Python drissionpage模块详细介绍
- 2026-07-03 14:38:35
1. 创始时间与作者
创始时间:DrissionPage 项目首次发布于 2022年3月(首个正式版本 v1.0.0)
核心开发者:
g1879:中国开发者,Python 自动化工具专家
Charles Pik:项目主要维护者,负责核心功能开发
项目定位:融合浏览器自动化和网络请求的下一代 Python 自动化框架
2. 官方资源
GitHub 地址:https://github.com/g1879/DrissionPage
官方文档:https://g1879.gitee.io/drissionpagedocs/
PyPI 地址:https://pypi.org/project/DrissionPage/
3. 核心特点
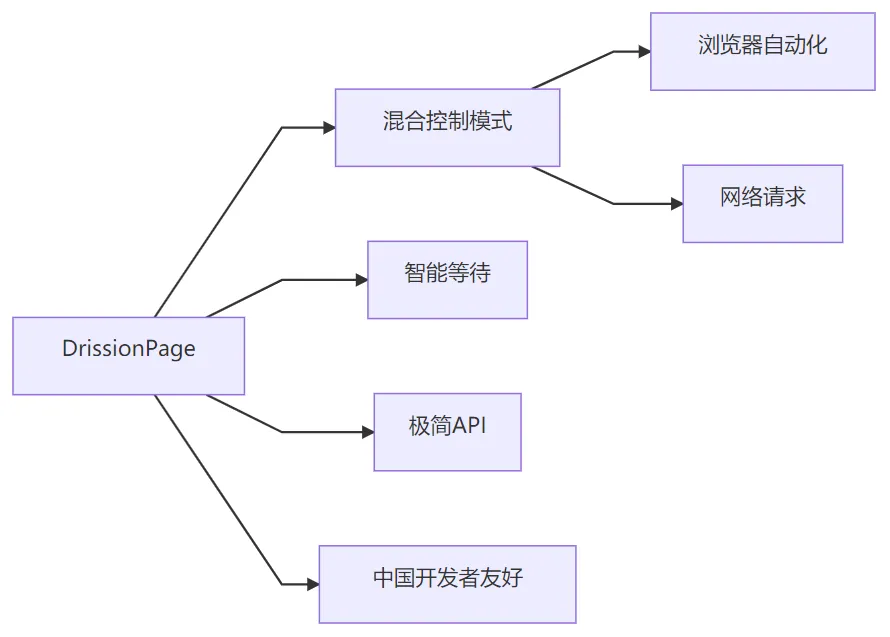
4. 核心功能与应用场景
设计理念:突破传统自动化框架限制,实现 浏览器操作 与 网络请求 的无缝切换
典型场景:
场景类型 传统方案痛点 DrissionPage 解决方案 混合爬虫 Selenium 效率低,Requests 难处理JS 动态页面用浏览器,静态数据切网络请求 数据采集 频繁切换工具 单框架内完成登录(浏览器)+ 数据抓取(HTTP) RPA 流程 浏览器自动化性能差 关键操作用浏览器,批量处理切高效请求模式 复杂测试 无法同时验证前端和API 一套脚本覆盖 UI 操作和接口验证
5. 底层逻辑与架构
双模式引擎:
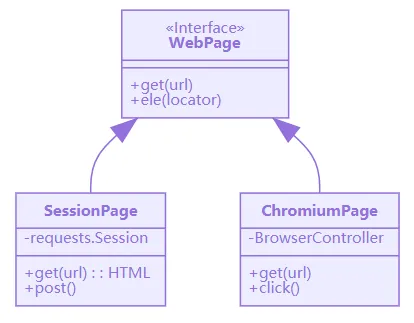
核心技术:
模式切换:浏览器标签页 ↔ 网络请求的无缝转换
智能等待:自动处理元素加载/网络请求
元素定位:增强型 CSS/XPath 定位器
通信机制:基于 Chrome DevTools Protocol 优化
6. 安装与配置
基础安装:
pip install DrissionPage浏览器配置:
from DrissionPage import ChromiumPage# 自动下载浏览器内核(首次使用)ChromiumPage().get('https://www.baidu.com')
两种模式初始化:
# 浏览器模式(默认)page = ChromiumPage()page.get('https://www.example.com')# 网络请求模式session_page = SessionPage()session_page.get('https://api.example.com/data')
7. 核心优势对比
| 特性 | DrissionPage | Selenium | Playwright |
|---|---|---|---|
| 中国网站支持 | 原生优化 | 需额外配置 | 需额外配置 |
| 模式切换 | ⭐⭐⭐ 无缝切换 | ❌ 不支持 | ❌ 不支持 |
| 学习曲线 | ⭐⭐ 简单 | ⭐⭐⭐ 复杂 | ⭐⭐⭐ 复杂 |
| 执行效率 | ⭐⭐⭐ 高效(混合模式) | ⭐⭐ 中等 | ⭐⭐⭐ 高 |
| 依赖项 | ⭐ 极少 | ⭐⭐⭐ 多(驱动) | ⭐⭐ 中等 |
| 中文文档 | ⭐⭐⭐ 完整 | ⭐⭐ 部分 | ⭐ 有限 |
8. 应用场景详解
场景 1:混合模式数据抓取
from DrissionPage import ChromiumPagepage = ChromiumPage()# 浏览器模式登录page.get('https://login.example.com')page.ele('#user').input('username')page.ele('#pwd').input('password')page.ele('#login-btn').click()# 切换网络请求模式获取数据data_page = page.to_session() # 关键:模式切换response = data_page.get('https://data.example.com/api')print(response.json())
场景 2:自动绕过验证码
page = ChromiumPage()page.get('https://target.site')if page.contains('验证码'):# 手动处理验证码page.ele('#captcha-img').click()input("请在浏览器中完成验证码后按回车...")# 继续自动化流程data = page.ele('#result-data').text
场景 3:API 测试与 UI 验证联动
def test_user_flow():# 通过API创建测试数据session = SessionPage()session.post('https://api.example.com/users', data={'name': 'test'})# 浏览器验证UI显示browser = ChromiumPage()browser.get('https://app.example.com/users')assert browser.ele('text=test').exists
9. 进阶功能
页面元素智能定位:
# 支持多种定位方式element = page.ele('@id=username') # 属性定位element = page.ele('text=登录') # 文本定位element = page.ele('tag:div') # 标签定位
下载管理:
page.download.add('https://example.com/file.zip')page.download.wait_all() # 等待所有下载完成
页面截图与PDF:
page.get_screenshot(path='screenshot.png', full_page=True)page.to_pdf(path='page.pdf')
事件监听:
page.listen.start('request') # 监听网络请求page.get('https://example.com')print(page.listen.steps()) # 打印所有请求
10. 性能优化建议
混合模式策略:
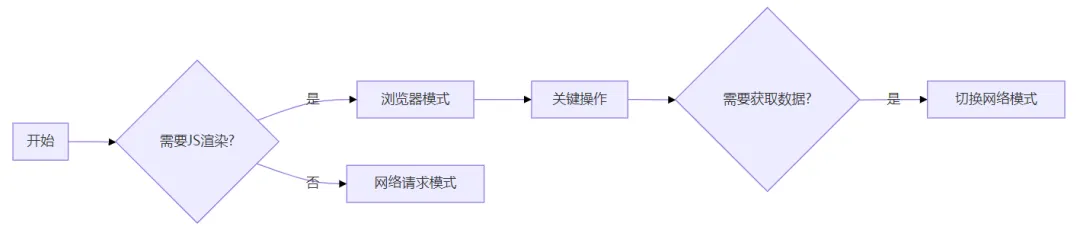
混合模式策略
内存优化配置:
# 创建节省内存的浏览器配置page = ChromiumPage(flags=['--disable-gpu','--single-process','--no-sandbox'])
并发控制:
from DrissionPage import ChromiumPool# 创建浏览器池pool = ChromiumPool(pool_size=3)pool.run(func=task_function, urls=url_list)
总结
DrissionPage 是 Python 自动化领域的革命性框架,特别适合:
需要同时处理 Web 页面操作 和 API 请求 的场景
针对 中文网站 和 国内生态 的自动化需求
期望 低学习成本 实现复杂自动化的开发者
其核心价值在于:
模式融合:打破浏览器操作与网络请求的界限
极简 API:相比 Selenium 代码量减少 40%
中国优化:原生支持国内主流网站和验证方案
智能交互:自动处理元素等待、弹窗等常见痛点
适用人群:
需要高效采集动态网站数据的开发者
国内电商/社交平台自动化运营人员
测试工程师(尤其中文产品)
RPA 流程开发者
通过其创新的混合控制模型,DrissionPage 在保持 Playwright 强大功能的同时,提供了更符合中国开发者习惯的解决方案。

