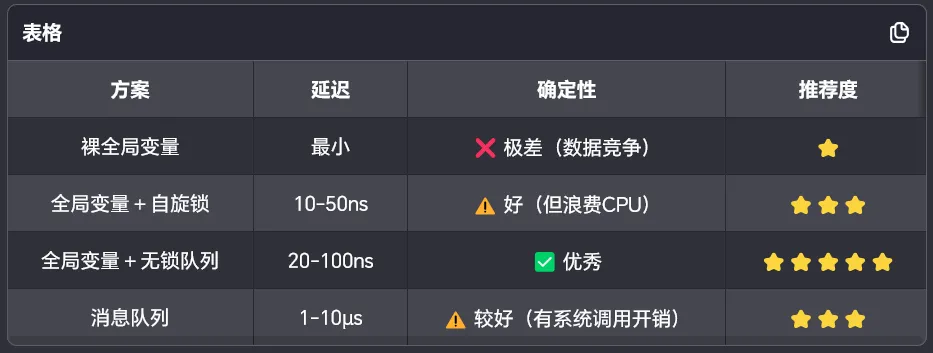
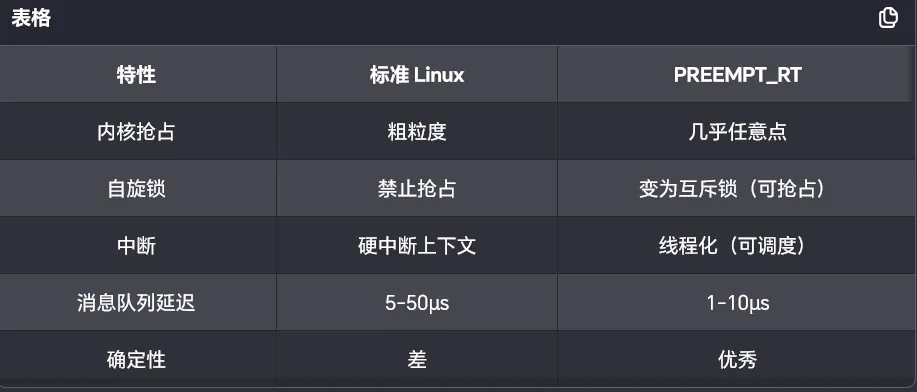
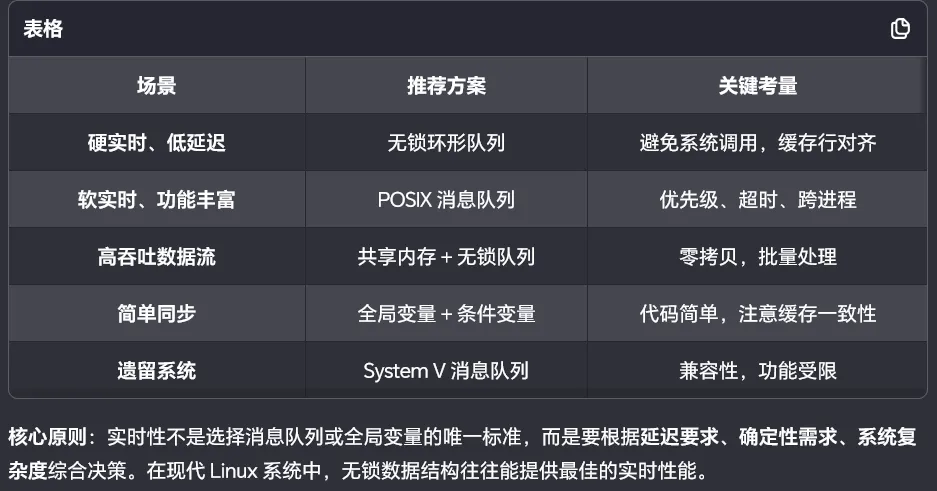
一、核心机制对比总览
维度 | 全局变量 | inux 消息队列 (System V | 实时性影响 |
**同步机制** | 无(需手动加锁) | 内核级原子操作 | 全局变量需自旋锁/互斥锁,引入调度延迟 |
**数据拷贝** | 零拷贝(直接访问 | | 消息队列多两次拷贝,增加延迟 |
**阻塞语义** | 无(轮询或忙等 | 支持阻塞/非阻塞/超时 | 全局变量轮询浪费 CPU,消息队列可精确等待 |
**上下文切换** | 无(访问时可能切换) | 阻塞时主动让出 CPU | 消息队列阻塞减少无效调度 |
**优先级继承** | 无 | | 两者均需额外处理优先级反转 |
二、全局变量通信深度分析2.1 实时性陷阱:非原子操作
// 看似简单的全局变量更新volatile int g_sensor_value = 0; // 传感器数据// 生产者任务(高优先级)voidproducer_task(void) { while (1) { int raw = read_sensor(); // 假设耗时 10us g_sensor_value = raw; // 非原子!可能被打断 }}// 消费者任务(中优先级)voidconsumer_task(void) { while (1) { int val = g_sensor_value; // 可能读到半更新值 process(val); }}
汇编级分析(ARM Cortex-A72)
; g_sensor_value = raw (32位写入)LDR x0, =g_sensor_value ; 加载地址 (1 cycle)STR w1, [x0] ; 存储 (2-10 cycles,可能缓存未命中); 总计 3-11 cycles,但可被中断/抢占!; 64位变量更危险,需要两条指令STR x1, [x0] ; 低32位STR x2, [x0+4] ; 高32位 ← 此处可能被抢占!
2.2 数据竞争实例
时间线 →T0: 生产者读取 raw = 0x12345678T1: 生产者写入低16位,g_sensor_value = 0x00005678T2: [中断] 高优先级中断抢占,延迟 5usT3: 消费者读取 g_sensor_value = 0x00005678 ← 错误!半值T4: 生产者恢复,写入高16位,g_sensor_value = 0x12345678T5: 消费者再次读取,得到正确值
2.3 保护全局变量的锁开销
#include<pthread.h>pthread_mutex_t g_lock = PTHREAD_MUTEX_INITIALIZER;pthread_cond_t g_cond = PTHREAD_COND_INITIALIZER;int g_data_ready = 0;// 带保护的生产者voidproducer_safe(void){ pthread_mutex_lock(&g_lock); // 进入临界区 // 关键:此处可能阻塞,引入调度延迟 // - 若锁被持有,任务挂起,上下文切换 ~1-10us // - 唤醒时再次切换,又 ~1-10us g_sensor_value = read_sensor(); g_data_ready = 1; pthread_cond_signal(&g_cond); // 唤醒消费者 pthread_mutex_unlock(&g_lock); // 退出临界区}// 带保护的消费者voidconsumer_safe(void){ pthread_mutex_lock(&g_lock); while (!g_data_ready) { pthread_cond_wait(&g_cond, &g_lock); // 阻塞等待 // 被唤醒后,锁自动重新获取 } int val = g_sensor_value; g_data_ready = 0; pthread_mutex_unlock(&g_lock);}
实时性损失:| 操作 | 典型延迟 | 最坏情况(锁竞争) ||-----|---------|---------------|| pthread_mutex_lock (无竞争) | 20-50ns | - || pthread_mutex_lock (有竞争) | 1-10μs | 100μs+ (优先级反转) || pthread_cond_wait/wakeup | 5-20μs | 50μs+ || 上下文切换 | 1-3μs | 10μs+ |
三、Linux 消息队列深度分析3.1 System V 消息队列实现
#include<sys/msg.h>#include<sys/ipc.h>// 消息结构(必须含 long mtype)struct msgbuf { long mtype; // 消息类型,支持优先级 char mtext[256]; // 实际数据};// 创建队列key_t key = ftok("/tmp", 'A');int msgid = msgget(key, IPC_CREAT | 0666);// 发送(非阻塞模式)voidsend_realtime(int msgid, int priority, void* data, size_t len){ struct msgbuf msg; msg.mtype = priority; // 小数字 = 高优先级 memcpy(msg.mtext, data, len); // IPC_NOWAIT: 队列满立即返回,不阻塞 int ret = msgsnd(msgid, &msg, len, IPC_NOWAIT); if (ret == -1 && errno == EAGAIN) { // 实时性保障:立即知道失败,可丢弃或降级 handle_overflow(); }}// 接收(带超时)voidrecv_realtime(int msgid, int* data, int timeout_ms){ struct msgbuf msg; // 使用 select/poll 实现超时,或信号驱动 struct timespec ts = { .tv_sec = timeout_ms / 1000, .tv_nsec = (timeout_ms % 1000) * 1000000 }; // MSG_NOERROR: 截断超长消息,不失败 // 按优先级接收:mtype = -10 表示接收类型 ≤10 的最高优先级 ssize_t n = msgrcv(msgid, &msg, sizeof(msg.mtext), -10, IPC_NOWAIT | MSG_NOERROR); if (n == -1) { if (errno == ENOMSG) { // 无消息,立即返回,不阻塞 *data = DEFAULT_VALUE; // 使用默认值保障实时性 } } else { memcpy(data, msg.mtext, n); }}
3.2 POSIX 消息队列(更实时友好)
#include<mqueue.h>#include<time.h>// 创建带属性的队列(实时关键)struct mq_attr attr = { .mq_flags = O_NONBLOCK, // 非阻塞模式 .mq_maxmsg = 100, // 最大消息数 .mq_msgsize = 256, // 单消息最大 .mq_curmsgs = 0};mqd_t mq = mq_open("/rt_queue", O_CREAT | O_RDWR, 0666, &attr);// 发送带超时voidmq_send_timed(mqd_t mq, void* data, size_t len, unsigned prio){ struct timespec ts; clock_gettime(CLOCK_REALTIME, &ts); ts.tv_nsec += 100000; // 100us 超时 int ret = mq_timedsend(mq, data, len, prio, &ts); // prio: 0-31,数字大优先级高 if (ret == -1 && errno == ETIMEDOUT) { // 超时处理,保障确定性 }}// 接收带超时voidmq_recv_timed(mqd_t mq, void* buffer, size_t len){ struct timespec ts; clock_gettime(CLOCK_REALTIME, &ts); ts.tv_sec += 0; // 立即返回 ts.tv_nsec += 50000; // 50us 超时 ssize_t n = mq_timedreceive(mq, buffer, len, NULL, &ts); if (n == -1 && errno == ETIMEDOUT) { // 使用上一周期数据或预测值 }}
3.3 消息队列内核路径分析
用户空间调用 mq_send() ↓系统调用入口 (syscall) ~50-100ns ↓内核:mq_send() 处理 ├── 权限检查 ~100ns ├── 查找消息队列对象 ~200ns (红黑树) ├── 检查队列空间 │ └── 有空间:复制数据 │ copy_from_user() ~500ns-5μs (取决于大小) │ └── 无空间:处理 O_NONBLOCK │ 或加入等待队列 ├── 唤醒等待的接收者(如有) │ schedule() 如果需要 ~1-3μs └── 返回 ↓用户空间恢复 ~50-100ns总计(无阻塞): 1-10μs总计(有唤醒): 5-20μs
四、实时性关键场景对比4.1 硬实时场景(截止时间 < 100μs)
// 硬实时首选:无锁环形队列(单生产者单消费者)typedef struct { alignas(64) volatile uint32_t head; alignas(64) volatile uint32_t tail; uint8_t buffer[1024][64]; // 64字节对齐} LockFreeRing;// 零系统调用,纯用户空间,缓存行对齐// 延迟:读-改-写操作 ~10-50ns
4.2 软实时场景(截止时间 100μs - 10ms)
4.3 数据流场景(高吞吐,延迟可接受)
生产者 → [消息队列] → 消费者 ↑ 缓冲作用优势:- 生产者和消费者速率解耦- 突发流量平滑- 支持多生产者/多消费者- 天然背压(队列满时丢弃或阻塞)
五、Linux 实时性增强机制5.1 PREEMPT_RT 补丁影响
// PREEMPT_RT 下,消息队列更可靠// 但全局变量+锁也更慢(自旋锁变成可睡眠)5.2 内存映射消息队列(零拷贝)#include<sys/mman.h>// 创建共享内存 + 无锁队列typedef struct { sem_t sem_prod; // 生产者信号量 sem_t sem_cons; // 消费者信号量 LockFreeRing ring; // 无锁环形缓冲区} SharedQueue;SharedQueue* create_shared_queue(constchar* name){ int fd = shm_open(name, O_CREAT | O_RDWR, 0666); ftruncate(fd, sizeof(SharedQueue)); SharedQueue* sq = mmap(NULL, sizeof(SharedQueue), PROT_READ | PROT_WRITE, MAP_SHARED, fd, 0); sem_init(&sq->sem_prod, 1, QUEUE_SIZE); // 跨进程 sem_init(&sq->sem_cons, 1, 0); return sq;}// 发送:零拷贝到共享内存voidshared_send(SharedQueue* sq, void* data, size_t len){ sem_wait(&sq->sem_prod); // 等待空槽(可超时) // 直接写入共享内存,无内核拷贝 uint32_t tail = sq->ring.tail; memcpy(sq->ring.buffer[tail & MASK], data, len); __atomic_store_n(&sq->ring.tail, tail + 1, __ATOMIC_RELEASE); sem_post(&sq->sem_cons); // 通知消费者}
六、决策树与最佳实践
开始 │ ▼硬实时要求?(截止时间 < 100μs) │ ├── 是 ──► 单生产者单消费者? │ │ │ ├── 是 ──► 无锁环形队列(数组) │ │ 延迟:10-50ns,确定性优秀 │ │ │ └── 否 ──► 多读多写? │ │ │ ├── 是 ──► 无锁链表(Michael-Scott) │ │ 延迟:100-500ns │ │ │ └── 否 ──► 全局变量 + 读写锁 │ 延迟:50-200ns │ └── 否 ──► 需要跨进程? │ ├── 是 ──► POSIX 消息队列(mq_open) │ 延迟:1-10μs,功能丰富 │ └── 否 ──► 同进程多线程? │ ├── 是 ──► 条件变量 + 全局变量 │ 延迟:5-20μs,简单 │ └── 否 ──► System V 消息队列 延迟:5-50μs,兼容旧代码