Linux 进程与线程深度解析:fork()、exec()、线程原理,一次彻底搞懂
- 2026-07-03 15:40:36
作者:小康,C/C++编程博主
关键词:fork、exec、写时复制、线程、clone、task_struct、进程状态
前言
上一篇讲了虚拟内存和缺页中断,顺带提到了 fork() 的写时复制。
不少读者留言:
"进程和线程到底有什么区别?Linux 里线程是怎么实现的?fork() 之后子进程和父进程有什么关系?exec() 又是干什么的?"
这些问题串在一起,其实是同一个故事——Linux 是如何创建和管理执行单元的。
这篇,我们顺着 fork() 这个入口,把进程和线程的底层机制一次讲透。
一、进程是什么:不只是"一个程序"
很多教材说"进程是程序的一次执行",这个定义太模糊了。
在 Linux 内核眼里,进程是一个 task_struct 结构体——一张记录了"这个执行单元所有信息"的大表,包括:
进程 ID( pid)、父进程 ID(ppid)虚拟内存映射( mm_struct)打开的文件表( files_struct)信号处理表、CPU 寄存器状态 调度信息(优先级、运行时间片)
┌─ task_struct ─────────────────┐│ pid = 1234 ││ mm → 虚拟内存空间 ││ files → 文件描述符表 ││ signals → 信号处理 ││ regs → CPU寄存器状态 ││ sched → 调度信息 │└───────────────────────────────┘一句话:进程 = task_struct + 独立的虚拟地址空间。
二、fork():最快的"复制粘贴"
fork() 是创建新进程的标准方式。它做的事情简单粗暴:把父进程复制一份,生成子进程。
pid_t pid = fork();if (pid == 0) {// 子进程:pid == 0printf("我是子进程,PID=%d\n", getpid());} else {// 父进程:pid == 子进程的PIDprintf("我是父进程,子进程PID=%d\n", pid);}fork() 返回两次:在父进程里返回子进程的 PID,在子进程里返回 0。这是一个很优雅的设计。
但问题来了:如果父进程有 2GB 数据,每次 fork() 都要复制 2GB?那 Nginx 启动时 fork() 几十个 worker 进程,岂不是要几十 GB 内存?
当然不是。这里就要用到上一篇讲过的写时复制(Copy-On-Write,COW)。
fork() 之后,父子进程共享同一批物理页,页表项都标记为只读。谁先写,才触发缺页中断,内核只复制那一页。
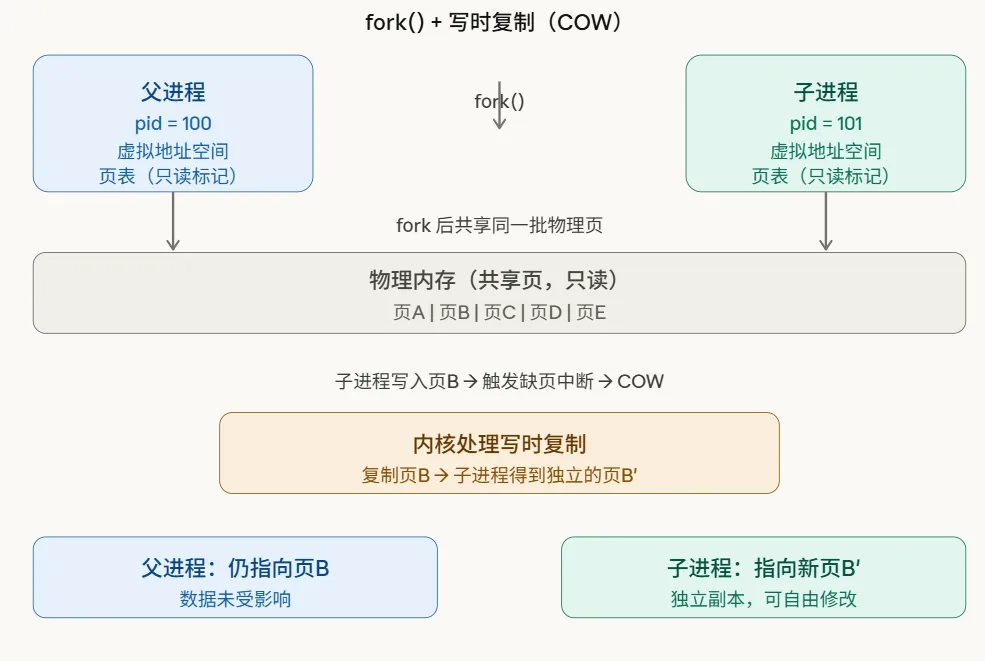
COW 的精妙之处在于:如果子进程 fork() 后立刻 exec() 换一个程序(这是 shell 的标准做法),原来的数据一页都不需要复制。fork() 的开销本质上只是复制页表,而不是复制数据。
三、exec():换一套衣服继续跑
fork() 复制了父进程,但子进程大多数情况下不想"继续做父进程的事",而是要运行一个全新的程序。这就是 exec() 的职责。
exec() 调用后,进程的虚拟地址空间被完全替换——代码段、数据段、栈全部清空,装载新程序。但 PID 不变,打开的文件描述符(除非设置了 O_CLOEXEC)也不变。
fork() + exec() 的组合,是 shell 执行命令的标准模式:
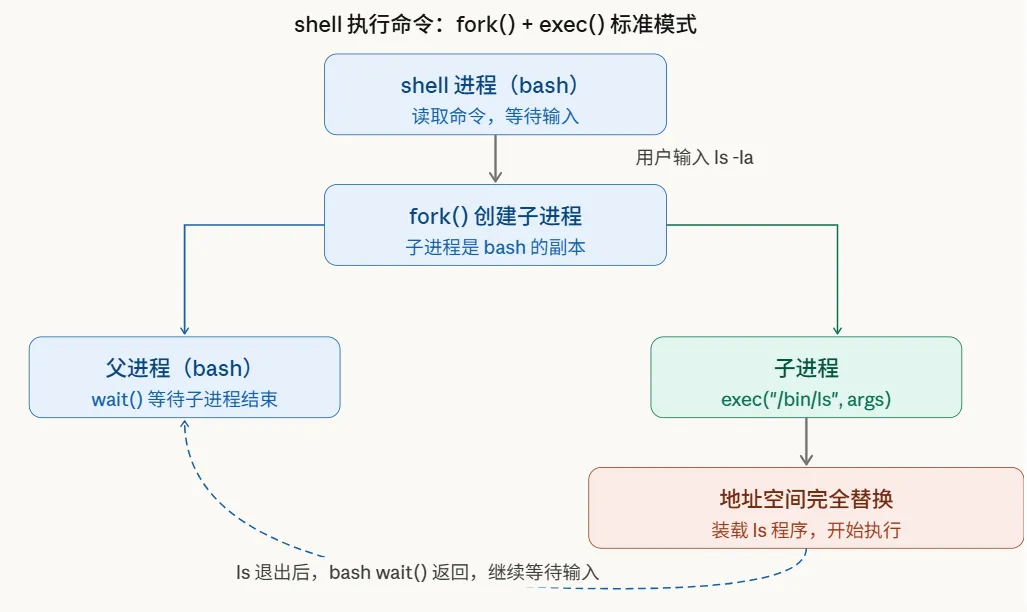
这就是为什么你在 shell 里输入 ls,执行的是 /bin/ls 而不是 bash 自己——bash fork() 出一个子进程,子进程 exec() 把自己替换成 ls,执行完退出,bash 继续等你输入下一条命令。
代码精简版:
pid_t pid = fork();if (pid == 0) {// 子进程:替换成 ls execv("/bin/ls", argv);// exec 成功不会返回到这里} else {// 父进程:等子进程结束 waitpid(pid, NULL, 0);}四、进程 vs 线程:共享的边界在哪里?
很多面试题问:"进程和线程的区别是什么?"
最精准的答案是:线程是进程内部的执行单元,同一进程的所有线程共享同一个虚拟地址空间。
看下面这张图,进程和线程的共享边界一目了然:
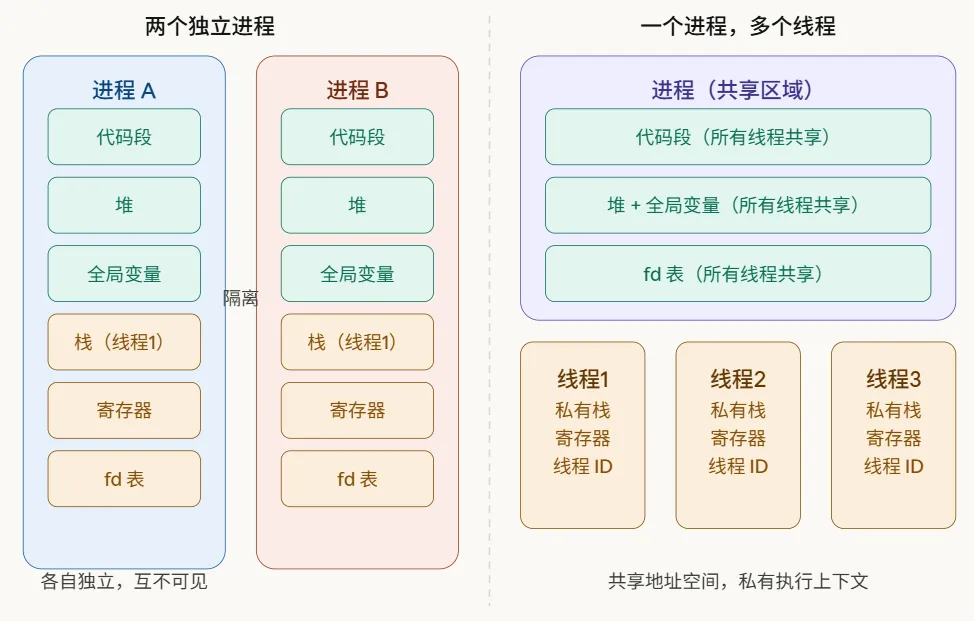
图中清晰展示了关键差异:进程间完全隔离,各自拥有独立的代码、堆、栈和文件描述符表。而同一进程内的多个线程,共享代码段、堆、全局变量和 fd 表,每个线程只有自己的栈、寄存器和线程 ID 是私有的。
这就是为什么线程间通信比进程间通信(IPC)简单得多——线程直接读写同一块内存就行,不需要管道或共享内存。但代价是:一个线程写坏了堆上的数据,所有线程都遭殃。
五、Linux 线程的真相:它和进程是同一个东西
这是很多人不知道的事实:
Linux 内核里没有"线程"这个概念,线程就是共享了某些资源的进程。
Linux 创建线程和创建进程用的是同一个底层系统调用——clone()。区别只在于传入的标志位:
// 创建进程:fork() 内部调用 clone,大部分资源不共享clone(fn, stack, SIGCHLD, arg);// 创建线程:pthread_create() 内部调用 clone,共享地址空间等clone(fn, stack, CLONE_VM | // 共享虚拟内存 CLONE_FS | // 共享文件系统信息 CLONE_FILES | // 共享文件描述符表 CLONE_SIGHAND | // 共享信号处理器 CLONE_THREAD, // 同一线程组 arg);CLONE_VM 是关键:有了这个标志,父子共享同一个 mm_struct(虚拟内存描述符),相当于共享了整个地址空间——这就是"线程"。
去掉这个标志,父子各有独立的地址空间——这就是"进程"。
内核里它们都是 task_struct,调度器一视同仁。
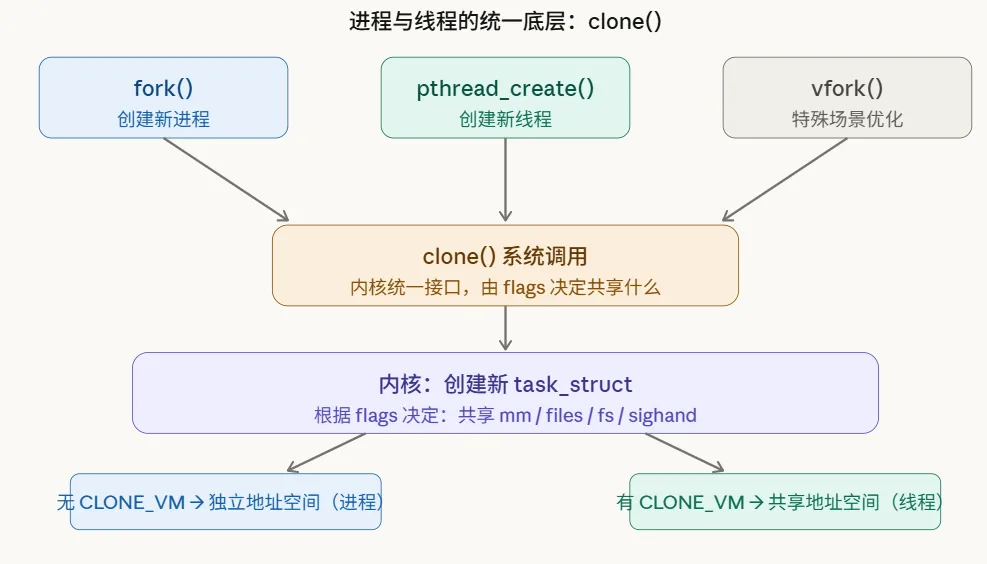
这个设计带来了一个重要的推论:Linux 的线程切换和进程切换在内核层面本质上是一样的——都是切换 task_struct,都是保存/恢复寄存器。线程切换比进程切换快,主要是因为线程共享 mm_struct,不需要切换页表,也就不需要刷 TLB——而 TLB 的刷新代价很高。
六、进程状态:从创建到死亡
一个进程从 fork() 开始,会经历这些状态:
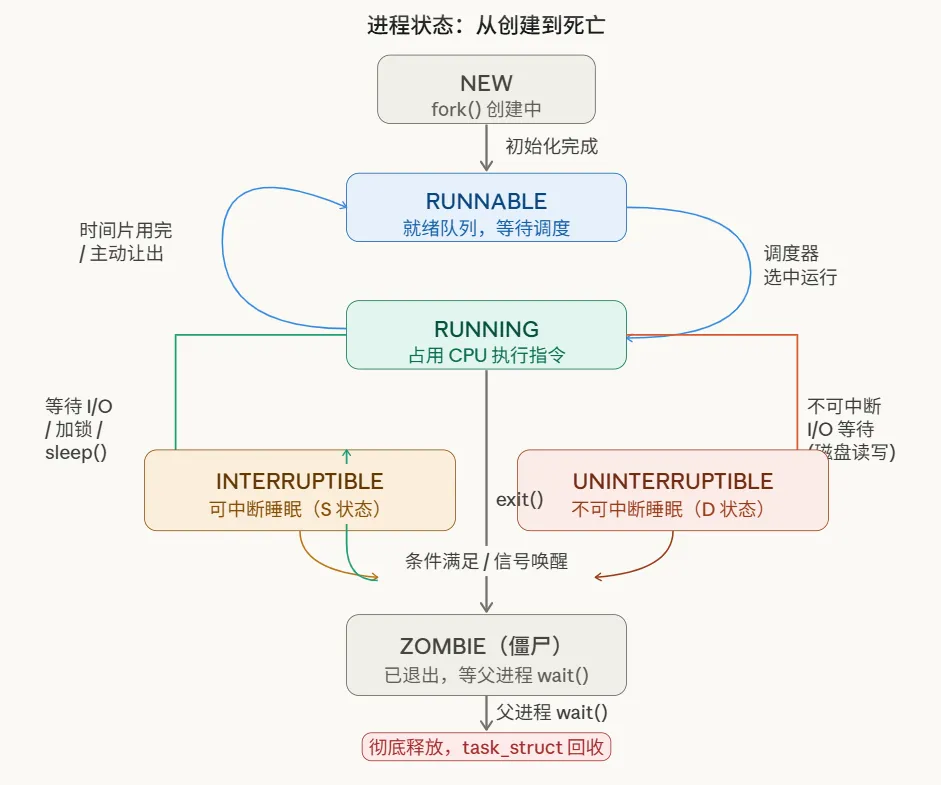
状态说明:
RUNNABLE⇄RUNNING是高频切换的双向循环,由调度器控制INTERRUPTIBLE(S 状态)是最常见的睡眠状态,ps看到的绝大多数进程都在这里,可以被信号唤醒UNINTERRUPTIBLE(D 状态)是等待不可中断 I/O 时进入,kill -9都杀不掉,NFS 挂起导致的进程卡死就是这个状态ZOMBIE是已死未葬,ps显示为Z,不占内存但占 PID
僵尸进程(Zombie) 是个常见话题:子进程退出后,task_struct 不会立刻释放,需要等父进程调用 wait() 收集退出状态,才会真正消失。如果父进程一直不 wait(),僵尸进程会堆积,占用 PID 资源(虽然不占内存)。
// 防止僵尸进程的正确做法signal(SIGCHLD, SIG_IGN); // 方案一:忽略 SIGCHLD,内核自动回收// 或者waitpid(-1, NULL, WNOHANG); // 方案二:非阻塞 wait,收割所有已退出子进程七、线程创建实战
#include<pthread.h>#include<stdio.h>int shared_counter = 0; // 全局变量,所有线程共享void *worker(void *arg){int id = *(int *)arg;// 注意:多线程操作 shared_counter 需要加锁! shared_counter++;printf("线程 %d,shared_counter = %d\n", id, shared_counter);returnNULL;}intmain(){pthread_t tid[3];int ids[3] = {1, 2, 3};for (int i = 0; i < 3; i++) pthread_create(&tid[i], NULL, worker, &ids[i]);for (int i = 0; i < 3; i++) pthread_join(tid[i], NULL); // 等待所有线程结束return0;}编译时记得加 -lpthread。
八、高频面试题精析
Q:fork() 之后父子进程谁先执行?
不确定。由内核调度器决定。在同一 CPU 上,通常父进程先继续运行(Linux 的历史默认行为),但可以用 sched_yield() 或 taskset 控制。不要依赖执行顺序。
Q:Linux 线程和进程切换的开销对比?
线程切换省去了切换页表和刷 TLB 的开销(因为线程共享 mm_struct),所以比进程切换快。但两者都涉及内核态切换、寄存器保存/恢复,差距没有想象中那么大。实测线程切换比进程切换快约 2~5 倍。
Q:fork() 之后文件描述符怎么处理?
子进程会继承父进程所有打开的文件描述符(都指向同一个文件表项),包括 socket。这是 Nginx prefork 模型中 worker 进程能共享 listen fd 的基础。如果不想让子进程继承某个 fd,可以在 open() 时加 O_CLOEXEC 标志,exec() 时该 fd 会自动关闭。
Q:什么是孤儿进程?和僵尸进程有什么区别?
孤儿进程:父进程先退出,子进程还在运行,内核会把孤儿进程"过继"给 PID 1(init/systemd),由它负责 wait()。孤儿进程无害。 僵尸进程:子进程先退出,父进程没有 wait(),子进程的 task_struct 无法释放,PID 被占用。僵尸进程积累多了会耗尽 PID 资源,危害系统稳定性。
Q:多线程程序里 fork() 是安全的吗?
危险!fork() 只复制调用线程,其他线程在子进程中消失。如果那些消失的线程持有某个互斥锁,子进程里这把锁永远不会被释放,会造成死锁。安全做法是 fork() 后立刻 exec()(不持有锁的情况下),或者使用 pthread_atfork() 注册清理回调。
结语
从 fork() 到 exec(),从进程到线程,这一路下来,我们看到的是 Linux 的一个核心设计哲学:
复用机制,用标志位控制行为。
进程和线程的底层是同一个 task_struct,只是 clone() 的标志位不同。写时复制让 fork() 极其轻量。exec() 让进程能彻底蜕变成一个新程序。
理解这些,才能真正理解 Nginx 的 prefork 模型为什么高效,才能理解为什么多线程 fork() 有坑,才能在面试里把这类问题讲到层次分明。
下篇预告:线程同步全解析:mutex、条件变量、读写锁、死锁的原理与避坑
📌 还在打基础?从这里出发
如果你读完这篇还觉得 C、C++、Linux 有些陌生,别急——我也开设了三门入门课程,从零带你打好地基,快速上手项目实战:
C 语言快速入门 :大一啃完谭浩强的书,还是不会写代码?我花1个月做了套'12天速成'的C语言课 C++ 快速入门 :12天,从C++小白到独立做项目!我把3年踩坑经验浓缩成了这门课 Linux 编程快速入门 :为什么你学了半年 Linux 编程,还是写不出一个像样的程序?
感兴趣可以了解一下。
🚀 基础扎实了?来做工业级项目
如果你已经有一定基础,想冲击更高的天花板,这些工业级 C++ 项目正是为你准备的:
| 线程池 | |
| 高性能日志库 MiniSpdlog | |
| 高性能内存池 | |
| 多线程下载工具 | |
| MySQL 连接池 | |
| 内存泄漏检测器 | |
| ReactorX | |
| 无锁栈 | |
| 工业级智能指针(shared_ptr) | |
| 高性能网络库 NetCore | |
| 高性能异步日志库 ZephyrLog | |
| 死锁检测工具 | |
| 高性能 HTTP 服务器 | |
| 协程库 CoroForge | |
| 高性能 HTTP 压测工具 | |
| Redis 核心模块实战 |
每个项目都是真实可用的工程代码,不是教学玩具。
详情点击 C++ 项目合集课程链接:为什么同样是"学过C++",有人面试碾压,有人开口就怂?差距在这18个C++硬核项目
对C++项目实战课程感兴趣的朋友,可以扫下方二维码添加小康微信(或微信搜索:jkfwdkf ) 备注「 项目实战 」

觉得有收获,点赞、推荐、转发支持下哦~ 🙏

