本期文章,我们来深入学习 Linux proc 文件系统。1.proc 文件系统简介
proc 文件系统一种伪文件系统,文件内容存储在内存(不占用磁盘空间,不能永久存储)。它用于向用户空间暴露内核数据结构、进程状态及系统配置信息,是系统监控、调试与性能调优的核心工具。
proc文件系统的内核定义如下:
staticstructfile_system_typeproc_fs_type = { .name = "proc", .init_fs_context = proc_init_fs_context, .parameters = proc_fs_parameters, .kill_sb = proc_kill_sb, .fs_flags = FS_USERNS_MOUNT | FS_DISALLOW_NOTIFY_PERM,};
内核初始化过程中,initramfs init 脚本会挂载 proc 文件系统。proc 文件系统中常见的文件有:
(1)系统信息
- /proc/meminfo:内存总大小、空闲、缓存、Swap 等状态。
- /proc/uptime:系统启动总时间、空闲时间。
- /proc/filesystems:内核支持的文件系统列表。
- /proc/stat:系统整体 CPU 使用率、中断、进程切换统计。
- /proc/partitions:块设备与分区信息。
- /proc/mounts:当前已挂载文件系统列表。
(2)进程信息
- /proc/[PID]/cmdline:进程启动命令与参数。
- /proc/[PID]/maps:进程虚拟内存映射。
- /proc/[PID]/fd/:进程打开的文件描述符列表。
- /proc/[PID]/environ:进程环境变量。
- /proc/[PID]/limits:进程资源限制。
- /proc/[PID]/io:进程 I/O 统计。
- /proc/[PID]/sched:进程调度信息与优先级。
(3)网络信息
- /proc/net/dev:网卡流量、错误、丢包统计。
- /proc/net/sockstat:套接字使用统计。
2.从内核看 proc 文件系统
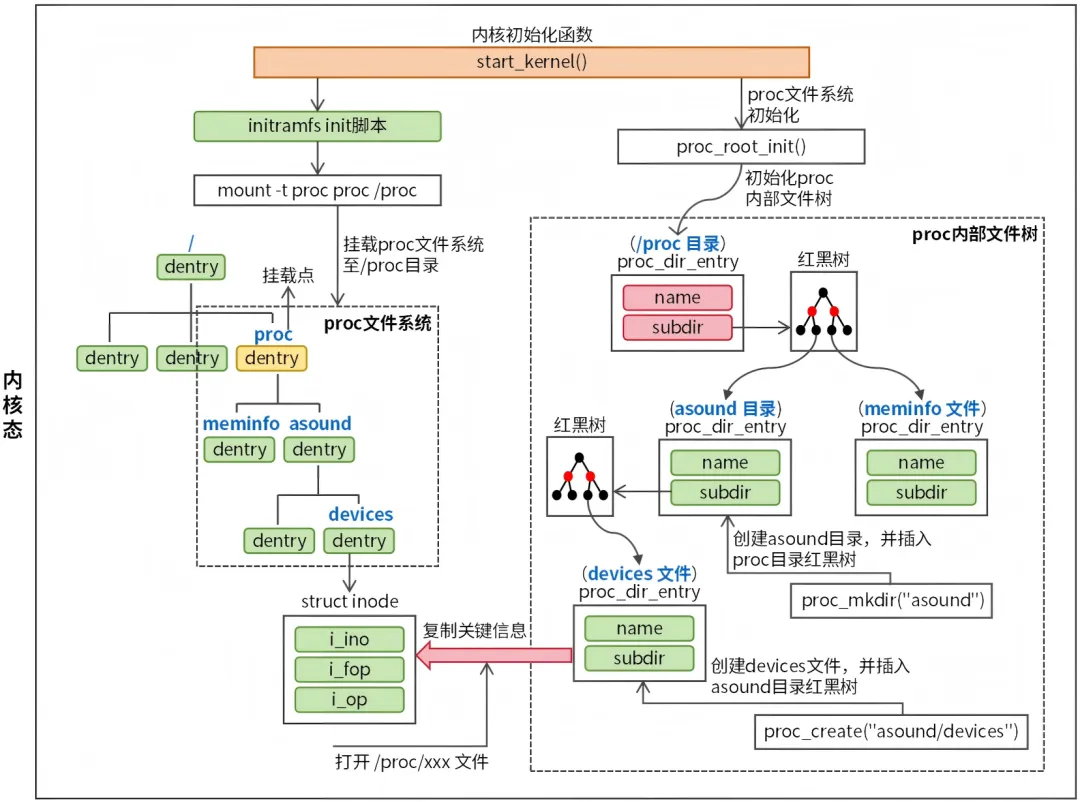
理解 proc 文件系统的关键在于理解 proc 文件系统内部树,所谓内部树是指独立于 VFS(虚拟文件系统)的文件树,具体情况如图1所示。
图1 proc 文件系统内核实现原理
内核初始化时会调用 start_kernel 函数,该函数会调用 proc_root_init 函数来初始化 proc 内部文件树。proc 内部文件树的节点类型(文件或目录)为 struct proc_dir_entry 结构,其定义如下:
structproc_dir_entry {conststructinode_operations *proc_iops;/* inode操作函数表 */union {conststructproc_ops *proc_ops;/* 内核5.6+新增proc专用文件操作函数表 */conststructfile_operations *proc_dir_ops;/* 文件操作函数表 */ };conststructdentry_operations *proc_dops;/* 目录项(dentry)操作函数表 */union {conststructseq_operations *seq_ops;/* seq_file操作函数表,用于复杂文件(多个记录)*/int (*single_show)(struct seq_file *, void *); /* 简单显示函数,用于简单文件(单个记录) */ };void *data; /* 私有数据指针 */nlink_t nlink; /* 硬链接数 */kuid_t uid; /* 用户 ID */kgid_t gid; /* 组 ID */loff_t size; /* 文件大小 */structproc_dir_entry *parent;/* 父目录指针,指向包含此节点的父目录 */structrb_rootsubdir;/* 子目录红黑树根 */structrb_nodesubdir_node;/* 红黑树节点,子节点插入父目录红黑树的节点 */char *name; /* 指向文件/目录名字符串 */umode_t mode; /* 表示文件类型和权限 */ u8 flags; /* 标志位 */ u8 namelen; /* 文件名长度 */ ......};
struct proc_dir_entry(简称 PDE)是 Linux 内核管理 /proc 文件系统所有节点(文件、目录、链接)的数据结构体,每个节点在内核中都对应一个PDE,PDE用于存储节点的名称、权限、所属目录、操作回调、私有数据等关键信息。
如果 PDE 是一个目录,那么 PDE 的 subdir 成员将会生效,subdir 是子节点(文件和目录)的红黑树根,子节点通过 PDE 的 subdir_node 成员插入父节点红黑树,这样就构成了树形结构。
proc 内部文件树的文件节点和 VFS(虚拟文件系统)中的文件是对应关系,proc 的文件由内核创建,内核通过 proc_mkdir 和 proc_create 函数来创建 proc 文件节点。当用户程序需要访问 proc 文件时,内核会基于 proc 文件节点动态生成 struct inode 结构,并将访问 proc 文件的方法(函数表)也赋值给inode。这样用户程序就能够通过 VFS 来访问 proc 文件了。
proc 内部文件树的根节点是 /proc 目录,它是一个特殊的PDE,其定义如下:
structproc_dir_entryproc_root = { .low_ino = PROC_ROOT_INO, .namelen = 5, .mode = S_IFDIR | S_IRUGO | S_IXUGO, .nlink = 2, .refcnt = REFCOUNT_INIT(1), .proc_iops = &proc_root_inode_operations, .proc_dir_ops = &proc_root_operations, .parent = &proc_root, .subdir = RB_ROOT, .name = "/proc",};
proc_root 是 Linux 内核中 /proc 文件系统根节点,所有 /proc 下的文件/目录都是挂载到这个根节点下的子节点,它是整个 proc 内部文件树的 “根”。
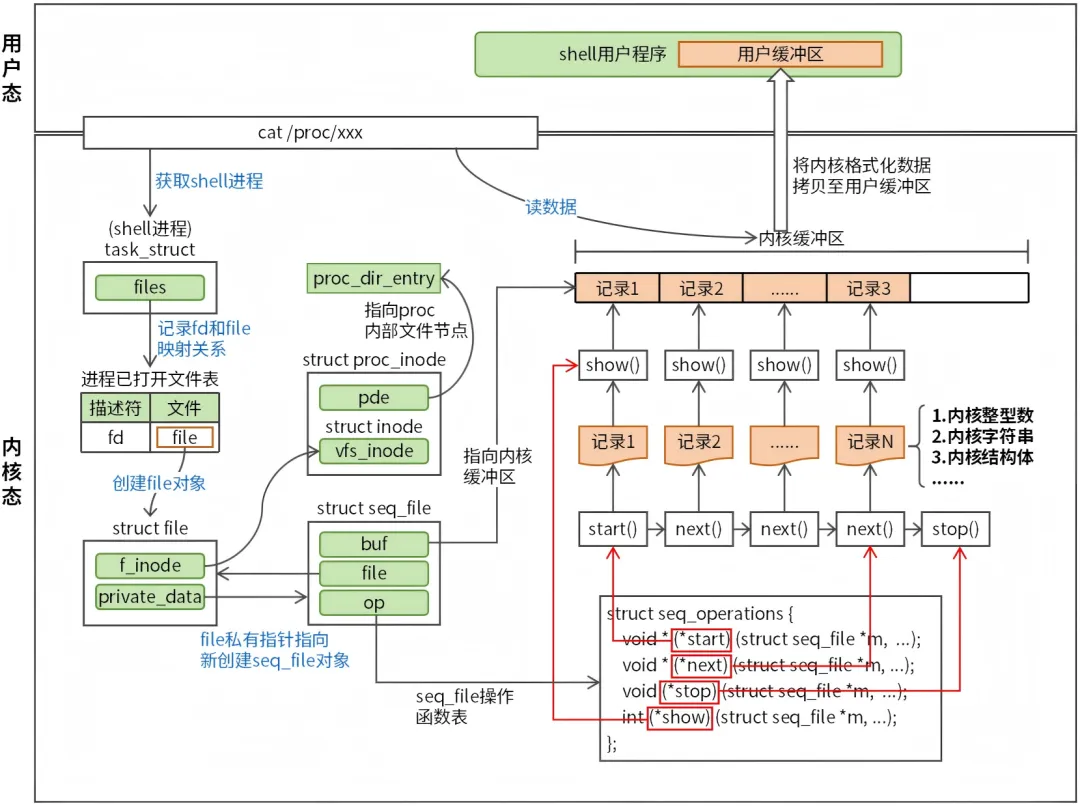
3.seq_file 机制
seq_file 是用于简化 /proc 文件的创建和读取操作的机制。它解决了传统 proc 文件处理中的缓冲区管理难题,提供了一种迭代式、分块输出的方式来生成动态内容。
seq_file 的核心数据结构为:
structseq_file {char *buf; // 输出缓冲区size_t size; // 缓冲区大小size_t from; // 用户空间已读取的位置size_t count; // buf 中有效数据量size_t pad_until; // 填充位置loff_t index; // 当前迭代位置loff_t read_pos; // 当前读取位置 u64 version; // 版本号structmutexlock;// 互斥锁conststructseq_operations *op;// 操作函数集int poll_event; // poll 事件conststructfile *file;// 关联的文件void *private; // 私有数据};
简单来说,seq_file 就是一个内核缓冲区,proc 文件中的数据需要先格式化输出到 seq_file 内核缓冲区,再拷贝至用户缓冲区。格式化输出的过程需要使用特定的方法,这种方法由 struct seq_operations 结构定义,如下:
structseq_operations {/* 遍历起始回调:找到第pos个数据节点(遍历的起点)*/void * (*start) (struct seq_file *m, loff_t *pos);/* 遍历结束回调:清理资源(解锁、释放内存等)*/void (*stop) (struct seq_file *m, void *v);/* 遍历下一个回调:获取当前节点的下一个节点 */void * (*next) (struct seq_file *m, void *v, loff_t *pos);/* 内容输出回调:将单个节点的数据格式化输出到seq_file缓冲区 */int (*show) (struct seq_file *m, void *v);};
seq_operations 的使用方式如图2所示。
图 2 seq_file机制
用户程序(shell)执行 cat /proc/xxx 命令查看 proc 文件时,首先会打开文件,打开文件的过程会创建 file 对象,然后将 file 对象的私有指针指向 proc 文件对应的 seq_file。接着,cat 命令会读取 proc 文件数据,读取的过程需要用到 seq_file 对象中的 op 函数表 (struct struct seq_operations),具体过程如下:
步骤1:调用 start 函数开始迭代,获取第一个数据项(整型数、字符串、结构体等),并调用 show 函数格式化输出该数据项至 seq_file 内核缓冲区。步骤2:调用 next 函数获取下一个数据项,并调用 show 函数格式化输出该数据项至 seq_file 内核缓冲区。步骤3:持续执行步骤2,直至所有数据项都格式化输出到 seq_file 内核缓冲区。步骤5::将 seq_file 收集到数据拷贝至用户缓冲区。
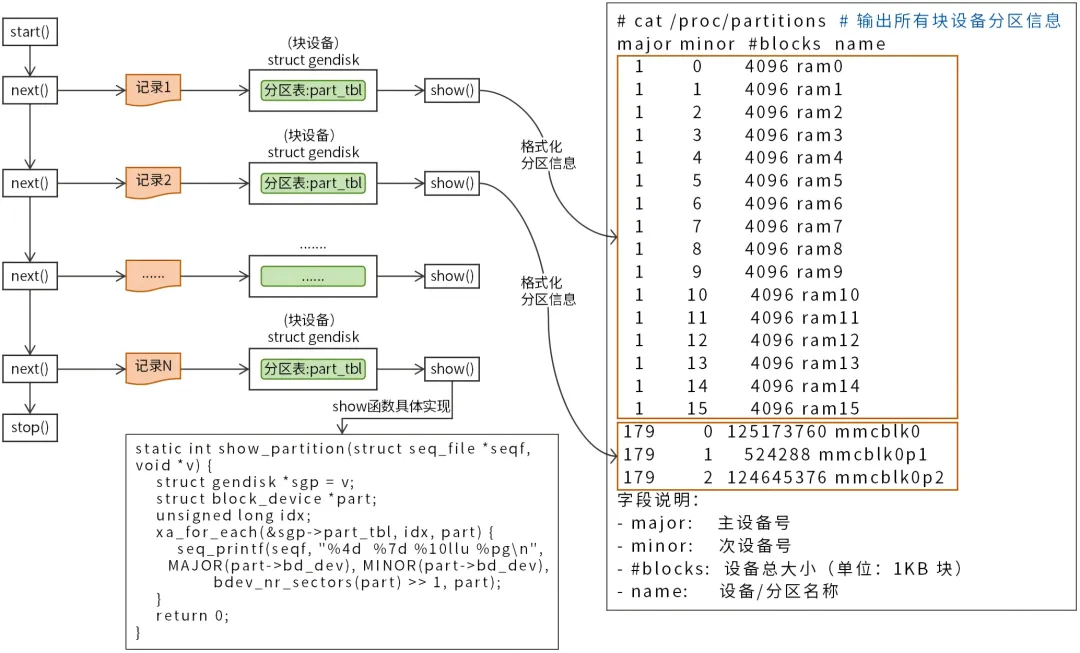
4. /proc/partitions 示例
我们以读取 /proc/partitions 文件为例,来进一步了解 proc 文件的读取过程。/proc/partitions 是 proc 文件系统中专门用于暴露系统块设备(磁盘 / 分区)信息的核心虚拟文件,如图3所示。
图3 读取 /proc/partitions 文件
/proc/partitions 文件的数据项是 struct gendisk 结构,struct gendisk(通用磁盘结构体)是 Linux 内核块设备子系统的核心数据结构,用于抽象和管理系统中所有块设备,定义如下:
structgendisk{int major; // 主设备号int first_minor; // 起始次设备号int minors; // 次设备号char disk_name[DISK_NAME_LEN]; // 磁盘名称structxarraypart_tbl;// 分区表structblock_device *part0;//主设备块设备对象 ......};
一台主机通常会有多个块设备,调用 start 函数后,内核会查询块设备列表,获取到第一个块设备。 接着,内核调用 show 函数格式化输出块设备信息,该场景下的 show 函数具体实现如下:staticintshow_partition(struct seq_file *seqf, void *v){structgendisk *sgp = v;structblock_device *part;unsignedlong idx; xa_for_each(&sgp->part_tbl, idx, part) { seq_printf(seqf, "%4d %7d %10llu %pg\n", MAJOR(part->bd_dev), MINOR(part->bd_dev), bdev_nr_sectors(part) >> 1, part); }return0;}
show 函数中循环(xa_for_each语言)格式化输出(调用 seq_printf 函数)每个分区的信息至 seq_file 内核缓冲区。一个块设备处理完毕后,调用 next 函数定位到下一个块设备,然后按照相同的方式处理下一个块设备,直至所有块设备的信息都格式化输出到 seq_file 内核缓冲区,最后将 seq_file 内核缓冲区的数据拷贝至用户缓冲区,用户程序就能够查看到内核的块设备分区信息了。我的新书《图解Linux网络编程》发布了,我对Linux网络编程的应用开发技术以及内核源码进行了深入的研究,并以图解方式创作了《图解Linux网络编程》这本书,如果你想系统性地学习Linux网络编程,从底层原理到上层应用彻底通关Linux网络编程,欢迎入手我的新书。
 10个月宝宝每天需要喝多少奶粉?
10个月宝宝每天需要喝多少奶粉?
