Python & MATLAB 到 光学生成模型(1)
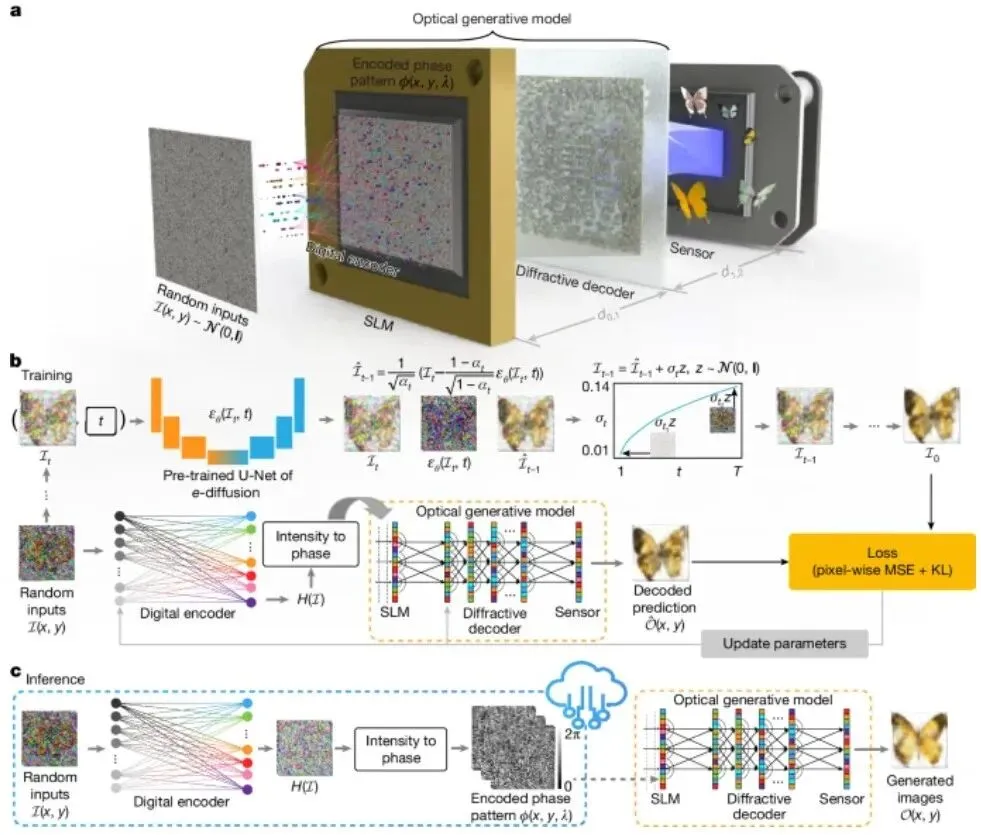
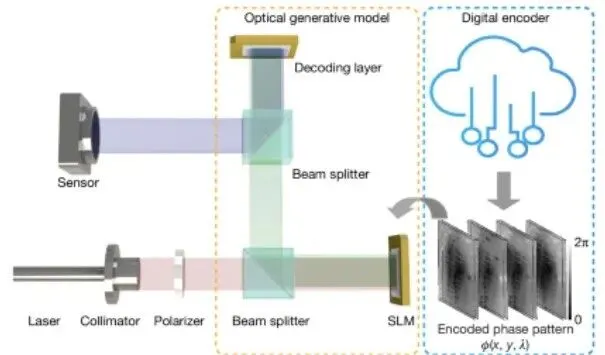
我们知道生成模型已覆盖众多应用领域(包括豆包的文生图以及混元模型等图生图模型),包括图像与视频合成、自然语言处理及分子设计等。随着数字生成模型规模不断扩大,如何实现快速且高能效的可扩展推理已成为一项挑战。本期来复现最新Nature上提出的光学生成模型(这篇论文是受到生成模型的启发,经典的加噪声和去噪声的无监督学习方式):一个轻量级快速数字编码器。具体步骤包括:1. 首先将随机噪声映射为相位模式,这些模式作为目标数据分布的光学生成种子;2. 随后,一个联合训练的自由空间可重构解码器以全光学方式处理这些生成种子,从而根据目标数据分布创造出前所未有的图像。除照明功耗和通过浅层编码器生成随机种子外,这些光学生成模型在图像合成过程中不消耗任何计算算力。我们报告了基于MNIST、Fashion-MNIST、Butterflies-100、Celeb-A数据集、以及梵高绘画与素描作品的数据分布,分别实现了手写数字、时尚单品、蝴蝶、人脸及艺术画作等单色与彩色图像的光学生成,其整体性能与基于数字神经网络的传统生成模型相当。为实验验证光学生成模型,我们利用可见光生成了手写数字和时尚单品图像,并进一步通过单色及多波长照明实现了梵高风格艺术作品的生成。这些光学生成模型或将为高能效可扩展推理任务开辟新路径,进一步发掘光学与光子学在人工智能生成内容领域的应用潜力。
光学生成模型示意图。基于随机高斯噪声的输入首先通过浅层数字编码器进行处理,生成大量光学生成种子,由空间光调制器随机调用。输入光场经可重构且经过优化的衍射解码器传播后,生成的图像被记录在传感器阵列上。针对给定的目标数据分布,该光学生成模型可合成海量图像。输入光经衍射解码器传播以生成输出图像的光学过程耗时<1 ns;然而,图像生成的总体速度受限于输入空间光调制器的刷新时间。光学生成模型通过已学习的去噪扩散概率模型进行训练,利用去噪扩散概率模型生成的数据对来指导即时光学生成模型的优化。对于图像的推理,预先计算好的光学生成种子通过(例如)云服务器随机调用,而图像生成则通过自由空间光学与波传播在本地实现。主要思路是利用扩散模型的训练方式,但是在生成阶段利用SLM相位图替代卷积,从而模型在生成阶段不需要利用电子运算,直接利用光的衍射来实现光学图像的生成。