Python-EconML包:快速上手动态双重机器学习
- 2026-07-04 09:13:33
👇 连享会 · 推文导航 | www.lianxh.cn
连享会:2026五一论文班 · 线上时间:5月2-4日嘉宾:郭士祺 (上海交通大学)、戚树森 (厦门大学)、李学恒 (中山大学)咨询:王老师 18903405450(微信)

本次课程框架为:因果证据链的构建 → 在顶刊论文中感受和校准这套因果证据链判断 → AI Agent 辅助实现完成
从「会跑回归」到「会做研究设计」。 从 RCT 出发,覆盖 DID、固定效应、工具变量的识别逻辑与论证策略,重点不在方法本身,而在于如何围绕一个研究问题构建完整的因果证据链——这是 AI 替代不了、也最值得花时间打磨的核心能力。
顶刊论文,原作者精讲。 戚树森老师亲自讲解自己参与完成的 Review of Finance 论文,覆盖选题缘起、识别策略设计、审稿意见的回应过程——不只是呈现结果,而是还原论文背后真实的决策过程。
用 AI Agent 真正解放执行环节。 学完这门课,你将掌握两套可以直接上手的 AI Agent 工作流——文献综述和论文修改——并理解如何把自己的研究方法论写成 Skill,让 Agent 按照你的标准自动执行,而不是每次重新解释。
作者: 李俊奇 (中南财经政法大学)邮箱:jqlee2003@126.com
说明:本文整合了 EconML 用户手册等多方资源中有关动态双重机器学习的内容,EconML 官方网址: -Link-
1. 背景介绍
1.1 引言
在现实研究中,我们经常面临如下问题:
在高维协变量存在的情况下如何估计一个稳定的因果效应? 存在混杂变量时,如何进行准确的估计?
机器学习方法虽强大,但直接用于因果推断容易产生偏误。双重机器学习(Double Machine Learning, DML)提供了一种实现稳健因果估计的新思路:使用正交化技术消除混杂变量对核心参数估计的偏差,通过两阶段建模来分离核心参数与冗余参数,最终实现无偏估计。
然而,许多实际问题具有时间动态性,处理效应可能随时间变化,仅仅使用双重机器学习是不够的。
例如,很多现实问题(医疗、农业、市场营销)中,干预(treatment)是动态多次的:
临床治疗通常包含多个治疗阶段,需随病情动态调整用药方案 教育干预常依据学生成长轨迹进行阶段性资源投放 在线广告投放决策也往往依赖用户行为的时间演化模式 在商品价格随时间变化的商店中,价格对需求的影响
这些场景下,因果效应的估计必须考虑多阶段干预下的动态机制,即每一期的处理不仅对当期结果产生影响,还会影响后续的状态变量与处理选择。因此,我们面临的是一个典型的动态因果推断问题。
(Lewis and Syrgkanis, 2021) 结合 Double Machine Learning(DML)与 Structural Nested Mean Models(SNMMs)中 g-Estimation 框架,提出一套可兼容任意机器学习模型、具有偏差修正能力的动态因果推断方法,即动态双重机器学习(Dynamic Double Machine Learning, i.e. DDML)。
DDML 可有效应用于高维协变量背景下的处理效应估计,扩展了 DML 的使用范围。与传统静态模型不同,DDML 允许处理变量随时间变化,且通过结合机器学习模型(如随机森林、梯度提升树)和非参数估计方法,显著提升了估计的灵活性与准确性。同时 DDML 保持与最终模型相关的许多有利的统计特性(如小均方误差、渐近正态性、置信区间的构建)。
1.2 什么时候适合使用 DDML ?
DDML 适用于以下情况:观察到所有潜在的动态混杂因素/控制因素(在收集的数据和观察到的结果中同时对适应性治疗决策产生直接影响的因素),要么是由于数量过多(高维)导致经典统计方法无法适用,要么是参数(非参数)函数无法令人满意地模拟这些因素对治疗和结果的影响。此时,后两个问题可以通过机器学习技术来解决 (Lewis and Syrgkanis, 2021)。
2. 准备工作
2.1 EconML 简介

本文主要使用 EconML 实现 DDML。
EconML 是微软研究院的 Alice 团队开发的 Python 工具包,可应用机器学习技术从观察或实验数据中估算个性化因果效应。
EconML 中提供的一套估算方法代表了因果机器学习的最新进展。通过将单个机器学习步骤纳入可解释的因果模型,这些方法提高了假设预测的可靠性,使广大用户能够更快、更轻松地进行因果分析。
该工具包集成了众多现代因果学习方法,其中几项由微软研究院的 ALICE 项目自行开发,还有许多其他技术来自该领域的领先团队。包括动态双重机器学习,如 (Lewis and Syrgkanis, 2021);双重机器学习,如 (Chernozhukov et al., 2017; Chernozhukov et al., 2018);因果森林,如 (Wager and Athey, 2018; Athey et al., 2019);深度工具变量 (Hartford et al.,2017) 等;非参数工具变量 (Newey and Powell, 2003);元学习器 (Künzel et al., 2017) 等。
该库将所有这些不同的技术汇集到一个通用的 Python API 中,极大简化了用户的建模流程,是因果推断应用实践的重要利器。

在EconML中,开发者实现了“条件平均处理效应”(Conditional Average Treatment Effect,CATE) 的四种估计方式:
双重机器学习(Double Machine Learning)。 双重鲁棒学习(Doubly Robust Learner)。 元学习器(Meta Learners)。 正交随机树(Orthogonal Random Forest)
这里我们主要介绍动态双重机器学习模块 DynamicDML 。
2.2 下载 EconML 库
在Python终端输入如下代码下载 EconML 库:
pip install EconML同时推荐安装如下依赖包:
pip install scikit-learn pandas numpy matplotlib seabornscikit-learn用于机器学习pandas用于数据分析numpy用于数组计算matplotlib和seaborn用于数据可视化
3. 模型简要数学设定
3.1 使用 DDML 的数据要求
DDML 模型旨在估计随时间变化的处理效应,适用于平衡面板数据数据。其核心思想是:
模型结构:在每个时间点,使用机器学习模型估计处理变量和结果变量的条件期望,然后通过残差计算处理效应。 时间动态性:由于处理效应随时间变化,故模型需要在每个时间点独立估计处理效应,捕捉动态变化。 数据要求:需要包含多个时间点的处理变量、结果变量和协变量,以及用于分组的标识符。
例如,如下数据格式可以使用 DDML :
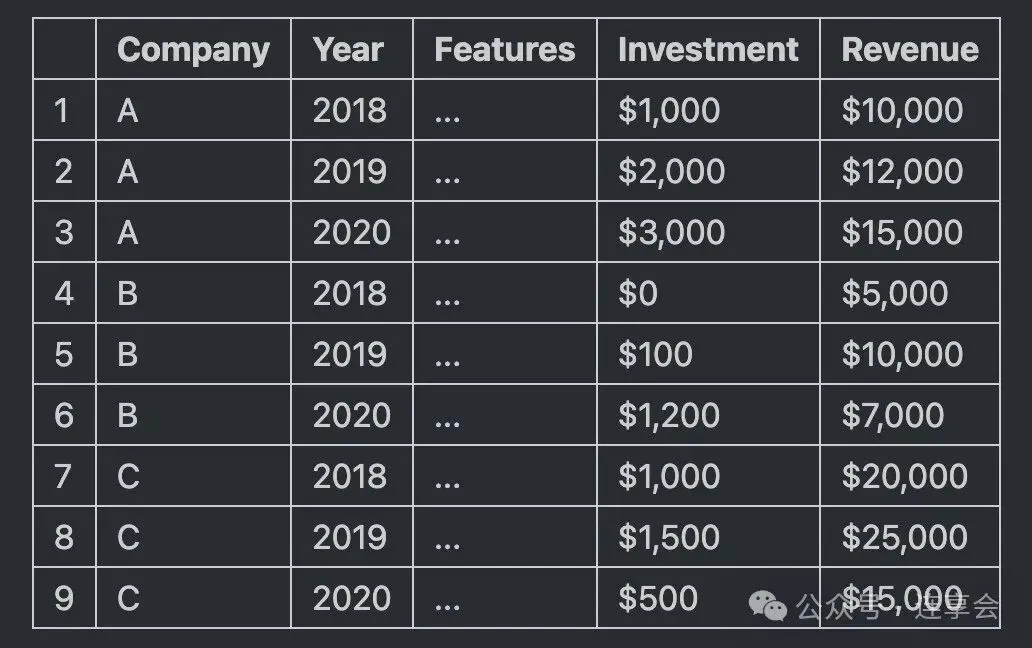
(注:将数据传递给 DynamicDML 估计器时,上面的 “公司” 列与拟合时的 “组” 参数相对应。上面的 “年份” 列不应传入,因为它会从 “公司” 列推断出来)
如果组内成员没有同时出现,则假定数据集中的第一个组实例对应于该组的第一个时期,第二个组实例对应于该组的第二个时期,例如:
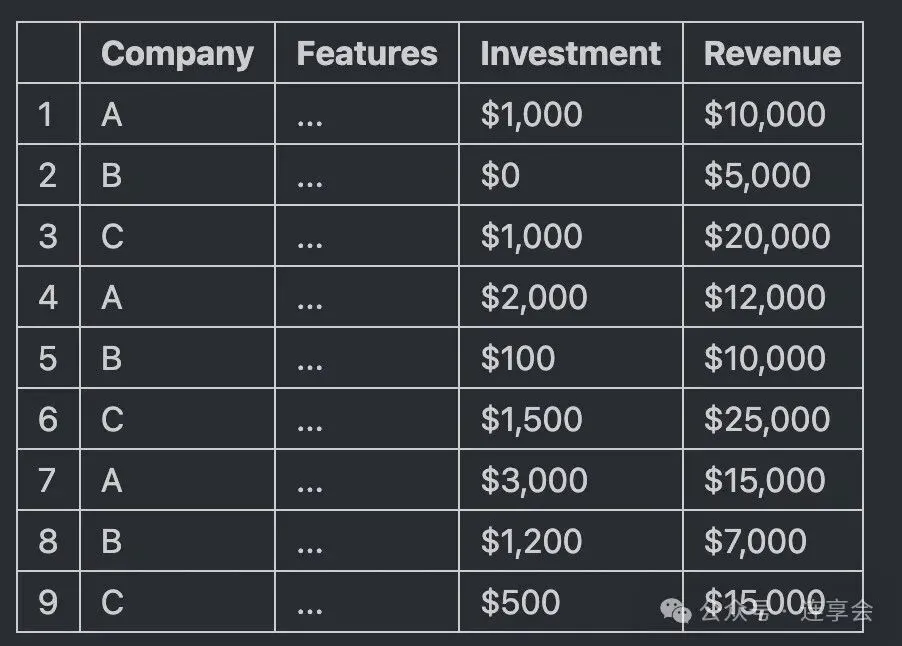
在该数据集中,第 1 行对应于 “A” 组的第一期,第 4 行对应于 “A” 组的第二期。
具体来说,数据需要满足以下特点:
假设你拥有观测性数据(或来自A/B测试的实验性历史数据),在这些数据中,每个个体单位随着时间推移接受了多个不同的处理或干预(),同时记录了最终的结果变量(),以及所有可能影响处理选择的协变量()。这些协变量不仅影响了处理决策(),还可能直接影响结果变量()(即 是所谓的控制变量或混杂变量),且这些信息都被完整记录在数据集中。
如果你的研究目标是理解处理()对结果变量()的影响,并且希望根据样本的可观测特征(,可以认为是混杂变量)来刻画这种影响关系,那么就可以使用 DDML。下面是一个例子(此例只是调用 DynamicDML 的数据格式,若要运行,需要读入自己的数据之后,并替换为相应的变量名):
from EconML.panel.dml import DynamicDMLest = DynamicDML()est.fit(y_dyn, T_dyn, X=X_dyn, W=W_dyn, groups=groups)DynamicDML 类是对传统 Double ML 方法的一种扩展,专门用于处理随时间顺序分阶段赋值的多期处理问题。该估计方法能够调整每期处理对未来结果变量的因果影响。数据生成过程可以建模为一个马尔可夫决策过程 ,其中:
表示第 期的状态变量(例如个体特征); 表示第 期的控制变量(可能同时影响处理决策和结果变量); 是第 期的处理变量; 是第 期观察到的结果变量。
该模型对数据生成过程作出了如下结构方程假设:
其中:
表示将状态变量 和控制变量 拼接(concatenation)而成的变量组; 、 和 分别表示外生的、均值为零的随机扰动项,且它们与所有当前期及滞后期的处理变量和状态变量相互独立。为了简化分析,我们假设这些随机扰动项在时间序列上是独立同分布(i.i.d.)抽取的; 结构参数 是一个 的矩阵,用于刻画前一期处理变量对下一期状态变量的影响; 结构参数 是一个 的矩阵,用于描述前一期状态变量对下一期状态变量的影响,即系统在没有处理干预情况下自身演化的动态机制; 函数 表示观测到的动态决策规则,它决定了下一期处理变量的分布,作为前一期处理变量和当前状态变量的函数; 参数向量 表示处理变量在当前期对结果变量的即时效应,参数向量 则表示状态变量在当前期对结果变量的即时效应; 此外,为了方便推导,假设初始期的处理变量和状态变量满足 。
(Lewis and Syrgkanis, 2021) 在论文中绘制了如下的马尔可夫模型因果图用于理解这个过程:
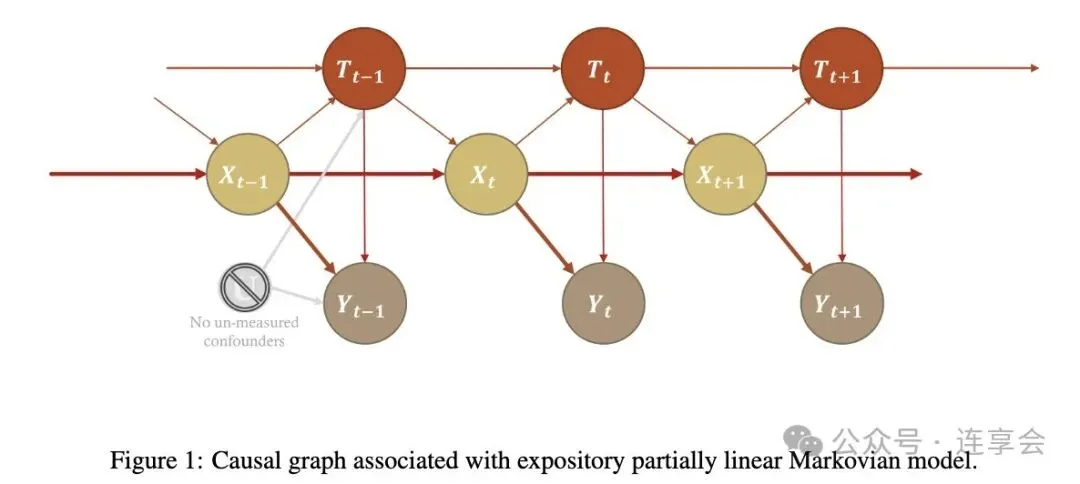
关于模型设定与更多理论假设,详见 (Lewis and Syrgkanis, 2021)和连享会往期推文 因果推断:双重机器学习-ddml。
本文以 Python 教程为主,因此不再过多赘述模型的理论部分。
3.2 DDML 伪代码
(Lewis and Syrgkanis, 2021) 提出了 DDML 的两阶段算法。其中在第一阶段以交叉拟合的方式拟合和评估一系列回归和分类模型,在第二阶段解决简单的线性方程组或简单的平方损失最小化问题。该方法还允许简单的样本分割/交叉拟合方法,允许在第一阶段中使用任意的机器学习方法。
动态双重机器学习(Dynamic Double Machine Learning, DDML)是传统双重机器学习在 时序场景 下的扩展。其核心目标是通过两阶段估计,消除混杂变量 的影响,从而准确识别动态处理效应。
(Lewis and Syrgkanis, 2021) 中的 Algorithm1 伪代码展现了 DDML 的基础动态效应估计过程,可以用于处理高维状态变量。文章中还提到了其他扩展算法,感兴趣的读者可点击文末链接进行阅读。

中文版:
Dynamic DML 伪代码(Algorithm 1,摘自 Lewis and Syrgkanis, 2021):
输入: 面板数据 ,其中 表示个体, 表示时间期;分组变量 。 分割数据: 将数据按组(如公司、个体)划分为 个交叉验证折(folds)。 第一阶段(Nuisance 参数估计): 用除第 折外的数据,拟合机器学习模型,分别预测 和 的条件期望(可用 Lasso、随机森林等): 用第 折数据,计算残差: 对每个折 : 第二阶段(主效应估计): 用所有折的残差,回归 关于 ,估计动态处理效应参数 : 可选:对每期、每个处理变量分别估计 。 输出: 各期处理效应估计值 及其置信区间。
说明: DDML 的关键在于用机器学习灵活建模协变量与处理/结果的关系,通过交叉拟合消除过拟合偏差,最终用残差回归获得无偏的动态因果效应估计。
4. 必要说明
本文演示代码基于 EconML 官方 notebooks 进行汉化。-Link-
假设你已经安装了第2部分提到的全部依赖包(如果没有,请看2.2节),在你运行下面提到的代码时,仍然可能出现下面这个问题(注意:以下代码是在 Jupyter Notebook 中进行测试的,没有遇到这个问题说明官方可能已经修复此 bug,可直接跳过 4.1 节):
# 主要使用的包from EconML.panel.dml import DynamicDMLfrom EconML.tests.dgp import DynamicPanelDGP, add_vlines# 这里的 tests 模块需要手动复制进去,这是 2025-03-28 官方最新上传的。# 即使 pip install EconML 下载最新的 EconML 的包,也暂时不能解决这个 bug(后期官方更新之后可能会修复此 bug)# 辅助包import numpy as npfrom sklearn.linear_model import LassoCV, MultiTaskLassoCVimport matplotlib.pyplot as plt%matplotlib inline会出现如下报错:
---------------------------------------------------------------------------ModuleNotFoundError Traceback (most recent call last)Cell In[1], line 3 1 # Main imports 2 from econml.panel.dml import DynamicDML----> 3 from econml.tests.dgp import DynamicPanelDGP, add_vlines 4 5 # Helper imports 6 import numpy as npModuleNotFoundError: No module named 'econml.tests'报错说 econml 中没有 tests 这个模块,可是我们刚刚明明下载了 econml 包,应该是含有这个模块才对。
那我们到官方的 GitHub 中一探究竟(需要魔法才能访问这个链接),-Link-:
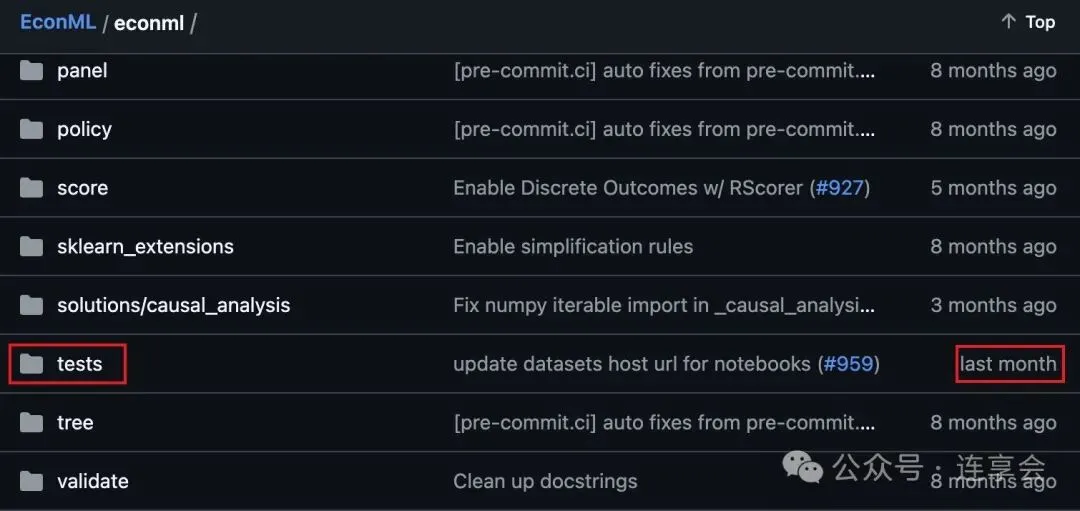
打开 econml 文件夹,可以看到 tests 这个模块是不久前才更新的,所以可能还没有把最新的代码封装到 econml 包中。
我们点击 Download ZIP 将官方的代码压缩包下载到本地,便于后续操作:
Python 的包通常安装在特定的文件夹中,所以我们需要在自己电脑本地已经安装的 Python 包里,找到 econml 这个包,并把官方更新的 tests 文件夹复制进去。
可以通过以下代码找到 Python 下载包的文件夹地址
import siteprint(site.getsitepackages())我的电脑(使用 mac 进行测试,且本文所有代码是在 work 这个虚拟环境下运行的)就会返回如下地址:
['/opt/anaconda3/envs/work/lib/python3.11/site-packages']对于 mac 用户,可以打开 Finder 然后按 command + shift + G 将 /opt/anaconda3/envs/work/lib/python3.11/site-packages(这里替换成你自己的路径) 复制进去,然后仔细寻找一番,便可以找到已经安装的 econml 包。
然后将前面下载的官方代码中的 tests 文件夹进行复制,粘贴到 econml 文件夹下,最终达到的效果应该是这样:
然后就可以正常运行下面的代码了。
5. Python 实现 DDML
在本节中,我们展示 DynamicDML 在合成数据和观测数据上的性能。
5.1 平均治疗效果示例(Example Usage with Average Treatment Effects)
5.1.1 数据生成过程(DGP)
我们考虑一个基于马尔可夫过程的处理模型来生成数据。
在下述示例中,变量定义如下:
表示第 期的处理变量; 表示第 期的结果变量; 表示第 期的特征变量与控制变量(其中系数向量 、 将用于挑选特征项与控制项)。
数据生成机制为:
其中,初始条件为 、,且噪声项 、、 独立同分布于正态分布 。
进一步设定如下:
; 矩阵 在前 列不为零,即 ,其余列为零,即 ; 参数 ; 矩阵 同样满足 ,; 系数向量 满足 ,。
我们生成一条单条时间序列,长度为 。
# 定义数据生成过程(DGP)参数np.random.seed(123) # 固定随机种子,确保实验可重复n_panels = 5000# 面板单位数量(即独立个体/样本组数量)n_periods = 3# 每个面板单位包含的时间期数n_treatments = 2# 每期的处理变量数量n_x = 100# 每期的特征变量与控制变量总数s_x = 10# 控制变量的稀疏度(即真正影响结果的控制变量数量)s_t = 10# 处理变量的稀疏支撑集大小(即真正影响处理的特征数量)# 生成数据dgp = DynamicPanelDGP(n_periods, n_treatments, n_x).create_instance( s_x, random_seed=12345)Y, T, X, W, groups = dgp.observational_data(n_panels, s_t=s_t, random_seed=12345)true_effect = dgp.true_effect5.1.2 训练估计器
# 定义 DynamicDML 估计器对象est = DynamicDML( model_y=LassoCV(cv=3, max_iter=1000), # 用 LassoCV 拟合结果变量 Y(交叉验证次数为3,最大迭代步1000) model_t=MultiTaskLassoCV(cv=3, max_iter=1000),# 用 MultiTaskLassoCV 同时拟合多维处理变量 T(交叉验证次数为3,最大迭代步数1000) cv=3# 外层交叉验证次数设为3,用于样本分折训练 nuisance models)# 训练估计器est.fit(Y, T, X=None, W=W, groups=groups)# 计算并输出:所有时期的处理变量对最后一期结果变量的平均处理效应(ATE)print(f"Average effect of default policy: {est.ate():0.2f}")# 计算目标政策(target policy)相对于基准政策(baseline policy)的效应# 必须为每一期指定一个处理值(即每期的处理决策路径)baseline_policy = np.zeros((1, n_periods * n_treatments)) # 基准政策:所有时期、所有处理变量均为0(不施加处理)target_policy = np.ones((1, n_periods * n_treatments)) # 目标政策:所有时期、所有处理变量均为1(完全施加处理)# 调用 DynamicDML 的 effect 方法,估计目标政策相对于基准政策的效应差异eff = est.effect(T0=baseline_policy, T1=target_policy)# 输出目标政策相对于基准政策的因果效应(保留两位小数)print(f"Effect of target policy over baseline policy: {eff[0]:0.2f}")接下来是进行逐期处理:
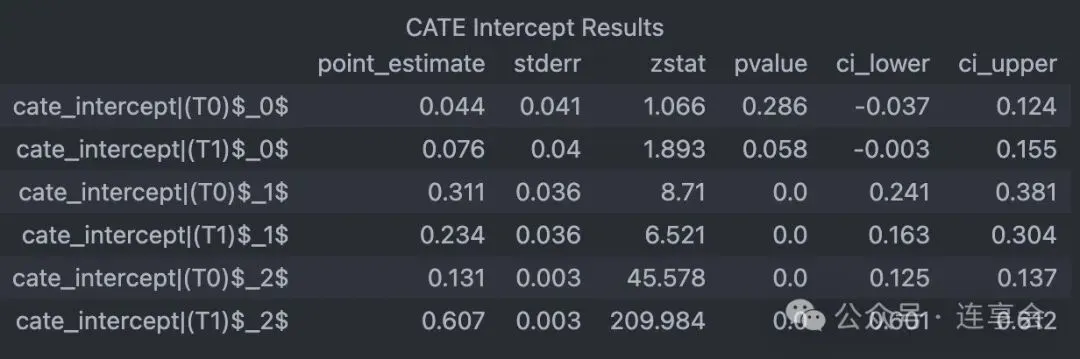
# 逐期处理效应(Period-specific treatment effects)for i, theta in enumerate(est.intercept_.reshape(-1, n_treatments)):# 输出:第 i+1 期的每个处理变量,对最终一期结果变量的边际效应 print(f"Marginal effect of a treatments in period {i+1} on period {n_periods} outcome: {theta}")# 输出逐期处理效应(Period Treatment Effects)及其置信区间(Confidence Intervals)est.summary()# 计算各期处理效应的置信区间(Confidence Intervals)conf_ints = est.intercept__interval(alpha=0.05)# alpha 设置成 0.01 就是 99% 的置信区间可以得到如下的 CATE 估计、p值和置信区间等:
5.1.3 可视化
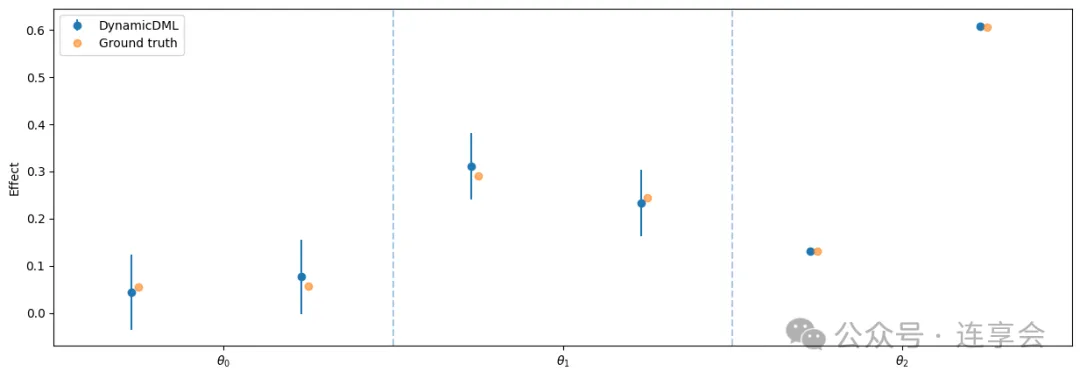
# 绘制各期处理效应及其置信区间(error bars)与真实效应对比图plt.figure(figsize=(15, 5)) # 设置图像大小为15×5英寸# 绘制 DynamicDML 估计的处理效应及其置信区间plt.errorbar( np.arange(n_periods * n_treatments) - .04, # x轴坐标(每个处理变量),稍微左移避免重叠 est.intercept_, # DynamicDML 估计的效应点 yerr=(conf_ints[1] - est.intercept_, # 上误差条 est.intercept_ - conf_ints[0]), # 下误差条 fmt='o', # 散点样式 label='DynamicDML'# 图例标签)# 绘制真实处理效应(Ground truth),用于与估计值对比plt.errorbar( np.arange(n_periods * n_treatments), true_effect.flatten(), # 真实效应,展开成一维 fmt='o', alpha=0.6, # 设置透明度 label='Ground truth'# 图例标签)# 在每个时期交界处画虚线分隔(帮助视觉区分不同时间段)for t in np.arange(1, n_periods): plt.axvline(x=t * n_treatments - .5, linestyle='--', alpha=.4)# 设置 x 轴刻度和刻度标签plt.xticks( [t * n_treatments - .5 + n_treatments/2for t in range(n_periods)], # 每个时间段中间的位置 ["$\\theta_{}$".format(t) for t in range(n_periods)] # 标签)plt.gca().set_xlim([-.5, n_periods * n_treatments - .5]) # 设置x轴范围plt.ylabel("Effect") # 设置y轴标签plt.legend() # 显示图例plt.show() # 显示图像画出图如下:
5.2 具有异质治疗效果的使用示例(Example Usage with Heterogeneous Treatment Effects)
我们还可以估计初始时期某些特征子集 的取值所引起的处理效应异质性(Treatment Effect Heterogeneity)。
目前,异质性估计仅支持基于初始状态特征(initial state features)进行建模。
这种设定特别适用于分析单位个体在时间上不变的特征(如出生年份、基础教育程度等)对处理效应的异质性影响。在这种情况下,可以简单地将每期的协变量 设置为一些在所有时期保持不变的单位特征的重复值。
当然,也可以传入随时间变化的特征作为协变量,此时这些特征的时间变化部分将作为控制变量(time-varying controls)使用,但需要注意的是:异质性估计只基于初始时期的状态特征进行建模,不会随时间动态调整。
5.2.1 数据生成过程(DGP)
# 定义额外的数据生成过程(DGP)参数het_strength = 0.5# 异质性强度(heterogeneity strength),控制处理效应对特征的敏感程度het_inds = np.arange(n_x - n_treatments, n_x) # 指定产生异质性的特征变量索引(靠近特征集尾部)# 生成模拟数据dgp = DynamicPanelDGP(n_periods, n_treatments, n_x).create_instance( s_x, # 控制变量稀疏度(真正影响结果的控制变量数量) hetero_strength=het_strength, # 设置处理效应异质性的强度 hetero_inds=het_inds, # 指定哪一组特征引入异质性 random_seed=12# 随机种子,确保实验可重复)# 从生成的DGP实例中抽取观测数据Y, T, X, W, groups = dgp.observational_data( n_panels, # 面板单位数量 s_t=s_t, # 处理稀疏度 random_seed=1# 再次设置随机种子)# 记录下:真实的均值处理效应 (ATE) 以及真实的异质性处理效应 (heterogeneous effect)ate_effect = dgp.true_effecthet_effect = dgp.true_hetero_effect[:, het_inds + 1] # 注意索引偏移(+1)5.2.2 训练估计器
# 定义 DynamicDML 估计器对象,用于估计动态处理效应与异质性效应est = DynamicDML( model_y=LassoCV(cv=3), # 采用 LassoCV(交叉验证3折)拟合结果变量 Y,适应高维协变量 model_t=MultiTaskLassoCV(cv=3), # 采用 MultiTaskLassoCV 同时拟合多期、多维处理变量 T cv=3# 外层 cross-fitting 交叉验证设为3折,提高估计稳健性)# 训练估计器est.fit(Y, T, X=X, W=W, groups=groups, inference="auto")# 结果展示est.summary()最终输出结果如下:
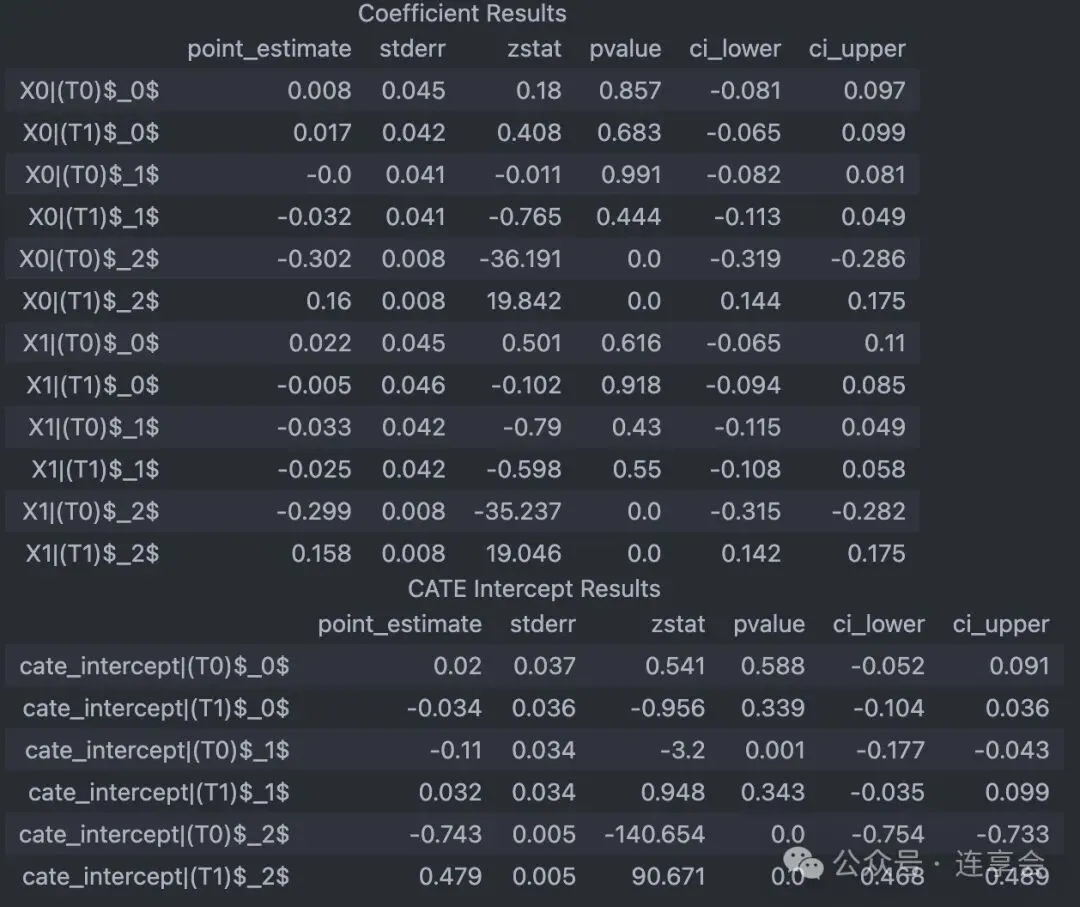
# 测试点的平均处理效应X_test = X[np.arange(0, 25, 3)]print(f"Average effect of default policy:{est.ate(X=X_test):0.2f}")# 目标政策相对于基准政策的效应# 必须为每个时期指定一个处理baseline_policy = np.zeros((1, n_periods * n_treatments))target_policy = np.ones((1, n_periods * n_treatments))eff = est.effect(X=X_test, T0=baseline_policy, T1=target_policy)print("Effect of target policy over baseline policy for test set:\n", eff)# 系数:截距为 n_treatments*n_periods coef_ 的形状(n_treatments*n_periods, n_hetero_inds),# 前 n_treatment 行来自第一期,后 n_treatment 行来自第二期。est.intercept_, est.coef_# 置信区间conf_ints_intercept = est.intercept__interval(alpha=0.05)conf_ints_coef = est.coef__interval(alpha=0.05)5.2.3 可视化
代码如下:
true_effect_inds = []for t in range(n_treatments): true_effect_inds += [t * (1 + n_x)] + (list(t * (1 + n_x) + 1 + het_inds) if len(het_inds)>0else [])true_effect_params = dgp.true_hetero_effect[:, true_effect_inds]true_effect_params = true_effect_params.reshape((n_treatments*n_periods, 1 + het_inds.shape[0]))# 拼接矩阵param_hat = np.hstack([est.intercept_.reshape(-1, 1), est.coef_])lower = np.hstack([conf_ints_intercept[0].reshape(-1, 1), conf_ints_coef[0]])upper = np.hstack([conf_ints_intercept[1].reshape(-1, 1), conf_ints_coef[1]])# 画图plt.figure(figsize=(15, 5))plt.errorbar(np.arange(n_periods * (len(het_inds) + 1) * n_treatments), true_effect_params.flatten(), fmt='*', label='Ground Truth')plt.errorbar(np.arange(n_periods * (len(het_inds) + 1) * n_treatments), param_hat.flatten(), yerr=((upper - param_hat).flatten(), (param_hat - lower).flatten()), fmt='o', label='DynamicDML')add_vlines(n_periods, n_treatments, het_inds)plt.legend()plt.show()最终画出图如下: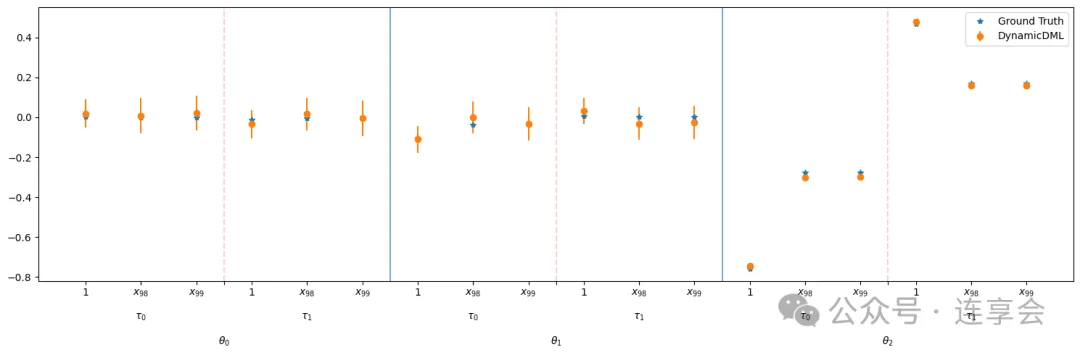
6. 参考资料
EconML官网:-Link-Aoshima, M., and Yata, K. (2011). Two-stage procedures for high-dimensional data. Sequential analysis, 30(4), 356-399. -PDF- Athey, S., Tibshirani, J., & Wager, S. (2019). Generalized random forests. -Link- Chernozhukov, V., Chetverikov, D., Demirer, M., Duflo, E., Hansen, C., Newey, W., & Robins, J. (2018). Double/debiased machine learning for treatment and structural parameters, The Econometrics Journal, Volume 21, Issue 1, Pages C1–C68. -Link- Chernozhukov, V., Goldman, M., Semenova, V., & Taddy, M. (2017). Orthogonal machine learning for demand estimation: High dimensional causal inference in dynamic panels. arXiv, arXiv-1712. -Link- Hartford, J., Lewis, G., Leyton-Brown, K., & Taddy, M. (2017, July). Deep IV: A flexible approach for counterfactual prediction. International Conference on Machine Learning (pp. 1414-1423). PMLR. -PDF- Künzel, S. R., Sekhon, J. S., Bickel, P. J., & Yu, B. (2019). Metalearners for estimating heterogeneous treatment effects using machine learning, Proceedings of the national academy of sciences, 116(10), 4156-4165. -PDF- Jaggi, M., & Sulovsk, M. (2010). A simple algorithm for nuclear norm regularized problems. Proceedings of the 27th International Conference on Machine Learning (ICML-10) (pp. 471-478). -PDF- Lewis, G., & Syrgkanis, V. (2021, December). Double/Debiased Machine Learning for Dynamic Treatment Effects. In NeurIPS, (pp. 22695-22707). -Link- Newey, W. K., & Powell, J. L. (2003). Instrumental variable estimation of nonparametric models. Econometrica, 71(5), 1565-1578. -PDF- S.R. Künzel, J.S. Sekhon, P.J. Bickel, & B. (2019). Yu, Metalearners for estimating heterogeneous treatment effects using machine learning. Proceedings of the national academy of sciences, 116 (10) 4156-4165. -Link- Wager, S., & Athey, S. (2018). Estimation and inference of heterogeneous treatment effects using random forests. Journal of the American Statistical Association, 113(523), 1228-1242. -PDF-
7. 相关推文
Note:产生如下推文列表的 Stata 命令为:
lianxh 机器学习, nocat安装最新版lianxh命令:ssc install lianxh, replace
Drukker, 刘迪, 2020, Stata Blogs - An introduction to the lasso in Stata (拉索回归简介), 连享会 No.117.
仵荣鑫, 2022, 知乎热议:如何学习机器学习, 连享会 No.983. 全禹澄, 2021, 机器学习如何用?金融+能源经济学文献综述, 连享会 No.670. 冯乔, 2023, Stata中的堆栈泛化和机器学习-pystacked, 连享会 No.1317. 吕卓阳, 2021, MLRtime:如何在 Stata 调用 R 的机器学习包?, 连享会 No.85. 张瑞钰, 2021, 知乎热议:纠结-计量经济、时间序列和机器学习, 连享会 No.585. 李金桐, 2023, 因果推断:双重机器学习-ddml, 连享会 No.1221. 樊嘉诚, 2021, Stata:机器学习分类器大全, 连享会 No.505. 浦进博, 2024, 合成控制法最新进展!机器学习+SCM!-qcm, 连享会 No.1515. 王卓, 2023, Python:从随机实验到双重机器学习, 连享会 No.1204. 田原, 2020, 支持向量机:Stata 和 Python 实现, 连享会 No.149. 米书颖, 2024, 机器学习:大佬建议的标准动作, 连享会 No.1470. 罗宇恒, 2025, 美国生命末期健康照护预测建模, 连享会 No.1541. 董洁妙, 2022, Stata:双重机器学习-多维聚类标准误的估计方法-crhdreg, 连享会 No.1036. 连享会, 2021, Stata-Python交互-7:在Stata中实现机器学习-支持向量机, 连享会 No.557. 连享会, 2023, 文本分析:从文本到论文, 连享会 No.1259. 连享会, 2024, 机器学习与因果推断专题, 连享会 No.1462. 连小白, 2025, Python常用包盘点:经济与金融领域的必备工具包, 连享会 No.1568. 马丁, 刘梦真, 2021, 机器学习:随机森林算法的Stata实现, 连享会 No.568.

连享会:2026五一论文班 · 线上时间:5月2-4日嘉宾:郭士祺 (上海交通大学)、戚树森 (厦门大学)、李学恒 (中山大学)咨询:王老师 18903405450(微信)

连享会微信小店上线啦!
Note:扫一扫进入“连享会微信小店”,你想学的课程在这里······
尊敬的老师 / 亲爱的同学们:
连享会致力于不断优化和丰富课程内容,以确保每位学员都能获得最有价值的学习体验。为了更精准地满足您的学习需求,我们诚挚地邀请您参与到我们的课程规划中来。 请您在下面的问卷中,分享您 感兴趣的学习主题或您希望深入了解的知识领域 。您的每一条建议都是我们宝贵的资源,将直接影响到我们课程的改进和创新。 我们期待您的反馈,因为您的参与和支持是我们不断前进的动力。感谢您抽出宝贵时间,与我们共同塑造更加精彩的学习旅程!https://www.wjx.cn/vm/YgPfdsJ.aspx# 再次感谢大家宝贵的意见!

New! Stata 搜索神器:
lianxh和songblGIF 动图介绍搜: 推文、数据分享、期刊论文、重现代码 ……👉 安装:. ssc install lianxh. ssc install songbl👉 使用:. lianxh DID 倍分法. songbl all

🍏 关于我们
连享会 ( www.lianxh.cn,推文列表) 由中山大学连玉君老师团队创办,定期分享实证分析经验。 直通车: 👉【百度一下:连享会】即可直达连享会主页。亦可进一步添加 「知乎」,「b 站」,「面板数据」,「公开课」 等关键词细化搜索。

随机文章
-
 10个月宝宝每天需要喝多少奶粉?
10个月宝宝每天需要喝多少奶粉?
- 10年学习Linux大师说这些命令不会等于不会Linux
- 从离线安装到图表分析:linux nmon 性能监控全流程指南
- Linux从入门到进阶02:VMware虚拟机与Ubuntu系统安装详解
- Linux系统修改Linux root密码时,提示"passwd:Permission denied "没有权限的处理思路.
- 瑞芯微——Linux的常用指令CP
- Linux必背基础命令|运维新手直接抄
- Linux内存管理:反向映射RMAP
- Linux部署和使用SVN
- Linux 服务器实现 Word 转图片方案
- Linux手机又出现了!带实体隐私开关的Jolla Phone
