你真的熟练Python吗?!!!
- 2026-07-03 15:40:54
面试Python开发,最忌讳“只会用,不会说”——很多候选人能熟练写出代码,却被面试官一句“Python的内存管理和Java有什么区别”“装饰器底层怎么实现的”问懵,最终错失offer。
其实Python面试的核心,本质是考察你对「底层原理」的掌握程度。不同于表面的API调用,底层知识能直接体现你的技术深度,证明你不是“调包侠”,而是真正熟练掌握Python的开发者。
今天就把Python面试中高频的底层八股文,一次性讲透,覆盖内存管理、迭代器生成器、元类、进程线程等核心模块,帮你轻松应对面试官的灵魂拷问。

一、先搞懂:Python与其他主流语言的内存管理差异
面试时,面试官常先问这个问题,目的是看你对多语言的认知的同时,引出Python内存管理的核心。我们重点对比Java、C++,抓核心差异,不用死记硬背:
C++:手动内存管理,程序员需通过new/delete手动分配和释放内存,灵活但易出现内存泄漏、野指针问题,完全依赖开发者的经验。
Java:自动内存管理,依赖JVM的垃圾回收(GC)机制,采用“分代回收”(年轻代、老年代),但对象创建后会进入堆内存,垃圾回收时会有Stop-The-World(STW)停顿。
Python:兼顾自动性和灵活性,采用“引用计数为主,标记清除+隔代回收为辅”的混合内存管理机制,无需手动管理内存,且STW停顿时间更短,同时支持手动释放内存(如del语句)。
核心考点:不用罗列所有差异,重点说清Python“引用计数”的独特性,以及与Java分代回收的区别,就能体现你的认知。

二、重点吃透:Python内存管理机制
2.1. 核心基础:引用计数(Reference Counting)
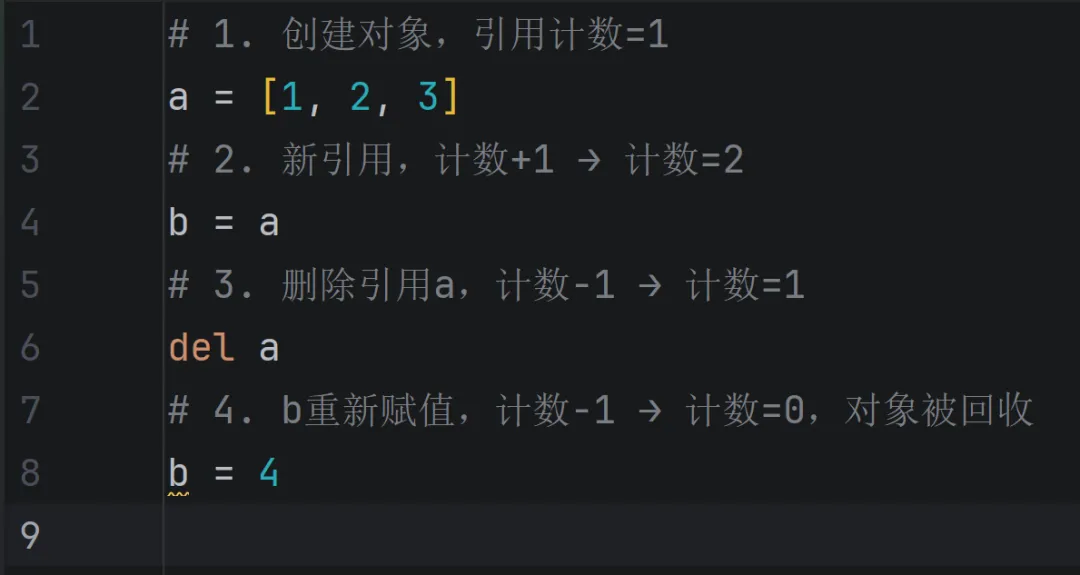
Python中,一切皆对象(int、str、list、函数等都是对象),每个对象都有一个“引用计数器”,用于记录当前有多少个变量引用该对象。
工作原理:当对象被创建时,引用计数设为1;当有新的变量引用该对象时,计数+1;当引用失效(如变量被删除、赋值给其他对象)时,计数-1;当引用计数变为0时,对象会被立即回收,释放占用的内存。
2.2. 补充机制:标记清除(Mark-Sweep)
专门解决引用计数无法处理的“循环引用”问题,是Python的“二级垃圾回收机制”,分为两个阶段:
标记阶段:从“根对象”(如全局变量、当前栈帧中的变量)出发,遍历所有可达的对象,标记为“存活”;不可达的对象(即没有任何根对象引用,且互相循环引用的对象)标记为“垃圾”。
清除阶段:遍历所有对象,回收被标记为“垃圾”的对象,释放内存。
注意:标记清除会触发STW(暂停所有用户线程),但Python会控制触发频率,减少对程序运行的影响。
2.3. 优化机制:隔代回收(Generational Collection)
基于一个核心规律:大多数对象的生命周期很短(比如临时变量,创建后很快被回收),少数对象的生命周期很长(比如全局变量)。
Python将对象分为3个“代”,根据生命周期长短分别管理,减少垃圾回收的开销:
0代(年轻代):新创建的对象都属于0代,垃圾回收频率最高(每次对象创建/销毁达到一定阈值,就触发0代回收),回收速度最快。
1代(中年代):0代回收后存活下来的对象,会进入1代,回收频率低于0代。
2代(老年代):1代回收后存活下来的对象,会进入2代,回收频率最低,只有当2代对象达到一定阈值时才触发回收。
核心优势:不用每次都遍历所有对象,只重点回收生命周期短的年轻代对象,大幅提升垃圾回收效率。
2.4. 延伸:Python对象的生命周期
结合上面的内存管理机制,Python对象的完整生命周期可总结为5步,面试时能说清这5步,直接加分:
创建:通过关键字(如list、dict)或函数(如range)创建对象,分配内存,初始化引用计数为1。
引用:多个变量引用该对象,引用计数递增。
存活:对象被根对象可达,引用计数保持≥1,正常使用。
垃圾标记:当引用计数为0,或被标记清除机制标记为“不可达”,成为垃圾。
回收:通过引用计数实时回收,或通过标记清除、隔代回收批量回收,释放内存。
三、高频考点:迭代器与生成器的区别
3.1. 迭代器(Iterator)
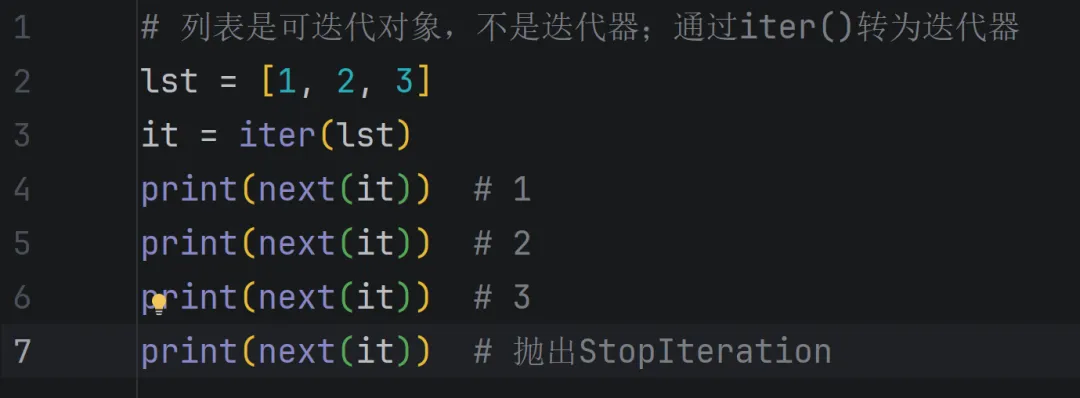
定义:实现了iter()和next()方法的对象(iter返回自身,next返回下一个元素,没有元素时抛出StopIteration异常)。
特点:可迭代(能被for循环遍历),一次性生成所有元素,占用内存较多。
3.2. 生成器(Generator)
定义:一种特殊的迭代器,通过yield关键字实现,无需手动实现iter和next方法。
特点:惰性生成,每次调用next()才生成一个元素,生成后立即释放,占用内存极少;生成器函数执行时,遇到yield会暂停,再次调用时从暂停位置继续执行。

3.3. 核心区别
内存占用:迭代器一次性生成所有元素,内存占用高;生成器惰性生成,内存占用极低。
实现方式:迭代器需手动实现iter和next;生成器通过yield自动实现,代码更简洁。
执行机制:迭代器一旦创建,元素就已存在;生成器只有调用next()才生成元素,可暂停/继续执行。

四、底层原理:With语句的实现机制
面试常问:“with语句为什么能自动关闭资源(如文件、数据库连接)?底层怎么实现的?”
核心答案:with语句的底层是上下文管理器(Context Manager),即实现了enter()和exit()两个方法的对象。
4.1. 执行流程(面试必说)
执行with后的表达式,获取上下文管理器对象。
调用上下文管理器的enter()方法,返回的值会赋值给as后的变量(可选)。
执行with块内的代码。
无论块内代码是否抛出异常,都会调用上下文管理器的exit()方法,释放资源(如关闭文件、断开数据库连接)。
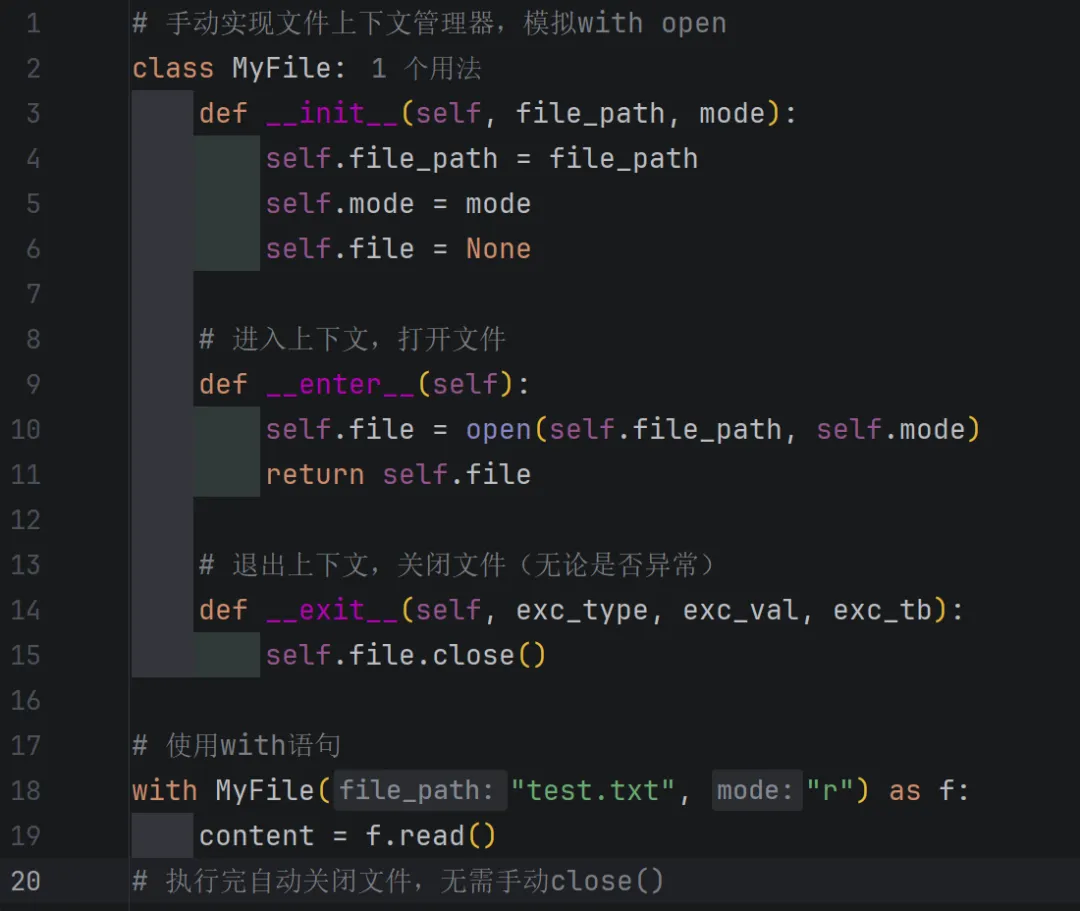
4.2. 示例(手动实现一个上下文管理器)

五、进阶考点:元类(MetaClass)—— Python的“类的类”
元类是Python中最抽象、最难理解的知识点之一,也是区分初级和高级开发者的关键,面试时能说清核心逻辑就够了,不用过度深入。
5.1. 核心定义
Python中,类也是对象(一切皆对象),而元类就是“创建类的类”——普通类是元类的实例,元类负责生成普通类。
默认情况下,Python的所有类的元类是type(即type是所有类的“父类”)。
5.2. 关键逻辑(面试简化版)
我们定义的类(如class A: ...),本质是通过type元类创建的实例。
元类的作用:控制类的创建过程(比如修改类的属性、方法),实现类的个性化定制(如单例模式、强制类必须实现某个方法)。
自定义元类:继承type,重写new()或init()方法,控制类的创建。
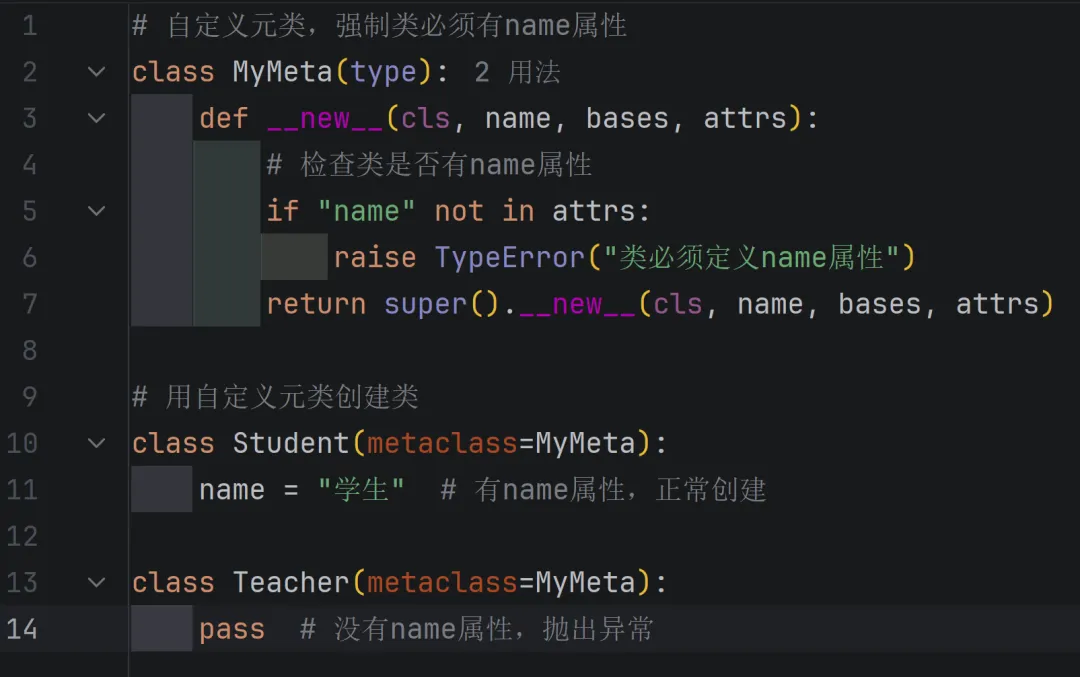
5.3. 简单示例

六、常用进阶:装饰器、Mixin混入类
6.1. 装饰器(Decorator)
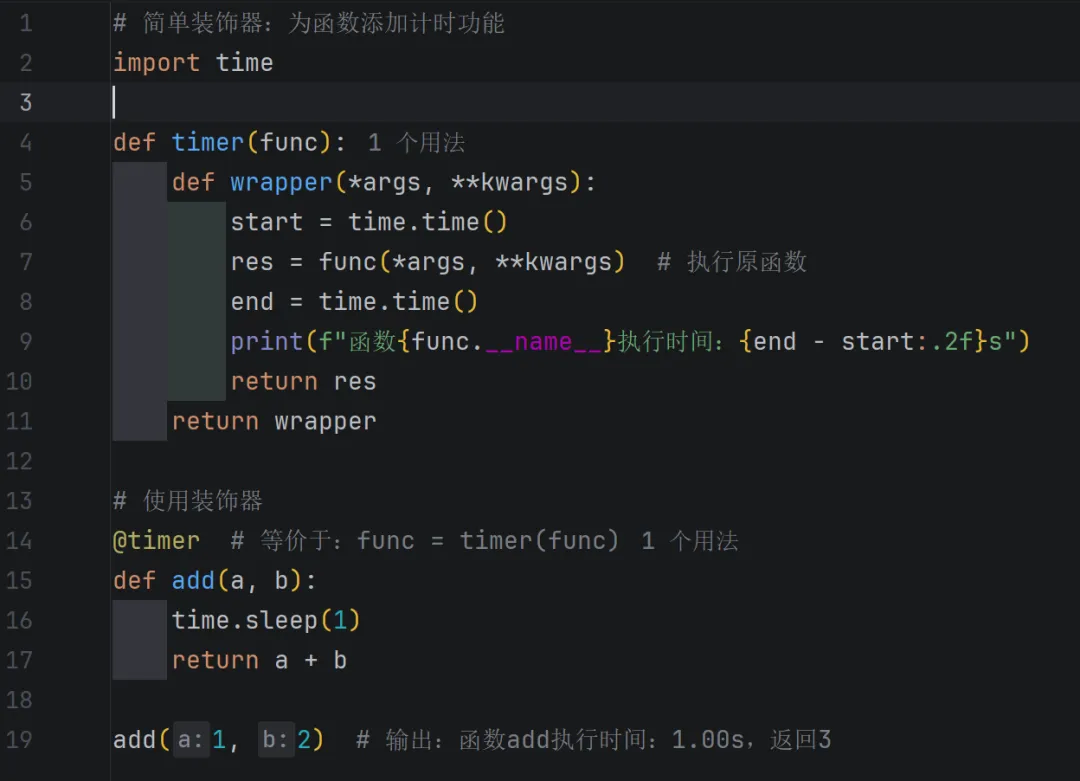
定义:一种“函数包装器”,本质是高阶函数(接受函数作为参数,返回一个新函数),用于在不修改原函数代码的前提下,为函数添加额外功能(如日志、计时、权限校验)。
底层原理:通过@语法糖,将原函数作为参数传入装饰器函数,返回的新函数替代原函数。
6.2. Mixin混入类
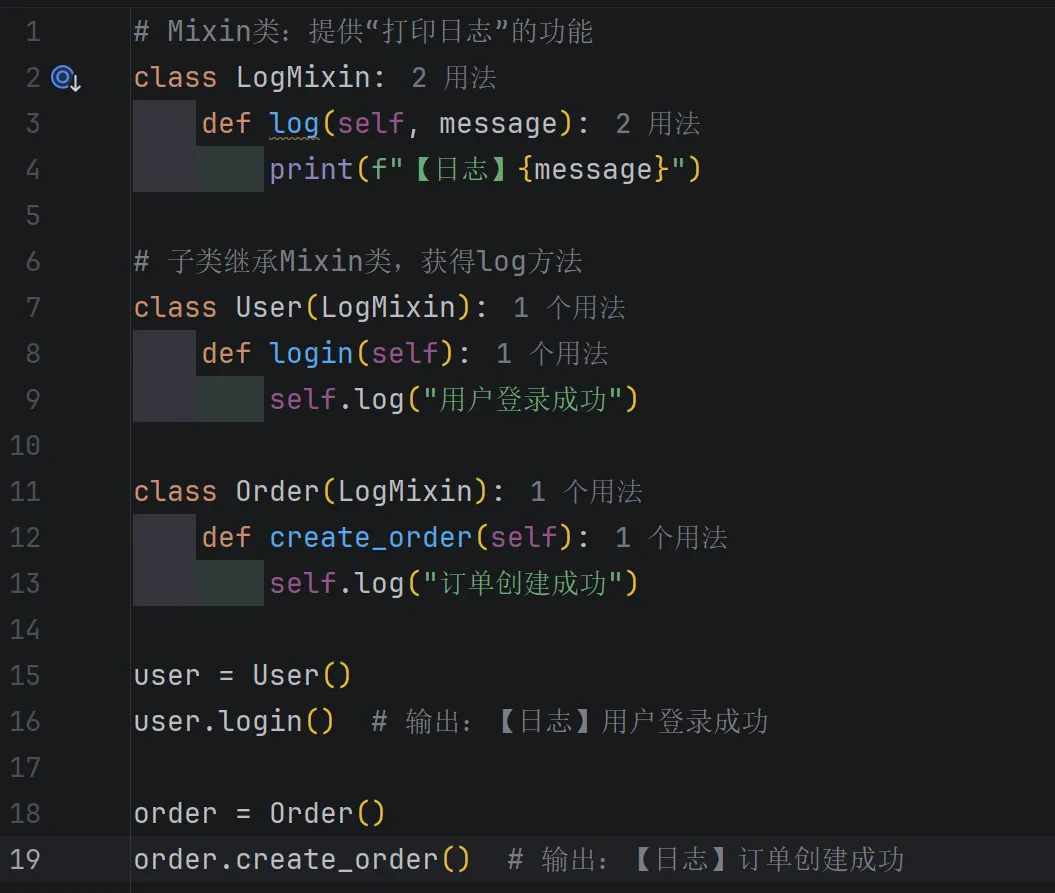
定义:一种“代码复用”的设计模式,本质是没有实例化意义的抽象类,用于给其他类添加额外的方法,不影响原类的继承关系。
核心特点:不单独实例化,只作为“混入”,通过多继承的方式,让子类获得Mixin类的方法。

七、并发编程:进程、线程、协程
1. 核心区别

2. 关键补充:GIL锁(Global Interpreter Lock)
面试官必问:“Python的多线程为什么不能利用多核CPU?”——答案就是GIL锁。
GIL锁是Python解释器的全局锁,确保同一时刻只有一个线程执行Python字节码。这就导致:即使在多CPU环境下,Python的多线程也只能“并发”(同一时间只有一个线程执行),无法“并行”(多个线程同时执行)。
解决方案:
CPU密集型任务:用多进程(multiprocessing),每个进程有独立的Python解释器,不受GIL限制,可利用多核CPU。
IO密集型任务:用多线程或协程,因为IO操作(如网络请求、文件读取)会释放GIL锁,其他线程可趁机执行,效率更高。

八、加分项:Python性能调优
面试官会问:“你平时怎么优化Python代码的性能?”,重点说4个实用方向,结合场景,不用太复杂:
减少内存占用:用生成器替代列表(惰性生成),用tuple替代list(tuple不可变,内存占用更少),避免不必要的变量创建。
优化循环效率:尽量用内置函数(如map、filter、列表推导式)替代for循环(内置函数是C语言实现,速度更快);避免在循环内频繁创建对象、调用函数。
并发优化:IO密集型用协程(asyncio)或多线程;CPU密集型用多进程;合理使用线程池、进程池(concurrent.futures模块),避免频繁创建/销毁进程/线程。
工具辅助:用cProfile模块分析代码耗时,定位性能瓶颈;用PyPy替代CPython(PyPy是即时编译,执行速度比CPython快数倍)。
以上所有知识点,不是让你死记硬背,而是理解底层逻辑,面试时能“用自己的话讲清楚”,并结合简单示例,就能让面试官认可你的能力。
重点优先级:内存管理机制 > 进程线程协程 > 迭代器生成器 > 装饰器 > 元类 > Mixin > 性能调优,优先吃透前4个,再补充后面的知识点。

