用 Python 写一个开源 RISC-V 向量编译器:MLIR 与 xDSL 的 GEMM 代码生成,较 OpenBLAS 最高提升 35%
- 2026-07-03 11:15:01
关键词:RISC-V、RVV、GEMM、MLIR、xDSL
在人工智能与高性能计算飞速发展的今天,芯片架构的多样性正成为开发者面临的最大挑战。从 x86 到 ARM,从 GPU 到 RISC-V,每一种架构都有其独特的指令集、内存层次和并行特性。特别是近年来异军突起的 RISC-V,以其开源、可扩展的优势吸引了全球的目光,但其向量扩展(RVV,RISC-V Vector Extension)的编程却远非易事。
如果你需要为一个深度学习模型编写高效的矩阵乘法内核,而这个内核需要适配不同向量长度的 RISC-V 处理器——有的只有 128 位向量寄存器,有的却有 256 位甚至更长。手动编写汇编代码?那将是一场噩梦。使用 C 语言加向量 Intrinsics?虽然可行,但需要针对每种微架构手工调优,开发成本极高。
这正是本文要解读的开源项目所解决的核心问题:如何让编译器自动生成高效、可移植的 RISC-V 向量代码?

Enabling RISC-V Vector Code Generation in MLIR through Custom xDSL Lowerings http://arxiv.org/pdf/2603.17800v1 代码:https://github.com/JieGH/RVV_code_gen_via_MLIR_xDSL 6000 字,阅读 20 分钟,播客 18 分钟
超越英伟达 B200 19%计算密度:7nm 四 Chiplet RISC-V 开源架构——面向 AI/HPC 的代际进化路线图 RISC-V HPC新标杆Sophon SG2044深度评估:支持RVV v1.0适配GCC 15.2,多核性能潜力巨大! Vortex RISC-V GPU 中 Warp 级特性的硬件与软件实现
这个项目来自学术界,提出了一种创新的混合编译方案——将 MLIR 与 xDSL 结合,构建了一条从高层抽象到底层 C 代码的完整降级(Lowering)路径。它的成果令人振奋:在 BERT-Large 模型推理中,自动生成的代码比 OpenBLAS 库快 2.4 倍!
让我们深入这个项目,看看它究竟解决了什么难题,以及背后的技术原理。
unsetunset本文目录unsetunset
一、问题:MLIR 的“最后一公里”困境 1.1 什么是 GEMM,为什么它如此重要? 1.2 RISC-V 向量扩展(RVV)的特殊性 1.3 MLIR 的“不完整降级” 二、解决方案:MLIR 与 xDSL 的“混血”编译管道 2.1 xDSL 是什么? 2.2 混合编译管道的整体架构 三、核心创新:自定义 RVV 方言与渐进式降级 3.1 以 微内核为例 3.2 自定义 RVV 方言的定义 3.3 降级 Pass 的实现:从 RVV 方言到 emitc 3.4 最终 C 代码的生成 四、性能评估:从微内核到完整 GEMM 4.1 微内核性能:寻找最优的 配置 4.2 GEMM 性能:与 OpenBLAS 的对比 4.3 性能分析:创新点与性能的关联 总结
 交流加群请在 NeuralTalk 公众号后台回复:加群
交流加群请在 NeuralTalk 公众号后台回复:加群unsetunset一、问题:MLIR 的“最后一公里”困境unsetunset
1.1 什么是 GEMM,为什么它如此重要?
矩阵乘法是线性代数的核心运算,也是深度学习模型的基石。一个卷积层、一个全连接层,最终都可以归结为 GEMM 操作:,其中 ,,。
在现代处理器上,要实现 GEMM 的极致性能,需要精心设计分块(Blocking)、打包(Packing)和微内核(Micro-kernel)。经典的高性能 GEMM 实现,如 GotoBLAS、OpenBLAS 都采用下图 1 所示的多层循环结构:

这里最关键的、也是最难优化的部分,就是微内核——图中 L6 循环内部的那一小段代码。它负责用向量指令更新一个 大小的 C 矩阵微瓦片,需要极致的寄存器重用和指令级并行。
1.2 RISC-V 向量扩展(RVV)的特殊性
与 ARM NEON 或 x86 AVX 不同,RVV 采用向量长度无关(VLA,Vector Length Agnostic)的设计理念。也就是说,向量寄存器的长度可以是任意值(128 位、256 位、512 位...),程序员编写的代码需要能够自适应不同的硬件向量长度。
这种设计虽然带来了可移植性,但也给编译器带来了巨大挑战:
向量长度需要动态获取:不能假设固定的向量宽度,代码必须用 vsetvli指令动态设置向量长度。寄存器的动态分组:RVV 允许将多个向量寄存器组合成更大的寄存器组(LMUL),但如何选择 LMUL 需要根据微内核尺寸和硬件向量长度共同决定。 Intrinsic 接口复杂:RVV 1.0 的 C 语言 Intrinsic 数量庞大,每个操作都有多种变体(如 vfmacc_vf_f32m1、vfmacc_vv_f32m2等),手动选择极为繁琐。
1.3 MLIR 的“不完整降级”
MLIR(Multi-Level Intermediate Representation)是 LLVM 生态中用于构建编译器的强大框架。它支持多级抽象,通过方言(Dialect)机制,可以从高层张量运算逐步降级到底层机器码。
然而,当项目团队尝试直接用 MLIR 生成 RVV 代码时,遇到了一个棘手的问题:MLIR 的 emitc 方言无法完整处理 memref 动态数组的降级。
简单来说,MLIR 的 memref 方言提供了多维数组的抽象,但在降级到 C 语言时,对于动态大小的数组(如memref<?xf32>),其转换 Pass 并不完善,导致无法生成标准的 C 指针代码。而 GEMM 内核中大量使用了动态大小的缓冲区(Ac、Bc),这个“最后一公里”的缺失使得直接使用 MLIR 生成 RVV 代码成为泡影。
unsetunset二、解决方案:MLIR 与 xDSL 的“混血”编译管道unsetunset
面对 MLIR 的局限,项目团队没有选择在 C++层面硬啃 MLIR 的 Pass 实现(开发成本极高),而是巧妙地引入了xDSL——一个 Python 原生的编译器开发工具包。
2.1 xDSL 是什么?
xDSL 是 MLIR 的“轻量级 Python 表亲”。它继承了 MLIR 的核心概念(操作、区域、块、方言),但用 Python 实现了完整的 IR 构建和降级框架。它的优势在于:
快速原型:无需编译,即可定义新方言、实现降级 Pass。 与 MLIR 互操作:可以生成标准的 MLIR IR,然后交给 MLIR 工具链继续处理。 脚本化集成:可以轻松与测试框架、性能分析工具集成,实现端到端的自动化。
2.2 混合编译管道的整体架构
项目的核心创新就是构建了一条如图 2 所示的混合编译流水线:
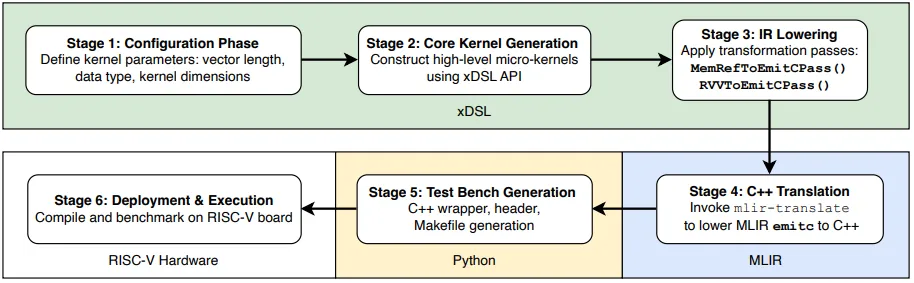
整个流水线的工作流程如下:
Stage 1-2(xDSL 环境):用户指定微内核参数(、数据类型、目标向量长度),xDSL 动态生成高层的 MLIR IR,并应用一系列降级 Pass(MemRefToEmitC、SCFToEmitC、RVVToEmitC)。 Stage 3(输出 emitc):经过降级后,IR 被转换为纯 emitc 方言。 Stage 4-6(MLIR 工具链+部署):利用 MLIR 的 mlir-translate工具将 emitc 转换为 C 代码,自动生成测试程序、编译并部署到 RISC-V 开发板上运行。
这种混合架构的精妙之处在于:用 Python 的灵活性弥补了 MLIR C++生态的刚性,同时保留了 MLIR 工具链的成熟后端。
unsetunset三、核心创新:自定义 RVV 方言与渐进式降级unsetunset
让我们深入到代码层面,看看这个管道是如何一步步将抽象的矩阵运算转化为具体的 RVV Intrinsic 的。
3.1 以 微内核为例
假设我们要生成一个 的微内核,目标平台是 256 位向量(可容纳 8 个单精度浮点数)。

那么最内层的 L6 循环(如图 1 所示)会执行以下操作:
从 Ac 缓冲区加载一个向量(8 个元素)到向量寄存器。 对 Bc 的每一列(共 4 列),执行一次标量-向量乘加(FMA)。
在 xDSL 中,我们可以用 Python 代码来构建这个 L6 循环的 IR。图 3 展示了生成 L6 循环的 Python xDSL 代码:

上面这段 Python 代码展示了如何用 xDSL 的 API 构建微内核最内层循环。作者将 RVV 硬件语义融入 xDSL 的高层抽象,通过自定义 API 生成多方言的 MLIR IR,避免了手动编写汇编级代码的低效性,还能动态适配不同 mr/nr 微内核维度,为后续 IR 的下降低级提供了简洁且可扩展的高层抽象基础。
这段 Python 代码执行后,会生成如下代码所示的包含 L6 循环的
scf.for表示与 FMA 操作绑定的 MLIR IR:

第 5-6 行展示了自定义的 rvv.vfmacc_vf_f32m10p操作,它接受 5 个参数:累加器、Bc 内存指针、偏移量、Ar 向量寄存器和向量长度。第 9 行将新的累加器值通过 scf.yield传递给下一次迭代。
注意这里的rvv.命名空间——这是项目团队自定义的RVV MLIR 方言,用于封装 RVV 指令的语义。

3.2 自定义 RVV 方言的定义
那么,这个自定义方言是如何在 xDSL 中定义的?下图 6 展示了
vfmacc_vf_f32m10p操作的定义:
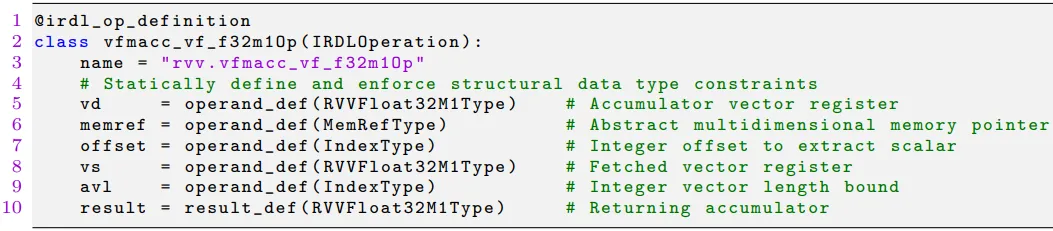
可以看出,通过继承IRDLOperation并定义操作名、操作数和结果,xDSL 可以轻松创建新的 MLIR 方言操作。这个定义明确了 FMA 操作需要 5 个输入(累加器、内存指针、偏移量、向量寄存器、向量长度)和 1 个输出(新的累加器),并强制执行类型约束。
3.3 降级 Pass 的实现:从 RVV 方言到 emitc
定义了方言之后,下一步是实现降级 Pass,将自定义的 RVV 操作转换为 emitc 中的
emitc.opaque调用。下图 7 展示了这个 Rewrite Pattern 的实现:
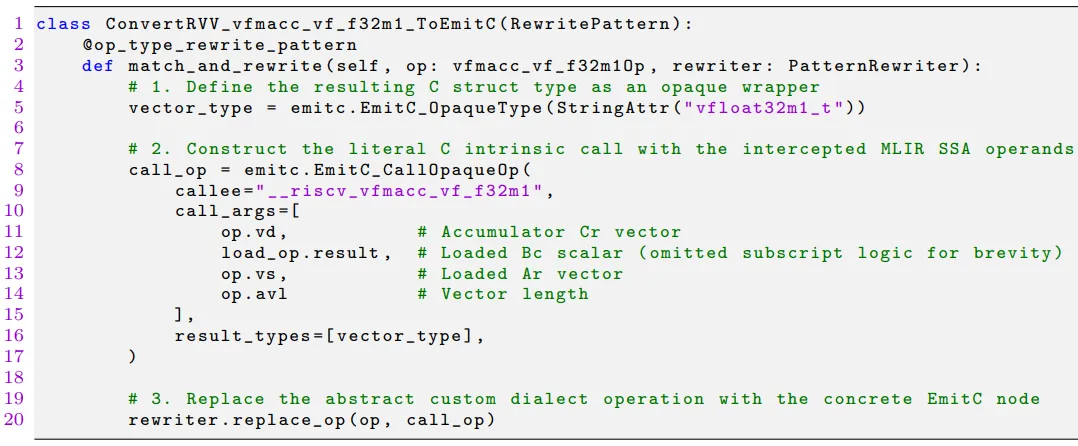
match_and_rewrite函数在遍历 IR 时捕获vfmacc_vf_f32m10p操作,提取其操作数,然后构建一个emitc.CallOpaqueOp,该操作将直接输出 C 语言的 RVV Intrinsic 字符串,如_riscv_vfmacc_vf_f32m1。该重写模式通过 match_and_rewrite 函数拦截自定义 RVV 方言操作,将其转换为 emitc 的透明调用,是 IR 下降低级的核心逻辑。此模式复用了 MLIR 的模式重写基础设施,实现了 RVV 抽象操作到硬件特定代码的自动化映射,避免了手动编写底层内联函数代码的工作量,大幅提升了 RVV 代码生成的自动化程度和可维护性。
经过这个降级 Pass 后,FMA 操作变成了如图 8 所示的 emitc 代码:

该表示将自定义 RVV FMA 操作转化为 emitc 的 call_opaque 透明调用,保留了 vfloat32m1_t 等 RVV 硬件特定数据类型。此表示是 MLIR IR 到最终 C 代码的关键中间态,其透明调用能直接映射为 RISC-V 的 RVV 原生内联函数,既保障了生成代码的硬件适配性,又完全兼容 MLIR 的官方编译流程,实现了抽象与硬件的无缝衔接。
3.4 最终 C 代码的生成
最后,通过 MLIR 的mlir-translate工具,emitc 代码被转换为标准 C 代码(如图 9 所示):

scf.for循环变为 C 的for循环(第 5 行),RVV 操作变为具体的 Intrinsic 调用(第 7、12 行)。可以直接被任何支持 RVV 的 RISC-V 编译器如 gcc编译。注意vfloat32m1_t类型和_riscv_vle32_v_f32m1、_riscv_vfmac_v_f32m1等 RVV Intrinsic,它们与硬件向量长度无关,能够自适应不同的向量寄存器宽度。该代码将 MLIR 的 SSA 形式 IR 转为含 RVV 原生内联函数的标准 C 代码,用可变变量替代 SSA 的寄存器复用,实现了 L6 循环的硬件加速。此代码是 MLIR-xDSL 混合流水线的直接产物,验证了流水线能生成可直接编译执行的 RVV 优化代码,其代码结构高度适配 RISC-V 硬件特性,为 gemm 微内核提供了高效的底层计算实现,是性能提升的核心载体。
至此,一条从高层抽象到可执行 C 代码的完整路径被打通了。
unsetunset四、性能评估:从微内核到完整 GEMMunsetunset
项目团队在两个真实的 RISC-V 开发板上进行了详细的性能评估:
K230:CanMV-K230 开发板,C908 核心,1.6GHz,128 位向量单元。 BPI:BananaPi F3 开发板,SpaceMiT K1 处理器,1.6GHz,256 位向量单元。
4.1 微内核性能:寻找最优的 配置
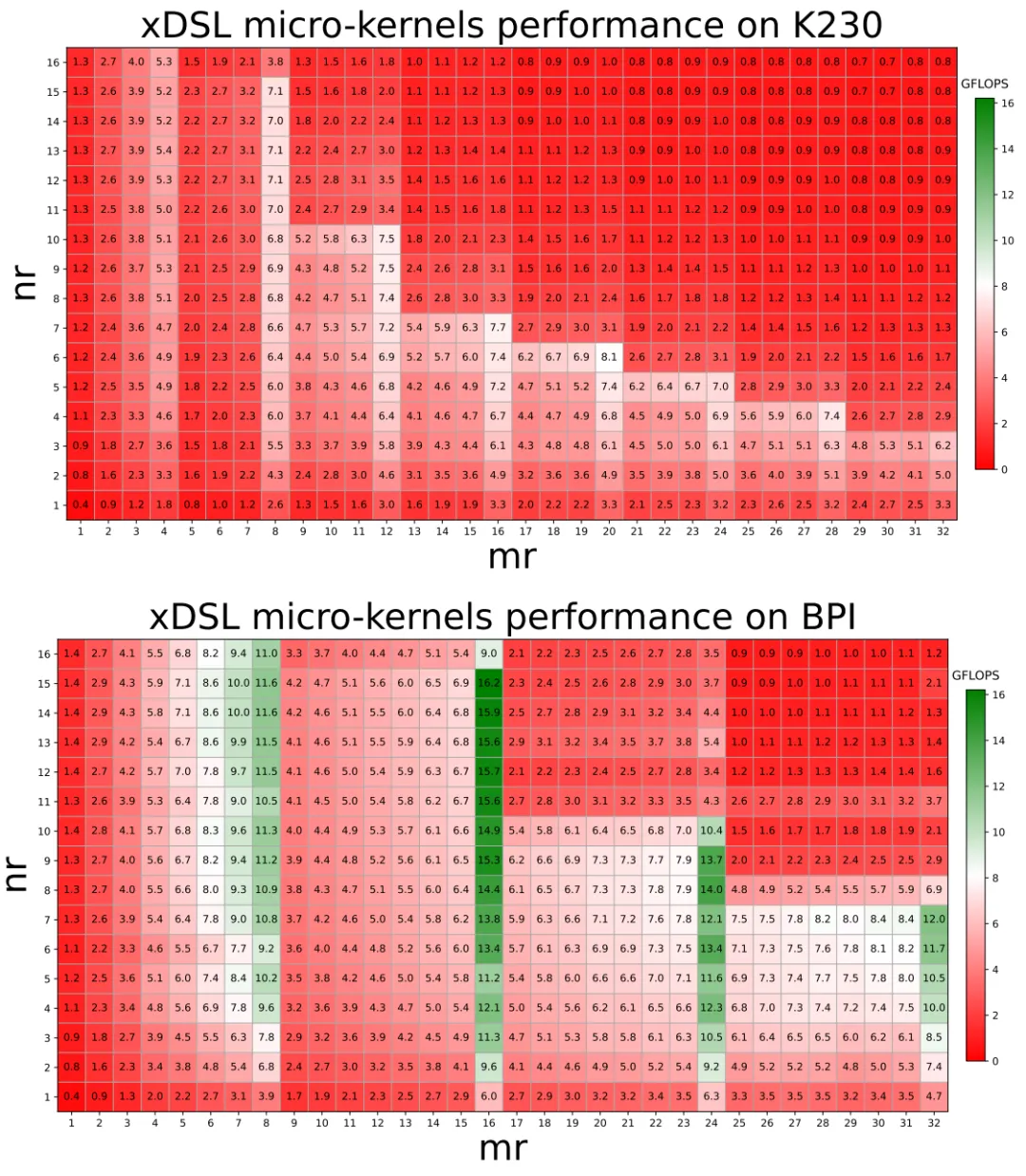
观察结果:
在 K230 上,最佳配置是 ,达到8.1 GFLOPS。 在 BPI 上,最佳配置是 ,达到16.2 GFLOPS。
有趣的是,最佳配置并不一定是向量宽度的简单倍数如 ,这表明微内核尺寸需要综合考虑向量宽度、寄存器压力和缓存行为。
4.2 GEMM 性能:与 OpenBLAS 的对比
为了评估微内核在实际 GEMM 中的效果,项目团队测试了两种工作负载:
正方形矩阵:S1-S5,从 1000×1000 到 5000×5000 BERT-Large 模型推理中的 GEMM 形状,B1-B5,如表 1 所示
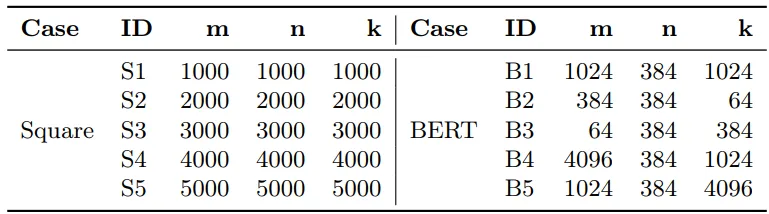
图 11 展示了完整的性能对比结果
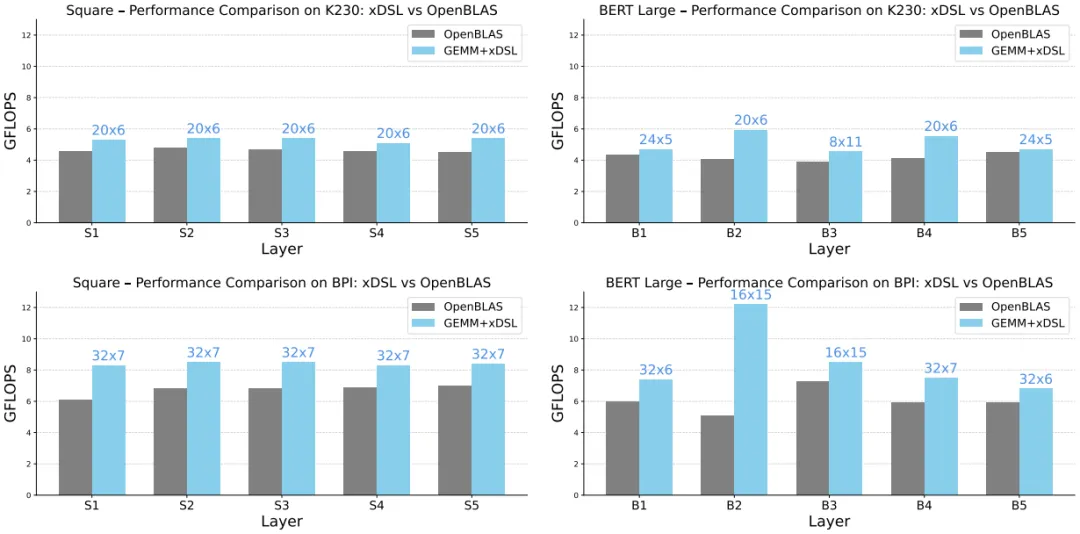
该图是论文的核心性能评估结果,清晰显示 xDSL 微内核在两类场景、两个 RVV 平台均显著优于 OpenBLAS,且在 BPI 平台和 BERT 非规则矩阵场景中提升更显著(最高 2.4 倍)。此结果验证了 MLIR-xDSL 混合编译方法的有效性,层特定分块策略完美适配了深度学习的非规则矩阵特性,证明该方法能更高效地利用 RVV 硬件的向量计算资源,具备实际应用价值。
关键发现 1. 在 K230(128 位向量)上
正方形矩阵:xDSL 比 OpenBLAS 快10-15%(5.1-5.4 GFLOPS vs 4.5-4.9 GFLOPS)。 BERT 工作负载:xDSL 领先优势更明显,B2 层提升47%(5.9 vs 4.0 GFLOPS),其他层提升 10-35%。
值得注意的是,BERT 工作负载中不同层选用了不同的微内核配置(、、),而在正方形矩阵中只用了 一种配置。这说明自适应微内核选择对于不规则形状的矩阵尤为重要。
关键发现 2. 在 BPI(256 位向量)上
正方形矩阵:xDSL 比 OpenBLAS 快20-35%(8.3-8.6 vs 6.1-7.0 GFLOPS)。 BERT 工作负载:差距进一步拉大,B2 层达到2.4 倍速度提升(12.2 vs 5.1 GFLOPS)!
这种巨大差距的原因在于:OpenBLAS 为 BPI 预编译的微内核是 ,而 xDSL 为 B2 层选择了更优的 配置,更好地匹配了矩阵维度(384×384×64),减少了边缘处理开销。
4.3 性能分析:创新点与性能的关联
性能数据的背后,反映了项目几个核心创新点的价值:
自动化微内核生成:传统手工优化只能提供有限几种微内核配置,OpenBLAS 只提供 或 ,而 xDSL 可以自动生成所有可能的 组合,覆盖各种边缘情况。这在 BERT 这种形状多样化的负载中尤其关键。
向量长度自适应:RVV 的向量长度无关特性在 xDSL 中得到了充分利用。同一份 IR 代码可以针对 128 位和 256 位平台生成不同的 C 代码,无需手动重写。这在 BPI 上实现 2.4 倍加速的背后,是微内核尺寸与向量宽度的完美匹配。
降低的开销:与 MLIR 直接方案相比,xDSL 的降级 Pass 避免了不必要的内存分配和指针间接访问,使得生成的 C 代码更接近手写汇编的效率。
unsetunset总结unsetunset
这个项目展示了如何用现代的编译器技术解决一个实际的性能可移植性难题。通过构建 MLIR 与 xDSL 的混合编译管道,它成功实现了:
填补 MLIR 的降级空白:用 xDSL 的 Python 框架快速实现了 memref 到 C 指针、scf 到 C 循环、自定义 RVV 方言到 C Intrinsic 的降级。 自动化的微内核生成:可以一键生成所有可能的 配置,并针对不同工作负载自动选择最优配置。 可移植的高性能:在两种不同的 RVV 平台上,生成的 GEMM 代码都超越了经过高度优化的 OpenBLAS 库。
从更广阔的视角看,这个项目为 RISC-V 生态的软件开发提供了一条新思路:与其为每个新架构手写汇编,不如构建一个灵活、可扩展的编译器框架,让机器自动完成最繁琐的优化工作。
未来,这个框架还可以扩展到更多线性代数内核(如卷积、FFT)、混合精度计算,甚至自动生成打包(Packing)例程。随着 RISC-V 硬件生态的日益丰富,这样的编译器工具将变得越来越重要。
随机文章
-
 10个月宝宝每天需要喝多少奶粉?
10个月宝宝每天需要喝多少奶粉?
- 发现个学 Python 的宝藏!用 GitHub 学才是真的高效
- Fastplotlib:一个Python快速绘图工具,支持前端PyQt/Side、wxPython,甚至 Jupyter Lab
- 0基础学python(7)
- 热情追求python的两天
- 第三篇:NVIDIA cuOpt Python API 详解:LP、QP、MILP 建模与求解,附核心术语名词解释
- 【Python钢琴节奏大师·第6讲】声音交互篇-Pygame音效播放与鼠标点击检测
- python笔记系列之——运算符
- 相关性分析(基于python)1——相关性问题的提出与误区
- Python基础练习:炸金花拖拉机文字版1
- 如何用python手搓一个“龙虾”
