# 🔥 控制翻页数量(自己改)MAX_PAGES = 10# 🔥 年份筛选(自己改)YEAR_START = 2020YEAR_END = 2026# 关键词KEYWORDS = ["ocean","atmosphere","coastal","typhoon","climate","storm","sea"]KEYWORDS = ["storm surge","typhoon","sea level","coastal flooding","wave","air-sea interaction"]

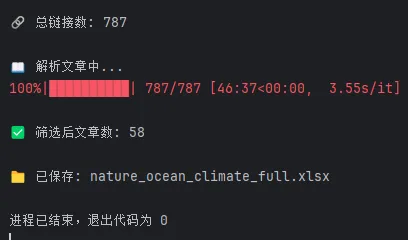
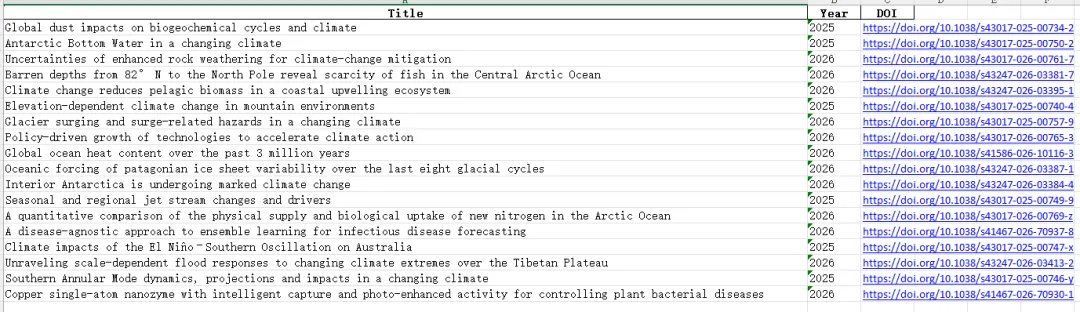

import requestsfrom bs4 import BeautifulSoupimport pandas as pdimport timefrom tqdm import tqdm# =========================# 基本配置# =========================HEADERS = {"User-Agent": "Mozilla/5.0"}BASE_URL = "https://www.nature.com"JOURNALS = ["ncomms","nature","natrevearthenviron","commsenv"]ARTICLE_TYPES = {"ncomms": "research-articles","nature": "research-articles","natrevearthenviron": "reviews-and-analysis","commsenv": "research-articles"}# 🔥 控制翻页数量(自己改)MAX_PAGES = 10# 🔥 年份筛选(自己改)YEAR_START = 2020YEAR_END = 2026# 关键词KEYWORDS = ["ocean","atmosphere","coastal","typhoon","climate","storm","sea"]KEYWORDS = ["storm surge","typhoon","sea level","coastal flooding","wave","air-sea interaction"]SLEEP_TIME = 0.5# =========================# 判断关键词# =========================def is_related(title): title_lower = title.lower()return any(k in title_lower for k in KEYWORDS)# =========================# 获取分页链接# =========================def get_links_from_pages(): all_links = []for journal in JOURNALS: article_type = ARTICLE_TYPES[journal]print(f"\n📚 期刊: {journal}")for page in range(1, MAX_PAGES + 1): url = f"https://www.nature.com/{journal}/{article_type}?page={page}"try: res = requests.get(url, headers=HEADERS, timeout=10) soup = BeautifulSoup(res.text, "lxml") links = []for a in soup.select("a.c-card__link"): href = a.get("href")if href and "/articles/" in href: links.append(BASE_URL + href) links = list(set(links))print(f"Page {page}: {len(links)} 篇") all_links.extend(links) time.sleep(SLEEP_TIME)except:print(f"失败: {url}")return list(set(all_links))# =========================# 解析文章# =========================def parse_article(url):try: res = requests.get(url, headers=HEADERS, timeout=10) soup = BeautifulSoup(res.text, "lxml")# 标题title_tag = soup.find("h1") title = title_tag.text.strip() if title_tag else "N/A"# DOIdoi = "N/A"meta_doi = soup.find("meta", {"name": "citation_doi"})if meta_doi: doi = "https://doi.org/" + meta_doi.get("content")# 🔥 年份(更准确)year = Nonemeta_date = soup.find("meta", {"name": "citation_publication_date"})if meta_date: year = int(meta_date.get("content")[:4])return {"Title": title,"Year": year,"DOI": doi }except:print(f"解析失败: {url}")return None# =========================# 主程序# =========================def main():print("🚀 开始抓取(支持翻页+年份筛选)") links = get_links_from_pages()print(f"\n🔗 总链接数: {len(links)}") results = []print("\n📖 解析文章中...")for link in tqdm(links): data = parse_article(link)if data and data["Year"]:# 年份筛选if YEAR_START <= data["Year"] <= YEAR_END:# 关键词筛选if is_related(data["Title"]): results.append(data) time.sleep(SLEEP_TIME)print(f"\n✅ 筛选后文章数: {len(results)}")# 转 DataFramedf = pd.DataFrame(results)# 🔥 按年份排序df = df.sort_values(by="Year", ascending=False)# 保存df.to_excel("nature_ocean_climate_full.xlsx", index=False)print("\n📁 已保存: nature_ocean_climate_full.xlsx")# =========================# 运行# =========================if __name__ == "__main__": main()