多线程就像一个人同时接多个电话,多进程就像多个人同时接电话。学会"一心多用",让你的程序效率翻倍!
🎯 本章目标
学完本章,你会:
✅ 理解线程和进程的基本概念
✅ 掌握创建多线程程序的方法
✅ 掌握创建多进程程序的方法
✅ 理解线程安全和进程间通信
✅ 知道何时使用多线程,何时使用多进程
✅ 能在测试中应用并发编程
🎪 第一部分:理解并发编程
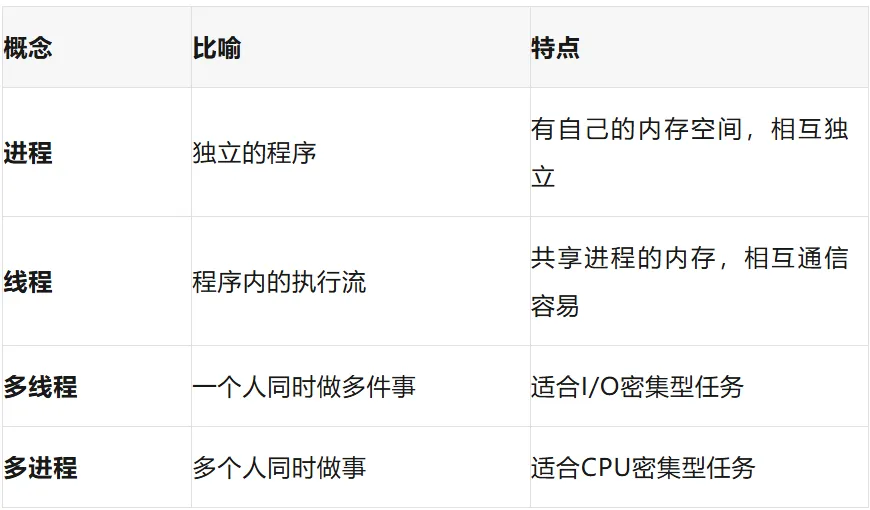
什么是线程和进程?
想象一下:
进程 = 一家餐厅 🍽️
线程 = 餐厅里的服务员 👨🍳👩🍳
一家餐厅(进程)可以有多个服务员(线程)
不同的餐厅(进程)是独立的
现实比喻:
⚡ 第二部分:多线程编程
为什么需要多线程?
没有多线程的世界:
# 程序必须一个一个任务执行下载文件1() # 等10秒下载文件2() # 等10秒下载文件3() # 等10秒# 总共30秒
有多线程的世界:
# 可以同时执行多个任务线程1: 下载文件1() # 同时开始线程2: 下载文件2() # 同时开始线程3: 下载文件3() # 同时开始# 总共10秒
创建线程的两种方法
方法1:使用函数创建线程
import threadingimport timedef download_file(filename, seconds): """模拟下载文件""" print(f"开始下载 {filename}...") time.sleep(seconds) # 模拟下载时间 print(f"{filename} 下载完成!耗时 {seconds} 秒")# 创建线程thread1 = threading.Thread(target=download_file, args=("文件1.txt", 3))thread2 = threading.Thread(target=download_file, args=("文件2.txt", 2))thread3 = threading.Thread(target=download_file, args=("文件3.txt", 1))# 启动线程print("开始下载文件...")thread1.start()thread2.start()thread3.start()# 等待所有线程完成thread1.join()thread2.join()thread3.join()print("所有文件下载完成!")
输出:
开始下载文件...开始下载 文件1.txt...开始下载 文件2.txt...开始下载 文件3.txt...文件3.txt 下载完成!耗时 1 秒文件2.txt 下载完成!耗时 2 秒文件1.txt 下载完成!耗时 3 秒所有文件下载完成!
方法2:使用类创建线程
import threadingimport timeclass DownloadThread(threading.Thread): """下载线程类""" def __init__(self, filename, seconds): super().__init__() # 必须调用父类初始化 self.filename = filename self.seconds = seconds def run(self): """线程运行时执行的方法""" print(f"开始下载 {self.filename}...") time.sleep(self.seconds) print(f"{self.filename} 下载完成!耗时 {self.seconds} 秒")# 创建线程对象threads = [ DownloadThread("文件A.txt", 2), DownloadThread("文件B.txt", 1), DownloadThread("文件C.txt", 3)]# 启动所有线程print("开始下载文件...")for thread in threads: thread.start()# 等待所有线程完成for thread in threads: thread.join()print("所有文件下载完成!")
线程同步:解决数据竞争
问题:多个线程同时修改同一个数据
import threadingimport time# 共享的计数器counter = 0def increment(): """增加计数器""" global counter for _ in range(100000): counter += 1# 创建多个线程threads = []for _ in range(5): t = threading.Thread(target=increment) threads.append(t) t.start()# 等待所有线程完成for t in threads: t.join()print(f"最终计数器值: {counter}") # 可能不是500000!
解决方案:使用锁
import threadingimport timecounter = 0lock = threading.Lock() # 创建锁def increment(): global counter for _ in range(100000): lock.acquire() # 获取锁 try: counter += 1 finally: lock.release() # 释放锁# 创建线程threads = []for _ inrange(5): t = threading.Thread(target=increment) threads.append(t) t.start()# 等待线程完成for t in threads: t.join()print(f"最终计数器值: {counter}") # 一定是500000
更简洁的写法(使用with):
def increment(): global counter for _ in range(100000): with lock: # 自动获取和释放锁 counter += 1
线程间通信:使用队列
import threadingimport queueimport timeimport random# 创建一个队列q = queue.Queue()def producer(name): """生产者线程,往队列放东西""" for i in range(5): item = f"{name}-产品{i}" time.sleep(random.random()) # 随机等待 q.put(item) # 放入队列 print(f"{name} 生产了: {item}")def consumer(name): """消费者线程,从队列取东西""" for _ in range(5): item = q.get() # 从队列获取,如果队列为空会等待 print(f"{name} 消费了: {item}") q.task_done() # 告诉队列任务完成 time.sleep(random.random()) # 随机等待# 创建生产者线程p1 = threading.Thread(target=producer, args=("工厂A",))p2 = threading.Thread(target=producer, args=("工厂B",))# 创建消费者线程c1 = threading.Thread(target=consumer, args=("顾客1",))c2 = threading.Thread(target=consumer, args=("顾客2",))# 启动线程p1.start()p2.start()c1.start()c2.start()# 等待生产者完成p1.join()p2.join()# 等待队列中所有任务完成q.join()# 消费者线程会在队列空时自动结束c1.join()c2.join()print("生产消费完成!")
🔥 第三部分:多进程编程
为什么需要多进程?
多线程的局限性:
多进程的优势:
每个进程有自己的GIL
可以真正同时运行多个CPU密集型任务
充分利用多核CPU
创建进程
import multiprocessingimport timeimport osdef cpu_intensive_task(n, task_name): """CPU密集型任务:计算平方和""" print(f"进程 {task_name} (PID: {os.getpid()}) 开始计算") result = 0 for i in range(n): result += i * i print(f"进程 {task_name} 计算完成: {result}") return resultif __name__ == "__main__": # 多进程必须写在main中 # 创建进程 p1 = multiprocessing.Process(target=cpu_intensive_task, args=(10000000, "任务A")) p2 = multiprocessing.Process(target=cpu_intensive_task, args=(10000000, "任务B")) p3 = multiprocessing.Process(target=cpu_intensive_task, args=(10000000, "任务C")) # 启动进程 start_time = time.time() p1.start() p2.start() p3.start() # 等待进程完成 p1.join() p2.join() p3.join() end_time = time.time() print(f"所有进程完成!总耗时: {end_time - start_time:.2f} 秒")
进程池:批量处理任务
import multiprocessingimport timedef process_data(data): """处理数据的函数""" time.sleep(1) # 模拟处理时间 result = data * 2 print(f"处理数据: {data} -> {result}") return resultif __name__ == "__main__": # 要处理的数据 data_list = [1, 2, 3, 4, 5, 6, 7, 8, 9, 10] print("单进程处理...") start_time = time.time() results = [] for data in data_list: results.append(process_data(data)) end_time = time.time() print(f"单进程耗时: {end_time - start_time:.2f} 秒") print("\n多进程处理(进程池)...") start_time = time.time() # 创建进程池,最多4个进程 with multiprocessing.Pool(processes=4) as pool: # 使用map方法并行处理 results = pool.map(process_data, data_list) end_time = time.time() print(f"多进程耗时: {end_time - start_time:.2f} 秒") print(f"处理结果: {results}")
进程间通信,由于进程有独立的内存空间,进程间通信需要使用特殊的方法。
方法1:使用队列(Queue)
import multiprocessingimport timeimport randomdef producer(queue, name): """生产者进程""" for i in range(3): item = f"{name}-产品{i}" time.sleep(random.random()) queue.put(item) # 放入队列 print(f"生产者 {name} 生产了: {item}")def consumer(queue, name): """消费者进程""" for _ in range(3): item = queue.get() # 从队列获取 print(f"消费者 {name} 消费了: {item}") time.sleep(random.random())if __name__ == "__main__": # 创建进程间通信的队列 queue = multiprocessing.Queue() # 创建进程 producers = [ multiprocessing.Process(target=producer, args=(queue, "工厂A")), multiprocessing.Process(target=producer, args=(queue, "工厂B")) ] consumers = [ multiprocessing.Process(target=consumer, args=(queue, "顾客1")), multiprocessing.Process(target=consumer, args=(queue, "顾客2")) ] # 启动所有进程 for p in producers: p.start() for c in consumers: c.start() # 等待生产者完成 for p in producers: p.join() # 告诉消费者可以结束了 for _ in consumers: queue.put(None) # 结束信号 # 等待消费者完成 for c in consumers: c.join() print("所有进程完成!")
方法2:使用共享内存
import multiprocessingimport timedef worker(shared_value, lock, name): """工作进程,修改共享值""" for _ in range(100000): with lock: # 使用锁保护共享数据 shared_value.value += 1 print(f"进程 {name} 完成")if __name__ == "__main__": # 创建共享值和锁 shared_value = multiprocessing.Value('i', 0) # 'i'表示整数 lock = multiprocessing.Lock() # 创建进程 processes = [] for i in range(4): p = multiprocessing.Process(target=worker, args=(shared_value, lock, f"P{i}")) processes.append(p) p.start() # 等待所有进程 for p in processes: p.join() print(f"最终共享值: {shared_value.value}") # 应该是400000
📊 第四部分:多线程 vs 多进程
什么时候用什么?
性能对比示例
import threadingimport multiprocessingimport timedef cpu_task(n): """CPU密集型任务""" result = 0 for i in range(n): result += i * i return resultdef io_task(seconds): """I/O密集型任务(模拟)""" time.sleep(seconds) return secondsdef test_threads(task_func, args_list, num_threads): """测试多线程性能""" threads = [] start_time = time.time() for args in args_list: t = threading.Thread(target=task_func, args=args) threads.append(t) t.start() for t in threads: t.join() return time.time() - start_timedef test_processes(task_func, args_list, num_processes): """测试多进程性能""" start_time = time.time() with multiprocessing.Pool(processes=num_processes) as pool: pool.starmap(task_func, args_list) return time.time() - start_timeif __name__ == "__main__": # 测试CPU密集型任务 print("=== CPU密集型任务测试 ===") cpu_args = [(1000000,)] * 4 # 4个相同的任务 thread_time = test_threads(cpu_task, cpu_args, 4) print(f"多线程耗时: {thread_time:.2f}秒") process_time = test_processes(cpu_task, cpu_args, 4) print(f"多进程耗时: {process_time:.2f}秒") print(f"多进程比多线程快: {thread_time/process_time:.1f}倍") # 测试I/O密集型任务 print("\n=== I/O密集型任务测试 ===") io_args = [(1,), (1,), (1,), (1,)] # 4个1秒的任务 thread_time = test_threads(io_task, io_args, 4) print(f"多线程耗时: {thread_time:.2f}秒") process_time = test_processes(io_task, io_args, 4) print(f"多进程耗时: {process_time:.2f}秒")
注意:多线程和多进程作为测试人员,如果你想后期做测开必须掌握这部分知识,但是如果你只是做一些自动化工作,这块可以不用掌握太多,了解他们是用来干什么的即可(基本用不到且pytest框架集成相关的并发功能,你只需掌握pytest的多线程多进程并发使用即可)
选择建议
I/O密集型(网络、磁盘):用多线程
CPU密集型(计算):用多进程
任务简单但多:用线程/进程池
需要隔离:用多进程
需要共享数据:用多线程
📋 检查清单
[ ] 能说出线程和进程的区别
[ ] 能创建简单的多线程程序
[ ] 能创建简单的多进程程序
[ ] 能使用锁保护共享数据
[ ] 能使用队列进行线程/进程间通信
[ ] 能使用线程/进程池
[ ] 知道何时用多线程,何时用多进程
[ ] 能在测试中应用并发编程
[ ] 能处理常见的并发错误
[ ] 能编写简单的并发程序
🎉 恭喜!并发编程掌握完成
现在你已经学会了Python中重要的并发编程技能:
关键收获:
✅ 线程概念:程序内的执行流
✅ 进程概念:独立的程序实例
✅ 多线程编程:适合I/O密集型任务
✅ 多进程编程:适合CPU密集型任务
✅ 线程同步:锁、队列保护共享数据
✅ 进程通信:队列、管道、共享内存
✅ 实战应用:在测试中并发执行任务
现在你可以:
编写高效的多线程程序
编写真正的并行多进程程序
保护共享数据避免竞争
在任务间通信和协调
选择合适的并发方式
提高程序执行效率
记住要点:
多线程适合I/O密集型任务
多进程适合CPU密集型任务
共享数据要加锁保护
多进程必须写if name== "main"
使用线程/进程池提高效率
下一章预告:神器pytest框架
准备好了吗?让我们继续前进!🚀
小提示:并发编程就像指挥交响乐团,每个线程/进程就像一个乐手,需要协调好他们才能演奏出美妙的音乐。多练习,你就能成为优秀的"指挥家"!

 10个月宝宝每天需要喝多少奶粉?
10个月宝宝每天需要喝多少奶粉?
