这两天我专门把一个 OpenClaw 安全实践仓库从头到尾看了一遍。
看完之后,我最大的感受不是“又多了几条安全命令”,而是:
很多人对 OpenClaw 安全这件事,连对象都理解错了。
很多人一提安全,脑子里冒出来的还是传统那一套:
这些当然重要。
但如果你把 OpenClaw 这种高权限智能体的安全,理解成普通 Linux 主机加固,你后面会越来越偏。
因为它真正危险的地方,不只是它有 Root、会执行命令。
更危险的是:
- 它会读文档
- 会装 Skill
- 会接 MCP
- 会执行脚本
- 会理解业务指令
- 还会因为“过于听话”而替你做高危决策
这就意味着,OpenClaw 的安全对象,从一开始就不只是“主机”。
它其实是:
一个高权限智能体系统的零信任架构问题。
我为什么会下这个判断?
因为我看的这个仓库,最有价值的地方,不是教你怎么把系统锁得更死。
而是它把 OpenClaw 的安全问题拆成了三段:
- 事前
- 事中
- 事后
也就是:
- 事前先拦住什么不能碰
- 事中再控制运行时怎么降风险
- 事后还要让你每天看见防线到底有没有在工作
这才是高权限 Agent 真正需要的安全结构。

真正危险的,不只是权限高,而是它会读、会接、会做、还会替你判断。
一、为什么 OpenClaw 安全不是传统主机安全
如果是普通服务器,你做安全,主要是在防:
但 OpenClaw 不一样。
它是一种会持续接收上下文、理解语言、调用外部能力的系统。
它面临的风险,除了传统主机风险,还包括:
- Prompt Injection
- Skill / MCP 供应链投毒
- 带毒文档诱导执行
- 高危业务逻辑误执行
- 明文凭证和私钥外发
换句话说:
你防的已经不只是“机器被黑”。
你还要防:
一个高权限、能看懂文本、会自己行动的系统,被诱导着去做错事。
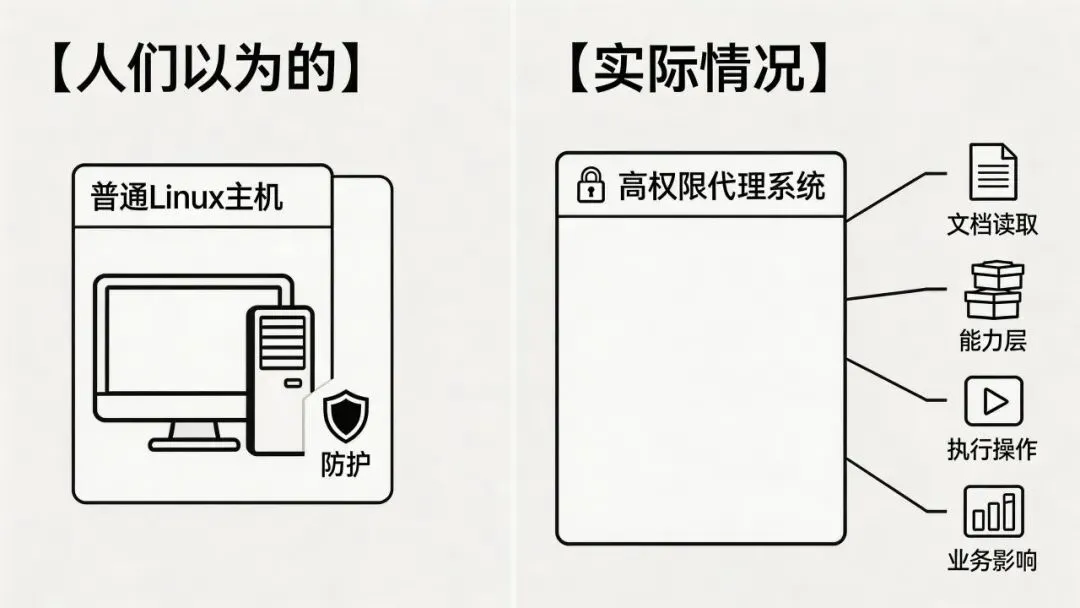
很多人以为自己在防一台机器,实际上在防一个会读文本、会接能力、会执行动作的系统。
这个区别非常大。
因为它意味着:
传统那种“把系统锁住一点”并不够。
你必须同时约束:
这个仓库最清楚的一点,就是它不是在讲散乱建议。
它给的是一套很完整的三层矩阵:
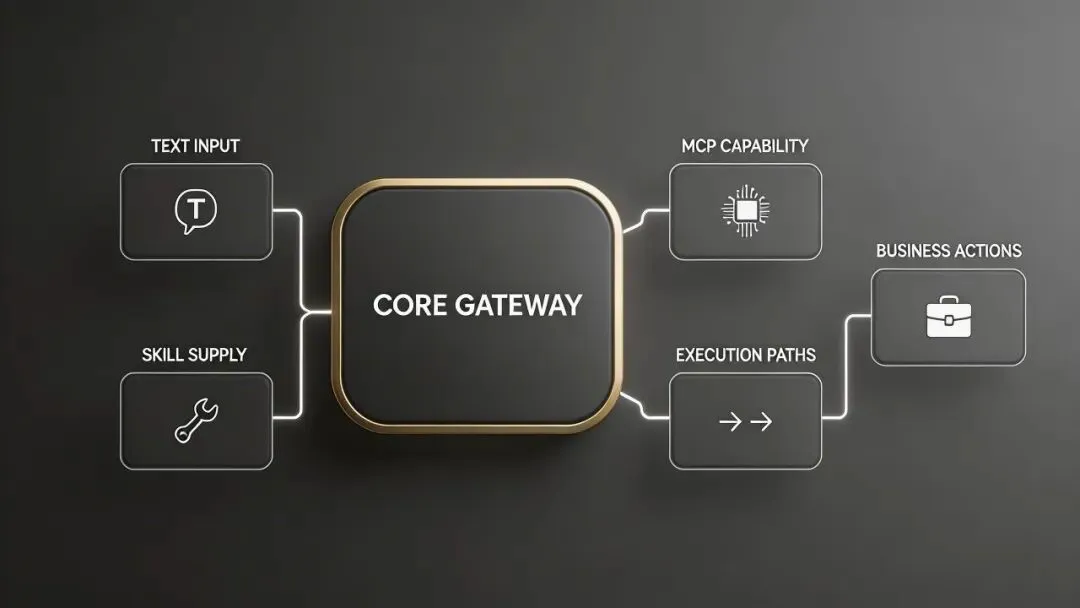
主机只是底层,真正的攻击面已经长成一张多入口、多动作的系统图。
1. 事前
先把行为红线和黄线写清楚。
比如:
- 哪些破坏性命令一定要停
- 哪些外发敏感数据的动作绝对不能做
- 哪些持久化、认证篡改、代码注入行为必须拦住
- 哪些命令虽然能做,但必须记录进 memory
更关键的是,它要求:
Skill / MCP / 第三方工具安装前,必须做全文本审计。
注意,是全文本。
不只是脚本,还包括:
因为对于高权限智能体来说,真正可怕的,不只是恶意 shell。
还有那种藏在文档里的隐性指令。
这一点特别重要。
很多人会默认把 Markdown 当成“安全文本”。
但对能读文档、能执行命令的 Agent 来说,文档本身就可能是攻击面。
2. 事中
它不是只讲“拦”,还讲运行时怎么降风险。
比如:
- 核心文件权限收窄
- 用 SHA256 做基线校验
- 在高危业务动作前做 Pre-flight 风控
这意味着它防的不是纯系统层问题。
它已经在往业务逻辑层走。
也就是说,OpenClaw 不只是不能乱删文件。
它还不能在高权限下,带着错误判断去做错误业务。
3. 事后
最后不是“配完就算了”。
它要求每晚做 13 项显性化巡检,还要做 Git 灾备。
包括:
- 平台原生安全审计
- 进程和网络快照
- 敏感目录变更
- 系统和 OpenClaw Cron
- SSH 失败尝试
- 配置基线
- 黄线日志与 memory 对账
- 敏感凭证扫描
- Skill/MCP 哈希基线
- 大脑灾备同步
这才像一套真正能长期跑的防线。
我很喜欢这个仓库的一点,是它并没有停留在概念层。
比如很多安全建议都喜欢神化 chattr +i。
看起来很硬,很安全。
但这份指南明确指出:
paired.json 和 openclaw.json 在 gateway 运行时本来就需要写入。
如果你不分场景直接上 chattr +i,很可能会把系统自己锁死。
所以它给出的替代方式是:
chmod 600- SHA256 哈希基线
- 只对巡检脚本这类不影响运行时的文件做只读锁
这说明什么?
说明作者不是在写“看起来很安全”的建议。
而是在处理一个更真实的问题:
这其实也是我判断一个安全方案有没有工程感的关键标准。
如果一个方案只能在 PPT 里成立,不能在运行时成立,那它就不是实战方案。
这个仓库里还有一个很值得传播的判断:
夜间巡检不只是要报异常。
它还要求把所有绿灯项也逐条报出来。
比如:
- 端口快照采集了
- 失败 SSH 次数是多少
- 配置基线是否通过
- 环境变量有没有异常
- Skill/MCP 的哈希基线有没有变化
- 灾备推送有没有成功
为什么这个要求很重要?
因为如果系统只在出事时才说话,人类会陷入一种很糟糕的状态:
所以这份指南要求显性化汇报 13 项指标。
这不是形式主义。
它背后其实是一个很成熟的系统判断:
高权限智能体的安全,不只是做了防护,还要让人持续看见防护是否还在工作。

安全不是“配过就行”,而是你要持续看见它昨晚有没有真的在工作。
很多系统不是死在没有策略,而是死在:
如果让我从这个仓库里只拿走一个传播价值最高的东西,我不会拿某条 shell 命令。
我会拿它那个很有张力的说法:
给 OpenClaw 做安全,不只是装一个 Skill,而是给它植入一层安全思想钢印。
我觉得这句话非常重要。
因为它把问题从“装一个工具”推进到了“重塑一个高权限智能体的默认判断”。
这也是为什么我越来越觉得,未来围绕 OpenClaw 的真正机会,不只是安装和接 MCP。
还会包括:
- 安全基线设计
- 可用性与安全性的平衡调优
- 高权限智能体部署前审计
- 业务风控前置设计
- 夜间巡检与灾备体系
也就是说:
未来不是只有“让它能跑起来”这件事。
还会有越来越多人开始关心:
这份仓库有一点我很认同:
它反复强调,这不是绝对安全。
它依赖:
所以真正成熟的安全表达,不该是:
“照着做就万无一失。”
而应该是:
“在高权限智能体这个新对象上,把最关键的风险前移、压缩、显性化,并让人始终保留最终判断权。”
我觉得这才是它真正值得看的地方。
不是因为它给了多少命令。
而是因为它帮我们把一个很新的问题定义对了:
OpenClaw 的安全,不是 Linux 加固,而是智能体零信任架构。
如果你也在折腾 OpenClaw、MCP、高权限 Agent 或相关交付,我后面会继续拆:
- 这类系统为什么必须把“安全”和“可用性”一起设计
- 哪些防线是真的有效,哪些只是看起来安全
- 为什么高权限智能体的风险,已经开始从系统层上升到认知层和业务层
如果你正在部署,或者已经开始接能力层,也欢迎直接来交流。
这类问题,越早想清楚,后面越少踩坑。
感谢看到这里。
如果这条判断对你有用,欢迎点赞、在看、转发。

