Linux 系统调用深度解析:read() 这一行代码,CPU 到底做了什么?
- 2026-07-04 05:07:17
作者:小康,C/C++编程博主
关键词:系统调用、syscall、用户态、内核态、陷入内核、vDSO、特权级
前言
你每天都在写这样的代码:
int fd = open("config.json", O_RDONLY);read(fd, buf, size);write(1, buf, size);三行代码,三个函数调用。但这三次调用和普通函数调用有一个根本区别——它们会让 CPU 从"用户态"切换到"内核态",经历一次代价不小的特权级切换,再切回来。
这个过程叫系统调用(System Call)。
理解它,你才能真正理解:为什么高性能程序要减少系统调用次数、vDSO 为什么能加速、io_uring 为什么比 epoll 快。
一、用户态 vs 内核态:CPU 的两个"特权等级"
现代 CPU(x86)有 4 个特权等级(Ring 0 ~ Ring 3)。Linux 只用了两个:
Ring 0(内核态):可以执行任何指令,访问所有硬件,操作物理内存 Ring 3(用户态):受限模式,不能直接操作硬件,不能访问内核内存
你写的 C/C++ 程序运行在 Ring 3。内核运行在 Ring 0。
这个隔离是系统稳定性的基础——用户程序崩溃,不会把整个内核拖下水。
但用户程序要读文件、发网络包、创建进程,这些都需要操作硬件,必须让内核帮忙。怎么让内核帮忙?通过系统调用——一种受控的、从 Ring 3 进入 Ring 0 的机制。

这道红线是系统中最重要的边界之一。用户态代码无法直接跨越它——必须通过 syscall 指令,以受控的方式请求内核帮忙。
二、系统调用的完整路径:CPU 做了什么?
当你调用 read(fd, buf, size) 时,实际发生了以下步骤:
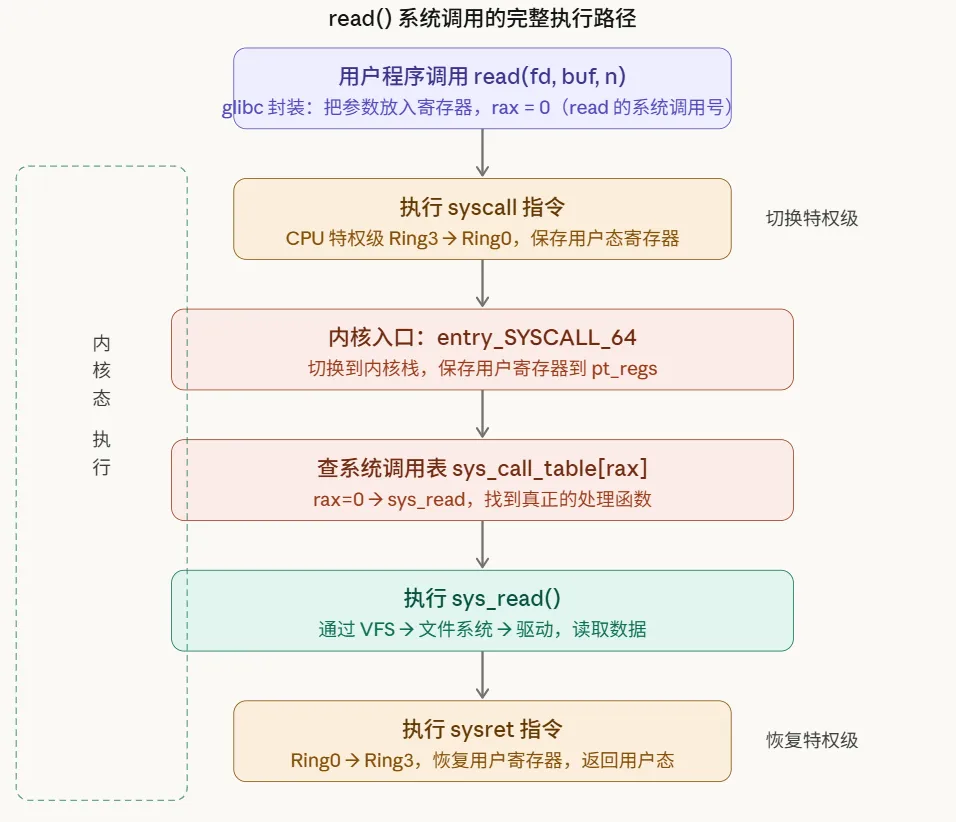
整个过程的关键细节:
寄存器约定(x86-64):
rax:系统调用号(read= 0,write= 1,open= 2,close= 3…)rdi、rsi、rdx、r10、r8、r9:前六个参数rax返回值:系统调用的返回值(负数表示错误码)
syscall 指令到底做了什么:
保存当前 rip(指令指针)和rflags到 CPU 特定寄存器(MSR)将 cs(代码段)切换为内核代码段,特权级变为 Ring 0跳转到 MSR_LSTAR寄存器里存的地址(即entry_SYSCALL_64)
这一切发生在 CPU 硬件层面,比软件中断(老的 int 0x80)快得多。
三、系统调用号:内核的"菜单"
内核里有一张大表——sys_call_table[],存放所有系统调用对应的处理函数地址。rax 就是这张表的下标。
# 查看 Linux 系统调用表$ cat /usr/include/x86_64-linux-gnu/asm/unistd_64.h | head -20#define __NR_read 0 ← read() 对应 0 号#define __NR_write 1 ← write() 对应 1 号#define __NR_open 2#define __NR_close 3#define __NR_stat 4...# x86-64 Linux 共有约 400+ 个系统调用# 用 strace 实时观察程序发出的系统调用$ strace ./a.outexecve("./a.out", ...) = 0openat(AT_FDCWD, "config.json", O_RDONLY) = 3read(3, "hello", 5) = 5write(1, "hello", 5) = 5close(3) = 0strace 本质上是利用 ptrace 系统调用拦截目标进程的每一次系统调用,打印调用名称、参数和返回值。是调试的利器。
四、系统调用的真实开销
每次系统调用并不是"免费"的。它会带来:
特权级切换:CPU 寄存器保存/恢复,上下文切换的一部分 内核栈切换:从用户栈切换到内核栈 TLB 刷新(部分场景):内核和用户地址空间隔离带来的代价(Meltdown 漏洞补丁后开销更大) 缓存污染:进入内核后 L1/L2 缓存的用户数据可能被替换
一次系统调用的开销大约在 100ns ~ 1μs 之间,对高性能场景来说不可忽视。
这正是高性能程序设计的一个核心原则:减少系统调用次数。
// 差:每次写一个字节,N次系统调用for (int i = 0; i < 1000; i++) write(fd, &buf[i], 1); // 1000 次 write()// 好:批量写,1次系统调用write(fd, buf, 1000); // 1 次 write()stdio 的 fwrite 在用户态做了缓冲,就是为了减少真正的 write() 系统调用次数。
五、vDSO:不进内核的"系统调用"
有些系统调用非常频繁,但实际上不需要操作硬件——比如 gettimeofday(),只是读一下系统时钟。如果每次都走完整的系统调用路径,太浪费了。
Linux 引入了 vDSO(Virtual Dynamic Shared Object) 来解决这个问题。
vDSO 是内核在每个进程的地址空间里映射的一小块内存,里面包含几个特殊的"内核函数"的用户态实现:
$ cat /proc/self/maps | grep vdso7ffd8a7fd000-7ffd8a7ff000 r-xp 00000000 00:00 0 [vdso]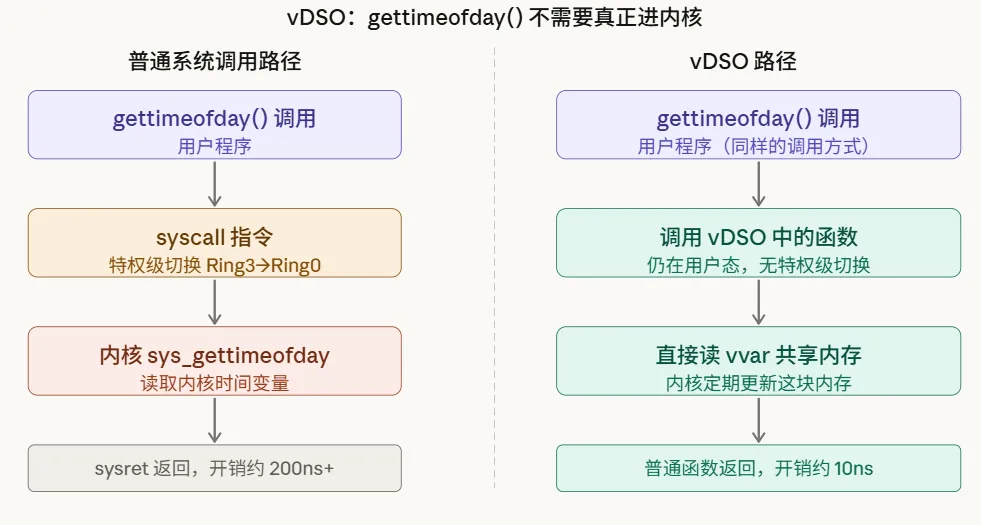
vDSO 的工作方式:
内核在一块共享内存( vvar)里定期更新时钟值vDSO 里的 gettimeofday实现直接从这块内存读取,不需要syscall指令对用户程序完全透明,调用方式不变,但快了 20 倍以上
受 vDSO 加速的主要函数:gettimeofday()、clock_gettime()、time()、getcpu()。
六、系统调用 vs 函数调用:差了多少?
普通函数调用:~1ns(几个 CPU 周期)vDSO 函数调用:~10ns(读共享内存)系统调用:~100~300ns(特权级切换 + 内核处理)有 Page Table 隔离(PTI,Meltdown 漏洞补丁)的系统调用:~500ns+实际验证:
#include<time.h>#include<stdio.h>intmain(){structtimespect;// 高频调用 clock_gettime,测量系统调用开销for (int i = 0; i < 10000000; i++) clock_gettime(CLOCK_MONOTONIC, &t);// 因为 vDSO,这里其实没有真正的系统调用}$ strace -c ./a.out% time seconds usecs/call calls errors syscall------ ----------- ----------- --------- --------- -------- 0.00 0.000000 0 1 read ...# clock_gettime 不在这里!因为走了 vDSO,strace 看不到七、从系统调用理解高性能设计
理解系统调用开销,才能理解高性能框架的设计选择:
为什么 stdio 的 fwrite 比 write 快(批量写)?fwrite 在用户态缓冲数据,积累到 4096 字节才真正调用 write(),把 N 次系统调用压缩成 1 次。
为什么io_uring 比 epoll 快?**epoll 每个事件需要独立的 read()/write() 系统调用;io_uring 用共享内存环形队列批量提交 I/O 请求,大幅减少系统调用次数,甚至可以做到 0 系统调用。
为什么 Redis 单线程还这么快? Redis 核心操作都是内存操作,不需要系统调用。网络 I/O 用 epoll,一次 epoll_wait 处理大量事件,系统调用次数极少。
八、高频面试题精析
Q:用户态和内核态的根本区别是什么?
CPU 特权等级不同。用户态(Ring 3)不能直接访问硬件和内核内存;内核态(Ring 0)可以执行所有指令、访问所有硬件。两者通过系统调用(syscall 指令)安全切换,是操作系统稳定性的基础保障。
Q:系统调用和函数调用有什么区别?
普通函数调用:跳转到同一特权级的另一个地址,保存/恢复几个寄存器,1ns 级别。系统调用:必须通过 syscall 指令切换特权级,保存大量寄存器状态,切换栈,进入内核处理,再切换回来,100ns+ 级别。本质区别是有没有特权级切换。
Q:int 0x80 和 syscall 指令有什么区别?
int 0x80 是老方式(x86 32位),用软件中断实现系统调用,需要查中断描述符表(IDT),开销更大。syscall 是 x86-64 专用的快速系统调用指令,CPU 直接从 MSR 寄存器读取内核入口地址,省去了 IDT 查找,快约 50%。现代 Linux 64 位程序都用 syscall。
Q:为什么 gettimeofday 这么快?
因为 glibc 会自动使用 vDSO 实现,完全不走 syscall 指令,在用户态直接读内核映射的共享时钟变量,耗时约 10ns vs 普通系统调用的 200ns+。
结语
系统调用是操作系统与用户程序之间唯一的受控边界。
理解了它,你就理解了:为什么 CPU 有特权等级、为什么减少系统调用是性能优化的第一原则、为什么 vDSO 能让时间函数飞速运行、为什么 io_uring 是下一代 I/O 的方向。
它是贯穿整个 Linux 系统编程系列的隐形主角——每一篇文章里出现的 read()、write()、mmap()、epoll_wait(),都是一次跨越特权边界的旅程。
觉得有收获,点赞、推荐、转发 支持下哦~ 🙏
📌 还在打基础?从这里出发
如果你读完这篇还觉得 C、C++、Linux 有些陌生,别急:
C 语言快速入门 :大一啃完谭浩强的书,还是不会写代码?我花1个月做了套'12天速成'的C语言课 C++ 快速入门 :12天,从C++小白到独立做项目!我把3年踩坑经验浓缩成了这门课 Linux 编程快速入门 :为什么你学了半年 Linux 编程,还是写不出一个像样的程序?
感兴趣可以了解一下。
🚀 基础扎实了?来做工业级项目
如果你已经有一定基础,想冲击更高的天花板,这些工业级 C++ 项目正是为你准备的:
| 线程池 | |
| 高性能日志库 MiniSpdlog | |
| 高性能内存池 | |
| 多线程下载工具 | |
| MySQL 连接池 | |
| 内存泄漏检测器 | |
| ReactorX | |
| 无锁栈 | |
| 工业级智能指针(shared_ptr) | |
| 高性能网络库 NetCore | |
| 高性能异步日志库 ZephyrLog | |
| 死锁检测工具 | |
| 高性能 HTTP 服务器 | |
| 协程库 CoroForge | |
| 高性能 HTTP 压测工具 | |
| Redis 核心模块实战 |
每个项目都是真实可用的工程代码,不是教学玩具。
详情点击 C++ 项目合集课程链接:为什么同样是"学过C++",有人面试碾压,有人开口就怂?差距在这18个C++硬核项目
对C++项目实战课程感兴趣的朋友,可以扫下方二维码添加小康微信(或微信搜索:jkfwdkf ) 备注「 项目实战 」

随机文章
-
 10个月宝宝每天需要喝多少奶粉?
10个月宝宝每天需要喝多少奶粉?
- linux设备驱动 -- RK3568 led驱动 (led子系统&设备树)
- Linux sed命令超详细教程:从入门到封神,全实战无废话
- Python 库 litellm 供应链投毒事件研究报告
- Python:图解 NumPy
- Python 实战项目合集|自动记账小程序(可视化 + 数据统计,新手 1 小时搞定)
- 22python(计算两数之和)
- 你还在为scratch、python学员没有比赛出口
- 学知识图谱,你得会Python!史上最通俗易懂系列(六)
- 教学灵感小记:Python Turtle 3 道趣味易错题,随手记的小干货
- 告别一次性动作:我在 Python 的循环里,看见时间开始累积
