第一章:问题建模——大页分配失败的真实约束
1.1 高阶分配的数学约束与物理连续性
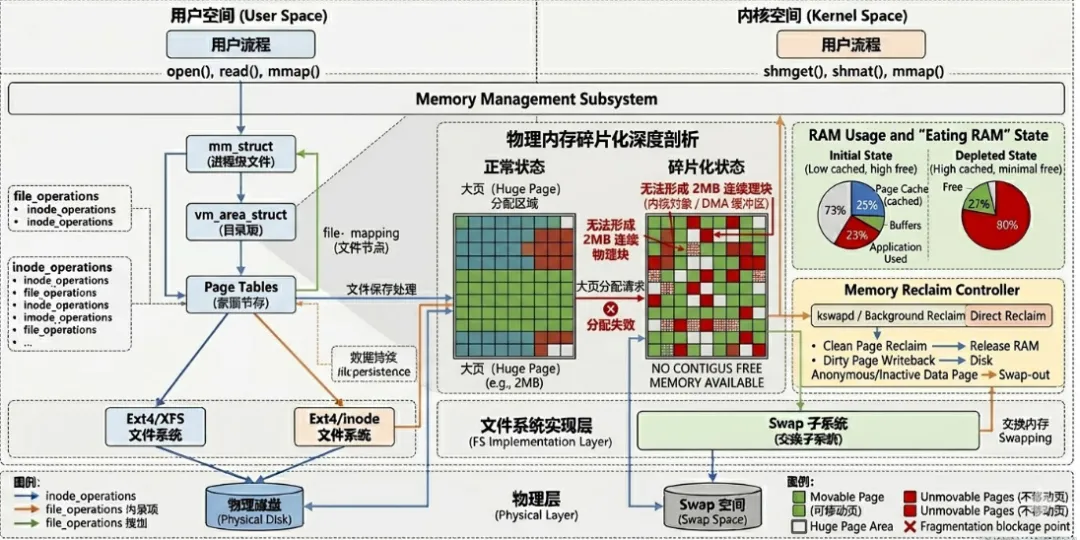
Linux 内存管理中的大页(HugeTLB 或 THP)核心需求是连续物理页,其本质并非“需要更多内存”,而是对系统中可连续 PFN 区间的强依赖。以 2MB THP 为例,Linux 内核会尝试 alloc_pages(order=9),要求 2^9 = 512 个连续 page frame。这里“连续”是物理地址连续,而不是虚拟地址连续,这是由硬件 MMU 和 TLB 映射方式决定的。TLB 映射条目直接覆盖连续物理页,如果连续性中断,则无法建立单条大页映射。对于 CPU 和 DMA 访问来说,连续性要求是硬性约束,一旦无法满足,分配必然失败。
数学上,可以把物理页视为离散集合 P = {p0, p1, …, pN},需要寻找长度 L = 2^order 的子集连续区间 [pi, pi+L-1]。随着系统长期运行,小页频繁分配和释放行为会随机打散这些区间,使大块连续区间概率呈指数下降。即便总空闲页数远超所需,最大连续块可能仍不足以满足高阶分配需求,这就是为什么我们常看到“内存足够但大页分配失败”的现象。
进一步从伙伴系统看,Linux 使用 free_area[order] 数组管理不同阶空闲页列表。当请求 order=N 时,系统优先从 free_area[N] 分配;若无,则向上查找更大阶并拆分(split)。拆分操作是不可逆的:高阶块被拆分后,其子块被不同分配路径占用,释放时间不同,merge 条件无法满足,从而高阶块难以恢复。长期运行下,高阶连续块呈单调下降趋势。可以理解为,大页连续性是一种随系统使用而不断消耗的稀缺结构资源,而非简单的容量问题。
理论上,系统可以通过 compaction 或隔离内存区(CMA)恢复高阶块,但实际效果受限于迁移类型、页锁、不可迁移页数量以及 NUMA 约束等因素。因此大页分配失败是系统运行的必然结果,而非偶发事件。
1.2 “内存充足但分配失败”的本质解释
在实际生产系统中,往往可以看到 free -m 显示大量空闲页,但 THP 分配仍失败。这里的关键是空闲页统计粒度与高阶分配需求不匹配。Linux 的 free memory 是按 order-0 页统计,而高阶分配需要物理连续块。公式化:
Total Free Pages ≥ 2^order∧ Max Contiguous Block < 2^order→ Allocation Fail
第二个条件才是关键。即使总空闲页数充足,只要最大连续块不足,就会分配失败。释放页本身不能自然恢复高阶块,因为释放页往往会被小粒度分配再次占用,形成“拆分 → 随机释放 → 再拆分”的循环。可以将其理解为一种熵增过程:系统从低熵状态(连续块)向高熵状态(碎片化)演化,除非有专门机制,否则连续块不会自发恢复。
进一步分析,从概率模型和系统演化角度看,这种现象具有高度确定性。随着时间增长,高阶块的可用性呈指数下降,碎片累积不可逆。即便在 low-load 环境中运行,也会逐渐出现连续块不足问题。换句话说,大页分配失败的根源是结构性碎片化,而非单纯的容量耗尽。系统设计者需要考虑到这一点,才能理解为何透明大页(THP)在高负载或长期运行环境中分配失败频率较高。
第二章:碎片的产生机制——从分配行为到结构退化
2.1 高频小对象分配的破坏性拆分
Linux 内核的绝大多数分配路径最终都退化为 order-0 页,例如 slab/slub 分配(kmalloc)、页缓存(page cache)、网络 buffer(skb)以及匿名页缺页处理。它们具有三个共同特征:高频率、小粒度、生命周期不可预测。当高阶块(例如 order-9)被拆分以满足这些请求时,其内部页会被分配给完全不同的子系统,每页的访问模式和生命周期可能完全不同。拆分后的块形成的碎片不会立即合并,导致原始高阶块结构被打散。
从统计模型看,这类似“随机占用模型”:随着分配次数增加,原本连续的区间会被随机点占据,连续空间快速缩小。释放页往往是离散的,周期长短不一,碎片化区间不会自发形成大块连续空间。长期运行下,碎片化是一种必然的稳态,而不是偶发事件。可以说,高阶页的连续性是系统运行时间的函数,随着时间推移呈现单调下降趋势。
此外,碎片产生的破坏性还源于伙伴系统的 split 操作不可逆。一旦高阶块被拆分成更低阶子块,子块被不同分配路径占用,释放时间不同,merge 条件难以满足。即使空闲页存在,也可能因为分布在不同 pageblock 或 migratetype 中而无法合并回原始高阶块,从而形成长期不可用的碎片。
2.2 生命周期不对齐导致的合并阻断
伙伴系统 merge 机制要求两个 buddy 块必须同时空闲、同阶、同迁移类型。现实中,不同子系统页的释放时间差异巨大,例如 slab 对象长期驻留,页缓存根据访问模式频繁变化,匿名页依赖进程行为,生命周期不一致。当这些页混杂于同一高阶块内时,释放事件几乎不可能同时发生,merge 条件长期无法满足。
即便部分页释放,其 buddy 块仍被占用,阻止整个高阶块恢复。释放后的页很快可能被新的小粒度分配占用,进一步加剧碎片化。这种生命周期去同步(lifecycle desynchronization)使大量潜在可合并的块长期不可用,形成系统级碎片。碎片的形成不是偶然,而是高频分配、低阶拆分和生命周期不对齐的系统行为的必然结果。
第三章:迁移类型(migratetype)——碎片的逻辑隔离层
3.1 pageblock 与迁移类型划分机制
Linux 为了降低碎片化影响,将内存划分为 pageblock(通常 2MB,对齐 THP),每个 pageblock 分配一个 migratetype,用于逻辑隔离不同生命周期的页。主要类型包括:
MIGRATE_MOVABLE:可迁移页(匿名页、页缓存)
MIGRATE_UNMOVABLE:不可迁移页(内核静态对象)
MIGRATE_RECLAIMABLE:可回收页(slab cache)
MIGRATE_CMA:连续内存保留区域
通过这种划分,内核可以在回收或 compaction 时针对可迁移页重组连续空间,避免不可迁移页阻塞高阶块恢复。pageblock 与 migratetype 的结合形成了碎片管理的第一道逻辑屏障。
3.2 fallback:隔离失效的根源
当某 migratetype 空闲页不足时,系统允许跨类型 fallback,例如 MOVABLE 可以从 UNMOVABLE 借用。这种操作在短期缓解分配压力时有效,但会破坏 pageblock 的逻辑隔离,导致未来 compaction 受阻。长期运行中,这种混杂不可逆,使 pageblock 退化为 MIXED 类型,高阶连续块恢复概率大幅下降。
迁移类型的污染效应在系统运行一段时间后显现:即便 LRU 或 compaction 回收了部分页,也无法生成完整高阶块,因为 pageblock 内混入不可迁移页,形成物理连续性的障碍。系统级碎片化因此具有结构性和长期性。
第四章:LRU 回收机制——为什么回收无法解决碎片
4.1 LRU 的目标:回收容量而非连续性
Linux 的 LRU 回收机制通过 active/inactive list 管理冷页,目标是释放长期未访问的页,提高内存可用性。LRU 只关心单页是否可回收,而不考虑 PFN 空间连续性。回收后通常生成零散 order-0 页,无法提供高阶分配所需的连续块。即使系统回收了数 GB 内存,高阶页分配仍可能失败。
LRU 回收的调度策略基于访问频率而非物理布局,例如 page aging 算法。其优化方向是最大化缓存命中率和降低内存压力,而不是保证高阶页连续性。这意味着碎片化无法通过传统回收自然修复。
4.2 回收与碎片的错位优化
回收机制和高阶分配需求目标错位。LRU 回收优化的是容量,减少内存压力,而大页分配依赖连续 PFN 区间。两者的目标函数完全不同,即使回收产生大量空闲页,也无法形成连续块。释放的页可能立即被小粒度分配占用,形成“回收-再打碎”循环,碎片长期存在且不可逆。理论上,只有结合 compaction 或隔离内存机制,才能在 LRU 回收基础上恢复连续空间。
第五章:内存规整(compaction)——理论解法与现实失败
5.1 compaction 的基本算法
内核 compaction 通过迁移可迁移页来形成连续空闲块,主要步骤:
free scanner 找到空闲页,建立空洞列表
migrate scanner 找到可迁移页
将可迁移页搬移到空闲区域
形成连续高阶块
该算法类似双指针压缩操作,可在理论上恢复连续块,但其有效性受迁移页可用性、不可迁移页分布和 pageblock 污染影响。
5.2 compaction 失败的根本原因
在实际系统中,compaction 常失败,原因包括:
pageblock 内不可迁移页阻塞
迁移成本高(拷贝 + TLB flush)
page lock 竞争严重
写回页(writeback)无法立即迁移
特别是 UNMOVABLE 页存在时,block 成为障碍,阻止形成高阶连续块。即使可迁移页被成功移动,仍可能被新分配破坏。实际中,compaction 仅能缓解碎片,不能根治系统结构性碎片化。
第六章:THP 分配路径——失败的真实调用链
6.1 fault path:直接分配
当进程访问缺页时,THP 尝试:
do_huge_pmd_anonymous_page() → alloc_pages(order=9)
如果分配失败,系统会 fallback 为 4KB 页。这条路径最直接体现高阶块不可用的现象,也是生产环境中最常见的失败模式。
6.2 khugepaged:后台合并线程
khugepaged 扫描匿名页尝试合并:
scan → isolate → compact → collapse
成功率依赖于连续可迁移页的存在。如果 pageblock 内不可迁移页过多,合并失败。khugepaged 本质依赖 compaction,而不是独立解决方案,高阶块恢复概率仍受系统碎片结构限制。
第七章:NUMA 与局部性——更隐蔽的失败来源
7.1 NUMA node 限制
Linux 高阶分配通常在本地 NUMA node 内完成:
alloc_pages_node(nid, order)
即便其他节点有足够空闲页,本地 node 碎片严重也会导致失败。NUMA 保证本地访问速度,但增加高阶页连续块缺失的风险。
7.2 zonelist fallback 的副作用
当 local node 分配失败时,系统尝试跨节点 fallback。虽然可以缓解分配压力,但增加访问延迟、破坏局部性,同时在远端节点可能引入碎片扩散,使整个系统高阶块恢复难度加大。
第八章:CMA 与隔离内存——为什么它能成功
8.1 CMA 的设计思想
CMA(Contiguous Memory Allocator)通过预留连续物理内存并仅允许 MOVABLE 页使用,保证该区域连续性。CMA 分配可以通过 dma_alloc_coherent() 或 migratetype 请求连续块,避免碎片破坏高阶连续性。
8.2 与普通内存的本质区别
普通内存没有隔离,易被不同生命周期页污染,连续性难恢复。CMA 区域隔离严格,可迁移页集中,形成高概率连续块。实践中,CMA 可保证驱动或特定大页分配成功,是解决碎片化最直接、有效的方法。
第九章:总结——一个不可逆系统的演化结果
9.1 因果链闭环
大页分配失败完整因果链:
小页高频分配 → 高阶拆分 → 生命周期不一致→ migratetype 污染 → LRU 回收无效 → compaction 受阻→ 高阶块消失 → THP 分配失败
这是系统长期运行的必然结果,而非偶发事件。
9.2 核心结论
碎片是结构性问题,而非容量问题
高阶连续块恢复成本极高
现有机制(LRU + compaction)只能缓解,无法根治
只有隔离内存(CMA)或预留策略能保证连续性
系统设计需考虑高阶分配失败概率,并使用 fallback、迁移策略优化 THP 成功率