在正式介绍这些生产案例之前,我们先了解一些比较常见的系统巡检步骤,在日常监控巡检的时候,我们一般先查看系统的运行基本信息,所以我们优先会执行uptime查看系统整体运行情况和负载,以笔者的输出为例,可以看到uptime输出显示如下消息:
1. 系统时间为23:08:23
2. 当前系统运行1天4小时多
3. 当前系统有3个登录会话
4. 系统近1min、15min、30min的系统负载稳定在0
uptime指令可以反映一个时间段的系统运行负载,一般来说,若近1min的值远远低于15和30min的值,这可能就说明我们错过了系统反馈的故障:
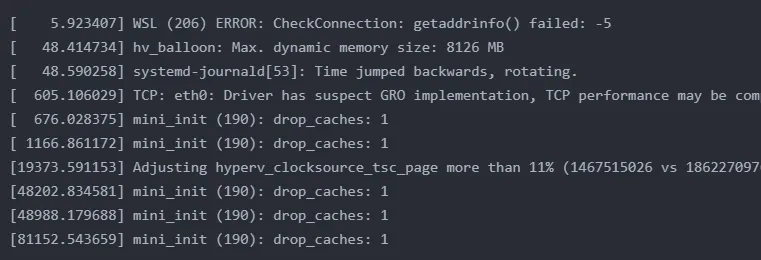
然后我们就通过dmesg |tail查看内核环形缓冲区的消息,通过该指令可以看到一些系统消息,检查运行时报错,以笔者服务器的输出结果来看:
1. 网络连接初始化失败
2. hv_balloon动态内存信息
3. Time jumped backwards, rotating即因为某个原因系统向后跳动了
4. 系统缓存清理
1. swpd: 已使用的交换空间大小,如果该值持续增长,说明物理内存不足
2. free: 空闲的物理内存大小
3. buff: 用于文件系统缓冲的内存大小
4. cache: 用于缓存文件数据的内存大小
针对磁盘I/O参数组:
1. bi/bo: 每秒从磁盘读取/写入的数据块数
2. si/so: 每秒从磁盘交换进/出内存的数据块数,如果这两个值持续大于0,说明内存不足
CPU参数组:
1. us: 用户态CPU使用百分比
2. sy: 内核态CPU使用百分比
3. id: CPU空闲百分比
4. wa: 等待I/O完成的CPU时间百分比,如果该值持续较高,说明存在I/O瓶颈
从以上输出可以看出,系统当前状态良好:CPU空闲率100%,无进程等待I/O,无内存交换发生。
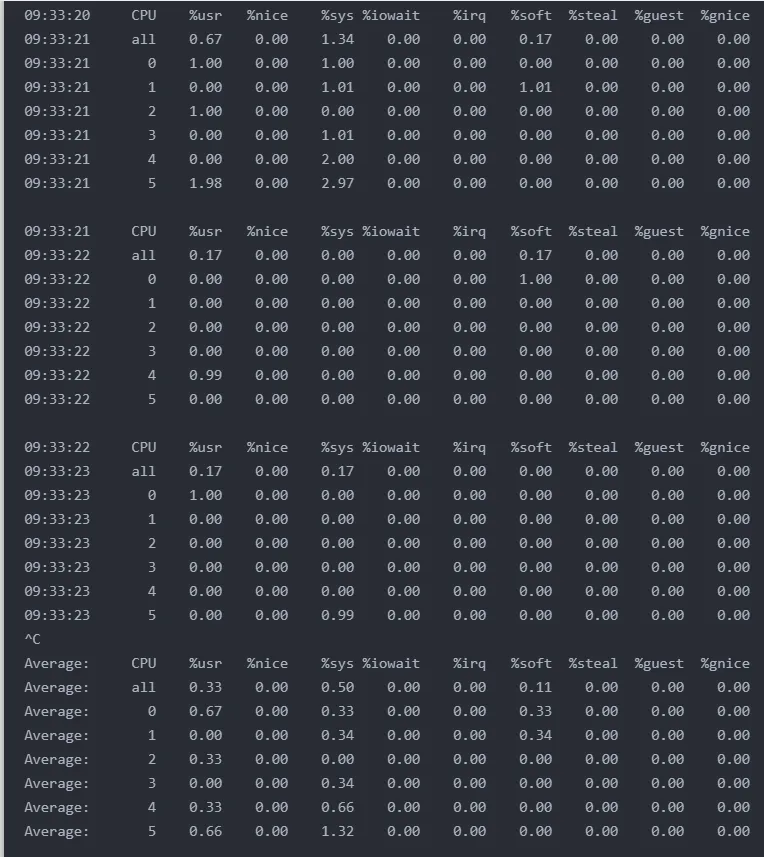
CPU亲和力是指进程或线程绑定到特定CPU核心的特性。通过检查各CPU核心的使用率分布,可以判断是否存在CPU负载不均衡的情况。执行mpstat -P ALL 1可以查看每个CPU核心的使用情况。
从笔者的输出结果来看,各CPU核心的使用率分布相对均匀,没有出现某个CPU核心使用率异常飙升的情况。如果某个CPU核心使用率持续接近100%,而其他核心相对空闲,则可能说明存在以下问题:
1. 单线程应用无法充分利用多核CPU资源
2. 进程调度问题导致负载集中在特定核心
3. 某个线程在特定核心上出现死循环或计算密集型任务
从平均值来看,系统整体CPU使用率较低,各核心负载分布相对均衡,说明CPU资源利用合理。
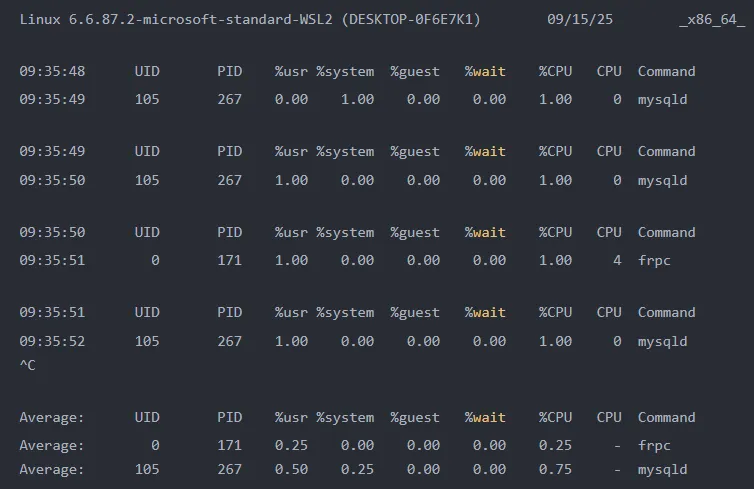
pidstat命令用于监控进程的CPU、内存、I/O等资源使用情况。与top命令不同,pidstat不会清屏刷新,而是以滚动方式显示进程信息,便于观察一段时间内的进程负载变化。执行pidstat 1可以每秒输出一次进程统计信息。输出字段说明:
1.UID: 进程所属用户ID
2.PID: 进程ID
3.%usr: 进程在用户态消耗的CPU百分比
4· %system: 进程在内核态消耗的CPU百分比
5· %guest: 进程在虚拟机中消耗的CPU百分比
6.%wait: 进程等待CPU的时间百分比7. %CPU: 进程总的CPU使用百分比8.CPU: 进程当前运行的CPU核心编号9.Command: 进程命令名称
从输出结果可以看出:
1. mysqld进程(PID 267)在系统态有较高的CPU使用率,说明该进程主要进行内核态操作
2. frpc进程(PID 171)在用户态有CPU使用,说明该进程主要进行用户态计算
3. 从平均值来看,两个进程的CPU使用率都不高,系统负载较轻。
free命令用于查看系统内存使用情况,包括物理内存和交换空间的使用统计。一般情况下我们使用free -m以MB为单位查看内存使用情况。输出字段说明:
1.total: 内存总量
2.used: 已使用的内存
3.free: 空闲的内存
4.shared: 多个进程共享的内存
5.buff/cache: 用于缓冲和缓存的内存
6.available: 可用内存(包括可回收的缓存和缓冲区内存)
1. 物理内存总量为7876MB,已使用828MB,空闲6915MB,内存使用率较低
2. buff/cache占用289MB,这部分内存可以在需要时被回收
3. available内存为7048MB,说明系统有充足的可用内存
4. 交换空间总量2048MB,已使用0MB,说明物理内存充足,未发生内存交换
需要注意的是,Linux系统会尽可能利用空闲内存作为文件系统缓存,因此free值较低并不一定表示内存不足。应重点关注available字段和交换空间使用情况来判断内存是否充足。
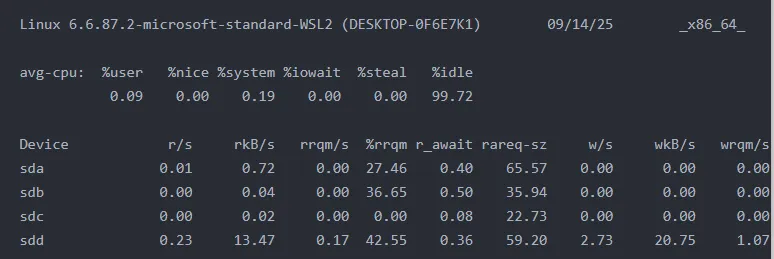
iostat命令用于监控系统设备的I/O负载情况。使用iostat -xz 1可以详细查看磁盘的读写性能指标,其中:
1. x: 显示扩展统计信息
2. -z: 跳过无活动的设备
3. 1: 每秒刷新一次
1. r/s、w/s: 每秒读/写请求数
2. rkB/s、wkB/s: 每秒读/写的数据量(KB)
3. await: I/O请求的平均等待时间(ms),包括排队时间和处理时间
4. avgqu-sz: 平均I/O请求队列长度,如果大于1说明设备可能已饱和
5. util: 设备使用率百分比,如果持续高于80%说明设备可能成为瓶颈
1. 各磁盘设备的I/O请求很少,r/s和w/s值都很低
2. await值都很小,说明I/O响应时间很短
3. util值都很低,说明磁盘设备使用率很低,没有出现瓶颈
4. avgqu-sz值都小于1,说明I/O请求队列长度正常
整体来看,系统磁盘I/O性能良好,没有出现性能瓶颈。
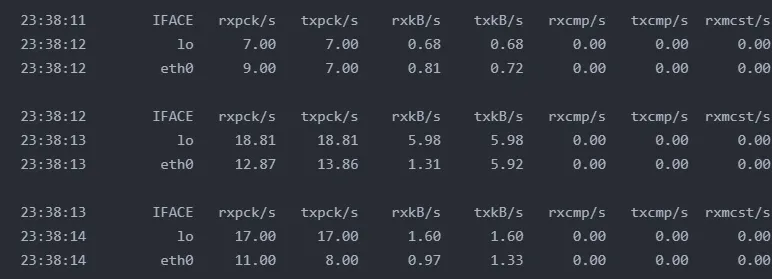
sar命令可以监控网络接口的流量情况。使用sar -n DEV 1可以每秒输出网络接口的统计信息。
输出字段说明:
1.IFACE: 网络接口名称
2.rxpck/s: 每秒接收的数据包数量
3.txpck/s: 每秒发送的数据包数量
4.rxkB/s: 每秒接收的数据量(KB)
5.txkB/s: 每秒发送的数据量(KB)
6.%ifutil: 网络接口使用率百分比
从输出结果可以看出:
1. lo接口是本地回环接口,用于本机通信
2. eth0是实际的网络接口
3. 数据包收发量和数据流量都比较小
4. %ifutil值为0,说明网络接口使用率很低,没有出现网络瓶颈
为了更准确地判断网络性能,还需要结合网络带宽信息进行分析。
上述指标反映了网络I/O的整体情况,实际上我们可能还需要结合带宽进行判断。ethtool命令可以查看网卡的详细信息,包括连接速度、双工模式等。
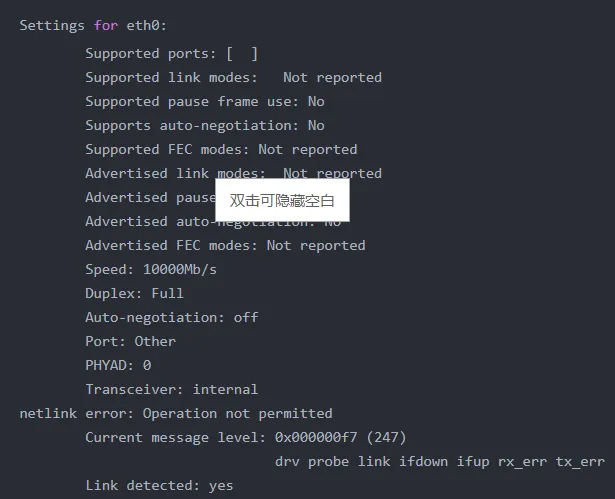
然后通过ethtool eth0查看网卡的带宽连接速度:
从输出结果可以看出:
1. 网卡连接速度为10000Mb/s(即10Gb/s),这是一个很高的带宽
2. 工作模式为全双工(Full Duplex)
3. Link detected: yes 表示网络连接正常
结合之前的sar输出数据,eth0接口的rxkB/s和txkB/s值都很小,远低于10Gb/s的带宽上限,说明网络带宽使用率很低,网络资源充足。















 10个月宝宝每天需要喝多少奶粉?
10个月宝宝每天需要喝多少奶粉?
