【Python语音识别系列】一文教你实现双声道录音文件语音识别(案例+源码)
- 2026-07-04 06:49:25
【Python语音识别系列】一文教你实现双声道录音文件语音识别(案例+源码)写在前面 

热门原创文章推荐阅读点击标题可跳转 写在后面 
免费电子书籍,带你入门人工智能:
这是我的第457篇原创文章。
『数据杂坛』以Python语言为核心,垂直于数据科学领域,专注于(可戳👉)Python程序设计|数据分析|特征工程|机器学习分类|机器学习回归|深度学习分类|深度学习回归|单变量时序预测|多变量时序预测|语音识别|图像识别|自然语音处理|大语言模型|软件设计开发等技术栈交流学习,涵盖数据挖掘、计算机视觉、自然语言处理等应用领域。(文末有惊喜福利)
一、引言
双声道录音文件的语音识别,一般用于区分两个说话人(如客服 vs 客户),典型处理流程如下:
✅ 整体流程
🎧 双声道 WAV 文件 → 🎙️ 声道分离 → 🧠 逐声道语音识别 → 📋 对话重建(按时间排序)
二、实现过程
2.1 定义模型
核心代码:
model = AutoModel(model="./workspace/official_models/speech_seaco_paraformer_large_asr_nat-zh-cn-16k-common-vocab8404-pytorch",model_revision="v2.0.4",vad_model="./workspace/official_models/speech_fsmn_vad_zh-cn-16k-common-pytorch",vad_model_revision="v2.0.4",punc_model="./workspace/official_models/punc_ct-transformer_zh-cn-common-vocab272727-pytorch",punc_model_revision="v2.0.4",spk_model = "./workspace/official_models/speech_campplus_sv_zh-cn_16k-common",spk_model_revision="v2.0.2",disable_update=True)
2.2 声道分离
读取双声道音频,分离为两个单声道 numpy 数组
def separate_channels(wav_path: str):"""读取双声道音频,分离为两个单声道 numpy 数组"""audio, sample_rate = sf.read(wav_path) # shape: [samples, channels]if audio.ndim != 2 or audio.shape[1] != 2:raise ValueError("音频不是双声道格式!")return audio[:, 0], audio[:, 1], sample_rate
2.3 语音识别
核心代码:
def recognize_with_model(audio: np.ndarray, sample_rate: int) -> List[Dict]:"""使用 FunASR 识别语音"""result = model.generate(input=audio,input_fs=sample_rate,hotword=None,return_dict=True)return result[0]["sentence_info"]
2.4 对话合并
核心代码:
def merge_dialogues(cust_segments, agent_segments) -> List[Dict]:"""按起止时间戳排序合并对话"""all_segs = [{"role": "客户", **seg} for seg in cust_segments] + [{"role": "客服", **seg} for seg in agent_segments]dialogue_data = sorted(all_segs, key=lambda x: x["start"])return dialogue_data
2.5 完成处理逻辑
将上面的逻辑进行串联:
def process_bichannel_wav(wav_path: str):print(f"处理文件:{wav_path}")# ====================声道分离================cust_audio, agent_audio, sr = separate_channels(wav_path)# ====================语音识别================result_cust = recognize_with_model(cust_audio, sr)result_agent = recognize_with_model(agent_audio, sr)# ====================组装对话================dialogue = merge_dialogues(result_cust, result_agent)# ====================打印最终合并结果================for turn in dialogue:start_sec = turn["start"] / 1000end_sec = turn["end"] / 1000print(f"[{start_sec:.2f}s - {end_sec:.2f}s] {turn['role']}:{turn['text']}")return dialogue
2.6 脚本测试
代码:
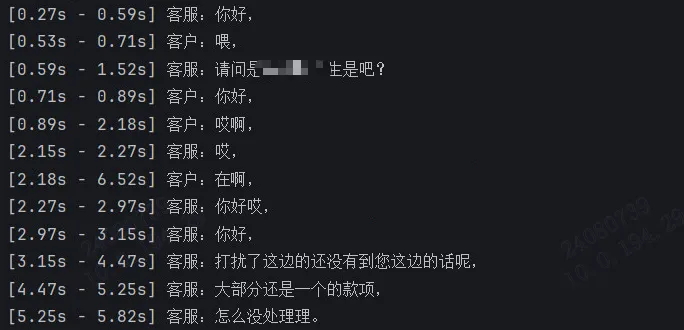
if __name__ == "__main__":# 传入一个双声道的客服录音wav_file = "test.wav"process_bichannel_wav(wav_file)
结果:
改进:合并连续相同角色的对话,使得对话记录更加简洁。对话合并的修改逻辑如下:
def merge_dialogues(cust_segments, agent_segments) -> List[Dict]:"""按起止时间戳排序合并对话"""all_segs = [{"role": "客户", **seg} for seg in cust_segments] + [{"role": "客服", **seg} for seg in agent_segments]dialogue_data = sorted(all_segs, key=lambda x: x["start"])merged_data = []for role, group in itertools.groupby(dialogue_data, key=lambda x: x['role']):group_list = list(group)merged_entry = {'role': role,'text': ''.join(entry['text'] for entry in group_list),'start': group_list[0]['start'],'end': group_list[-1]['end'],'timestamp': [ts for entry in group_list for ts in entry['timestamp']],'spk': group_list[0]['spk']}merged_data.append(merged_entry)return merged_data
结果:
建立CNN与Transformer融合模型实现单变量时序预测(案例+源码)
建立Transformer-LSTM-TCN-XGBoost融合模型多变量时序预测(源码)
利用SHAP进行特征重要性分析-决策树模型为例(案例+源码)
梯度提升集成:LightGBM与XGBoost组合预测油耗(案例+源码)
一文教你建立随机森林-贝叶斯优化模型预测房价(案例+源码)
建立随机森林模型预测心脏疾病(完整实现过程)
建立CNN模型实现猫狗图像分类(案例+源码)
使用LSTM模型进行文本情感分析(案例+源码)
基于Flask将深度学习模型部署到web应用上(完整案例)
新版Dify 开发自定义工具插件在工作流中直接调用(完整步骤)
作者简介:
读研期间发表6篇SCI数据算法相关论文,目前在某研究院从事数据算法相关研究工作,结合自身科研实践经历不定期持续分享关于Python、数据分析、特征工程、机器学习、深度学习、人工智能系列基础知识与案例。
致力于只做原创,以最简单的方式理解和学习,关注我一起交流成长。
1、关注下方公众号,点击“领资料”即可免费领取电子资料书籍。
2、文章底部点击喜欢作者即可联系作者获取相关数据集和源码。
3、数据算法方向论文指导或就业指导,点击“联系我”添加作者微信直接交流。
4、有商务合作相关意向,点击“联系我”添加作者微信直接交流。

本文来自网友投稿或网络内容,如有侵犯您的权益请联系我们删除,联系邮箱:wyl860211@qq.com 。
随机文章
-
 10个月宝宝每天需要喝多少奶粉?
10个月宝宝每天需要喝多少奶粉?
- 一小时速学python--手册版08--综合项目
- 学习 Python 的免费资源
- 如何在 Windows 上将 Python 脚本打包为 macOS 原生应用
- Chrome将支持ARMLinux;王兴不让叫兴哥;OpenClaw希望百度支持
- Python与C语言交互的秘密武器:bytes转void指针的正确姿势
- 【蝴蝶识别系统】~Python+深度学习+图像识别+人工智能+算法模型+2026原创
- 10分钟掌握 Python操作MySQL数据库之pymysql模块
- python实现智能测试数据工厂
- Linux设备驱动 -- LED驱动(使用PWM子系统)
- 129元→_→带你从0到1学习Python编程
