本文的重点不在“怎么用”,
而在于理解一件事:
你敲下的每一个网络命令,其实都在改写内核协议栈的运行状态。
你是内核协议栈的“操盘手”。
一、一个常见误解
很多人觉得:
ping = 网络是否通
netstat = 查看连接
ifconfig = 配网卡
但从内核角度看:
这些命令本质上是在读写 kernel networking stack 的状态。
你不是在“用网络”,你是在:
操控 socket + routing + neighbor + netfilter 的组合系统
二、为什么 Linux 网络命令越来越“难用”
你可能注意到:
ifconfig → 被淘汰
route → 被淘汰
netstat → 被淘汰
统一被一个命令替代:
1️.这不是重构,这是“理念变化”
旧工具的问题,每个工具管一块:
ifconfig → 接口
route → 路由
arp → 邻居表
而内核里,这些是强耦合的状态机。
于是新思路是:
用一个工具,直接映射 kernel object
2️. ip 命令到底在干嘛?
本质上是:
通过 netlink socket 和内核通信
不是读文件,而是:
这是 Linux 网络工具和其他 command 最大的不同:
它是 RPC,不是文本解析。
三、ss:为什么它能替代 netstat
1️. netstat 的问题
依赖 /proc/net/*
每次都要解析文本
性能差
2️. ss 的优势
直接走 netlink
内核直接返回 socket 信息
这意味着:
ss 是“内核态视角”,而不是“文件快照”。
3️. 一个关键认知
当你看到:
ESTAB:稳定工作状态,三次握手已完成;连接进入全双工数据传输阶段。这是 TCP 状态机的“稳态”,表示双方已建立可靠的逻辑信道。TIME-WAIT:主动关闭方的等待状态;主动关闭连接的一方,在发送完最后一个 ACK 后会进入此状态,等待 2MSL(最长报文段寿命的两倍)。 这是 TCP 状态机的“善后清理”节点,确保网络中属于此连接的旧报文彻底消失,防止污染新连接。 CLOSE-WAIT:被动关闭方的等待状态;被动关闭连接的一方,在收到对方的 FIN 并回复 ACK 后进入此状态,等待本地应用程序 调用 close() 来发送自己的 FIN。这是 TCP 状态机的“等待上层指令”节点。你看到的不是连接,而是:
TCP 状态机的当前节点
四、ping:最被误解的命令
1️. ping 用的不是 TCP
所以:
ping 通 ≠ TCP 可用
2️. ping 的真实作用
它验证的是:
路由是否可达
ICMP 是否被允许
网络路径是否通畅
但现实世界:
防火墙可能屏蔽 ICMP
NAT 可能影响返回路径
所以:
ping 更像“网络探针”,不是“连接测试”。
五、tcpdump:你唯一能“偷看协议栈”的窗口
1️. 它是怎么做到抓包的?
数据路径:
NIC(网卡) → 驱动 → tcpdump → kernel stack正常路径:将数据包送入内核协议栈,由 TCP/IP 协议处理,最终交给应用程序。抓包路径:如果存在 Packet Socket(例如 tcpdump创建的),则复制一份数据包, 直接送入用户空间的 tcpdump进程。
它甚至可以:
在数据进入协议栈之前就看到包
2️. 为什么 tcpdump 很危险
高流量下会丢包
会影响系统性能
可能改变 timing 行为
它是:
观测工具,但会干扰系统
六、ethtool:驱动层的“真相入口”
1️. 它操作的不是网络栈
而是:
网卡驱动(driver)
你看到的是:
全双工(Full Duplex)
同时双向传输,发送和接收互不干扰 现代标准(100M/1G/10G 等) 所有现代交换网络(交换机-主机、交换机-交换机) 半双工(Half Duplex) 交替双向传输,同一时间只能发送或接收 旧式标准(10M/100M) 集线器(Hub)环境、旧式网络
将本应由CPU处理的网络协议计算任务,卸载到网卡专用硬件中执行,从而大幅降低CPU负载、提升吞吐量的技术。
2️. offload 是什么?
网卡可以帮你做:
checksum :由网卡硬件计算和验证数据包的校验和,解放CPU;
segmentation (TSO) :TCP分段卸载;以太网MTU通常为1500字节(包括头部),将大于MTU的TCP数据包的分段工作,从CPU转移到网卡硬件执行。
GRO :Generic Receive Offload,通用接收卸载;在接收侧,将多个属于同一流的小数据包合并成一个大包,再交给协议栈处理。
这意味着:
你在 tcpdump 看到的包,可能是“假象”
因为:
七、ip route:网络的“大脑”
1️. 路由不是一条路径
而是:
一个决策系统(FIB)
包含:
前缀 = 网络地址 + 子网掩码长度 匹配 = 目标IP地址与路由表项的网络地址部分进行比较 工作原理:逐位精确匹配
传统路由:目标IP → 路由表 → 下一跳 策略路由:数据包特征 → 策略规则 → 路由表 → 下一跳 常见的策略路由有:基于数据包长度的策略,时间策略路由以及负载均衡策略
2️. 为什么你能“多出口上网”
因为:
一句话概括: 多出口上网 = 多张地图(路由表) + 智能导航(规则系统)
通过这种架构,网络管理员可以:
充分利用多个ISP的带宽
实现业务流量精细化管理
提高网络可靠性和可用性
优化用户体验和成本效益
这已经接近:
软件定义网络(SDN)的雏形
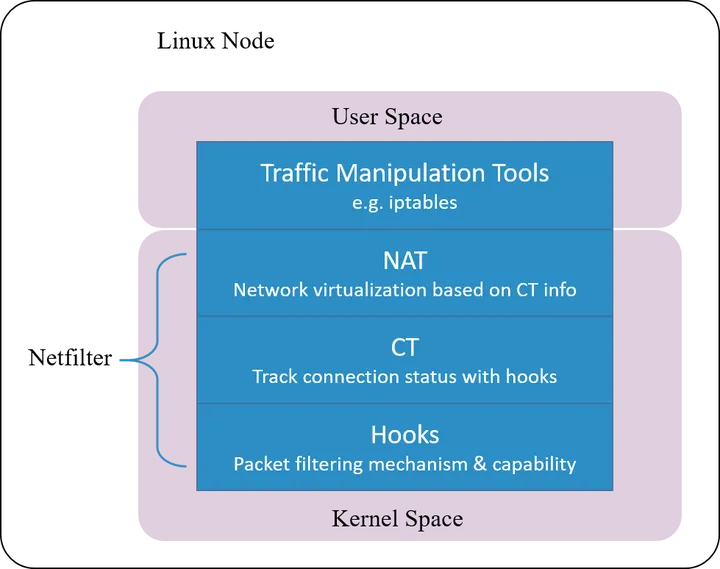
八、conntrack:NAT 背后的核心机制
很多人以为 NAT 是简单的地址替换。
实际上:
NAT 是一个状态机。
1️. conntrack 记录什么?
源地址
目标地址
端口映射
状态(NEW / ESTABLISHED)
2️. 为什么 NAT 很复杂
因为:
这就是:
为使连接跟踪(Conntrack)能够追踪节点上所有连接的状态,它需要完成以下工作:
拦截(或过滤)经过此节点的每一个数据包,并对其进行分析。
建立一个用于记录这些连接状态的“数据库”(即连接跟踪表)。
根据从拦截到的数据包中提取的信息,及时更新数据库中连接的状态。
当一个新的连接尝试开始(拦截到 TCP SYN 包)时,创建一个新的连接跟踪条目来记录该连接。
当属于某个已存在连接的数据包到达时,更新该连接跟踪条目的统计信息(例如已发送字节数、包数、超时值等)。
当一个连接跟踪条目在超过30分钟没有匹配到任何数据包时,系统会考虑删除此条目。
Netfilter framework
九、一个完整链路:当你访问一个网站
实际发生:
DNS 查询(可能)
socket()
connect()
路由查找(ip route)
ARP / neighbor 查找
发包(驱动)
NIC 发出
返回包进入
conntrack 更新状态
TCP 状态机推进
整个过程:
不是“发请求”,而是驱动一整套状态机。
十、为什么 Linux 网络命令“难记”
因为它们不是用户抽象,而是:
内核数据结构的直接映射
比如:
ip link → net_device
ip addr → in_ifaddr
ip route → fib_table
ss → sock
这也是为什么:
一旦理解内核结构,命令反而变简单。
十一、三句你真正该记住的话
Linux 网络命令不是工具集合,而是协议栈的控制面。
ip / ss 之所以难,是因为它们接近内核真实模型。
你看到的“网络问题”,往往是状态机不同步。
参考文献:
What is Conntrack
 10个月宝宝每天需要喝多少奶粉?
10个月宝宝每天需要喝多少奶粉?
