Python数据分析基石NumPy全套干货Part.5
- 2026-07-04 05:25:11
Python数据分析基石NumPy全套干货Part.5(喜欢文章的朋友一定要点在关注呀~) 

往期回顾: Python可视化天花板|wordcloud词云库,搭配jieba做出高颜值创意图! Python中文分词神器jieba|精准拆分文本,数据分析必备! 用Python Pygame做小游戏|从设计到算法,手把手复刻经典款 baoyu-skills 全攻略:AI效率神器,一键解锁创作/办公超能力
第五篇:NumPy高阶花式玩法🎊实战技巧+避坑+效率提升
作为NumPy系列终篇,本篇不讲基础,全是高阶花式玩法、实战技巧、避坑指南和效率提升秘籍,帮大家把NumPy用得更熟练、更优雅,解决实战中遇到的各类疑难问题,从新手进阶为NumPy高手~
🎨 花式高阶玩法(实用又炫酷)
1. 条件筛选与布尔索引(精准筛选数据)
不用循环判断,直接用条件表达式筛选数组内符合要求的数据,高效过滤数据:
import numpy as nparr = np.array([1,2,3,4,5,6,7,8,9])# 筛选大于5的元素mask = arr > 5result = arr[mask]print("大于5的元素:", result)# 多维数组条件筛选arr2 = np.array([[1,12,3],[4,15,6]])print("大于10的元素:", arr2[arr2>10])
2. 数组拼接与拆分(合并/拆分数据集)
数据处理中常需要合并多个数组,或拆分一个数组,NumPy提供便捷的拼接、拆分方法:
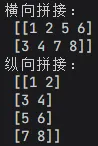
a = np.array([[1,2],[3,4]])b = np.array([[5,6],[7,8]])# 横向拼接h_stack = np.hstack((a,b))# 纵向拼接v_stack = np.vstack((a,b))# 数组拆分split_arr = np.hsplit(h_stack, 2)print("横向拼接:\n", h_stack)print("纵向拼接:\n", v_stack)
3. 数据类型转换与缺失值处理
处理数据时常遇到类型不匹配、缺失值(nan),NumPy轻松解决:
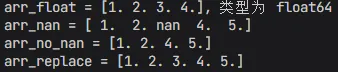
arr = np.array([1,2,3,4])# 转换为浮点型arr_float = arr.astype(np.float64)print(f"arr_float = {arr_float}, 类型为 {arr_float.dtype}")# 缺失值处理arr_nan = np.array([1,2,np.nan,4,5])print(f"arr_nan = {arr_nan}")# 去除缺失值arr_no_nan = arr_nan[~np.isnan(arr_nan)]print(f"arr_no_nan = {arr_no_nan}")# 缺失值替换为均值arr_replace = np.nan_to_num(arr_nan, nan=np.nanmean(arr_nan))print(f"arr_replace = {arr_replace}")
4. 排序与去重(数据清洗必备)
arr = np.array([3,1,4,1,5,9,2,6])# 数组排序arr_sort = np.sort(arr)# 数组去重arr_unique = np.unique(arr)print("排序后:", arr_sort)print("去重后:", arr_unique)
⚡ 效率提升实战技巧
尽量用NumPy内置函数,避免手写for循环,速度差距极大;
提前指定数组dtype,减少数据类型转换损耗;
大数据量优先用视图(切片),少用副本,节省内存;
随机运算固定种子,保证结果可复现。
🚫 高频避坑大全(实战总结)
坑1:数组数据类型统一,混入不同类型会自动强制转换,导致数据异常;
坑2:广播机制形状不兼容,提前用shape核对;
坑3:切片是视图,修改切片会改动原数组,想用副本加copy();
坑4:nan参与运算结果都是nan,先处理缺失值再计算;
坑5:axis参数记反,行和列计算结果出错。
🎯 系列终篇总结
历时5篇连载,我们从NumPy基础概念、数组创建、数组操控、核心运算,到高阶花式玩法,完整吃透了NumPy全知识点。
NumPy作为数据分析的基石,看似基础,实则贯穿整个数据科学领域,熟练掌握它,后续学习Pandas、Matplotlib、机器学习框架都会事半功倍,零基础也能顺利进阶数据领域。
赶紧把5篇内容串联起来,动手实操一遍,所有代码直接复制运行,很快就能熟练运用NumPy处理各类数值数据啦!
本文来自网友投稿或网络内容,如有侵犯您的权益请联系我们删除,联系邮箱:wyl860211@qq.com 。
随机文章
-
 10个月宝宝每天需要喝多少奶粉?
10个月宝宝每天需要喝多少奶粉?
- 告别一次性动作:我在 Python 的循环里,看见时间开始累积
- 让一台 Linux 平板“秒变”Android:Surface Go 2 的 GNOME + Phosh + Waydroid 双系统(伪)玩法(免重启)
- 【云码课堂】《为什么Python是程序员的“白月光”?这些热梗告诉你答案!》
- 靠少儿Python编程教程变现:零成本轻副业,小白也能做,每月稳赚3000+(合规无风险)
- 0基础小白30天从入门到精通,Python学习笔记
- 辅助日常办公常用的Python库
- Python的Litestar库介绍
- 今日金价速递&python金价案例分析 引言
- 发现个学 Python 的宝藏!用 GitHub 学才是真的高效
- Fastplotlib:一个Python快速绘图工具,支持前端PyQt/Side、wxPython,甚至 Jupyter Lab
