。
传统桌面、远程办公场景(如办公电脑、服务器):优先选择X11。此类场景需兼容大量旧版应用,且依赖X11的网络透明性实现远程桌面功能,X11的生态兼容性能够满足需求。优化方向:启用GPU硬件加速,减少CPU渲染压力;优化X11服务器配置,减少多层级通信延迟;使用轻量化合成器(如Xfce compositor),降低合成开销;开启V-Sync功能,避免画面撕裂。
现代高性能场景(如3D游戏、高清视频播放、智能座舱):优先选择Wayland。此类场景对延迟、流畅度、安全性要求高,Wayland的扁平化架构和GPU加速合成能够大幅提升性能。优化方向:选择高性能合成器(如KWin、Weston),充分发挥GPU加速能力;优化应用渲染逻辑,减少渲染开销;合理配置显示模式(如匹配显示器刷新率),避免过度渲染;利用Wayland的原生特性,实现多屏协同、高分辨率适配等功能。
通用性能优化策略:无论选择哪种显示模式,都需注重图形渲染和显存管理的优化。优化渲染管线,减少不必要的渲染操作,如锥体剔除、遮挡剔除技术,剔除屏幕外或被遮挡的物体,减少渲染对象的数量;优化纹理加载和使用,采用纹理压缩技术,降低纹理内存占用和传输带宽,同时避免频繁切换纹理,减少GPU状态切换的开销;合理使用顶点缓冲对象(VBO)、索引缓冲对象(IBO),减少CPU与GPU之间的数据传输,提升渲染效率。
优化显存使用,避免显存带宽瓶颈。合理分配显存缓冲区,避免频繁创建和销毁缓冲区,采用缓冲区复用机制,提升显存使用效率;减少数据拷贝,利用零拷贝技术,直接访问显存缓冲区中的数据,避免CPU与GPU之间的冗余数据传输;对于大尺寸图像、视频帧,采用分块渲染的方式,降低单次渲染的显存占用,避免显存溢出。
此外,需适配显示模式的特性,开启V-Sync同步功能,避免画面撕裂,同时根据显示器的刷新率,合理设置渲染帧率,避免过度渲染导致的资源浪费。对于多窗口应用,合理管理窗口层级和渲染顺序,减少图层合成的开销,提升多窗口场景下的流畅度。
6.3 图形问题定位:常见故障排查方法
画面撕裂问题:优先排查V-Sync功能是否开启。若未开启V-Sync,需在应用或显示服务器中启用该功能,确保GPU渲染帧率与显示器刷新率同步;若已开启仍出现撕裂,需检查显卡驱动是否适配,是否存在驱动bug,可尝试更新显卡驱动或调整显示模式(如降低刷新率)。此外,还需排查合成器的配置,确保合成器正常工作,避免合成环节导致的撕裂。
画面卡顿、帧率过低问题:首先排查应用自身的渲染逻辑,是否存在不必要的渲染操作、显存使用不合理等问题,可通过工具(如glxinfo、vulkaninfo)分析应用的渲染性能,定位性能瓶颈;其次,检查GPU负载和显存使用情况,若GPU负载过高,需优化应用的渲染管线,减少渲染压力;若显存不足,需优化显存分配策略,释放冗余显存资源。此外,还需排查驱动是否正常,是否存在驱动未正确加载、驱动版本不兼容等问题。
显示异常(如黑屏、花屏、颜色失真)问题:首先检查硬件连接,确保显示器、显卡等硬件连接正常,无松动、接触不良等情况;其次,排查显示模式配置,是否存在分辨率、刷新率超出显示器支持范围的情况,可通过DRM工具(如drm-info)查看显示模式参数,调整为合适的显示模式;若硬件和显示模式均无问题,需排查显卡驱动,是否存在驱动bug、驱动与硬件不兼容等情况,可尝试重新安装、更新驱动,或切换至兼容的驱动版本。
驱动崩溃问题:首先查看系统日志(如dmesg、/var/log/syslog),获取驱动崩溃的错误信息,定位崩溃的具体环节(如显存管理、指令处理、显示模式切换);其次,检查驱动代码,是否存在逻辑错误、资源泄漏、非法访问等问题,针对性修复代码;此外,还需排查硬件是否存在故障,如显卡损坏、显存异常等,可通过硬件检测工具排查硬件问题。