每天都在用的 Linux 管道 |,你真的知道它怎么工作的吗?
- 2026-07-03 18:18:51
作者:小康,C/C++编程博主
关键词:管道、pipe、匿名管道、FIFO、进程间通信、文件描述符、内核缓冲区
前言
你每天都在敲这样的命令:
ps aux | grep nginxcat access.log | awk '{print $1}' | sort | uniq -c | sort -rn | head -10| 用起来行云流水,但你有没有想过:
左边的命令和右边的命令是同时跑的,还是左边跑完再跑右边? 数据在哪里"流动"?内存里还是硬盘上? 如果左边生产数据太快,右边来不及消费,会怎样? |和我们 IPC 那篇讲的管道,是同一个东西吗?
这篇文章,我们把 | 背后的机制从头到尾拆开来看。
一、| 的本质:一个内核缓冲区 + 两个文件描述符
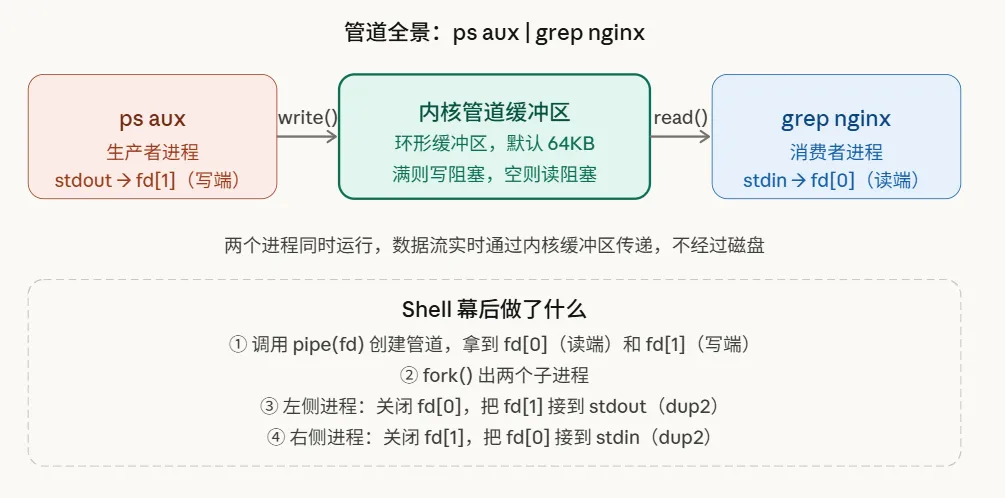
先说结论:管道(pipe)是内核维护的一块环形缓冲区,默认 64KB。
左边的进程往里写,右边的进程从里读。内核提供了两个文件描述符——一个写端,一个读端——连接这两个进程。
几个关键事实,记住了就真正理解了管道:
两个进程是同时运行的,不是左边跑完再跑右边。ps 一边生产数据,grep 一边消费,实时流动。
数据不经过磁盘,全程在内核内存里。速度远比重定向到文件再读取快得多。
管道是单向的,数据只能从写端流向读端,不能反向。
二、Shell 怎么接管 |:pipe() + fork() + dup2()
在用户层面,shell 用三个系统调用实现了 |:
// 这就是 shell 处理 "ps aux | grep nginx" 的核心逻辑int fd[2];pipe(fd); // fd[0] = 读端,fd[1] = 写端if (fork() == 0) {// 子进程 1:执行左侧命令(ps aux) close(fd[0]); // 不需要读端 dup2(fd[1], STDOUT_FILENO); // 把 stdout 重定向到管道写端 close(fd[1]); execvp("ps", args_ps); // 执行 ps,输出自动进管道}if (fork() == 0) {// 子进程 2:执行右侧命令(grep nginx) close(fd[1]); // 不需要写端 dup2(fd[0], STDIN_FILENO); // 把 stdin 重定向到管道读端 close(fd[0]); execvp("grep", args_grep); // 执行 grep,输入自动从管道读}// 父进程(shell)关闭两端,等待子进程结束close(fd[0]); close(fd[1]);wait(NULL); wait(NULL);dup2 是整个机制的关键:它把管道的 fd 复制到标准输入/输出位置。之后,ps 和 grep 根本不知道自己在和管道打交道——它们只是照常读写 stdin/stdout,管道对它们完全透明。
这也解释了为什么大多数 Linux 命令都能互相配合 | 使用——它们各自只关心标准输入和标准输出,shell 负责把管道悄悄塞进中间。
三、管道链:多个 | 串联发生了什么?
cat log | awk '{print $1}' | sort | uniq -c | sort -rn | head -10这条命令涉及 6 个进程,5 根管道,全部同时运行:
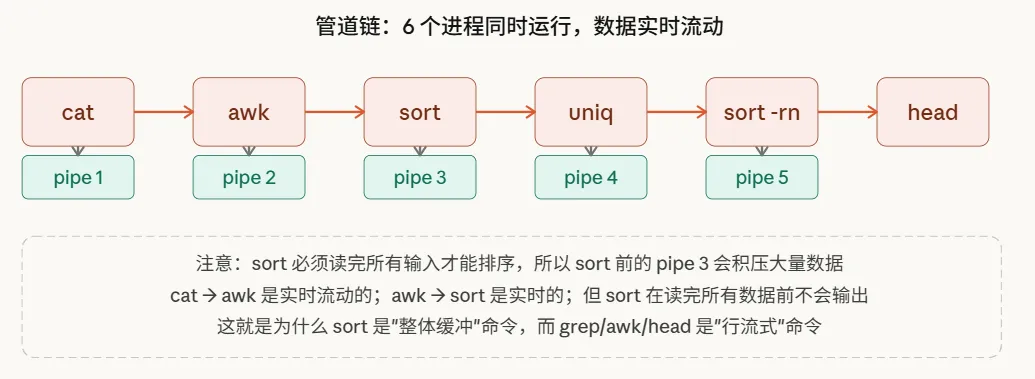
这里有一个很多人不知道的细节:sort不是流式的。
grep、awk、head 这些命令读一行处理一行,能做到实时流动。但 sort 必须把所有输入都读完才能排序——在 sort 之前那根管道里,数据会持续积累,直到上游进程退出(关闭写端),sort 才开始排序,然后往下游写。
这就是为什么处理超大文件时,... | sort | ... 会先等很久,然后突然快速输出。
四、管道的阻塞行为:写满了会怎样?
管道缓冲区只有 64KB,如果生产者太快、消费者太慢,会发生什么?
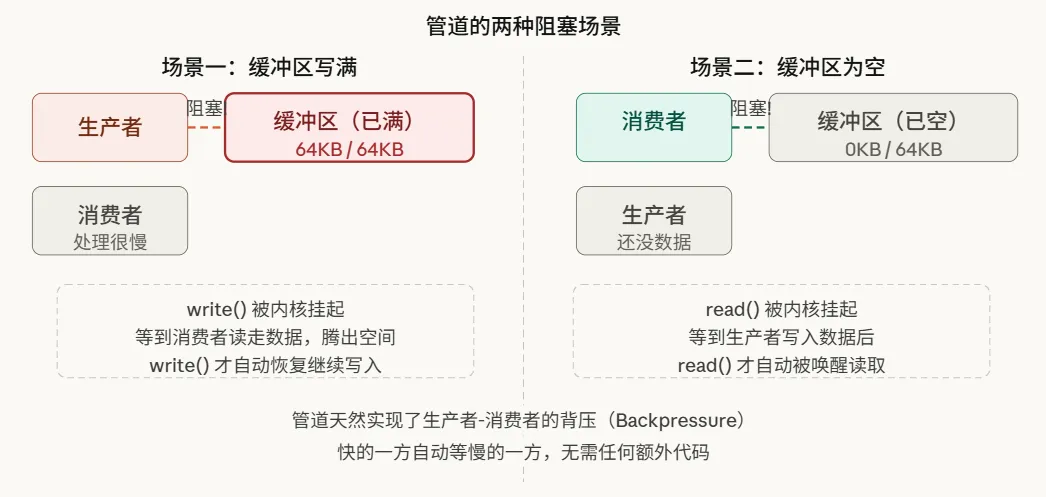
这个自动背压机制是管道设计最精妙的地方:不需要写任何同步代码,快的一方自动等慢的一方。内核帮你做好了一切。
可以用 fcntl 查看或修改管道缓冲区大小:
int pipe_fd[2];pipe(pipe_fd);// 查看管道缓冲区容量int cap = fcntl(pipe_fd[1], F_GETPIPE_SZ);printf("管道容量: %d 字节\n", cap); // 默认 65536 (64KB)// 调大管道缓冲区(需要有权限)fcntl(pipe_fd[1], F_SETPIPE_SZ, 1024 * 1024); // 设为 1MBLinux 2.6.11 起管道默认 64KB,最大可以调到 /proc/sys/fs/pipe-max-size(通常 1MB)。
五、匿名管道 vs 命名管道(FIFO)
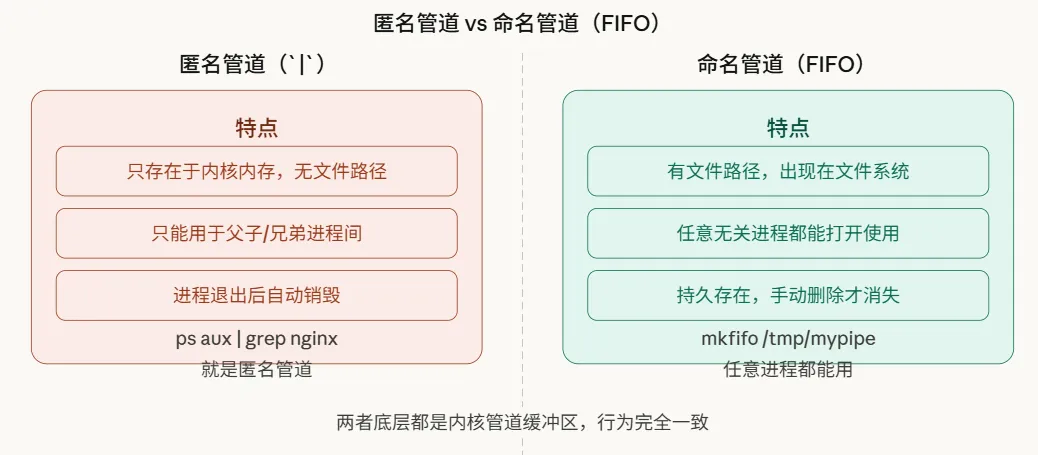
上面讲的都是匿名管道(Anonymous Pipe)——用 | 创建的那种,只存在于内存,只能在有亲缘关系的进程(父子进程)之间使用。
如果两个没有亲缘关系的进程想通信怎么办?用命名管道(Named Pipe / FIFO):
命名管道的实际使用:
# 终端 1:创建命名管道,等待数据mkfifo /tmp/mypipecat /tmp/mypipe # 阻塞,等待写入# 终端 2:往管道写数据(两个进程完全无关)echo"hello from process B" > /tmp/mypipe# 终端 1 立刻看到输出# 用完记得删除rm /tmp/mypipe在 C 代码里:
// 创建命名管道mkfifo("/tmp/mypipe", 0666);// 进程 A:写入int wfd = open("/tmp/mypipe", O_WRONLY);write(wfd, "hello", 5);// 进程 B:读取(两个进程完全独立)int rfd = open("/tmp/mypipe", O_RDONLY);char buf[64];read(rfd, buf, sizeof(buf));ls -l /tmp/mypipe 看到的文件类型是 p(pipe),这是区分 FIFO 和普通文件的标志。
六、管道的限制与陷阱
陷阱一:读端关闭,写端写入触发 SIGPIPE
# 经典例子yes | head -5yes 无限输出 y,head 读 5 行就关闭读端退出。这时 yes 再往管道写,会收到 SIGPIPE 信号,默认行为是终止进程——这正是 yes 正常停止的原因。
// 在程序里忽略 SIGPIPE,改为 write() 返回 -1signal(SIGPIPE, SIG_IGN);// 或者用 MSG_NOSIGNAL 标志send(fd, data, len, MSG_NOSIGNAL);陷阱二:管道是字节流,没有消息边界
和 Unix Domain Socket 的 SOCK_STREAM 一样,管道里的数据是连续字节流。你写入 "hello" 和 "world" 两次,读端可能一次读出 "helloworld",也可能分两次读。需要自己处理消息边界。
陷阱三:stdout 默认行缓冲,在管道里可能变成全缓冲
# 这条命令看起来应该实时输出,但可能长时间没有输出some_program | grep patternsome_program 的 stdout 连到管道时,glibc 自动把行缓冲换成全缓冲(4096 字节),数据积攒够了才发。解决:
// 在程序里强制行缓冲setvbuf(stdout, NULL, _IOLBF, 0);// 或者每次输出后 fflushprintf("some output\n");fflush(stdout);七、高频面试题精析
Q:管道是如何实现进程间同步的?
管道通过内核缓冲区天然实现了生产者-消费者同步:缓冲区满时 write() 阻塞,缓冲区空时 read() 阻塞,内核负责在条件满足时唤醒对应进程。这是一种无需显式锁的同步机制,背后由内核的等待队列和调度器实现。
Q:ls | grep txt 里 ls 和 grep 是串行还是并行执行的?
并行执行。shell 用 fork() 创建两个子进程,两者同时运行。ls 往管道写数据,grep 从管道读数据并过滤,两者通过管道缓冲区同步。不是 ls 跑完再跑 grep——如果 ls 很慢(比如 ls 一个很大的目录),grep 会一直阻塞等待,但两个进程都是存活的。
Q:为什么管道只能单向通信?如何实现双向?
匿名管道只有一个内核缓冲区,有一个读端和一个写端,数据只能单向流动,向反方向写会破坏数据。双向通信需要创建两根管道——一根 A→B,一根 B→A,这正是 shell 实现双向通信(如 |&)或 socketpair() 的方式。
结语
从一个 | 出发,我们走过了:
pipe() 系统调用 → 内核创建 64KB 环形缓冲区 → fork() 创建两个进程 → dup2() 把管道接到 stdin/stdout → 两进程并发运行,通过缓冲区流式传递数据 → 满了自动阻塞,空了自动等待,天然背压下次再敲 | 的时候,你脑子里能浮现出这条链路,就真正理解了它。
原创不易!觉得有收获,记得点赞、推荐、转发支持下哦~ 🙏
📌 还在打基础?从这里出发
如果你读完这篇还觉得 C、C++、Linux 有些陌生,别急:
C 语言快速入门 :大一啃完谭浩强的书,还是不会写代码?我花1个月做了套'12天速成'的C语言课 C++ 快速入门 :12天,从C++小白到独立做项目!我把3年踩坑经验浓缩成了这门课 Linux 编程快速入门 :为什么你学了半年 Linux 编程,还是写不出一个像样的程序?
感兴趣可以了解一下。
🚀 基础扎实了?来做工业级项目
如果你已经有一定基础,想冲击更高的天花板,这些工业级 C++ 项目正是为你准备的:
| 线程池 | |
| 高性能日志库 MiniSpdlog | |
| 高性能内存池 | |
| 多线程下载工具 | |
| MySQL 连接池 | |
| 内存泄漏检测器 | |
| ReactorX | |
| 无锁栈 | |
| 工业级智能指针(shared_ptr) | |
| 高性能网络库 NetCore | |
| 高性能异步日志库 ZephyrLog | |
| 死锁检测工具 | |
| 高性能 HTTP 服务器 | |
| 协程库 CoroForge | |
| 高性能 HTTP 压测工具 | |
| Redis 核心模块实战 |
每个项目都是真实可用的工程代码,不是教学玩具。
详情点击 C++ 项目合集课程链接:为什么同样是"学过C++",有人面试碾压,有人开口就怂?差距在这18个C++硬核项目
对C++项目实战课程感兴趣的朋友,可以扫下方二维码添加小康微信(或微信搜索:jkfwdkf ) 备注「 项目实战 」

随机文章
-
 10个月宝宝每天需要喝多少奶粉?
10个月宝宝每天需要喝多少奶粉?
- 这个网站我愿称之为: python 学习之光!
- 零基础学 Python 别乱找资料!这套鸿蒙团队力荐教程,400集干货免费领
- Python进阶之路70个练手项目
- 两周速成|蓝桥杯python组(一)IO篇
- 这些Linux还须准备好Ubuntu 26.04的到来
- 2026 编程语言风云榜:Python 霸榜,鸿蒙 ArkTS 杀入 Top 20!
- 15天0基础学AI编程(7):安装python与mysql
- 第一次见有人把python编程简历写得这么高级!
- 第217讲:告别手动算分:VBA和Python双方案构建自动化质检评分计算引擎,释放管理效能
- 这么好用的Python学习指南被我拿到了!
