10分钟掌握 2026版 Python爬虫 之BeautifulSoup 网页解析模块
- 2026-07-03 16:58:59
概述
搞定网页解析,用 BeautifulSoup 就够了!从模块安装到本地文件解析,再到实战抓取 cnblog 首页帖子,跟着练,轻松把网页里的干货 “扒” 出来用~
BeautifulSoup 网页解析模块
(一)beautifulsoup 模块简介及安装
简单来说,Beautiful Soup 是 python 的一个库,最主要的功能是从网页抓取数据。官方解释如下:
Beautiful Soup 提供一些简单的、python 式的函数用来处理导航、搜索、修改分析树等功能。它是一个工具箱,通过解析文档为用户提供需要抓取的数据,因为简单,所以不需要多少代码就可以写出一个完整的应用程序。 Beautiful Soup 自动将输入文档转换为 Unicode 编码,输出文档转换为 utf-8 编码。你不需要考虑编码方式,除非文档没有指定一个编码方式,这时,Beautiful Soup 就不能自动识别编码方式了。然后,你仅仅需要说明一下原始编码方式就可以了。 Beautiful Soup 已成为和 lxml、html6lib 一样出色的 python 解释器,为用户灵活地提供不同的解析策略或强劲的速度。
beautifulsoup 可以简称 bs4
beautifulsoup4 安装
pip install beautifulsoup4
-i https://pypi.tuna.tsinghua.edu.cn/simple
(二)beautifulsoup 解析本地文件之基础语法
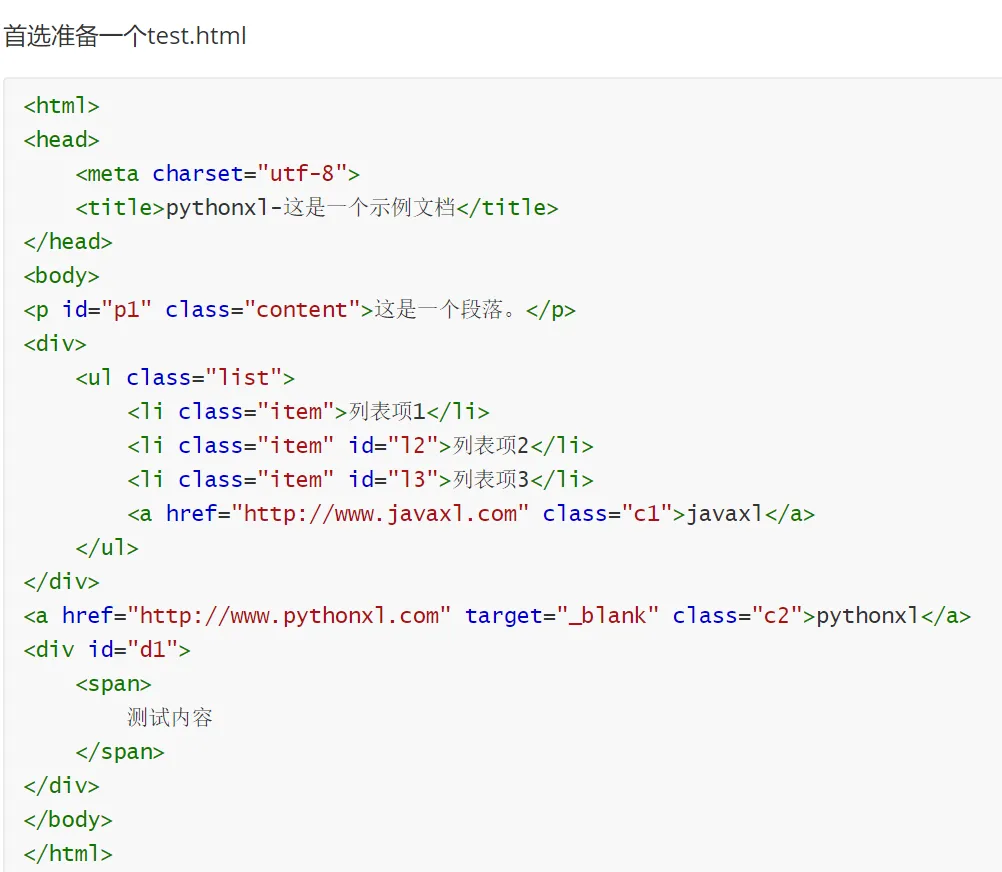
beautifulsoup 支持解析本地文件和网络文件,需要注意的是在实例化 BeautifulSoup 对象时,“html.parser” 是一个解析器,用于解析 HTML 代码,可以使用其他解析器,如 lxml、html5lib 等
通过 bs4 对象,可以使用多种方式来获取 HTML 中的元素信息,包括标签名、属性、文本等。


知识点总结:
BeautifulSoup 实例化:读取本地 HTML 文件时指定编码为 utf-8(解决 Windows 默认 gbk 编码问题),使用 Python 内置的 html.parser 解析器完成实例化。
基础标签节点获取:通过soup.标签名获取 HTML 中第一个匹配该标签的 DOM 节点,可查看节点类型、标签名称。
标签属性基础获取:通过attrs属性获取标签的所有属性(返回字典类型),并可通过键名直接提取指定属性值。
标签文本内容获取:通过string属性获取标签内的纯文本内容(仅适用于标签内无嵌套其他标签的场景)。
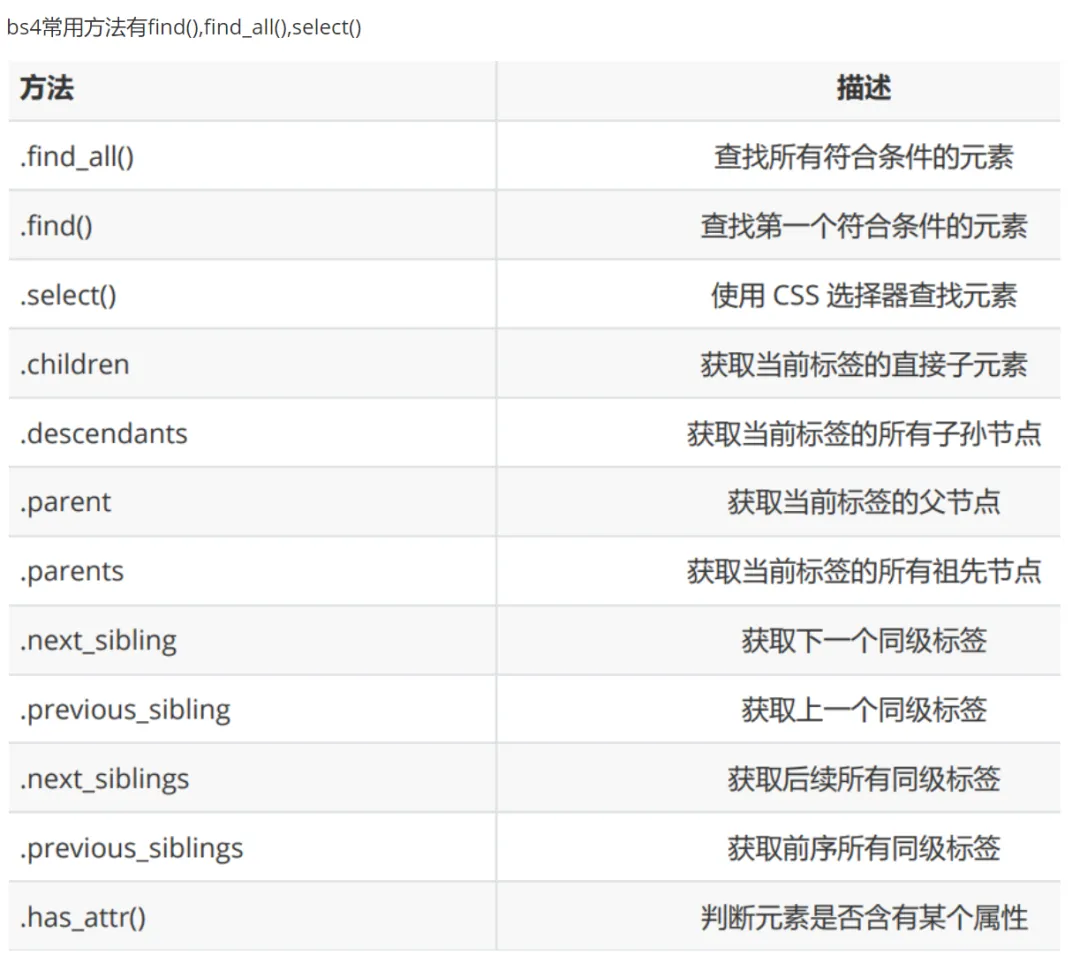
find 方法使用:查询并返回第一个符合条件的元素,支持按标签名、属性(如 target)筛选,class 属性需用 class_关键字(避免与 Python 关键字冲突)。
find_all 方法使用:返回所有符合条件的元素列表,支持多标签批量查询、通过 limit 参数限制返回结果数量。
select 方法(CSS 选择器):返回匹配的元素列表,支持标签选择器、类选择器(. 类名)、id 选择器(#id 名)。
CSS 属性选择器:select 方法支持按属性存在性(如 li [id])、属性具体值(如 li [id="l3"])筛选元素。
CSS 层级选择器:后代选择器(空格分隔)匹配标签下所有层级的后代节点,子代选择器(> 分隔)仅匹配直接子节点。
节点文本内容进阶获取:string 属性仅适用于无嵌套标签的节点,get_text () 可获取含嵌套标签节点的全部文本,结合 strip () 可去除文本首尾空白。
节点属性进阶操作:通过 name 属性获取标签名;可通过 attrs 字典、直接键访问、get 方法三种方式提取属性值,其中 get 方法更灵活安全。
(三)网络抓取和解析 cnblog 首页帖子数据
知识点:
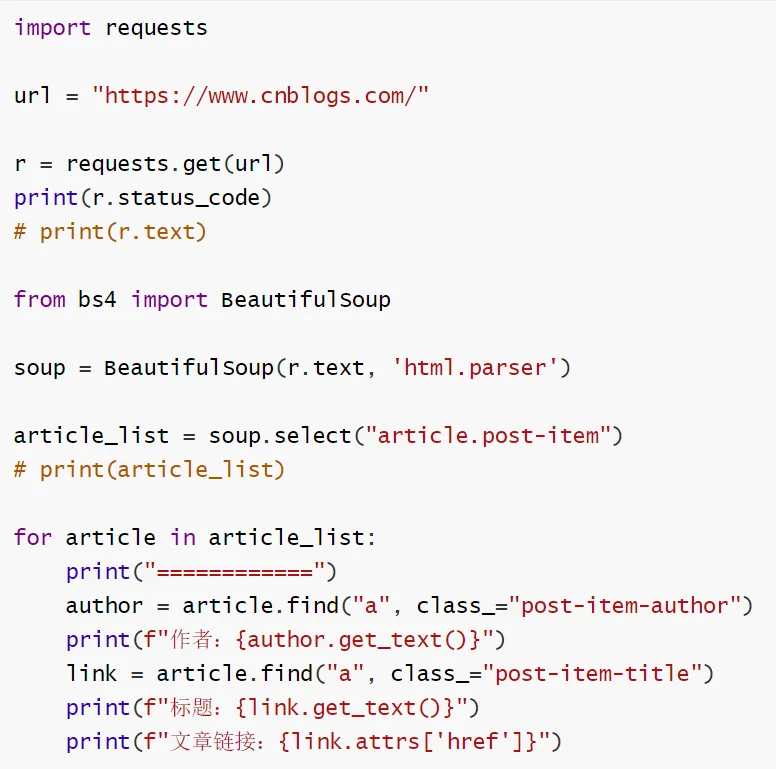
使用requests.get()发送 GET 请求获取网络页面内容,通过status_code属性查看 HTTP 响应状态码,验证请求是否成功。
BeautifulSoup 解析网络响应文本:将requests返回的网页文本(r.text)传入 BeautifulSoup,使用html.parser解析器实例化对象,实现对网络 HTML 内容的解析。
CSS 类选择器批量获取节点:通过soup.select()结合类选择器(post-item)获取页面中所有文章项的节点列表,返回可遍历的元素集合。
遍历节点列表提取数据:循环遍历select获取的文章节点列表,逐个处理单篇文章的信息。
局部节点精准查询:基于已获取的父节点(article)使用find方法,按标签名 + class 属性(post-item-author、post-item-title)精准查找子节点,缩小查询范围。
节点文本内容提取:使用get_text()方法提取标签内的文本内容(作者名、文章标题),适配节点内有无嵌套标签的场景。
节点属性值提取:通过attrs['href']获取标签的 href 属性值,提取文章的链接地址。
基础爬虫流程实现:完成「发送网络请求→解析 HTML 内容→定位目标节点→提取结构化数据」的完整爬虫基础流程。

结束语
1
后续我会持续输出优质、实用的内容,也欢迎大家在评论区留言,说说你们最想学习的内容、遇到的困惑,我们一起交流、一起进步。
愿每一位软件人,都能在这里收获知识、突破自我,在自己的赛道上发光发热✨
以上内容仅做学习所用,如有侵权联系必删
随机文章
-
 10个月宝宝每天需要喝多少奶粉?
10个月宝宝每天需要喝多少奶粉?
- PHP代码审计实战:发现并修复安全漏洞
- Arch Linux衍生版EndeavourOS代号泰坦的版本新特性,新工具解决驱动问题,让ARM版本重生
- 从 UNIX 昂贵到 Linux 免费,再到红帽“订阅模式”:一场开源革命的商业真相
- PHP 中的延迟静态绑定
- 这个宝藏软件能让我轻松学习python啊
- wooey,一个轻量化的 Python 库
- OpenClaw 技能开发系列:Python 脚本调用实战指南
- 《花了2万多买的Python教程全套,现在分享给大家,入门到精通 全栈开发教程》」
- 【教程】基于R、Python的Copula变量相关性分析及AI大模型应用
- 超强Python知识手册,整整773页,附高清PDF
