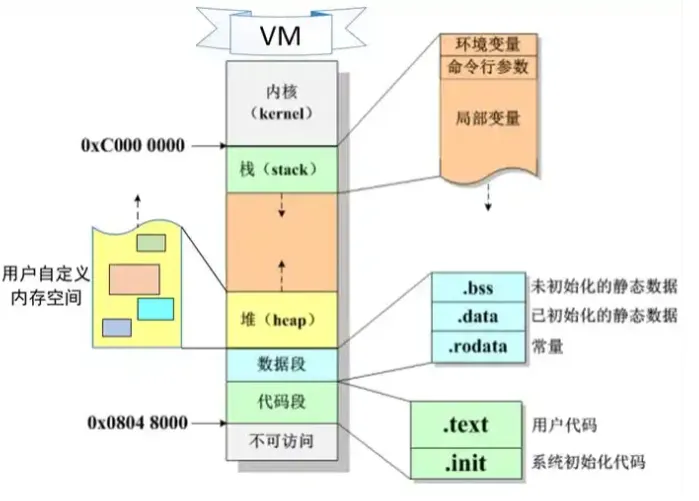
最近笔者自己在Linux平台下,写了一些调度和算法的代码,其中牵扯到多线程的调度和耦合。后来笔者将代码整合后测试,通过top命令查看到,整个进程的内存mem占用是在不断增长的。由于部分代码引用了开源代码,因此笔者也比较好奇,到底是哪个代码部分对内存的malloc 后没有free, 也将代码同步二次审阅了一遍。在此过程中发现,在高发或者频繁分配内存的应用开发中,程序性能经常被malloc/free 干掉,对malloc 内存的管理方式也有了更深的理解,特此给大家共享。在 C 语言的标准库中,malloc 函数为程序提供着动态内存分配的关键服务。它的定义:void *malloc(size_t size); 这个函数接受一个参数 size,用于指定需要分配的内存字节数。其返回值是一个指向所分配内存起始地址的指针 ,类型为 void*,这意味着它可以被转换为任何类型的指针,以适应不同的数据存储需求。在 Linux 系统中,malloc 函数是通过 glibc(GNU C Library)来实现的,glibc 作为一个功能强大的 C 库,为程序员提供了丰富的函数和工具。Arena(分配区) 实现上(例如 glibc 的 ptmalloc)会把堆划分为若干个 arena。每个 arena 管理若干空闲链表、元数据等。多线程分配时,线程有可能争用同一个 arena,从而触发锁竞争。
Cache line bouncing(缓存行抖动) CPU 缓存是按 cache line(通常 64 字节)管理的。多个核心频繁写同一条共享元数据,会造成缓存行在核心间来回迁移,极大增加延迟,即便不显式加锁也会慢。
---强调一下: 同一CPU的多核调度,如负载较大,则会影响多核cache 的交互效率,比如PLC的多核动态负载分配等;
上下文切换 当线程在等待锁时被挂起,操作系统会调度其他线程运行。保存/恢复寄存器、切换栈和虚拟内存上下文等开销都是真实的成本。
元数据(metadata)开销malloc 为每个 chunk 保存 size / flags / prev_size 等信息,导致小请求的额外空间与访问开销。比如申请 64 字节可能实际占用 80+ 字节。
碎片(fragmentation)管理 为减少内存浪费/重用性能,分配器会合并/拆分 chunk,这些操作也会消耗 CPU、并影响缓存局部性。
系统调用:brk / mmap 小块通常通过堆(brk/sbrk)管理,偶尔扩堆;大块通常直接通过 mmap 申请虚拟内存,这些系统调用都有明显延迟(mmap 通常是微秒级)。
---划重点: 小的用brk, 大的用mmap;
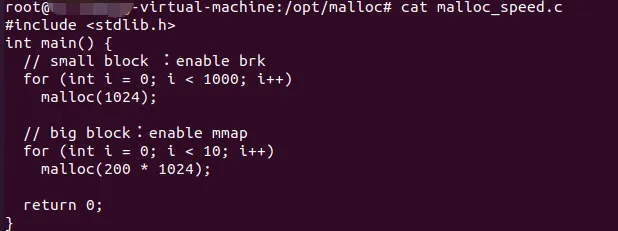
在程序中调用 malloc 函数时,它会首先在 glibc 维护的内存池中查找是否有足够的空闲内存来满足请求。如果内存池中有足够的空闲内存,malloc 函数会直接从内存池中分配内存,并返回相应的指针。如果内存池中的空闲内存不足以满足,malloc 函数就会借助系统调用与操作系统进行交互,如上述:brk和mmap 。brk系统调用通过移动程序数据段的结束地址来增加堆的大小,从而分配新的内存。而mmap系统调用则是通过在文件映射区域分配一块内存来满足请求。一般来说,小于128KB的时候,就会用brk ; 大于128KB时候,就用mmap系统调用;我们写一个程序,来测试一下brk和mmap的调用情况:编译:gcc malloc_speed.c -o malloc_speed
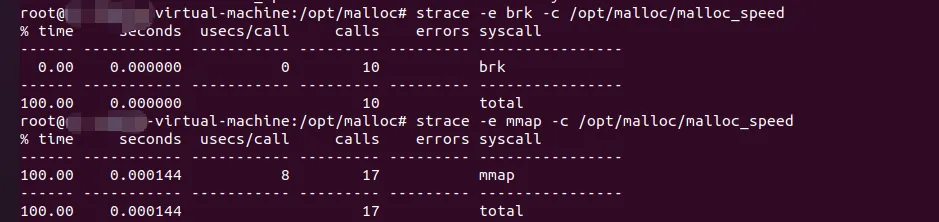
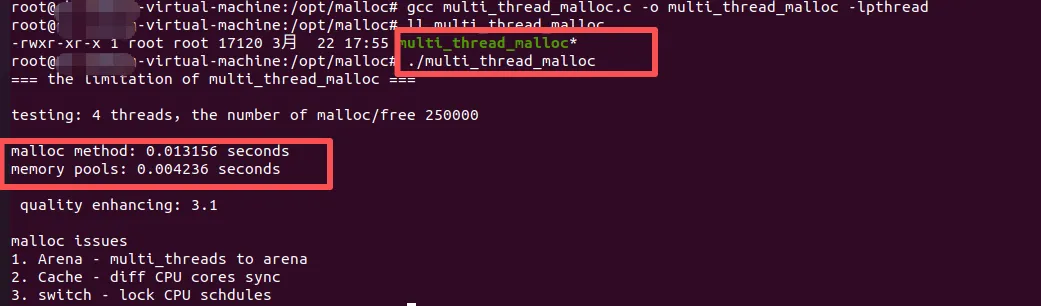
然后采用strace命令 计算brk和mmap结果,并对比;通过上述结果,大家可以看到,小块主要用brk 进行堆增长,大块用mmap, mmap的系统调用明显有延迟(查看seconds等指标);#include<stdio.h>#include<stdlib.h>#include<pthread.h>#include<time.h>#define THREADS 4#define PER_THREAD 250000// malloc void* thread_malloc(void* arg){ for (int i = 0; i < PER_THREAD; i++) { void *ptr = malloc(64); free(ptr); } return NULL;}// memory pooltypedef struct { char pool[64 * 1000];} ThreadPool;void* thread_pool(void* arg){ ThreadPool *pool = (ThreadPool*)arg; for (int i = 0; i < PER_THREAD; i++) { char *ptr = &pool->pool[(i % 1000) * 64]; *ptr = 1; } return NULL;}intmain(){ pthread_t threads[THREADS]; struct timespec start, end; printf("=== the limitation of multi_thread_malloc ===\n\n"); printf("testing: %d threads,the number of malloc/free %d \n\n", THREADS, PER_THREAD); // malloc testing clock_gettime(CLOCK_MONOTONIC, &start); for (int i = 0; i < THREADS; i++) { pthread_create(&threads[i], NULL, thread_malloc, NULL); } for (int i = 0; i < THREADS; i++) { pthread_join(threads[i], NULL); } clock_gettime(CLOCK_MONOTONIC, &end); double malloc_time = (end.tv_sec - start.tv_sec) + (end.tv_nsec - start.tv_nsec) / 1e9; ThreadPool pools[THREADS]; clock_gettime(CLOCK_MONOTONIC, &start); for (int i = 0; i < THREADS; i++) { pthread_create(&threads[i], NULL, thread_pool, &pools[i]); } for (int i = 0; i < THREADS; i++) { pthread_join(threads[i], NULL); } clock_gettime(CLOCK_MONOTONIC, &end); double pool_time = (end.tv_sec - start.tv_sec) + (end.tv_nsec - start.tv_nsec) / 1e9; printf("malloc method: %.6f seconds\n", malloc_time); printf("memory pools: %.6f seconds\n", pool_time); printf("\n quality enhancing: %.1f\n\n", malloc_time / pool_time); printf("malloc issues \n"); printf("1. Arena - multi_threads to arena\n"); printf("2. Cache - diff CPU cores sync \n"); printf("3. switch - lock CPU schdules \n"); return 0;}
malloc 的版本会比相对简单的per-thread pool 慢不少;pool 相关版本函数,在多线程并发场景有优势的;研发可以采用perf、heaptracek、valgrind massif、 strace、 gperftools来实测问题原因;malloc 在处理大数据块时候,的确会有一些慢,尤其是在多线程的条件下,甚至因为多个thread的调度算法影响到响应速度,lock /cache等切换,从而出现卡机现象;对于高频小数据分配(相对DPU等通信量大),如工业实时以太网ECAT, PN, POWERLINK等,可采用per-thread或者per-core 创建内存池,避免多线程交互竞争;