相关性分析(基于Python)2——随机变量关系的数学刻画
- 2026-07-04 03:52:49
在上一节中,我们发现,若不考虑数据情况,随意将两个变量之间的复杂关系强行用线性关系表征,可能会导致严重的信息坍塌。为了避免这种坍塌带来的误判,我们从统计学中去寻找能够完整描述变量关系的数学工具。
在概率论的公理化体系中,这个工具就是联合概率分布(Joint Probability Distribution)。本节我们将暂时抛开具体的统计指标,从测度论和微积分的视角出发,严谨地推导随机变量之间的关系是如何在多维空间中被数学刻画的。
1联合分布
假设我们在同一个样本空间 上定义了两个连续型随机变量 和 。在单变量统计学中,我们用概率密度函数(PDF) 来描述 在各个取值点附近的概率密集程度。几何上, 是一条位于一维坐标轴上方的曲线,曲线下方的面积代表概率。
当我们同时考虑 和 时,一维的曲线就扩展成了二维平面上方的一个曲面。这个曲面的高度,就是联合概率密度函数 。
包含了 和 之间所有可能的互动信息。它不仅告诉我们 取某个值的概率有多大,还精确地描述了在 取该值的同时, 取各个值的概率分布形态。
根据概率的公理,这个二维曲面必须满足两个基本条件:
非负性:对于平面上的任意一点 ,都有 。 归一性:曲面下方的总体积必须等于1。用二重积分表示为:
如果我们要计算 和 同时落入二维平面上某个特定区域 的概率,只需要计算该区域上方曲面的体积:
为了直观地理解联合概率密度函数,我们编写一段Python代码,在三维空间中绘制一个典型的二维高斯(正态)分布的联合概率密度曲面,并将其投影到二维平面上形成等高线图。
import numpy as npimport matplotlib.pyplot as pltfrom scipy.stats import multivariate_normalfrom mpl_toolkits.mplot3d import Axes3D# 设置中文字体plt.rcParams['font.sans-serif'] = ['SimHei']plt.rcParams['axes.unicode_minus'] = False# 定义二维空间的网格范围x = np.linspace(-4, 4, 100)y = np.linspace(-4, 4, 100)X, Y = np.meshgrid(x, y)pos = np.dstack((X, Y))# 设定二维高斯分布的均值向量和协方差矩阵# 这里我们设定一个存在正向依赖关系的协方差矩阵mu = np.array([0.0, 0.0])cov = np.array([[2.0, 1.2], [1.2, 2.0]])# 实例化多维正态分布对象rv = multivariate_normal(mu, cov)# 计算网格上每个点的联合概率密度值Z = rv.pdf(pos)# 创建画布fig = plt.figure(figsize=(14, 6))# 子图1:三维曲面图ax1 = fig.add_subplot(121, projection='3d')surf = ax1.plot_surface(X, Y, Z, cmap='viridis', edgecolor='none', alpha=0.9)ax1.set_title('联合概率密度函数 $f_{X,Y}(x,y)$ 的三维曲面', fontsize=14)ax1.set_xlabel('变量 X')ax1.set_ylabel('变量 Y')ax1.set_zlabel('概率密度')fig.colorbar(surf, ax=ax1, shrink=0.5, aspect=10)# 子图2:二维等高线图(俯视图)ax2 = fig.add_subplot(122)contour = ax2.contourf(X, Y, Z, levels=20, cmap='viridis')ax2.set_title('联合分布的等高线投影', fontsize=14)ax2.set_xlabel('变量 X')ax2.set_ylabel('变量 Y')fig.colorbar(contour, ax=ax2)# 在等高线图上添加两条辅助线,用于后续解释条件分布ax2.axvline(x=1.0, color='red', linestyle='--', alpha=0.7, label='给定 X=1.0')ax2.axvline(x=-1.0, color='white', linestyle='--', alpha=0.7, label='给定 X=-1.0')ax2.legend(loc='upper left')plt.tight_layout()plt.show()执行结果如下:
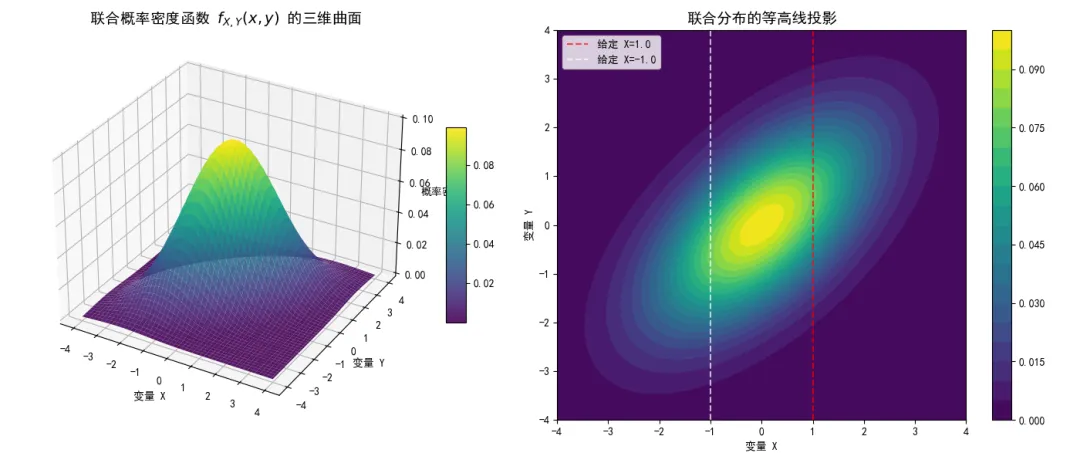
左侧的三维曲面展示了概率在二维空间中的堆积方式。右侧的等高线图则是我们在学术文献中最常见的表达形式。等高线的形状(这里是倾斜的椭圆)直接反映了 和 之间的关系结构。椭圆的主轴向右上方倾斜,意味着当 取较大值时, 也倾向于取较大值。
2边缘分布
在拥有了联合分布 之后,我们有时需要回答一个退化的问题:如果我们完全不关心 的取值,仅仅想知道 自身的概率分布是什么样的?
这个剥离另一个变量的过程,在微积分中被称为边缘化(Marginalization)。通过对联合概率密度函数在整个 轴上进行定积分,我们可以得到 的边缘概率密度函数(Marginal PDF):
从几何角度来看,这个积分操作相当于把三维空间中的概率密度曲面,沿着 轴的方向“压扁”或者说“投影”到 轴上。对于 轴上的任意一个固定点 ,我们沿着 轴切一刀,得到一个截面。计算这个截面的面积,就是 在 处的边缘概率密度 。
同理, 的边缘概率密度函数 则是对 积分:
为了清晰地展示联合分布与边缘分布之间的几何投影关系,我们不使用现成的统计绘图库(如seaborn的jointplot),而是利用matplotlib的GridSpec模块,从底层手动构建一个包含二维散点(代表联合分布抽样)和一维直方图(代表边缘分布)的复合图表。
import numpy as npimport matplotlib.pyplot as pltimport matplotlib.gridspec as gridspecplt.rcParams['font.sans-serif'] = ['SimHei']plt.rcParams['axes.unicode_minus'] = False# 设定随机种子并生成二维正态分布的抽样数据np.random.seed(42)mean = [0, 0]# 设定一个负相关的协方差矩阵cov = [[3.0, -2.0], [-2.0, 3.0]]# 生成 5000 个样本点data = np.random.multivariate_normal(mean, cov, 5000)x_data = data[:, 0]y_data = data[:, 1]# 使用 GridSpec 定制复杂的图表布局fig = plt.figure(figsize=(10, 10))gs = gridspec.GridSpec(4, 4, hspace=0.1, wspace=0.1)# 主图:二维联合分布的散点图ax_main = fig.add_subplot(gs[1:4, 0:3])ax_main.scatter(x_data, y_data, alpha=0.2, s=10, color='#2b8cbe')ax_main.set_xlabel('变量 X', fontsize=12)ax_main.set_ylabel('变量 Y', fontsize=12)ax_main.grid(True, linestyle=':', alpha=0.6)# 顶部图:X 的边缘分布 (沿着 Y 轴积分投影)ax_top = fig.add_subplot(gs[0, 0:3], sharex=ax_main)ax_top.hist(x_data, bins=50, density=True, color='#a6bddb', edgecolor='white')ax_top.set_title('联合分布与边缘分布的几何投影', fontsize=15, pad=20)ax_top.axis('off') # 隐藏坐标轴以保持整洁# 右侧图:Y 的边缘分布 (沿着 X 轴积分投影)ax_right = fig.add_subplot(gs[1:4, 3], sharey=ax_main)ax_right.hist(y_data, bins=50, density=True, orientation='horizontal', color='#a6bddb', edgecolor='white')ax_right.axis('off')# 调整坐标轴范围以对齐ax_main.set_xlim(-6, 6)ax_main.set_ylim(-6, 6)plt.show()执行结果如下:
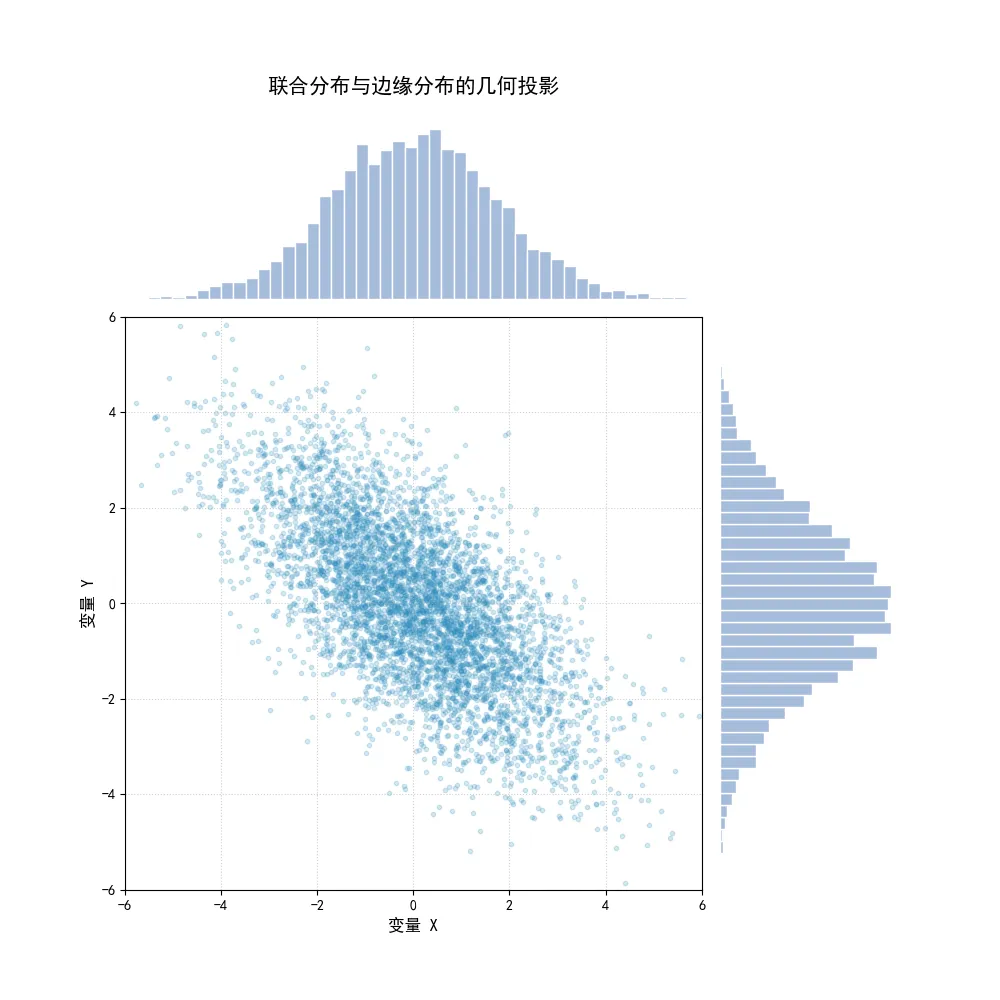
在这幅图中,中央的散点云代表了联合分布 的经验形态。由于协方差矩阵中设定了负的非对角线元素,散点云呈现出向右下方倾斜的趋势。
顶部的直方图是 的边缘分布 ,它等价于将中央的所有散点垂直向下砸到 轴上所形成的密度分布。右侧的直方图则是 的边缘分布 ,等价于将所有散点水平向右砸到 轴上。
理解边缘分布的关键在于认识到它的局限性:从联合分布可以唯一地推导出边缘分布,但从边缘分布绝对无法反推回联合分布。 即使我们知道了 服从正态分布, 也服从正态分布,我们依然对它们之间是否存在相关性一无所知。无数种截然不同的联合分布,都可以投影出完全相同的边缘分布。
3统计独立性
在明确了联合分布和边缘分布的定义后,我们终于可以从数学上严谨地定义什么是“两个变量之间没有关系”。在概率论中,这种绝对的无关系被称为统计独立性(Statistical Independence)。
如果随机变量 和 是相互独立的,那么它们的联合概率密度函数,必须在二维平面上的每一个点 ,都严格等于它们各自边缘概率密度函数的乘积:
这个等式是概率论中最核心的基石之一。它的物理意义是: 和 的联合概率行为,可以完全被拆解为两个孤立系统的独立运作。
我们可以从条件概率的角度来更深刻地理解这个等式。条件概率密度函数 描述的是:在已知 取某个特定值 的前提下, 的概率分布。根据贝叶斯公式的连续形式:
如果 和 相互独立,我们将 代入上式,可以得到:
这个推导得出了一个极其直观的结论:如果两个变量独立,那么无论 取什么值,都不会对 的概率分布产生任何影响。 知道 的信息,对于预测 毫无帮助。此时, 的条件分布 永远等于它自身的边缘分布 。
反之,如果 和 存在某种相关性(无论是线性还是非线性),上述等式就不成立。此时,随着 取值的改变, 的条件分布的形状、均值或方差必然会发生相应的变化。
我们通过代码来对比独立与不独立两种状态下,联合分布等高线和条件分布的几何形态差异。
import numpy as npimport matplotlib.pyplot as pltfrom scipy.stats import multivariate_normalplt.rcParams['font.sans-serif'] = ['SimHei']plt.rcParams['axes.unicode_minus'] = False# 定义网格x = np.linspace(-5, 5, 100)y = np.linspace(-5, 5, 100)X, Y = np.meshgrid(x, y)pos = np.dstack((X, Y))# 场景A:X 和 Y 相互独立# 协方差矩阵的非对角线元素必须为 0cov_indep = [[2.0, 0.0], [0.0, 2.0]]rv_indep = multivariate_normal([0, 0], cov_indep)Z_indep = rv_indep.pdf(pos)# 场景B:X 和 Y 存在相关性# 协方差矩阵存在非零的非对角线元素cov_dep = [[2.0, 1.5], [1.5, 2.0]]rv_dep = multivariate_normal([0, 0], cov_dep)Z_dep = rv_dep.pdf(pos)fig, axes = plt.subplots(1, 2, figsize=(14, 6))# 绘制独立的联合分布contour1 = axes[0].contourf(X, Y, Z_indep, levels=15, cmap='Blues')axes[0].set_title('场景A:X与Y相互独立\n$f(x,y) = f(x)f(y)$', fontsize=14)axes[0].set_xlabel('X')axes[0].set_ylabel('Y')# 绘制给定 X 时的条件分布切片位置axes[0].axvline(x=-2, color='red', linestyle='--', label='给定 X=-2')axes[0].axvline(x=2, color='green', linestyle='--', label='给定 X=2')axes[0].legend()# 绘制相关的联合分布contour2 = axes[1].contourf(X, Y, Z_dep, levels=15, cmap='Reds')axes[1].set_title('场景B:X与Y存在相关性\n$f(x,y) \\neq f(x)f(y)$', fontsize=14)axes[1].set_xlabel('X')axes[1].set_ylabel('Y')axes[1].axvline(x=-2, color='red', linestyle='--', label='给定 X=-2')axes[1].axvline(x=2, color='green', linestyle='--', label='给定 X=2')axes[1].legend()plt.tight_layout()plt.show()执行结果如下:
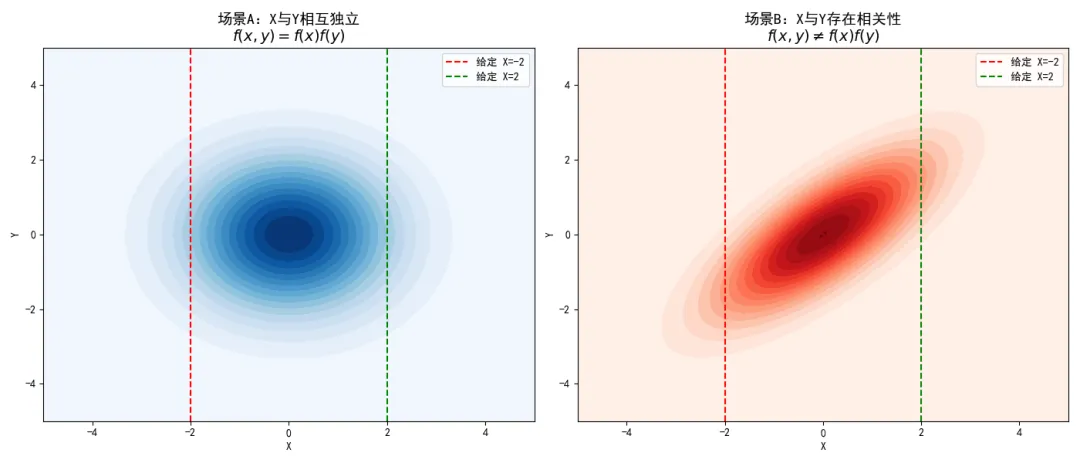
观察这两幅图。在左侧的独立场景中,等高线是完美的同心圆(或轴对齐的椭圆)。当我们把辅助线从 移动到 时,沿着这条垂直线切下去得到的 的条件分布,其中心位置始终停留在 处,没有任何偏移。这完美印证了 。
而在右侧的相关场景中,等高线发生了倾斜。当我们在 处切一刀时, 的条件分布的中心位于负半轴;当我们移动到 时, 的条件分布的中心随之上移到了正半轴。 的取值改变了 的期望形态,这正是相关性存在的几何证明。
统计独立性是相关性分析中最严苛的基准线。任何度量相关性的指标(如协方差、皮尔逊系数、互信息),其核心逻辑都是在量化真实的联合分布 偏离独立基准线 的距离。
4二维随机变量函数的期望与内积
在明确了联合概率密度函数 能够完整刻画 和 之间的所有关系之后,我们面临一个实际的工程问题:这个二维曲面虽然包含了全部信息,但它太复杂了。在绝大多数情况下,我们无法精确知道 的解析表达式,只能通过有限的样本去估计它。
为了从这个复杂的二维分布中提取出我们关心的特征(比如变量之间协同波动的趋势),我们需要一种数学运算,能够将二维空间中的信息“压缩”成一个一维的标量。在概率论中,完成这种信息提取的核心算子,就是数学期望(Mathematical Expectation)。
在单变量统计学中,随机变量 的期望 是对其取值按照概率密度进行加权平均:
当我们进入二维空间时,期望运算的对象不再局限于单个变量,而是可以扩展到任意关于 和 的函数 。二维随机变量函数 的期望,定义为该函数在整个二维平面上,按照联合概率密度 进行加权的二重积分:
这个公式是整个相关性分析理论的基石。通过选择不同的函数 ,我们可以从联合分布中提取出不同维度的关系特征。
例如,如果我们令 ,那么上述二重积分就退化成了 的边缘期望 :
这证明了二维期望算子向下兼容了一维期望。
现在,我们来寻找能够度量 和 之间协同变化关系的特定函数 。最直观的想法是,考察 和 的乘积。如果我们令 ,那么我们计算的就是 和 乘积的期望,记为 :
在统计学中被称为 和 的混合原点矩(Mixed Raw Moment)。从泛函分析的角度来看,如果我们将随机变量视为希尔伯特空间(Hilbert Space)中的向量,那么 本质上就是向量 和向量 在该空间中的内积(Inner Product),通常记为 。
内积是度量两个向量之间夹角和投影关系的核心工具。如果 ,说明在联合概率密度较高的区域, 和 倾向于同号(同正或同负),这暗示了正向的协同关系;如果 ,说明它们倾向于异号,暗示了负向的协同关系。
然而,直接使用混合原点矩 来度量相关性存在一个致命的缺陷:它严重依赖于坐标系的原点位置。如果我们对变量 加上一个常数 (相当于平移坐标轴),混合原点矩的值会发生剧烈变化:
只要 ,平移操作就会改变度量结果。一个合理的度量指标,必须具备平移不变性(Translation Invariance),即变量之间协同波动的本质规律,不应该因为我们改变了测量基准(如将摄氏度改为开尔文温度)而发生改变。
为了解决这个问题,我们需要将坐标系的原点,平移到数据的“重心”位置。
5协方差
数据的重心,正是变量各自的数学期望 。我们将变量 减去其期望 ,得到去中心化(Mean-centered)后的变量 。这个新变量代表了 偏离其均值的纯粹波动。同理,我们得到 的纯粹波动 。
现在,我们将这两个去中心化后的变量相乘,作为新的函数 ,并计算它的期望。这个期望值,就是统计学中鼎鼎大名的协方差(Covariance):
将协方差的定义式展开,我们可以得到它的另一种常用计算形式:
这个展开式清晰地揭示了协方差的代数结构:它是混合原点矩 减去两个边缘期望乘积 的结果。
从几何和泛函分析的视角来看,协方差 本质上是去中心化后的随机变量向量在希尔伯特空间中的内积。
我们通过一段Python代码,在二维散点图上直观地展示协方差的几何意义。我们将平面划分为四个象限,原点设为数据的重心 ,并观察数据点在各个象限的分布如何决定协方差的符号和大小。
import numpy as npimport matplotlib.pyplot as pltplt.rcParams['font.sans-serif'] = ['SimHei']plt.rcParams['axes.unicode_minus'] = False# 设定随机种子np.random.seed(100)# 生成具有正向线性关系的二维数据mean = [5, 10]cov_matrix = [[4.0, 3.5], [3.5, 5.0]]data = np.random.multivariate_normal(mean, cov_matrix, 300)x = data[:, 0]y = data[:, 1]# 计算重心(期望)mean_x = np.mean(x)mean_y = np.mean(y)# 计算去中心化后的坐标dx = x - mean_xdy = y - mean_y# 计算每个点的乘积 (X-E[X])(Y-E[Y])products = dx * dy# 根据乘积的符号将数据点分类# 象限 I 和 III:乘积为正(同号)positive_idx = products > 0# 象限 II 和 IV:乘积为负(异号)negative_idx = products <= 0# 计算样本协方差cov_xy = np.sum(products) / (len(x) - 1)# 创建图表fig, ax = plt.subplots(figsize=(10, 8))# 绘制散点,使用不同颜色区分乘积的符号ax.scatter(x[positive_idx], y[positive_idx], color='#d73027', alpha=0.7, label='$(X-E[X])(Y-E[Y]) > 0$ (第一、三象限)', s=50, edgecolors='white')ax.scatter(x[negative_idx], y[negative_idx], color='#4575b4', alpha=0.7, label='$(X-E[X])(Y-E[Y]) < 0$ (第二、四象限)', s=50, edgecolors='white')# 绘制重心的十字基准线ax.axvline(mean_x, color='black', linestyle='-', linewidth=1.5)ax.axhline(mean_y, color='black', linestyle='-', linewidth=1.5)# 标注重心位置ax.plot(mean_x, mean_y, marker='X', color='black', markersize=12, label='重心 $(E[X], E[Y])$')# 在四个象限添加文本说明ax.text(mean_x + 1, mean_y + 2, '第一象限\n$dx>0, dy>0$\n乘积为正', fontsize=12, color='#d73027')ax.text(mean_x - 3, mean_y - 3, '第三象限\n$dx<0, dy<0$\n乘积为正', fontsize=12, color='#d73027')ax.text(mean_x - 3, mean_y + 2, '第二象限\n$dx<0, dy>0$\n乘积为负', fontsize=12, color='#4575b4')ax.text(mean_x + 1, mean_y - 3, '第四象限\n$dx>0, dy<0$\n乘积为负', fontsize=12, color='#4575b4')ax.set_title(f'协方差的几何意义:去中心化后的象限分布\n样本协方差 Cov(X,Y) = {cov_xy:.2f}', fontsize=15)ax.set_xlabel('变量 X', fontsize=13)ax.set_ylabel('变量 Y', fontsize=13)ax.legend(loc='upper left')ax.grid(True, linestyle=':', alpha=0.5)plt.tight_layout()plt.show()执行结果如下:
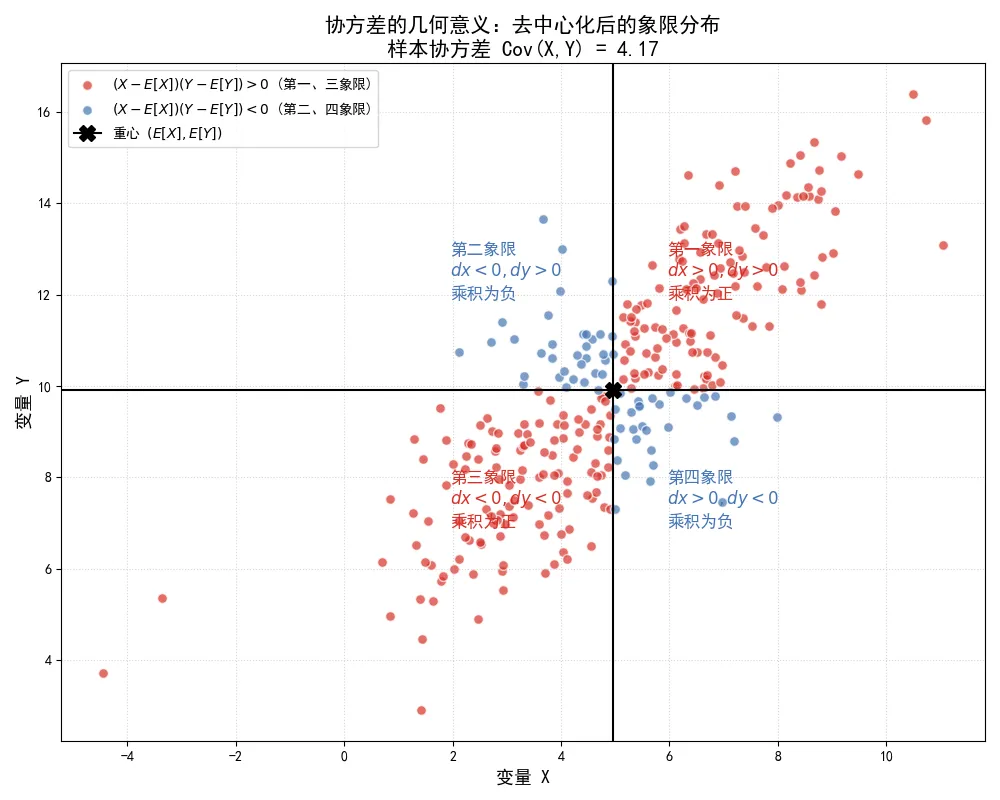
在这幅图中,黑色的十字线将数据空间划分为四个象限,十字的交点就是数据的重心 。
对于落在第一象限的点,它们在 和 方向上都大于均值,因此 和 都是正数,它们的乘积为正。 对于落在第三象限的点,它们在 和 方向上都小于均值,两个负数相乘,乘积依然为正。 红色的点代表了这两种情况,它们对协方差的计算贡献了正值。
相反,落在第二象限( 小于均值, 大于均值)和第四象限( 大于均值, 小于均值)的点,它们的乘积为负。蓝色的点代表了这两种情况,它们对协方差的计算贡献了负值。
协方差的最终大小,就是这所有红色正值和蓝色负值在概率密度加权下的总和。如果红色的点在数量和偏离程度上占据绝对优势(如图所示),总和为正,说明变量之间存在正向的线性协同趋势;如果蓝色的点占据优势,总和为负,说明存在负向趋势;如果红色和蓝色的贡献相互抵消,总和接近于0,说明变量之间缺乏明显的线性协同关系。
6独立性与协方差的单向推导
假设 和 相互独立,我们来计算它们的混合原点矩 :
由于独立性假设成立,我们可以将联合概率密度 替换为边缘密度的乘积 :
由于积分变量 和 是分离的,我们可以将这个二重积分拆解为两个独立的一重积分的乘积:
观察括号内的部分,它们恰好就是 和 各自的边缘期望 和 。因此,我们得出了一个极其重要的定理:
如果 和 相互独立,那么它们的混合原点矩等于各自期望的乘积:
将这个结论代入协方差的展开式 ,我们立刻得到:
这个推导在数学上严格证明了:独立必定导致协方差为0(即不相关)。
这是因为,当两个变量独立时,它们在四个象限中的概率分布是完全对称和均衡的。第一象限的正向贡献必然会被第二象限或第四象限的负向贡献精确抵消,导致最终的内积积分为0。
然而,我们必须极其谨慎地对待这个定理的逆命题。在第1节中,我们已经通过 的例子证明了,协方差为0绝对推导不出变量相互独立。协方差仅仅是联合分布在特定函数 下的积分投影。当联合分布呈现出某种非线性的对称结构时,这个特定的积分依然会等于0,但变量之间可能存在着极其强烈的确定性依赖。
这就是为什么在高级统计学和机器学习中,我们不能仅仅依赖协方差矩阵来判断特征是否冗余。协方差只能捕捉线性依赖,它是独立性的一个必要不充分条件。
7协方差矩阵
为了全面刻画这 个变量之间两两的协同变化关系,我们需要将单个的协方差数值扩展为一个矩阵。这个矩阵就是统计学和机器学习中极其重要的协方差矩阵(Covariance Matrix),通常记为 。
协方差矩阵 是一个 的方阵,它的第 行第 列的元素 定义为变量 和 之间的协方差:
我们可以从代数和几何两个维度来深刻理解协方差矩阵的性质。
(1)对称性与半正定性
首先,根据协方差的定义,乘法满足交换律,因此 。这意味着协方差矩阵 必定是一个对称矩阵(Symmetric Matrix),即 。
其次,我们来看矩阵的主对角线元素。当 时,。这恰好就是变量 自身的方差 。因此,协方差矩阵的主对角线存放的是各个变量的方差,而非对角线存放的是变量之间的协方差。
更重要的是,协方差矩阵在代数上必须是一个半正定矩阵(Positive Semi-definite Matrix)。这意味着对于任意一个非零的常数向量 ,二次型 必须大于等于0。
我们可以通过方差的非负性来严谨地推导这一点。构造一个新的随机变量 。根据方差的性质,任何随机变量的方差都不能为负数,因此 。
我们将 的表达式代入方差计算公式并展开:
这个双重求和的表达式,恰好就是二次型 的展开形式。因此:
这个推导不仅证明了协方差矩阵的半正定性,还揭示了它的物理意义:协方差矩阵 决定了多维随机向量 在任意方向 上的投影方差。 这个性质是主成分分析(PCA)等降维算法的数学基石。
(2)几何形变与线性变换
从几何视角来看,协方差矩阵描述了多维概率分布的形状和方向。对于多维正态分布 ,其等概率密度面是一个超椭球体。协方差矩阵 决定了这个椭球体的轴长和旋转角度。
如果 是一个对角矩阵(非对角线元素全为0,即变量之间两两不相关),那么椭球体的各个轴将与坐标轴平行。如果非对角线元素不为0,椭球体就会发生旋转,倾斜的方向和程度由协方差的大小决定。
我们可以通过一段Python代码,直观地展示协方差矩阵如何通过线性变换,将一个标准的圆形分布“拉伸”和“旋转”成一个椭圆形分布。
import numpy as np
import matplotlib.pyplot as plt
from matplotlib.patches import Ellipse
plt.rcParams['font.sans-serif'] = ['SimHei']
plt.rcParams['axes.unicode_minus'] = False
np.random.seed(42)
# 生成标准二维正态分布数据
mean_std = [0, 0]
cov_std = [[1, 0], [0, 1]]
data_std = np.random.multivariate_normal(mean_std, cov_std, 1000)
# 目标协方差矩阵
target_cov = np.array([[3.0, 1.5], [1.5, 2.0]])
# Cholesky 分解
L = np.linalg.cholesky(target_cov)
# 变换数据
data_transformed = data_std.dot(L.T)
# 绘图
fig, axes = plt.subplots(1, 2, figsize=(12, 6))
# 标准分布
axes[0].scatter(data_std[:, 0], data_std[:, 1], alpha=0.3, color='#377eb8', s=10)
axes[0].set_title(r'标准分布:$\Sigma = I$ (单位矩阵)' + '\n变量独立且方差为1', fontsize=14)
axes[0].set_xlim(-6, 6)
axes[0].set_ylim(-6, 6)
axes[0].set_aspect('equal')
axes[0].grid(True, linestyle=':', alpha=0.6)
# 变换后的分布
axes[1].scatter(data_transformed[:, 0], data_transformed[:, 1], alpha=0.3, color='#e41a1c', s=10)
axes[1].set_title(
'目标分布:Σ = [[3.0, 1.5], [1.5, 2.0]]\n协方差矩阵导致拉伸与旋转',
fontsize=14
)
axes[1].set_xlim(-6, 6)
axes[1].set_ylim(-6, 6)
axes[1].set_aspect('equal')
axes[1].grid(True, linestyle=':', alpha=0.6)
# 绘制特征向量
eigenvalues, eigenvectors = np.linalg.eigh(target_cov)
for i in range(2):
vec = eigenvectors[:, i] * np.sqrt(eigenvalues[i]) * 2
axes[1].arrow(0, 0, vec[0], vec[1], head_width=0.3, head_length=0.4,
fc='black', ec='black', linewidth=2, zorder=5)
plt.tight_layout()
plt.show()
执行结果如下:
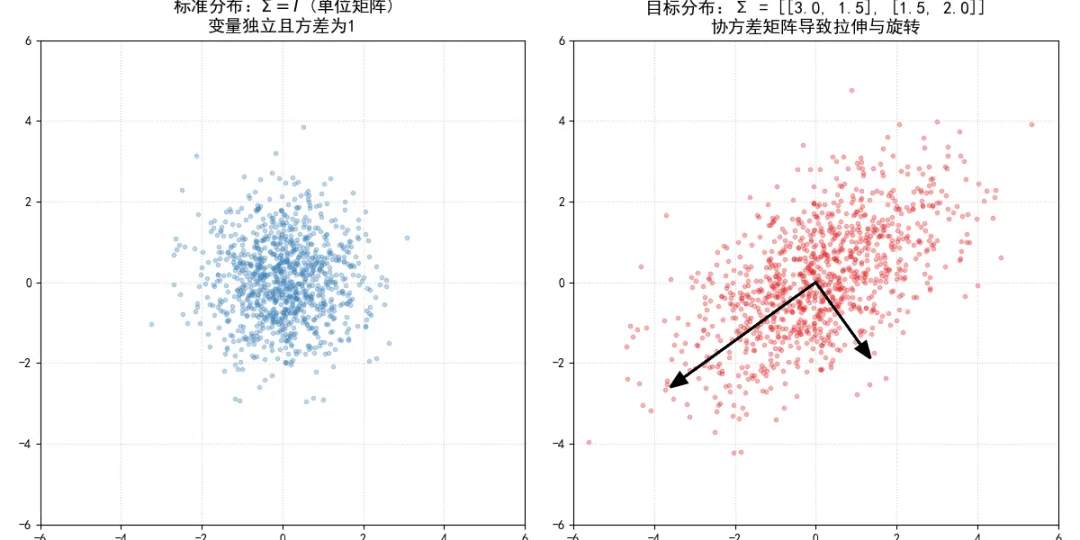
我们首先生成了一个协方差矩阵为单位矩阵的标准正态分布。在左图中,数据点呈现出完美的圆形对称。
接着,我们定义了一个目标协方差矩阵,并通过Cholesky分解求得了一个线性变换矩阵 。当我们将这个线性变换应用到标准数据上时,右图展示了变换后的结果。原本的圆形被协方差矩阵“拉伸”成了一个椭圆(因为 和 的方差不再是1),并且发生了“旋转”(因为非对角线元素1.5引入了正相关)。
图中的黑色箭头代表了目标协方差矩阵的特征向量(Eigenvectors),箭头的长度正比于特征值(Eigenvalues)的平方根。特征向量指明了数据方差最大的方向,也就是椭圆的主轴方向。这直观地证明了协方差矩阵在几何上完全控制了多维分布的形态。
8相关系数:协方差的无量纲化
尽管协方差在代数和几何上都具有极其优美的性质,但它在实际应用中存在一个致命的缺陷:它对变量的量纲(尺度)极其敏感。
假设我们正在研究身高()和体重()的协方差。如果我们把身高的单位从“米”改为“厘米”,那么所有的 值都会放大100倍。根据协方差的线性性质:
仅仅因为单位的改变,计算出的协方差数值就膨胀了100倍。这使得我们无法通过协方差的绝对数值来判断相关性的强弱。一个协方差为1000的变量对,其真实的关联强度可能远远弱于一个协方差为0.5的变量对。
为了消除量纲的影响,获得一个纯粹度量线性相关强度的指标,我们需要对协方差进行标准化(Standardization)。
在单变量统计中,我们将变量减去均值并除以标准差,得到无量纲的标准分数(Z-score):
其中 ,。
现在,我们计算这两个标准化变量 和 之间的协方差。由于标准化变量的期望为0,它们的协方差就等于它们乘积的期望:
由于 和 都是常数,我们可以将它们提取到期望算子的外部:
观察等式右侧的分子,它恰好就是原始变量 和 的协方差 。因此,我们得到了:
这个将协方差按两个变量的标准差进行归一化的结果,就是统计学中最著名的皮尔逊相关系数(Pearson Correlation Coefficient),通常记为 。
从代数推导可以看出,皮尔逊相关系数本质上就是标准化变量之间的协方差。它彻底消除了量纲的影响,无论我们怎么对 或 进行线性缩放(如乘以常数或加上常数), 的值都将保持绝对不变。
此外,根据柯西-施瓦茨不等式(Cauchy-Schwarz Inequality),我们可以严格证明皮尔逊相关系数的取值范围被死死地限制在 之间。
对于任意两个随机变量的去中心化形式 和 ,柯西-施瓦茨不等式指出,它们内积的平方永远小于等于它们各自二范数(方差)的乘积:
将协方差和方差的定义代入上式:
两边同时除以 并开平方,我们立刻得到:
当且仅当 是 的线性函数,即 时,等号成立。如果 ,,表示完全正线性相关;如果 ,,表示完全负线性相关。
本节总结
在这一节中,我们从概率论的公理化体系出发,完成了对随机变量关系数学刻画的严密推导。
我们首先引入了联合概率密度函数 ,它是包含变量间所有互动信息的终极载体。通过对联合分布在不同维度上的积分投影,我们得到了边缘分布,并由此严谨地定义了统计独立性的基准线:。
为了从复杂的二维分布中提取可计算的特征,我们引入了二维期望算子。通过计算去中心化变量的乘积期望,我们推导出了协方差的代数形式。协方差本质上是变量向量在希尔伯特空间中的内积,它度量了变量间线性协同的趋势。
我们将双变量的协方差扩展到高维空间,构建了协方差矩阵 。通过证明其半正定性,我们揭示了协方差矩阵在几何上控制着多维概率分布的拉伸与旋转,是多元统计分析的核心引擎。
最后,为了克服协方差对量纲的敏感性,我们通过对变量进行标准化,推导出了无量纲的皮尔逊相关系数 ,并利用柯西-施瓦茨不等式证明了其 的绝对边界。
随机文章
-
 10个月宝宝每天需要喝多少奶粉?
10个月宝宝每天需要喝多少奶粉?
- Python-06基础语法-输入输出(体系文章)
- 最新AI+Python驱动的高光谱遥感全链路解析与典型案例实践高级培训班
- 10分钟用Python搭建模型驱动Agent
- 保姆级教程:Linux 安装 Zookeeper(附配置详解与常见问题)
- Python 每日精进:从基础到通透Python Daily Improvement: From Basics to Clarity
- Python数据分析基石NumPy全套干货Part.5
- Linux head 命令完全指南
- Python 测试工程师如何快速提升核心能力?
- 跨平台远程桌面完全指南:macOS、Linux与Windows的原生服务与协议选型
- 为什么 Win 叫 Admin, Linux 叫 root?
