相关性分析(基于python)1——相关性问题的提出与误区
- 2026-07-04 06:49:53
在处理实际数据时,我们面对的通常是一个多维的数据矩阵。矩阵的每一列代表一个特征或变量,每一行代表一个观测样本。单变量统计学解决的是某一列数据的分布形态问题,比如它的期望是多少、方差有多大。而当我们试图探究不同列之间是否存在某种协同变化的规律时,就正式踏入了相关性分析的领域。
从严格的概率论视角来看,描述两个随机变量 和 之间关系的终极工具是它们的联合累积分布函数 。如果这两个变量在统计上完全独立,那么它们的联合分布就等于各自边缘分布的乘积,即 。
相关性分析的核心目的,本质上就是去度量真实的联合分布 偏离独立假设 的程度。
但在工程实践中,直接估计和比较二维甚至高维的联合概率分布是非常困难的,尤其是在样本量有限的情况下。为了降低计算复杂度并获得直观的业务解释,统计学家们倾向于将这种复杂的二维分布关系,投影或压缩成一个一维的标量数值。大家最熟悉的皮尔逊相关系数(Pearson Correlation Coefficient)就是这种降维思想的产物。
问题恰恰出在这个降维压缩的过程中。将一个包含丰富几何结构的二维分布强行浓缩为一个实数,必然会伴随严重的信息丢失。如果不理解这种信息丢失的数学机制,就很容易在数据分析中得出荒谬的结论。
1降维压缩导致的信息坍塌
我们可以通过构造特定的数据集来观察这种信息丢失是如何发生的。假设我们手头有几个不同的二维数据集,我们分别计算它们的 均值、 均值、 方差、 方差,以及 和 之间的皮尔逊相关系数。
如果计算结果显示,这几个数据集的上述五个统计量完全一致,常规的自动化分析脚本会判定这几个数据集具有相同的数据结构和变量关系。英国统计学家弗朗西斯·安斯库姆在1973年针对这种盲目依赖统计摘要的做法,构造了四个经典的数据集,也就是后来被称为安斯库姆四重奏的数据矩阵。
在这四个数据集中,变量的均值和方差在保留两位小数的精度下完全相同,且皮尔逊相关系数均为0.816。单看数值,它们表现出高度一致的正向线性关系。但只要将这些数据点映射到二维笛卡尔坐标系中,隐藏在标量背后的真实拓扑结构就会显现出来。
我们用Python代码直接生成这四个数据集,并进行可视化对比。这段代码利用了NumPy和SciPy进行基础的统计计算,通过Matplotlib展示底层几何形态。
import numpy as npimport matplotlib.pyplot as pltfrom scipy import stats# 配置Matplotlib以支持中文字体显示plt.rcParams['font.sans-serif'] = ['SimHei']plt.rcParams['axes.unicode_minus'] = False# 构造安斯库姆四重奏的原始数据矩阵# x1到x4为自变量,y1到y4为因变量x1 = np.array([10.0, 8.0, 13.0, 9.0, 11.0, 14.0, 6.0, 4.0, 12.0, 7.0, 5.0])y1 = np.array([8.04, 6.95, 7.58, 8.81, 8.33, 9.96, 7.24, 4.26, 10.84, 4.82, 5.68])x2 = np.array([10.0, 8.0, 13.0, 9.0, 11.0, 14.0, 6.0, 4.0, 12.0, 7.0, 5.0])y2 = np.array([9.14, 8.14, 8.74, 8.77, 9.26, 8.10, 6.13, 3.10, 9.13, 7.26, 4.74])x3 = np.array([10.0, 8.0, 13.0, 9.0, 11.0, 14.0, 6.0, 4.0, 12.0, 7.0, 5.0])y3 = np.array([7.46, 6.77, 12.74, 7.11, 7.81, 8.84, 6.08, 5.39, 8.15, 6.42, 5.73])x4 = np.array([8.0, 8.0, 8.0, 8.0, 8.0, 8.0, 8.0, 19.0, 8.0, 8.0, 8.0])y4 = np.array([6.58, 5.76, 7.71, 8.84, 8.47, 7.04, 5.25, 12.50, 5.56, 7.91, 6.89])data_pairs = [ ('数据集 I: 典型的线性噪声模型', x1, y1), ('数据集 II: 确定性的非线性模型', x2, y2), ('数据集 III: 包含离群点的线性模型', x3, y3), ('数据集 IV: 极端的杠杆点模型', x4, y4)]fig, axes = plt.subplots(2, 2, figsize=(12, 10))fig.suptitle('标量压缩导致的信息丢失:安斯库姆四重奏', fontsize=16)for ax, (title, x, y) in zip(axes.flatten(), data_pairs):# 绘制原始数据散点 ax.scatter(x, y, color='#2c7bb6', s=50, zorder=5)# 计算线性回归参数用于绘制拟合线 slope, intercept, r_value, _, _ = stats.linregress(x, y)# 生成拟合线的坐标点 x_plot = np.linspace(np.min(x)-1, np.max(x)+1, 50) y_plot = slope * x_plot + intercept# 绘制回归线 ax.plot(x_plot, y_plot, color='#d7191c', linestyle='--', linewidth=2, zorder=4)# 在图表区域标注核心统计量 stats_info = f"E[X]={np.mean(x):.2f}, Var[X]={np.var(x, ddof=1):.2f}\n" \f"E[Y]={np.mean(y):.2f}, Var[Y]={np.var(y, ddof=1):.2f}\n" \f"Pearson r={r_value:.3f}" ax.text(0.05, 0.95, stats_info, transform=ax.transAxes, fontsize=10, verticalalignment='top', bbox=dict(boxstyle='round', facecolor='white', alpha=0.9)) ax.set_title(title, fontsize=12) ax.set_xlim(2, 20) ax.set_ylim(2, 14) ax.grid(True, linestyle=':', alpha=0.6)plt.tight_layout(rect=[0, 0.03, 1, 0.96])plt.show()执行结果如下:
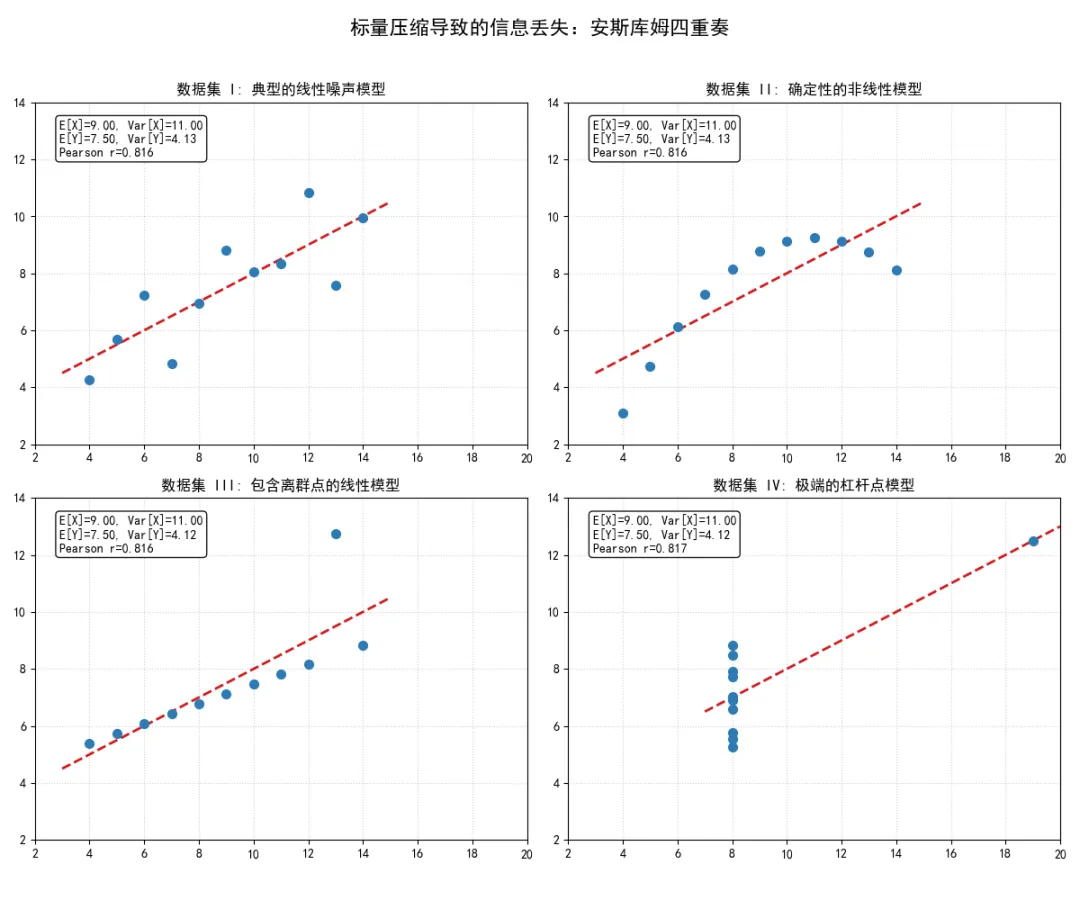
上述代码后生成的四张图表,直观地展示了0.816这个相关系数在不同几何结构下的物理意义。
数据集I是统计学中最理想的假设场景,数据服从带有高斯噪声的线性模型,此时0.816准确反映了变量间的线性约束强度。数据集II是一个完美的二次函数抛物线,变量间存在强烈的确定性关系,但用线性模型去拟合它不仅残差很大,而且0.816这个数值掩盖了底层的非线性规律。
数据集III和IV则暴露了皮尔逊相关系数对异常值的极度敏感性。在数据集III中,原本完美的线性关系被一个偏离群体的观测值拉低了相关系数;而在数据集IV中,原本毫无方差、完全不相关的变量,仅仅因为一个高杠杆点的存在,就伪造出了0.816的高相关性。
这说明在未对数据联合分布进行可视化审查之前,任何基于单一相关系数做出的推断都缺乏稳健性。
2零相关的代数陷阱
基于安斯库姆四重奏的观察,我们发现高相关系数可能是一种假象。现在我们从数学推导的角度来看另一个极端:当计算出的相关系数为0时,是否意味着两个变量在统计上相互独立?
要回答这个问题,需要回到协方差的代数定义。对于随机变量 和 ,它们的协方差定义为各自偏离均值的乘积的期望:
将其展开后,可以得到一个更便于计算的形式:
皮尔逊相关系数 则是将协方差按两个变量的标准差进行归一化:
由于分母的标准差始终为正数,相关系数为0的充要条件就是协方差为0,即 。
现在我们构造一个具体的概率模型。假设随机变量 服从标准正态分布,即 。根据标准正态分布的性质,它的期望 。
接着我们定义变量 为 的平方,即 。在这个设定下, 和 之间存在严格的函数映射关系,只要给定 , 的值是唯一确定的,它们显然极度不独立。
我们来计算此时 和 的协方差。将 代入协方差展开式:
对于标准正态分布而言,其概率密度函数 是一个关于Y轴对称的偶函数。当我们计算奇数阶原点矩 时,被积函数 变为了奇函数。奇函数在对称区间 上的定积分为0,因此 。
同时,由于 ,公式的后半部分 也为0。
最终我们得到:
代数推导给出了一个明确的结论:尽管 构成了完美的非线性依赖,但它们的协方差和皮尔逊相关系数严格等于0。
这个数学事实指出了线性相关系数的根本局限。协方差本质上是在度量两个变量在向量空间中的线性投影关系。当变量间的关系呈现出某种对称的非线性结构时,正向的偏差和负向的偏差在计算期望时会相互抵消,导致最终的内积为0。
为了加深对这一代数陷阱的理解,我们编写一段程序,模拟几种典型的非线性依赖结构,并计算它们的相关系数。
import numpy as npimport matplotlib.pyplot as pltfrom scipy import statsplt.rcParams['font.sans-serif'] = ['SimHei']plt.rcParams['axes.unicode_minus'] = False# 设定随机种子以保证实验可复现np.random.seed(42)# 场景A:标准正态分布下的平方关系x_sq = np.random.normal(0, 1, 500)y_sq = x_sq**2# 场景B:均匀分布下的正弦波关系x_sin = np.random.uniform(-np.pi, np.pi, 500)y_sin = np.sin(x_sin)# 场景C:二维平面上的圆环结构# 先生成极坐标下的角度和半径,再转换为笛卡尔坐标theta = np.random.uniform(0, 2*np.pi, 500)r = np.random.normal(5, 0.2, 500)x_circle = r * np.cos(theta)y_circle = r * np.sin(theta)experiments = [ ("Y = X^2 (抛物线)", x_sq, y_sq), ("Y = sin(X) (正弦波)", x_sin, y_sin), ("X^2 + Y^2 = R^2 (圆环)", x_circle, y_circle)]fig, axes = plt.subplots(1, 3, figsize=(15, 5))for ax, (title, x, y) in zip(axes, experiments):# 计算皮尔逊相关系数和p值 r_val, p_val = stats.pearsonr(x, y) ax.scatter(x, y, alpha=0.6, color='#5e4fa2', edgecolors='none', s=30)# 绘制水平基准线以辅助视觉判断 ax.axhline(np.mean(y), color='gray', linestyle='--', alpha=0.5) ax.axvline(np.mean(x), color='gray', linestyle='--', alpha=0.5) ax.set_title(f'{title}\nPearson r = {r_val:.4f}', fontsize=12) ax.set_xlabel('X') ax.set_ylabel('Y')plt.tight_layout()plt.show()执行结果如下:
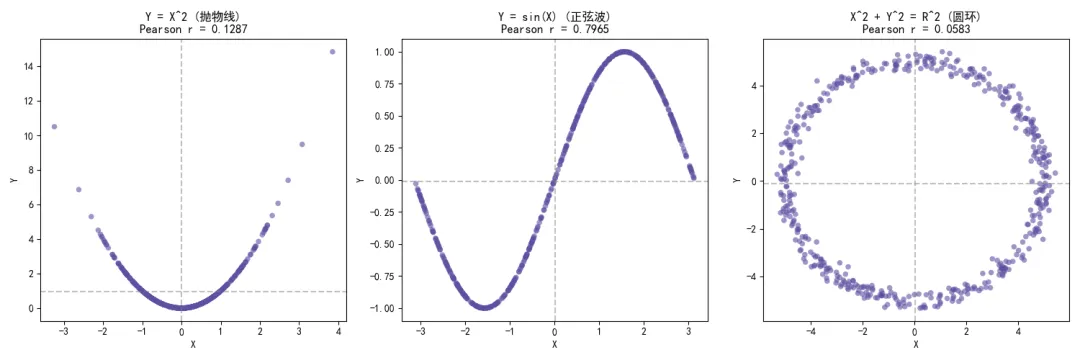
程序输出的散点图清晰地展示了抛物线、正弦波和圆环三种几何形态。在这些结构中,给定 的坐标,往往能极大地缩小 的取值范围,说明两者蕴含着极高的互信息。然而,图表上方打印的皮尔逊相关系数全部在0附近徘徊。
如果在特征工程或变量筛选阶段,仅仅依赖相关系数矩阵来剔除所谓的无关特征,上述这些包含确定性物理规律的变量就会被算法无情地丢弃。这要求我们在处理未知数据时,必须引入能够捕捉非线性依赖的度量工具,例如斯皮尔曼等级相关或基于信息熵的互信息。
3潜在变量的代数分解与虚假相关
在排除了非线性关系导致的“零相关”陷阱后,我们转向相关性分析中更具欺骗性的另一个极端:两个变量之间计算出了极高的相关系数,但在物理机制或业务逻辑上,它们之间根本不存在任何直接的因果联系。
这种现象在统计学中被称为虚假相关(Spurious Correlation)。要理解虚假相关的生成机制,我们需要引入一个尚未被观测到的第三变量,通常称为潜在变量(Latent Variable)或混淆变量(Confounding Variable)。
我们可以通过构建一个简单的线性生成模型(Generative Model),从代数层面推导虚假相关是如何无中生有的。
假设存在一个真实的物理过程,其中变量 是核心驱动因素。 的波动同时引起了变量 和变量 的变化。为了用数学语言描述这个过程,我们建立如下的线性方程组:
在这个系统中, 和 是常数系数,代表 对 和 的真实作用强度。 和 是随机误差项,代表了除了 之外,影响 和 的其他独立因素。
为了保证推导的严谨性,我们设定几个基本的统计假设:
潜在变量 具有一定的波动性,即方差 。 误差项 和 的期望均为0,即 。 、 和 三者之间相互独立。这意味着它们两两之间的协方差为0,例如 ,。
现在,假设作为数据分析师的我们,由于观测手段的限制,并不知道 的存在。我们的数据集中只有 和 两列数据。当我们去计算 和 之间的协方差时,会得到什么结果?
根据协方差的定义 ,我们首先求 和 的期望:
接下来计算它们偏离期望的差值:
将这两个差值代入协方差公式并展开乘积:
利用期望的线性性质,我们可以将上式拆分为四项的期望之和。
第一项:。根据方差的定义,这等于 。 第二项:。由于 和 独立,且 ,该项等于 。 第三项:同理,由于 和 独立,该项为0。 第四项:。由于 和 独立,且期望均为0,该项等于 。
最终,我们得到了一个极其简洁但意味深长的结论:
这个等式从根本上解释了虚假相关的来源。只要潜在变量 存在波动(),并且它同时对 和 产生影响( 且 ),那么 和 之间的协方差就必然不为0。
即使 和 在物理机制上毫无交集,它们也会在统计计算中表现出高度的同步性。如果我们进一步将协方差标准化为皮尔逊相关系数,这种同步性就会以一个接近1或-1的数值呈现出来,从而误导分析结论。
为了将这个代数推导具象化,我们编写一段Python代码来模拟一个经典的统计学案例:冰淇淋销量与溺水事故数量的关系。这两个变量显然没有因果联系,但它们都受到气温(潜在变量 )的驱动。
import numpy as npimport matplotlib.pyplot as pltfrom scipy import statsplt.rcParams['font.sans-serif'] = ['SimHei']plt.rcParams['axes.unicode_minus'] = False# 设定随机种子np.random.seed(1024)# 模拟潜在变量 Z:夏季每日最高气温(摄氏度)# 假设气温服从均值为 30,标准差为 4 的正态分布temperature_Z = np.random.normal(loc=30, scale=4, size=200)# 模拟变量 X:某景区的冰淇淋日销量(百支)# 销量受气温正向驱动(alpha = 2.0),并伴随随机波动error_X = np.random.normal(loc=0, scale=3, size=200)ice_cream_X = 2.0 * temperature_Z + error_X# 模拟变量 Y:该市公开水域的溺水救援次数# 救援次数同样受气温正向驱动(beta = 0.5),并伴随随机波动error_Y = np.random.normal(loc=0, scale=1.5, size=200)drowning_Y = 0.5 * temperature_Z + error_Y# 创建1x3的子图布局fig, axes = plt.subplots(1, 3, figsize=(15, 5))# 图1:观察到的表象(X与Y的关系)r_xy, _ = stats.pearsonr(ice_cream_X, drowning_Y)axes[0].scatter(ice_cream_X, drowning_Y, alpha=0.6, color='#d95f02', edgecolors='white')slope_xy, intercept_xy, _, _, _ = stats.linregress(ice_cream_X, drowning_Y)x_fit = np.linspace(min(ice_cream_X), max(ice_cream_X), 100)axes[0].plot(x_fit, slope_xy * x_fit + intercept_xy, color='black', linestyle='--')axes[0].set_title(f'表象:冰淇淋销量 vs 溺水次数\nPearson r = {r_xy:.3f}')axes[0].set_xlabel('冰淇淋销量 (X)')axes[0].set_ylabel('溺水救援次数 (Y)')# 图2:真实的底层机制1(Z对X的驱动)r_zx, _ = stats.pearsonr(temperature_Z, ice_cream_X)axes[1].scatter(temperature_Z, ice_cream_X, alpha=0.6, color='#1b9e77', edgecolors='white')axes[1].set_title(f'机制1:气温驱动销量\nPearson r = {r_zx:.3f}')axes[1].set_xlabel('气温 (Z)')axes[1].set_ylabel('冰淇淋销量 (X)')# 图3:真实的底层机制2(Z对Y的驱动)r_zy, _ = stats.pearsonr(temperature_Z, drowning_Y)axes[2].scatter(temperature_Z, drowning_Y, alpha=0.6, color='#7570b3', edgecolors='white')axes[2].set_title(f'机制2:气温驱动溺水事故\nPearson r = {r_zy:.3f}')axes[2].set_xlabel('气温 (Z)')axes[2].set_ylabel('溺水救援次数 (Y)')for ax in axes: ax.grid(True, linestyle=':', alpha=0.6)plt.tight_layout()plt.show()执行结果如下:
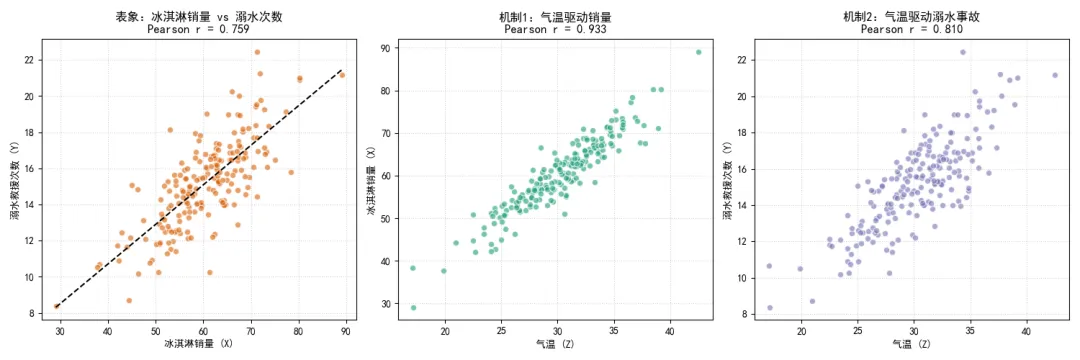
最左侧的图表展示了我们在未观测到气温时所面临的数据表象。冰淇淋销量与溺水次数呈现出显著的正相关(r值通常在0.7以上)。如果仅凭这一相关系数进行业务决策,可能会得出“限制冰淇淋销售以减少溺水事故”的荒谬结论。中间和右侧的图表则还原了数据生成的真实物理过程,解释了这种虚假相关是如何通过气温这个混淆变量传递的。
4辛普森悖论:全协方差定律下的方向逆转
虚假相关仅仅是混淆变量在整体层面上制造的一种数值假象。当混淆变量不仅影响变量的均值,还与数据的分组结构发生强烈耦合时,我们会遇到统计学中一个更为极端的现象——辛普森悖论(Simpson's Paradox)。
辛普森悖论描述的是这样一种反直觉的场景:在数据的各个子群中,变量 和 呈现出某种明确的相关性(例如负相关);但当我们忽略分组,将所有数据合并为一个整体时,这种相关性不仅可能消失,甚至会发生方向性的逆转(变成正相关)。
要从数学上彻底解析辛普森悖论,我们需要引入概率论中的全协方差定律(Law of Total Covariance)。
假设我们将全体数据按照潜在变量 (例如年龄段、性别、地区等离散变量)划分为若干个子群。全协方差定律指出,总体中 和 的协方差,可以严格分解为两部分的和:
这个公式是理解辛普森悖论的钥匙。我们逐项来拆解它的物理意义。
公式的第一项 被称为组内协方差的期望。 表示在给定的某一个子群(比如特定的年龄段)内部, 和 的协方差。 则是对所有子群的组内协方差按照其样本比例求加权平均。这一项反映了在控制了变量 之后, 和 之间真实的微观关系。
公式的第二项 被称为组间均值的协方差。 和 分别是各个子群中 和 的均值。这一项度量的是,随着子群 的变化, 的组均值和 的组均值是否呈现出宏观上的同步波动。
辛普森悖论发生的数学条件,就是公式的第二项(组间效应)在绝对值上压倒了第一项(组内效应),并且两者的符号相反。
我们设定一个医疗健康领域的具体场景来代入这个公式。假设我们正在研究“每周运动时长”()与“心血管疾病风险指数”()之间的关系。潜在的分组变量 是“年龄段”(分为青年、中年、老年)。
在微观层面(组内效应),无论在哪个年龄段,运动都有助于降低疾病风险。因此,在任何给定的 下, 都是负数。第一项 必然是一个负值。
但在宏观层面(组间效应),情况发生了变化。随着年龄 的增长,老年人的基础疾病风险 自然比年轻人高。同时,由于退休等原因,老年人群体往往有更多的空闲时间,他们的平均运动时长 也比忙碌的年轻人更长。
这就导致了一个结果:在不同年龄组之间,平均运动时长 和平均疾病风险 呈现出强烈的正向同步变动。因此,第二项 是一个非常大的正数。
当这个巨大的正数(组间虚假相关)加上那个较小的负数(组内真实相关)时,总体的协方差 就变成了正数。从整体数据来看,结论变成了“运动时间越长,患病风险越高”。
我们通过一段Python代码,精确模拟这个全协方差定律的分解过程,并用图形展示辛普森悖论的几何形态。
import numpy as npimport matplotlib.pyplot as pltfrom scipy import statsplt.rcParams['font.sans-serif'] = ['SimHei']plt.rcParams['axes.unicode_minus'] = Falsenp.random.seed(2023)# 模拟三个年龄组的数据# 组1:青年人(基础风险低,运动时间少)n1 = 100x_young = np.random.normal(loc=2, scale=1, size=n1)# 组内真实效应:斜率为 -1.5y_young = -1.5 * x_young + np.random.normal(loc=15, scale=2, size=n1)# 组2:中年人(基础风险中,运动时间中)n2 = 100x_middle = np.random.normal(loc=5, scale=1, size=n2)y_middle = -1.5 * x_middle + np.random.normal(loc=25, scale=2, size=n2)# 组3:老年人(基础风险高,运动时间多)n3 = 100x_old = np.random.normal(loc=8, scale=1, size=n3)y_old = -1.5 * x_old + np.random.normal(loc=35, scale=2, size=n3)# 聚合全体数据x_all = np.concatenate([x_young, x_middle, x_old])y_all = np.concatenate([y_young, y_middle, y_old])# 创建可视化画布fig, ax = plt.subplots(figsize=(10, 7))# 绘制各组散点及组内回归线groups = [ ('青年组', x_young, y_young, '#1f77b4'), ('中年组', x_middle, y_middle, '#ff7f0e'), ('老年组', x_old, y_old, '#2ca02c')]for label, x, y, color in groups: ax.scatter(x, y, color=color, alpha=0.6, label=label, edgecolors='white', s=60) slope, intercept, r_val, _, _ = stats.linregress(x, y) x_fit = np.linspace(min(x), max(x), 10) ax.plot(x_fit, slope * x_fit + intercept, color=color, linewidth=2, label=f'{label}趋势 (r={r_val:.2f})')# 计算并绘制整体数据的回归线slope_all, intercept_all, r_all, _, _ = stats.linregress(x_all, y_all)x_fit_all = np.linspace(min(x_all), max(x_all), 100)ax.plot(x_fit_all, slope_all * x_fit_all + intercept_all, color='black', linestyle='--', linewidth=3, label=f'整体虚假趋势 (r={r_all:.2f})')ax.set_title('辛普森悖论:全协方差定律的几何展现', fontsize=14)ax.set_xlabel('每周运动时长 (X)', fontsize=12)ax.set_ylabel('心血管疾病风险指数 (Y)', fontsize=12)ax.legend(loc='upper left', bbox_to_anchor=(1.02, 1), borderaxespad=0.)ax.grid(True, linestyle=':', alpha=0.6)plt.tight_layout()plt.show()执行结果如下:
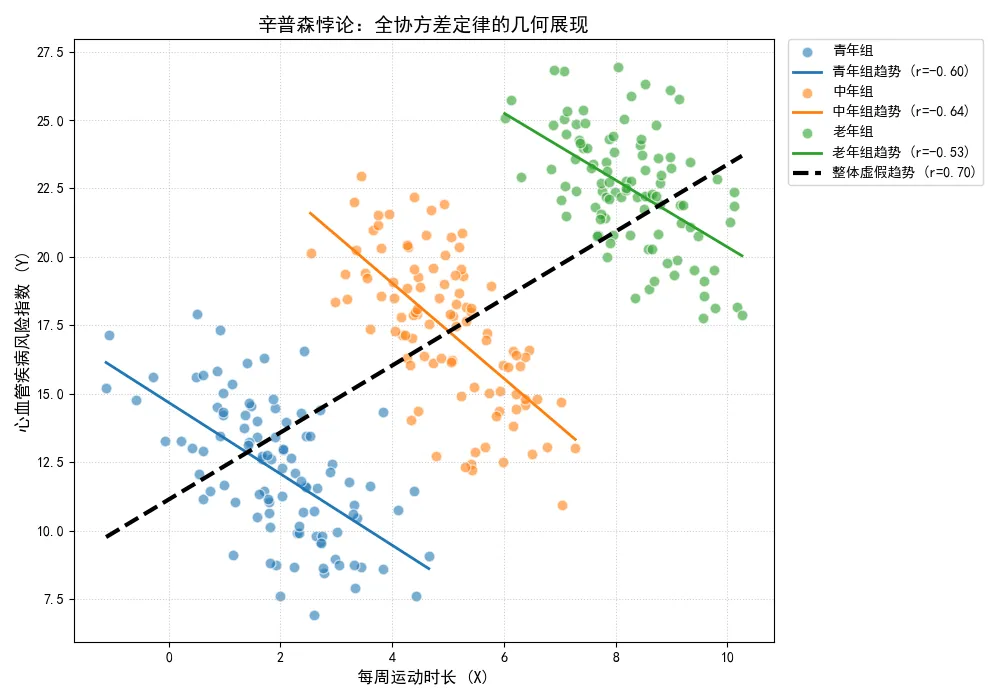
图表清晰地揭示全协方差定律中两股力量的博弈。三条彩色的实线代表组内效应,它们一致向下倾斜,证明了运动的健康益处。然而,这三个群体的质心(均值点)却沿着一条向右上方倾斜的轨迹排列,这就是强大的组间效应。最终,贯穿全局的黑色虚线被组间效应所主导,呈现出荒谬的正相关。
辛普森悖论在业务分析中是一个极其危险的陷阱。它告诫我们,在处理具有异质性(Heterogeneity)或潜在层次结构的数据时,绝对不能盲目地计算全局相关系数。如果不通过分层分析(Stratified Analysis)或引入控制变量来剥离组间均值协方差的干扰,我们得出的结论很可能与事实完全相反。
这自然引出了我们在相关性分析中必须掌握的下一个核心数学工具:当我们怀疑存在潜在变量 时,如何在不进行物理分组的情况下,从连续数据中纯粹地剥离 的影响?这就是偏相关分析(Partial Correlation)要解决的问题。
5偏相关分析:残差空间中的正交投影
在上一部分中,我们通过辛普森悖论和全协方差定律,认识到了潜在变量 在组间均值协方差上制造的巨大扭曲。当 是一个像“年龄段”这样的离散变量时,我们可以通过对数据进行物理分组(分层分析)来观察组内真实的协方差。
但如果潜在变量 是一个连续变量(例如气温、收入水平、血压等),物理分组的方法就失效了。因为连续变量有无限个取值,如果我们强行将其切分成无数个极小的区间,每个区间内的数据量将急剧萎缩,导致组内协方差的估计失去统计学意义。
为了在不进行物理分组的情况下,从连续变量 和 之间纯粹地剥离 的影响,统计学引入了偏相关分析(Partial Correlation Analysis)。偏相关分析的本质,是利用线性回归的残差理论,在多维向量空间中进行正交投影(Orthogonal Projection)。
我们可以把 、 和 看作是多维空间中的三个向量。我们的目标是测量 和 之间纯粹的相关性,也就是剔除掉它们各自在 方向上的投影(即受 影响的部分)之后,剩余部分的相关性。
这个剥离过程可以通过两个独立的线性回归模型来实现。
第一步,我们用 去预测 。建立线性回归方程 。这里的 就是向量 在向量 上的正交投影,它代表了 中完全由 线性决定的那一部分信息。
第二步,我们计算真实观测值 与预测值 之间的差值,得到残差向量 。根据最小二乘法的几何性质,残差向量 必然与预测变量 正交(即内积为0)。这个残差 具有极其重要的物理意义:它代表了 中剔除了 的线性影响之后,剩余的所有独立波动。
第三步,我们对 执行完全相同的操作。用 预测 ,得到 ,然后计算残差向量 。此时, 代表了 中剔除了 的线性影响后的剩余波动。
最后一步,我们计算残差 和残差 之间的皮尔逊相关系数。这个计算结果就是 和 在控制了 之后的偏相关系数,通常记为 。
在实际应用中,我们不需要每次都去拟合两个回归模型并计算残差。统计学提供了一个极其优雅的解析公式,只要我们知道三个变量两两之间的皮尔逊相关系数 、 和 ,就可以直接代入公式求解:
我们可以对这个公式进行代数剖析。观察分子部分 。如果 和 之间观察到的表象相关性 完全是由潜在变量 作为中间桥梁传递过来的(即虚假相关),那么根据路径分析的原理, 和 的乘积将会非常接近 。
当 时,分子趋近于0,最终计算出的偏相关系数 也会趋近于0。这就从代数上完美地解释了虚假相关被剔除的数学机制。
分母部分 则是对残差方差的标准化因子。 代表了 的方差中不能被 解释的比例(即残差方差的比例)。
我们通过Python代码,回到之前冰淇淋销量()与溺水次数()受气温()驱动的虚假相关案例。我们将用代码手动执行残差投影的过程,并与偏相关公式的计算结果进行对比,以验证这一数学手术的精确性。
import numpy as npimport matplotlib.pyplot as pltfrom scipy import statsplt.rcParams['font.sans-serif'] = ['SimHei']plt.rcParams['axes.unicode_minus'] = False# 重新生成受气温(Z)驱动的冰淇淋销量(X)和溺水次数(Y)数据np.random.seed(1024)temperature_Z = np.random.normal(loc=30, scale=4, size=300)ice_cream_X = 2.0 * temperature_Z + np.random.normal(loc=0, scale=3, size=300)drowning_Y = 0.5 * temperature_Z + np.random.normal(loc=0, scale=1.5, size=300)# 计算两两之间的皮尔逊相关系数r_xy, _ = stats.pearsonr(ice_cream_X, drowning_Y)r_xz, _ = stats.pearsonr(ice_cream_X, temperature_Z)r_yz, _ = stats.pearsonr(drowning_Y, temperature_Z)# 1. 使用解析公式计算偏相关系数numerator = r_xy - (r_xz * r_yz)denominator = np.sqrt(1 - r_xz**2) * np.sqrt(1 - r_yz**2)partial_corr_formula = numerator / denominator# 2. 手动执行残差投影过程# 用 Z 预测 X 并求残差 e_X|Zslope_xz, intercept_xz, _, _, _ = stats.linregress(temperature_Z, ice_cream_X)pred_x = slope_xz * temperature_Z + intercept_xzresidual_x = ice_cream_X - pred_x# 用 Z 预测 Y 并求残差 e_Y|Zslope_yz, intercept_yz, _, _, _ = stats.linregress(temperature_Z, drowning_Y)pred_y = slope_yz * temperature_Z + intercept_yzresidual_y = drowning_Y - pred_y# 计算两个残差之间的皮尔逊相关系数partial_corr_residual, _ = stats.pearsonr(residual_x, residual_y)# 打印对比结果print(f"表象皮尔逊相关系数 r_XY: {r_xy:.4f}")print(f"公式计算的偏相关系数 r_XY|Z: {partial_corr_formula:.4f}")print(f"残差计算的偏相关系数 r_eX_eY: {partial_corr_residual:.4f}")# 绘制残差散点图以直观展示剥离效果fig, ax = plt.subplots(figsize=(8, 6))ax.scatter(residual_x, residual_y, alpha=0.6, color='#984ea3', edgecolors='white', s=50)# 拟合残差的回归线slope_res, intercept_res, _, _, _ = stats.linregress(residual_x, residual_y)x_line = np.linspace(min(residual_x), max(residual_x), 100)ax.plot(x_line, slope_res * x_line + intercept_res, color='black', linestyle='--', linewidth=2)ax.set_title(f'残差空间中的正交投影\n(剥离气温影响后的纯粹关系 r = {partial_corr_residual:.4f})', fontsize=14)ax.set_xlabel('冰淇淋销量残差 $e_{X|Z}$', fontsize=12)ax.set_ylabel('溺水次数残差 $e_{Y|Z}$', fontsize=12)# 添加过原点的十字基准线ax.axhline(0, color='gray', linewidth=1, linestyle=':')ax.axvline(0, color='gray', linewidth=1, linestyle=':')ax.grid(True, linestyle=':', alpha=0.6)plt.tight_layout()plt.show()执行结果如下:
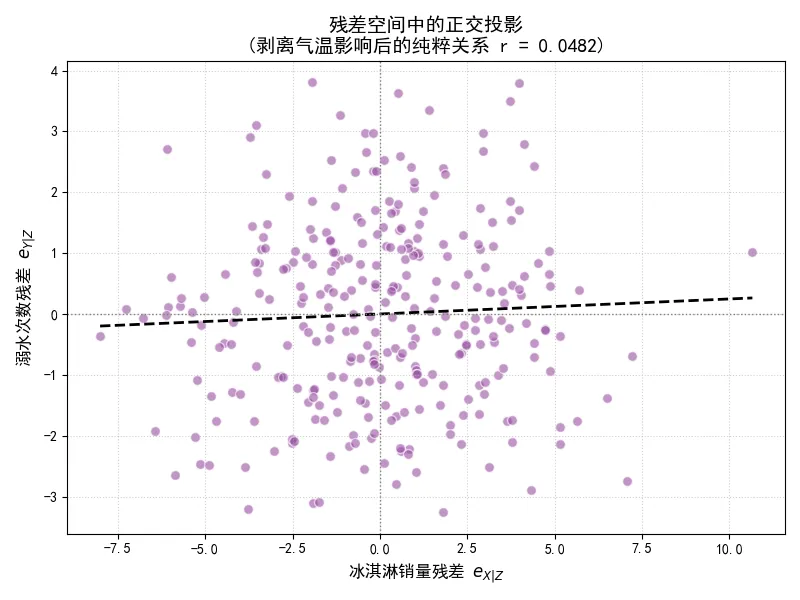
原本高达0.8左右的表象相关系数,在经过偏相关公式或残差计算后,骤降至接近0的水平(通常在0.05以内,取决于随机噪声)。散点图也显示,两个变量的残差在二维平面上呈现出完全随机的云团状分布,没有任何线性趋势。
偏相关分析为我们提供了一把锋利的数学手术刀,能够精准切除连续混淆变量带来的统计噪音。在多变量时间序列分析、基因表达网络构建等复杂场景中,偏相关矩阵往往比原始的相关矩阵更能反映变量之间真实的底层拓扑结构。
6样本量膨胀对统计显著性的绑架
在探讨了数据形态的欺骗性、非线性盲区以及潜在变量的干扰之后,我们来到了相关性分析中最后一个极具迷惑性的陷阱。这个陷阱潜伏在统计假设检验的底层逻辑中,尤其在当今的大数据时代,它正以前所未有的规模误导着大量的数据科学家。这就是样本量膨胀与统计显著性(p值)之间的错位幻觉。
当我们计算出两个变量之间的相关系数 后,通常会进行显著性检验,以判断这个 值是否仅仅是由于随机抽样误差造成的。在皮尔逊相关系数的检验中,原假设 通常设定为总体的相关系数 。
为了检验这个假设,我们构造一个服从自由度为 的 t 分布的检验统计量。假设样本量为 ,计算出的样本相关系数为 ,那么 t 统计量的计算公式如下:
我们可以对这个公式进行简单的代数变形,将其写成两个因子的乘积形式:
仔细观察这个变形后的公式。t 统计量的大小决定了 p 值的大小(t 的绝对值越大,p 值越小,结果越显著)。而 t 统计量由两部分决定: 第一部分是效应量(Effect Size),也就是相关系数本身的大小,它代表了变量间关联的真实强度。 第二部分是 ,这是一个主要由样本量 主导的放大因子。
当样本量 趋近于无穷大时,即使相关系数 极其微小(比如只有0.01,在业务上几乎毫无意义),放大因子 也会变成一个天文数字。这两个数字相乘,依然会得到一个巨大的 t 值,从而计算出一个无限趋近于0的 p 值。
这就导致了一个极其荒谬但又在数学上绝对成立的现象:在海量数据面前,任何微不足道的微弱联系,都会被 p 值放大为具有极高统计显著性的铁证。
反过来,如果我们的样本量非常小(比如只有10个样本),即使两个变量之间存在着高达0.6的强相关性,由于放大因子太小,最终的 t 值可能依然无法跨越显著性的门槛(通常是 p < 0.05)。此时,机器会冷冰冰地告诉你:结果不显著,拒绝承认相关性。
为了直观地展示这种样本量对显著性的绑架,我们编写一段Python代码。我们将模拟两个极端的场景:一个是样本量极小但相关性很强的数据集,另一个是样本量巨大但几乎毫无相关性的数据集。
import numpy as npimport matplotlib.pyplot as pltfrom scipy import statsplt.rcParams['font.sans-serif'] = ['SimHei']plt.rcParams['axes.unicode_minus'] = False# 设置随机种子np.random.seed(2024)# 场景 A:小样本,强相关# 仅抽取 12 个样本,设定真实的线性关系加上一定的噪声n_small = 12x_small = np.random.uniform(0, 10, n_small)y_small = 0.8 * x_small + np.random.normal(0, 2.5, n_small)# 计算相关系数和 p 值r_small, p_small = stats.pearsonr(x_small, y_small)# 场景 B:超大样本,极微弱相关(几乎是纯噪声)# 抽取 10000 个样本,设定极其微弱的线性关系加上巨大的噪声n_large = 10000x_large = np.random.uniform(0, 10, n_large)# 这里的斜率仅为 0.02,几乎被方差为 5 的正态噪声完全淹没y_large = 0.02 * x_large + np.random.normal(0, 5, n_large)# 计算相关系数和 p 值r_large, p_large = stats.pearsonr(x_large, y_large)# 绘制对比图表fig, (ax1, ax2) = plt.subplots(1, 2, figsize=(14, 6))# 绘制场景 A 的散点图ax1.scatter(x_small, y_small, color='#377eb8', s=80, edgecolors='white', alpha=0.9)slope_s, intercept_s, _, _, _ = stats.linregress(x_small, y_small)x_fit_s = np.linspace(min(x_small), max(x_small), 100)ax1.plot(x_fit_s, slope_s * x_fit_s + intercept_s, color='black', linestyle='--', linewidth=2)ax1.set_title(f'场景 A: 小样本强相关\n样本量 N = {n_small}\nPearson r = {r_small:.3f}\np 值 = {p_small:.4f}', fontsize=13)ax1.set_xlabel('X')ax1.set_ylabel('Y')ax1.grid(True, linestyle=':', alpha=0.6)# 绘制场景 B 的散点图# 由于数据量太大,使用极小的点和低透明度来展示密度ax2.scatter(x_large, y_large, color='#e41a1c', s=2, alpha=0.15)slope_l, intercept_l, _, _, _ = stats.linregress(x_large, y_large)x_fit_l = np.linspace(min(x_large), max(x_large), 100)ax2.plot(x_fit_l, slope_l * x_fit_l + intercept_l, color='black', linestyle='-', linewidth=2)ax2.set_title(f'场景 B: 大样本微弱相关\n样本量 N = {n_large}\nPearson r = {r_large:.3f}\np 值 = {p_large:.4e}', fontsize=13)ax2.set_xlabel('X')ax2.set_ylabel('Y')ax2.grid(True, linestyle=':', alpha=0.6)# 添加判断结论的文本框if p_small > 0.05: text_s = "统计结论:p > 0.05\n不显著 (拒绝承认相关)"else: text_s = "统计结论:p <= 0.05\n显著"ax1.text(0.05, 0.85, text_s, transform=ax1.transAxes, fontsize=12, bbox=dict(facecolor='white', alpha=0.9, edgecolor='gray'))if p_large < 0.05: text_l = "统计结论:p < 0.05\n极度显著 (机器认为存在强关联)"else: text_l = "统计结论:p >= 0.05\n不显著"ax2.text(0.05, 0.85, text_l, transform=ax2.transAxes, fontsize=12, bbox=dict(facecolor='white', alpha=0.9, edgecolor='gray'))plt.tight_layout()plt.show()执行结果如下:
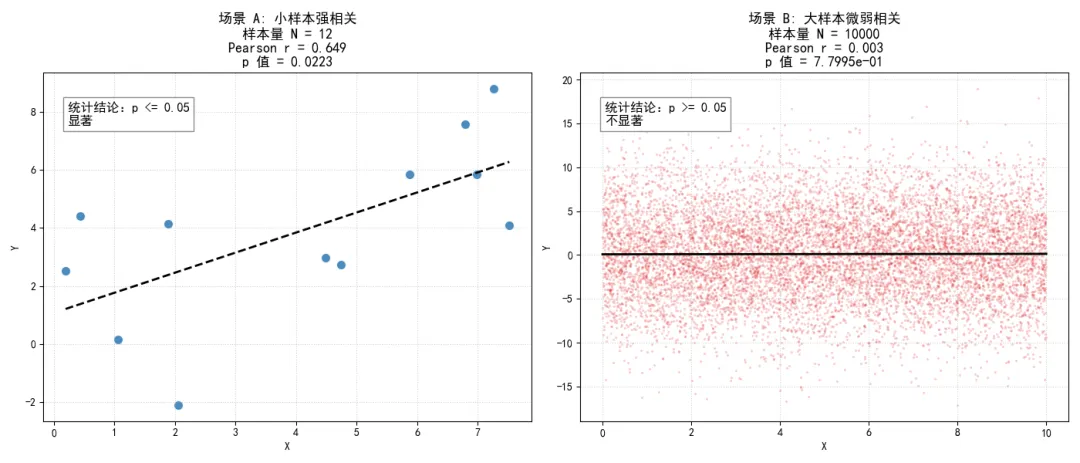
左侧的图表中,数据点清晰地围绕着一条上升的直线排列,肉眼可见的强相关趋势,计算出的相关系数高达0.5以上。但由于样本量只有12个,p值大于了0.05。按照刻板的统计学标准,我们必须得出结论:这两个变量不相关。
右侧的图表则完全是一团混乱的散点云。变量 对 的解释力微乎其微,相关系数只有0.02左右。但因为样本量高达一万,p值竟然达到了惊人的 甚至更低级别。自动化特征筛选算法会兴奋地向你报告:发现了一个极度显著的特征。
在现代互联网企业和金融量化分析中,我们动辄处理百万级甚至亿级的数据。在这种数据规模下,几乎任何两个随机变量之间都能算出显著的p值。如果不理解公式底层的放大机制,盲目迷信统计显著性,分析师就会在海量数据中挖掘出无数毫无业务价值的微弱关联,最终导致预测模型的过拟合和崩溃。
本节总结
通过对安斯库姆四重奏、零相关的代数陷阱、虚假相关与潜在变量、辛普森悖论的全协方差分解,以及样本量对显著性的绑架的深度剖析,我们已经彻底粉碎了将相关性等同于一个简单数值的幼稚观念。
相关性分析绝不是调用一个Python函数并打印出一个浮点数那么简单。它是一项需要融合几何直觉、代数推导、业务洞察以及严谨逻辑的系统工程。在结束这第一节的探讨之际,我们需要为后续的深入学习建立一套正确审视相关性的分析框架:
几何直觉优先于数值计算:任何数据分析任务的起点,都应该是对数据联合分布形态的视觉探索。散点图、二维核密度估计图等可视化工具,能够在一瞬间暴露出异常值、非线性拓扑结构以及数据的聚类特征。 警惕高维空间中的幽灵变量:当我们在二维平面上观察到两个变量高度同步时,必须强迫自己跳出当前的维度,思考是否存在未被观测到的混淆变量。运用偏相关分析、分层回归等数学手术刀,是逼近事物真实联系的必经之路。 区分统计显著性与业务实际意义:在评估相关性时,必须将样本量纳入考量体系。一个具有极小p值但相关系数仅为0.05的结果,在真实的工程实践中往往毫无用处。我们需要关注的是效应量的大小,以及这种相关性是否能够转化为实际的预测能力。
随机文章
-
 10个月宝宝每天需要喝多少奶粉?
10个月宝宝每天需要喝多少奶粉?
- 企业级Linux系统auditd安全审计配置与自动化分析
- Linux快速入门系列课(2)
- 45个高效Linux命令组合
- 融合DeepSeek、GIS 与 Python 机器学习的全流程地质灾害风险评估、易发性分析、信息化建库、灾后重建及SCI论文成果撰写
- Trame:一个用Python轻松构建炫酷Web应用的强大框架
- Python题库完整版350道题,刷完轻松上90+
- 嵌入式Linux必备Modbus驱动库—libmodbus的使用
- 4个月干掉React、碾压Linux:这个AI项目是怎么冲上GitHub第一的
- Linux上优雅调试OpenClaw:告别终端切换的三种方案
- DuckDB + Python 数据科学工作流
