【Python大语言模型系列】谈一谈大模型应用的两种工作模式:Workflow和Agent(案例分析)
- 2026-07-03 14:21:02
这是我的第459篇原创文章。
『数据杂坛』以Python语言为核心,垂直于数据科学领域,专注于(可戳👉)Python程序设计|数据分析|特征工程|机器学习分类|机器学习回归|深度学习分类|深度学习回归|单变量时序预测|多变量时序预测|语音识别|图像识别|自然语音处理|大语言模型|软件设计开发等技术栈交流学习,涵盖数据挖掘、计算机视觉、自然语言处理等应用领域。(文末有惊喜福利)

一、引言
1、workflow:在预定义的链路中由LLM控制流程(路由代理)
大模型作用:根据意图识别判断走哪条链路
2、agent:LLM根据环境(对话上下文)自行选择工具并执行(工具代理)
大模型作用:根据上下文判断要不要调工具,选择哪个工具
结论:Workflow(无论是 Dify 的可视化编排,还是 LangGraph 的状态机)非常适合步骤确定 + 条件有限的流程,一旦进入长尾问题,Workflow 就会遇到“分支爆炸”,只要“问题不可完全穷举、要跨多系统查证、并且需要在对话中澄清/协商/决策”,无法事先“画”成固定分支,需要在对话上下文里做决策、需要跨工具动态组合、需要“问一句 → 查一下 → 再决定,就更应该用 Agent 框架,而不是纯 Workflow。以 AutoGen/CrewAI 这类 Agent 框架为例,它们把“在对话里动态规划与调用工具”作为第一性能力。
二、ReAct范式
ReAct范式由Shunyu Yao等人在2022年的论文《ReAct: Synergizing Reasoning and Acting in Language Models》中首次提出。
ReAct的核心在于推理和行动的交替进行,而不是传统AI的"纯推理"或"纯行动"模式。
通过一个具体的天气查询例子来说明:
# 传统AI方法:要么纯推理,要么纯行动def traditional_reasoning_only(question):"""纯推理方法:仅基于训练数据回答"""return "基于我的训练数据,今天可能是晴天"def traditional_action_only(question):"""纯行动方法:直接调用API,缺乏思考"""# 模拟直接调用API,没有推理过程if "天气" in question:return "晴天,温度25°C" # 硬编码结果,没有推理return "无法处理"# ReAct方法:推理和行动交替进行def react_approach(question):"""ReAct方法:推理和行动交替进行"""# 第1步:推理 - 分析问题reasoning = "用户问的是今天某城市的天气,我需要查询实时天气信息"# 第2步:行动 - 执行查询weather_result = weather_api("某城市")# 第3步:推理 - 分析查询结果reasoning = "查询结果显示今天某城市是晴天,温度25度,这是实时准确信息"# 第4步:行动 - 生成最终答案return"今天某城市是晴天,温度25度,适合外出"
二、Agent(工具代理)
2.1 简单demo
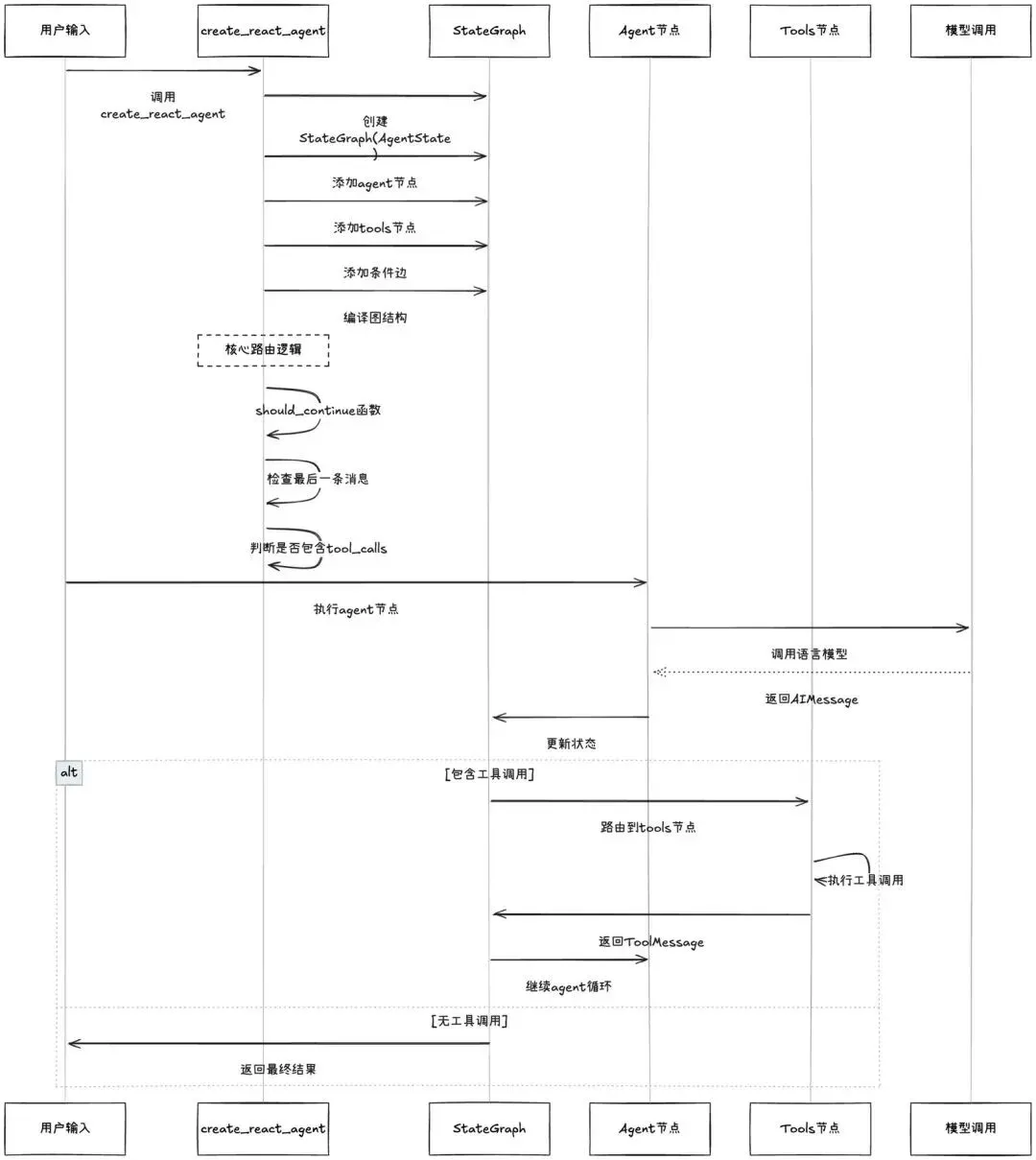
项理解了ReAct的原理后,你可能会想:如何在项目中实现这种"推理-行动"的循环?比如,如何让AI在需要时主动调用工具,如何管理整个对话状态,如何控制循环的结束条件?LangGraph就是专门解决这些问题的框架。在LangGraph里,这个过程分三步:
第一步:定义工具
from langchain_core.tools import tool@tooldef search_web(query: str):"""搜索互联网获取最新信息"""# 实际调用搜索APIreturn "搜索结果..."@tooldef get_weather(city: str):"""查询城市天气"""if city == "北京":return "北京今天16度,晴"return "未知城市"
第二步:绑定到模型
tools = [search_web, get_weather]llm_with_tools = llm.bind_tools(tools)
第三步:让AI自动调用
response = llm_with_tools.invoke("北京天气怎么样?")# AI会自动生成:get_weather(city="北京")
2.2 进阶版
这次我们做个功能更强大的助手,支持:
联网搜索
天气查询
用户信息存储
普通对话
完整代码:
import osimport jsonimport requestsfrom typing import Optional, Annotatedfrom pydantic import BaseModel, Fieldfrom langchain_openai import ChatOpenAIfrom langchain_core.tools import toolfrom langgraph.graph import StateGraph, END, STARTfrom langgraph.prebuilt import ToolNodefrom langchain_core.messages import HumanMessage, AnyMessage, AIMessagefrom typing import TypedDictimport operator# ========== 1. 配置 ==========os.environ["OPENAI_API_KEY"] = "your-api-key-here"llm = ChatOpenAI(model="gpt-4o-mini")# ========== 2. 定义工具 ==========@tooldef search_web(query: str):"""搜索互联网获取最新信息Args:query: 搜索关键词"""print(f"[Tool] 正在搜索: {query}")# 这里用一个简化的实现# 实际项目可以接入真实的搜索APIreturn f"关于'{query}'的最新搜索结果:[这里是模拟的搜索结果]"@tooldef get_weather(city: str):"""查询城市天气Args:city: 城市名称"""print(f"[Tool] 正在查询天气: {city}")weather_data = {"北京": "北京今天16度,天气晴朗","上海": "上海今天20度,多云","深圳": "深圳今天28度,有雨"}return weather_data.get(city, f"抱歉,暂时没有{city}的天气信息")@tooldef save_user_info(name: str, age: int, email: str, phone: str):"""保存用户信息到数据库Args:name: 用户姓名age: 用户年龄email: 邮箱地址phone: 手机号"""print(f"[Tool] 正在保存用户信息: {name}")# 实际项目这里应该是真实的数据库操作print(f" - 姓名: {name}")print(f" - 年龄: {age}")print(f" - 邮箱: {email}")print(f" - 手机: {phone}")return f"✅ 已成功保存 {name} 的信息"# ========== 3. 创建工具节点 ==========tools = [search_web, get_weather, save_user_info]tool_node = ToolNode(tools)# 绑定工具到模型llm_with_tools = llm.bind_tools(tools)# ========== 4. 定义图的状态 ==========class AgentState(TypedDict):messages: Annotated[list[AnyMessage], operator.add]# ========== 5. 定义节点函数 ==========def call_model(state):"""调用大模型,让它决定要不要用工具"""print(f"\n[call_model] 收到消息: {state['messages'][-1].content}")messages = state['messages']response = llm_with_tools.invoke(messages)# 检查AI是否要调用工具if response.tool_calls:print(f"[call_model] AI决定调用工具: {[tc['name'] for tc in response.tool_calls]}")else:print("[call_model] AI决定直接回答")return {"messages": [response]}# ========== 6. 定义路由函数 ==========def should_continue(state: AgentState):"""判断是否需要调用工具"""messages = state["messages"]last_message = messages[-1]# 如果AI生成了tool_calls,就去执行工具if last_message.tool_calls:return "tools"# 否则直接结束return END# ========== 7. 构建图 ==========workflow = StateGraph(AgentState)# 添加节点workflow.add_node("agent", call_model) # AI决策节点workflow.add_node("tools", tool_node) # 工具执行节点# 设置入口workflow.add_edge(START, "agent")# 添加条件边:AI决定后,要么调用工具,要么结束workflow.add_conditional_edges("agent",should_continue,{"tools": "tools",END: END})# 工具执行完后,回到AI节点让它总结结果workflow.add_edge("tools", "agent")# 编译graph = workflow.compile()# ========== 8. 测试函数 ==========def test_agent(query):print("\n" + "="*70)print(f"👤 用户: {query}")print("="*70)result = graph.invoke({"messages": [HumanMessage(content=query)]},{"recursion_limit": 10} # 防止无限循环)final_answer = result["messages"][-1].contentprint(f"\n🤖 助手: {final_answer}")print("="*70 + "\n")# ========== 9. 运行测试 ==========if __name__ == "__main__":# 测试1:普通对话test_agent("你好,请介绍一下你自己")# 测试2:天气查询test_agent("北京今天天气怎么样?")# 测试3:联网搜索test_agent("Claude 4.5 Sonnet有什么新功能?")# 测试4:用户信息test_agent("我叫李四,25岁,邮箱lisi@example.com,手机139xxxx321")# 测试5:复杂任务(可能调用多个工具)test_agent("帮我查一下上海的天气,然后搜索一下最近的AI新闻")
运行效果:

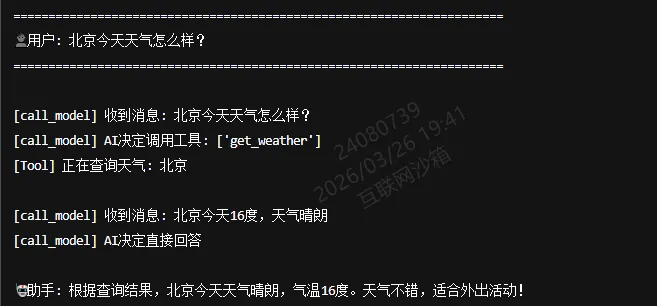

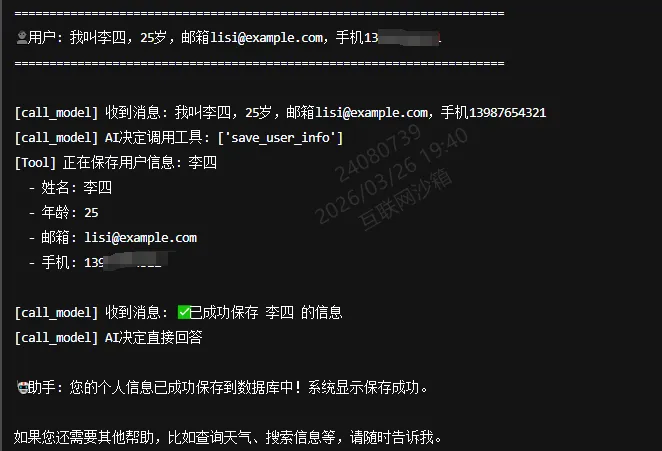

2.3 原理深度拆解
这个工具调用的流程比路由代理复杂一些,我们详细拆解:
流程图:
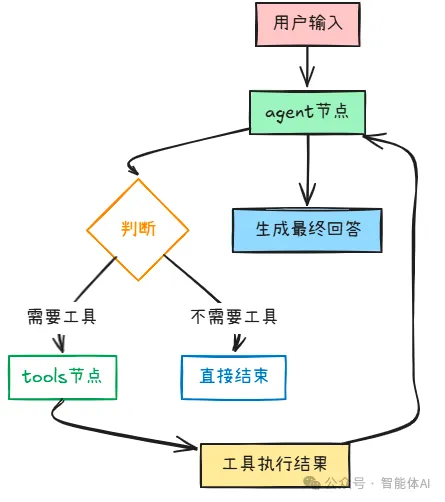
关键点1:AI如何知道要调用哪个工具?
当我们执行llm.bind_tools(tools)时,LangChain会把
工具的信息(名称、描述、参数):
你现在有以下工具可用:1. search_web(query: str) - 搜索互联网获取最新信息2. get_weather(city: str) - 查询城市天气 3. save_user_info(name, age, email, phone) - 保存用户信息用户问题:
北京今天天气怎么样?
告诉AI,并问AI
AI分析后会返回工具名称和对应的参数值:
{"name": "get_weather","args": {"city": "北京"}}
关键点2:ToolNode如何执行工具?
ToolNode内部实现很简单:
def tool_node(state):results = []for tool_call in state["messages"][-1].tool_calls:# 找到对应的工具tool = tools_by_name[tool_call["name"]]# 执行工具result = tool.invoke(tool_call["args"])# 包装成ToolMessageresults.append(ToolMessage(content=result, ...))return {"messages": results}
关键点3:为什么要回到agent节点?
因为工具的返回结果通常是原始数据,需要AI整理成人类能看懂的回答:
工具返回: "北京今天16度,天气晴朗"AI整理后: "北京今天的天气是16度,天气晴朗。适合外出活动哦!"
关键点4:怎么保证AI不会乱调用工具?
清晰的工具描述:让AI明确知道每个工具的用途
参数验证:在工具内部验证参数合法性
权限控制:敏感操作需要用户确认
日志记录:记录所有工具调用,方便追踪
2.4 Function Calling or MCP
Function Calling:
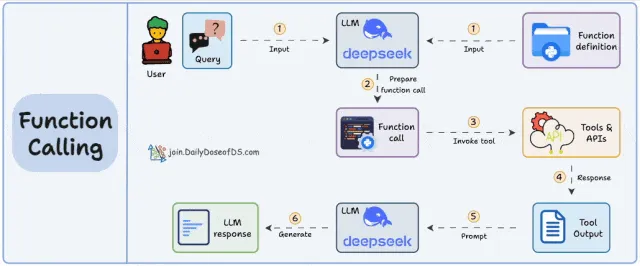
基本工作原理如下:LLM 接收用户的提示词,LLM 决定它需要的工具,执行方法调用,后端服务执行实际的请求给出处理结果,大语言模型根据处理结果生成最终给用户的回答。
不同的 API 需要封装成不同的方法,通常需要编写代码,很难在不同的平台灵活复用。
MCP:
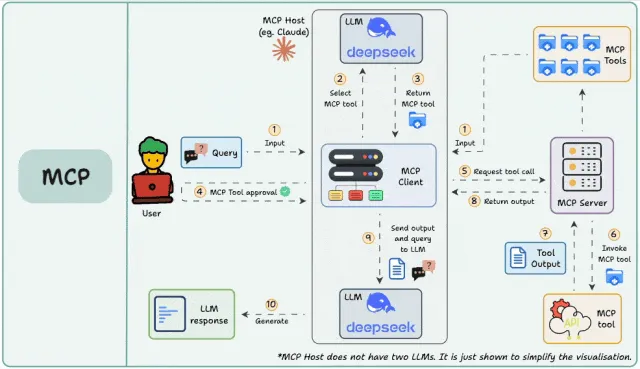
首先需要在主机上自动或手动配置 MCP 服务,当用户输入问题时, MCP 客户端让 大语言模型选择 MCP 工具,大模型选择好 MCP 工具以后, MCP 客户端寻求用户同意(很多产品支持配置自动同意),MCP 客户端请求 MCP 服务器, MCP 服务调用工具并将工具的结果返回给 MCP 客户端, MCP 客户端将模型调用结果和用户的查询发送给大语言模型,大语言模型组织答案给用户。
主机:代表任何提供 AI 交互环境的应用程序(如 Claude 桌面版、Cursor),它能访问工具和数据,并运行 MCP 客户端。
MCP 客户端:在主机内运行,使其能与 MCP 服务器通信。
MCP 服务器:暴露特定功能并提供数据访问,例如:
工具:使 LLM 能通过服务器执行操作 资源:向 LLM 公开服务器中的数据和内容 提示:创建可重用的提示模板和工作流
区别在于MCP多包了一层,Function Calling是LLM直接和服务端(工具或者接口)交互(调用),而MCP多了一个客户端,LLM和客户端交互,客户端和服务端交互。
三、小结
Agent交互图:
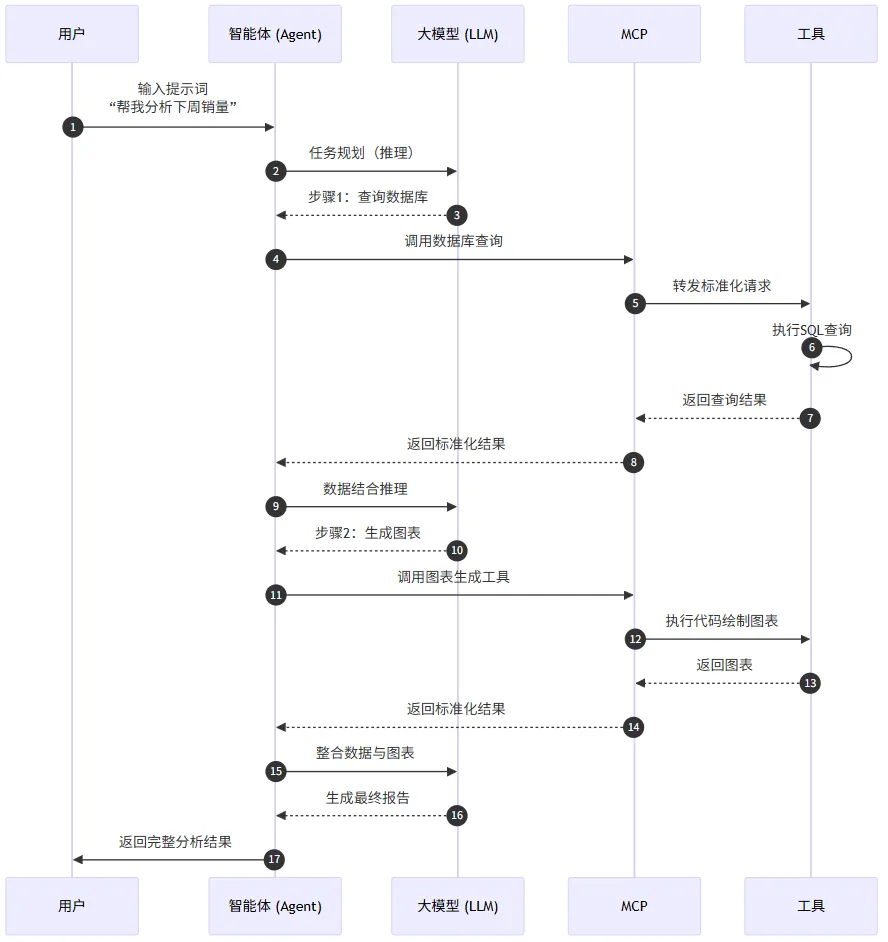
1. 提示词 - 指令与控制
角色:是用户与大模型/智能体之间的“沟通语言”和“操作指令”。通过精心设计的提示词,可以引导大模型执行特定任务、扮演特定角色或调用特定工具。
关系:提示词是激活和驱动大模型的关键输入。
例子:“你现在是一个旅行规划专家,请使用网络搜索工具,为我查找北京未来三天的天气,并推荐室内外活动。”
2. 智能体 - 决策与执行中心
角色:智能体是一个以大模型为核心,增加了自主性和执行力的软件实体。它不仅仅是被动地响应提示,还能够:
规划:将复杂目标拆解为步骤(例如:先查天气,再查航班,最后推荐景点)。
记忆:保留对话和历史操作的上下文。
工具调用:根据规划,决定在何时调用何种工具。
关系:智能体将大模型的通用能力与专用工具结合起来,形成一个可以主动完成任务的“数字员工”。
例子:AutoGPT、ChatGPT的Advanced Data Analysis模式、各种AI助手。
3.大模型 - 核心引擎
角色:是整个体系的“大脑”和基础能力提供者。它具备强大的语言理解、生成、逻辑推理能力。
类比:就像是人类的大脑,能够思考、分析和创造。
例子:DeepSeek、Qwen、GPT-4、Claude、Llama等。
4. MCP模型上下文协议 - 连接标准
角色:MCP是一个标准化协议,它定义了智能体(或大模型应用)与工具之间如何“对话”,解决了工具无法通用的问题。
核心价值:
标准化:工具开发者按照统一的MCP标准来开发工具,无需为每个智能体做适配。
安全性:明确定义了工具的可访问资源和操作权限。
互操作性:任何支持MCP的智能体都可以轻松使用任何符合MCP标准的工具。
关系:MCP是连接“智能体层”和“能力扩展层”的标准化桥梁。它让工具的集成变得简单、安全、统一。
5. 智能体工具 - 手脚与感官
角色:是智能体用来与现实世界交互、获取实时信息或执行具体操作的“接口”或“插件”。大模型本身是“纯思维”的,它不知道实时天气,不能执行代码,也不能操作数据库,工具弥补了这一缺陷。
关系:智能体通过调用工具来扩展其能力边界,从“思考”走向“行动”。
例子:
网络搜索工具:获取最新信息。
代码执行器:运行一段代码并返回结果。
数据库查询工具:从数据库中检索信息。
API调用工具:与其他软件服务交互。
建立CNN与Transformer融合模型实现单变量时序预测(案例+源码)
建立Transformer-LSTM-TCN-XGBoost融合模型多变量时序预测(源码)
利用SHAP进行特征重要性分析-决策树模型为例(案例+源码)
梯度提升集成:LightGBM与XGBoost组合预测油耗(案例+源码)
一文教你建立随机森林-贝叶斯优化模型预测房价(案例+源码)
建立随机森林模型预测心脏疾病(完整实现过程)
建立CNN模型实现猫狗图像分类(案例+源码)
使用LSTM模型进行文本情感分析(案例+源码)
基于Flask将深度学习模型部署到web应用上(完整案例)
新版Dify 开发自定义工具插件在工作流中直接调用(完整步骤)
作者简介:
读研期间发表6篇SCI数据算法相关论文,目前在某研究院从事数据算法相关研究工作,结合自身科研实践经历不定期持续分享关于Python、数据分析、特征工程、机器学习、深度学习、人工智能系列基础知识与案例。
致力于只做原创,以最简单的方式理解和学习,关注我一起交流成长。
1、关注下方公众号,点击“领资料”即可免费领取电子资料书籍。
2、文章底部点击喜欢作者即可联系作者获取相关数据集和源码。
3、数据算法方向论文指导或就业指导,点击“联系我”添加作者微信直接交流。
4、有商务合作相关意向,点击“联系我”添加作者微



