2025 常用 linux 指令 top10 (个人向)
- 2026-07-03 03:38:49

背景
作为 linux 的重度用户,每天都要和 linux 系统打交道,定位问题也好,调试服务也好,都离不开在命令行用指令进行各种操作
在写完 top10 听歌回顾之后,回过头一想,2025 年确实用了挺多 linux 指令的吧。有哪些指令是在用的时候眼前一亮,并且能在需要的时候马上用得上的呢?
于是就有了这样一篇慢节奏的、从完全个人体会、真正使用者的视角,回顾 10 个一年来使用最多 linux 指令
所有指令如下:
git
find
dd
s3cmd
hdfs ( minicluster )
trdsql
k3s ( k3s and deploy flink app )
python( http.server, json.tool, httpbin )
patch
htop
git
❝最近回顾了下我用到的所有服务版本,starrocks 目前用的是 3.3 版本,有一年多没更新了,怎么知道 3.3 和今年刚发布的 3.5 之间,有什么新功能呢?
❞
想了解一个开源项目最新的版本和新功能,从项目官网或者 github 上查看 release 更新日志是一种方法

不过在本地已经拉取的仓库代码中直接执行 git 命令,也是完全可以的,甚至比前面的方式更直观,代码改了哪里,每次更新记录中有什么关键说明都能看到
下面以 flink cdc 项目为例
log --stat
查看最近的提交日志
# 查看所有提交,最近的放在前git log --stat# 反向排序,最早的提交放在前git log --stat --reverse# 只看最近 10 次提交,包括哪些代码文件有变化git log -n 10 --stat# 只看 commit 信息,不看代码变更只看 commit 日志git log --shortstat -n 10 --pretty=oneline# 看指定日期之间的变更git log --stat --since="2026-01-01" --until="2026-03-25"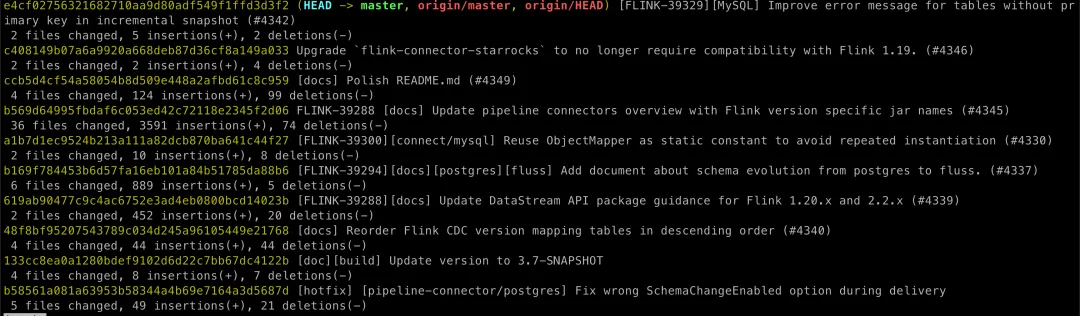
如上图, flink cdc 最近的更新有对 pgsql、mysql 和 pgsql 连接器相关的,也有版本升级相关的
ls-remote
查看项目的最新版本
# 在项目根路径执行,查看最近发布的版本git ls-remote --tags --sort="v:refname" | tail -n10# 或: 不用 clone 整个项目,直接指定项目 github 地址查看git ls-remote --tags --sort="v:refname" https://github.com/apache/flink-cdc | tail -n10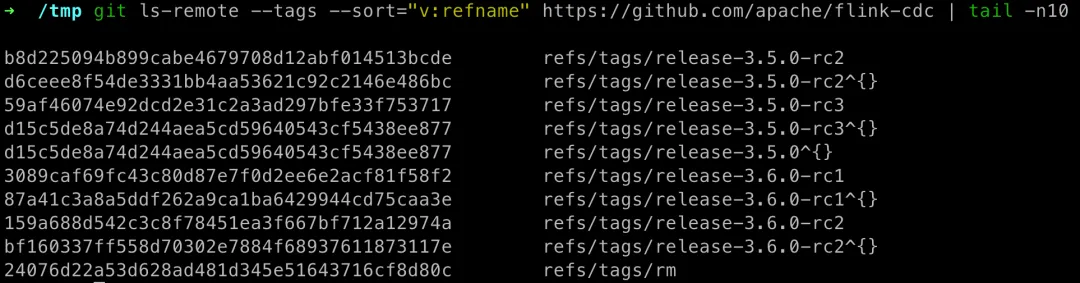
如上,flink cdc 目前最新的稳定版是 3.5。3.6 是最新的预发布版
log --pretty
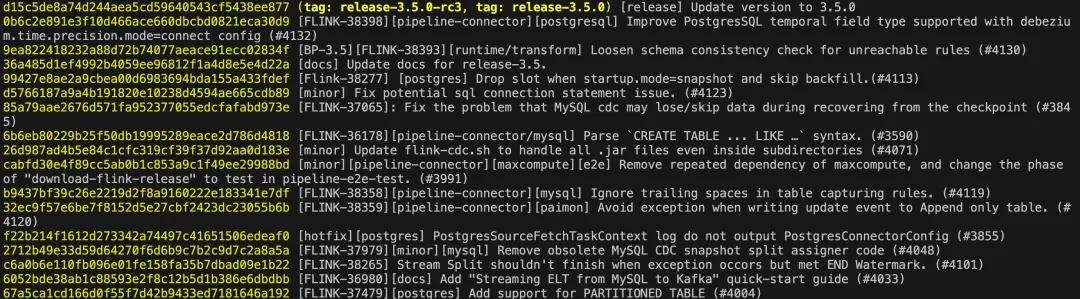
# 查看 flink cdc 在 3.3 和 3.5 之间的 commit 记录git log --pretty=oneline release-3.3.0...release-3.5.0# 查看 starrocks commit ( 只看和 paimon 相关的功能更新 )git log --pretty=oneline 3.3.0...3.5.9 | grep Enhancement | grep Paimon查看版本之间有哪些 commit
对于 flink cdc 这种管理非常规范的项目来说,新功能真的是一目了然
log -L
在你已经知道新功能相关的代码文件、相关的方法名是哪个的时候,也可以直接用 -L 查看这部分代码的变更
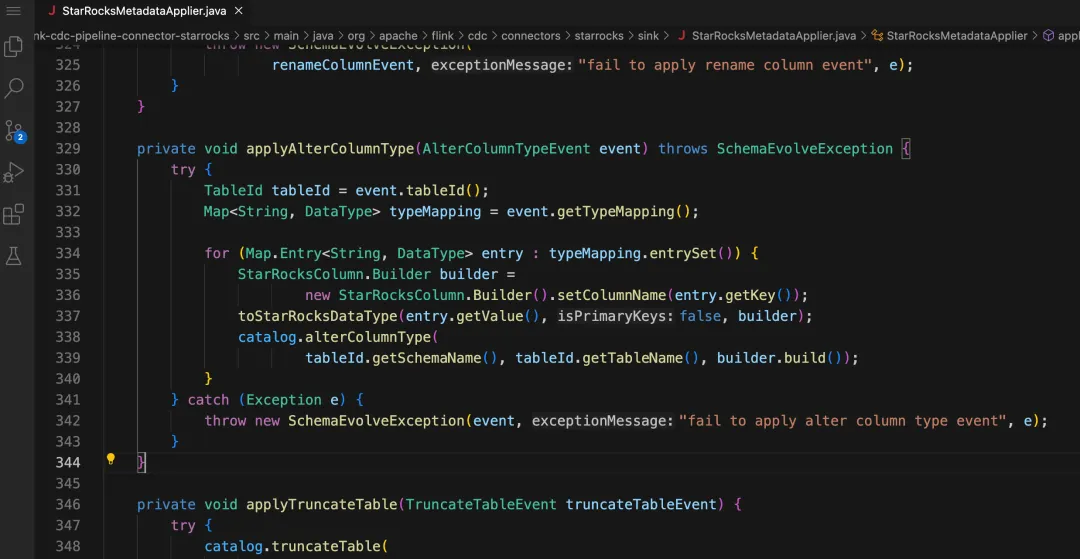
如上 StarRocksMetadataApplier.applyAlterColumnType 是 starrocks 处理列类型修改事件的方法,它的代码在 329-344 行
git log -L 329,344:flink-cdc-connect/flink-cdc-pipeline-connectors/flink-cdc-pipeline-connector-starrocks/src/main/java/org/apache/flink/cdc/connectors/starrocks/sink/StarRocksMetadataApplier.java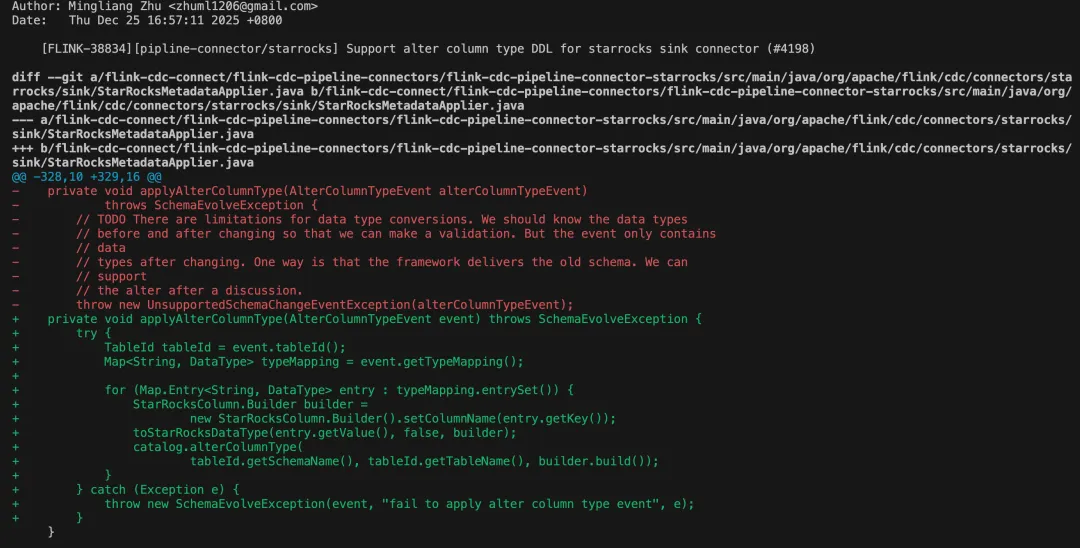
这样就可以看到支持 alter column type 功能是在哪一次 commit 之后支持的了
ls-files
wc -l 是计算行数的指令,和 ls-files 结合,我们可以统计整个项目的文件数和代码行数
以 apache 组织下代码量和复杂度都比较高的 flink 为例, 代码行数达到了 370 多万
# 统计代码文件数git ls-files | wc -l# 统计代码总行数git ls-files | xargs cat | wc -l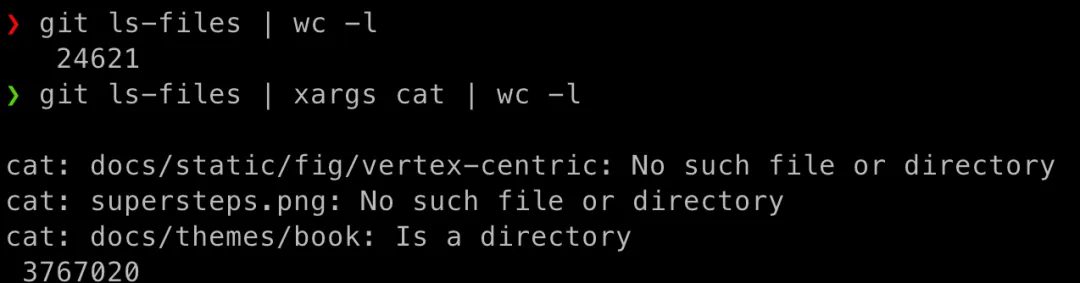
扩展: scc 更细致的项目统计信息
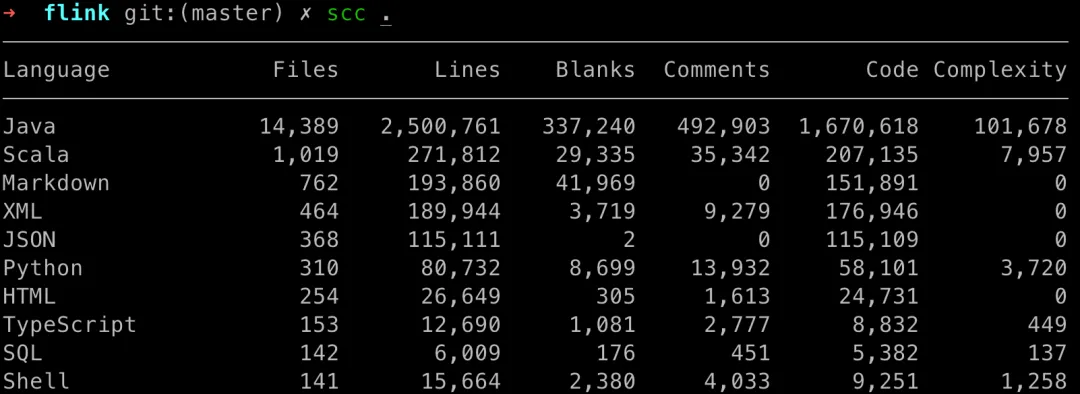
scc[1] 是类似 cloc 的代码统计工具,它可以统计代码行数,以及通过 cocomo ( 构造性成本模型 )算出项目开发所需的时间成本
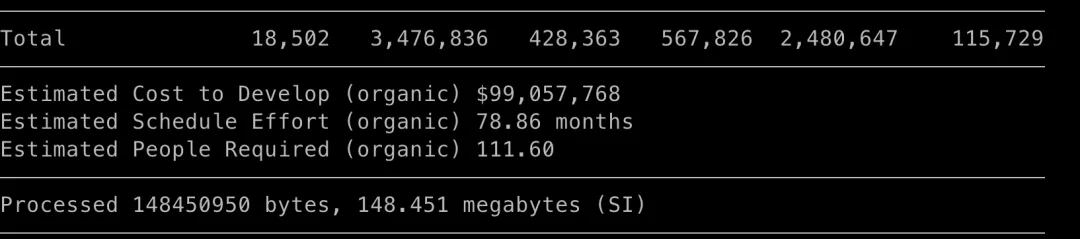
当然这种算出来的结果和实际难免有偏差,笔者还是好奇看了下 flink 需要多少开发时间和投入成本,还是挺惊人的,当然实际的时间和成本肯定要远多得多
flink 开发语言: 主要是 java
flink 开发成本: 9kw 美刀,研发时间需要 78 个月 ( 6.5 年 )
find
❝笔者最近在调试上线一些 flink 任务,于是很荣幸地和 ClassNotFoundException 成为了每天都会见一见的好朋友。如何应付这位热情的朋友,find 就是法宝
❞
find 本身的功能是根据文件名查找文件位置。再结合 xargs 和 grep,它还能实现文件的批量操作、内容筛选等功能
查找文件和目录
首先 find 的基本用法就是在一个目录下查找具体的文件路径,不过它支持很多参数,可以模糊查询、只查找文件而非目录、按修改时间在多久之前等规则来过滤
这里列举一点我用过的参数
# 在指定目录,按文件名查找find /opt/modules/flink -name 'flink-conf.yaml'# 正则模糊匹配find /usr -name '*.h'# 按文件类型查找(f: 文件, d: 目录)find -type f -name "data"# mtime: 按修改时间查找 ( +7 表示7天之前 ) ( 配合 xargs 清理日志 )find /var/log/hive -maxdepth 1 -type f -mtime +7
find + xargs
「场景1: 查找文件内容」
想查找 flink conf 目录下所有和 memory 相关的配置,可以通过 find + xargs + grep 进行批量文件内容过滤
find /opt/modules/flink/conf -name '*' | xargs grep "memory"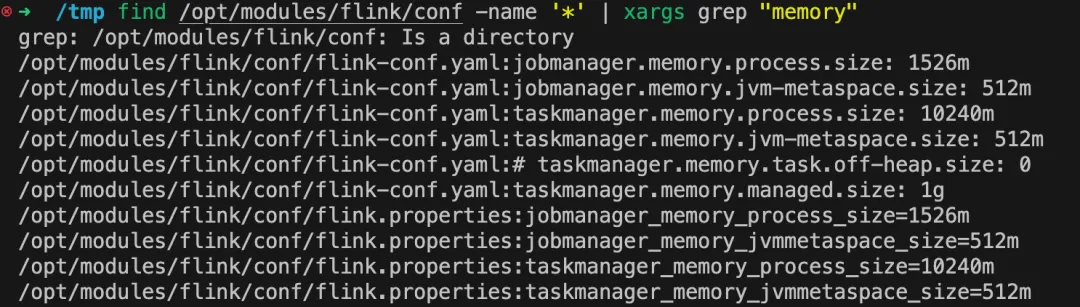
「场景2: 根据 java 类名查找 jar 路径」
在调试 java 程序的时候,环境问题往往是无法避开的,ClassNotFoundException 就是在不同环境部署同一个 java 服务时非常经典的异常,它出现的原因无非就是就是在 classpath 中少了一些 jar 包,加进来再重启服务就能解决
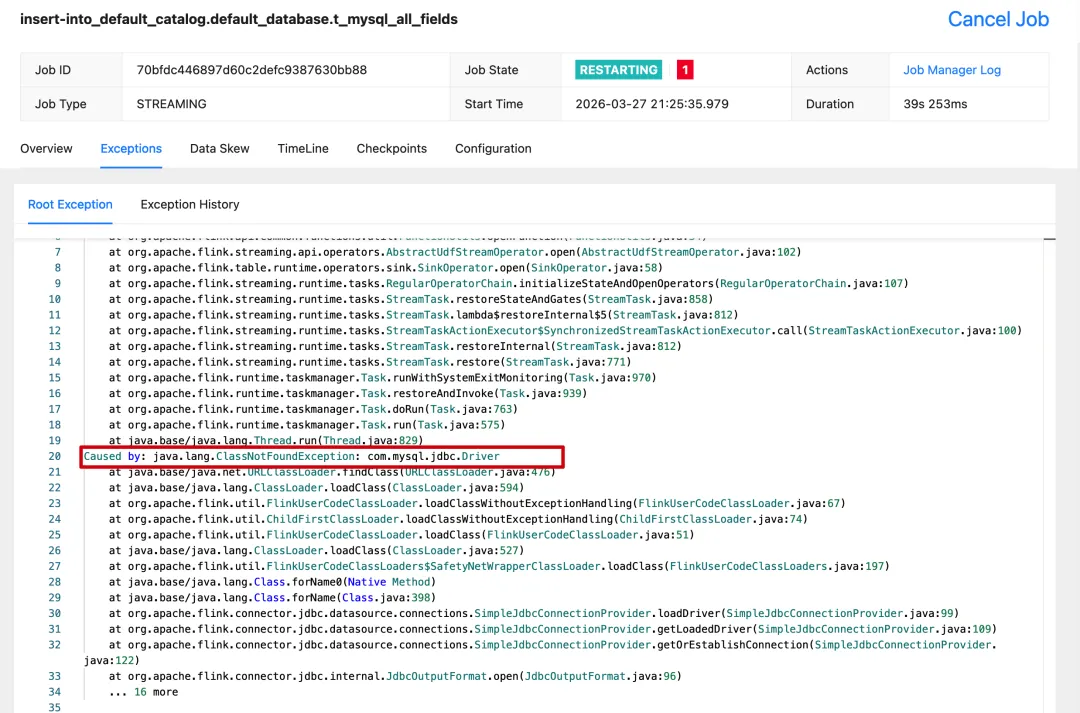
上图是我通过 flink 的 sql 客户端,提交一个 datagen -> mysql 的数据写入任务,但是在 flink 的 lib 目录没有加 mysql-connector-java-{version}.jar 导致的问题
现在我们有了具体的报错,知道具体是少了哪个类,如何通过类名去查找 jar 在哪里呢?
我们可以优先在本地主要的服务安装目录中,用 find 先找找看
find /opt/modules/flink -name '*.jar' | xargs grep -Hls "com.mysql.jdbc.Driver" {} \;
这里因为我本地确实下载了 mysql connector jar (只是不在 lib 目录),因此很快就找到 jar 在哪
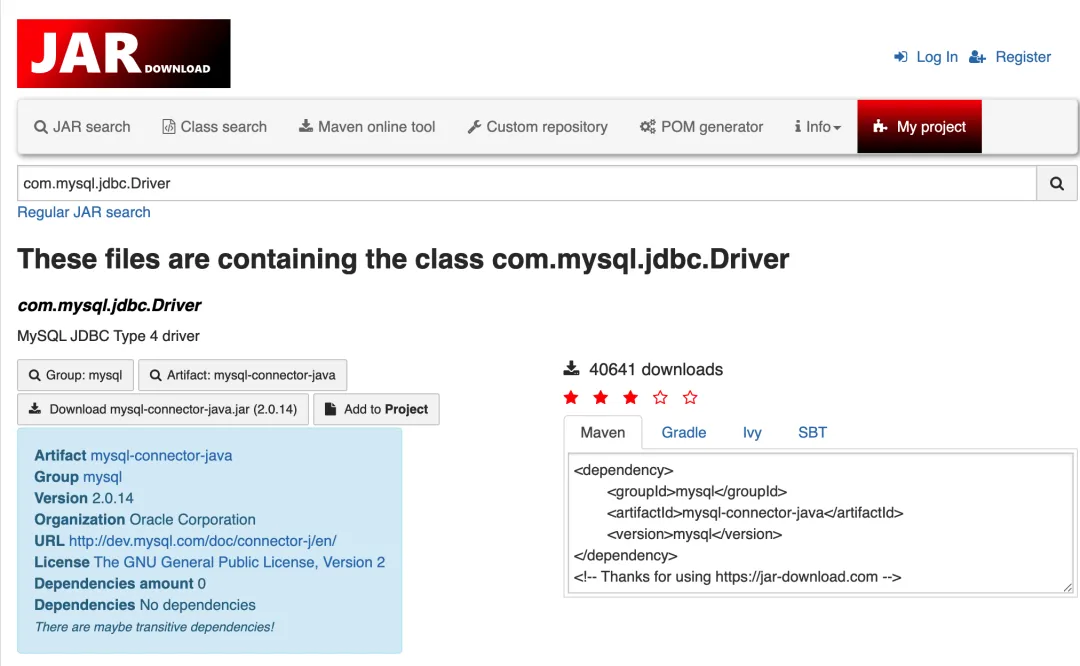
但如果我们找遍了本地机器目录,确实没有需要的 jar 包,就只能去 maven repo 中下载了。通过类名搜索 jar 有一个网站 maven-repository-class-search[2] ,可以按类名查找包名的网站,不过有的类可能很多第三方的包也会引入,所以搜索结果会很多,还得自己筛选一下,找到最准确的依赖包
「场景3: 文件批量操作」
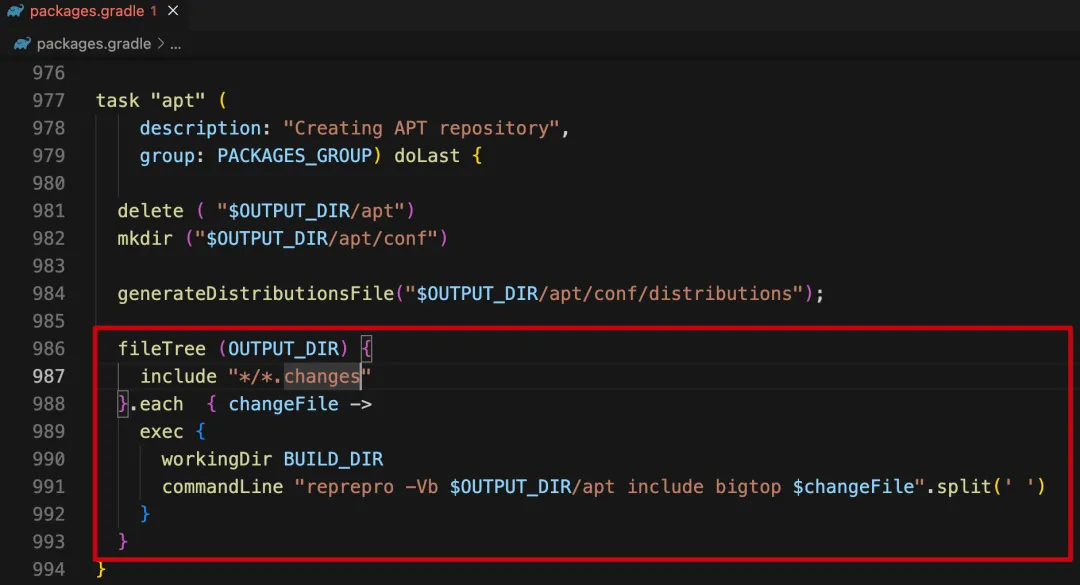
在 ubuntu 编译 bigtop 组件( hadoop、zookeeper、flink 等 )的时候,会先生成 changes 文件,记录最终生成的 deb 安装包的内容,每个组件都有对应的 changes 文件 ( hadoop_3.3.6-1_amd64.changes , hive_3.1.3-1_amd64.changes 等 ),最后再通过 reprepro 生成最终的安装包
在 packages.gradle 中能看到批量对 changes 文件执行 reprepro 的代码,使用 find + xargs 也可以实现相同操作
# 批量对每个组件生成 deb 安装包find output -name '*changes*' | xargs -I {} bash -c "reprepro -Vb ./output/apt include bigtop {}"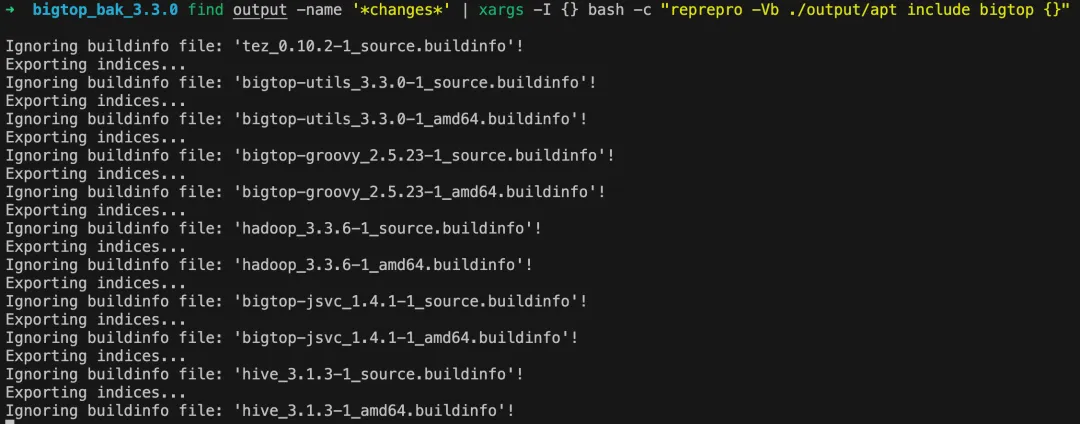
find + sed
「场景: 批量精确查找并替换文件内容」
在 superset 执行 superset load_examples 导入演示数据的时候,会从 examples-data[3] 下载数据集,国内访问 github 不是很稳定,通过 find + sed 的组合,我们可以将 github 默认下载地址统一替换成国内加速源
find /opt/modules/miniconda/envs/py3_10/lib/python3.10/site-packages/superset/examples -type f -name '*'| xargs -I {} bash -c "sed -i 's#data: https://github.com#data: https://ghfast.top/https://github.com#g' '{}'"find /opt/modules/miniconda/envs/py3_10/lib/python3.10/site-packages/superset/examples -type f -name '*' | xargs -I {} bash -c "sed -i 's#data: https://raw.githubusercontent.com#data: https://ghfast.top/https://raw.githubusercontent.com#g' '{}'"扩展: linux 文件索引工具 locate
find 比较适合在特定目录中查找你要的文件,但如果你不确定文件的目录在哪,并且系统上文件很多,那 find 跑起来可能就要比较久了。这个时候 locate 是更适合的工具,因为它是先构建系统上所有文件的索引(相当于字典),再找起来速度就非常快
在 centos 和 ubuntu 上,locate 对应的安装包分别是 mlocate 和 plocate
# centosyum -y install mlocate# ubuntu# 注: ubuntu 安装时会自动进行索引构建,因此安装需要较长时间apt -y install plocate构建索引的指令是 updatedb,索引存储目录在 /var/lib/mlocate(或 plocate)
我在线上服务器实测,文件总数 450w,总存储 430G ,索引只需5分钟构建完成,索引文件大小仅为几十M
索引构建完成后,用文件名搜索,3秒内就搜出来了

dd
❝记得还在读大学时,第一次把笔记本的机械硬盘换下来,再用一张 250G 的固态硬盘重装了系统,那重启之后的感觉,简直就如同体会了过年坐车回家之后,再体验坐高铁的爽感。不过这会再回想起来,好像还差一个疑问未解开:两种硬盘的速度具体相差多少,能否有办法实测出来,让自己有更深刻的印象呢
❞
dd 是 linux 自带、来自 coreutils[4] 的一个指令,可以用于磁盘速度测试、制作硬盘镜像等
刚好我电脑上就插了 HDD 和 SDD 各一块盘,那就直接来测试一下吧
写速度测试
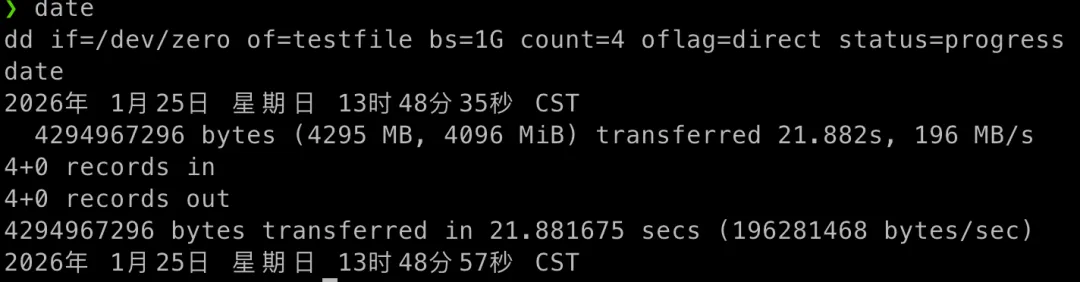
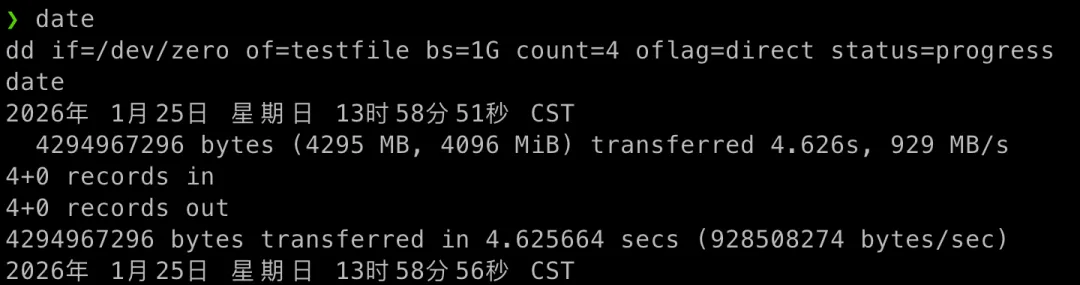
dd if=/dev/zero of=testfile bs=1G count=4 oflag=direct status=progress
如上图,执行这段指令后,会生成一个 1G 大小的文件
参数解释:
count: 创建多少个文件块,最后会组合到同一个文件
iflag, oflag: 输入和输出的方式,默认情况下会使用页缓存,不是真正的磁盘读写性能,direct 表示跳过内存缓存,这样就是比较真实的写入性能( 还有 sync 、dsync 等更严格的参数 )
bs: 每个文件块的大小
if: 文件读取来源, /dev/zero 将会让文件内容全都是 0, 还可以设置成 /dev/urandom 产生随机内容
以下是我在 HDD 和 SSD 分别运行同样指令的结果,可以计算得到 HDD 每秒的写入速度是 196 MB/s,SDD 每秒的写入速度是 929 MB/s 每秒,「SSD 比 HDD 快 4.7 倍」
读速度测试
接下来看看文件读取速度
dd if=testfile of=/dev/null bs=1G count=4 iflag=direct status=progressof=/dev/null 表示数据从磁盘读取出来之后不会再写入其他的 IO 设备,因此最终速度就取决于磁盘读取速度
HDD 测试结果:

SSD 测试结果:

可以算出读速度相差是 5 倍,和写速度相差倍数差不多
扩展: fio
dd 只能模拟顺序写入、读取的操作,fio 还可以模拟随机读写,更接近磁盘使用的真实场景
# 随机写fio -filename=fiotest -direct=1 -iodepth=1 -end_fsync=1 -thread -rw=randwrite -ioengine=psync -bs=4M -size=4G -numjobs=1 -group_reporting -name=randwrite# 随机读fio -filename=fiotest -direct=1 -iodepth=1 -end_fsync=1 -thread -rw=randread -ioengine=psync -bs=4M -size=4G -numjobs=1 -group_reporting -name=randreadHDD 的随机读写结果:


SSD 的随机读写结果:


可以看出在随机读写的场景下,SSD 比 HDD 的速度提升更加明显,快百倍以上
s3cmd[5]
❝定期备份自己电脑上的重要文件,是个好习惯。在工作中,定时备份重要文档同样重要。我通常会备份到对象存储( 比如 ceph )中。但它和个人用的网盘形式不太一样了,没有界面,需要借助指令手动上传
❞
s3 是最标准的对象存储协议,由 AWS 开发。我们可以通过 minio、 seaweedfs 等开源服务,快速搭建一个对象存储,然后就可以把它当做一个个人网盘,进行文件上传和下载操作了
那么通过什么指令可以进行文件操作呢?s3cmd 就是一个可以兼容 aws、minio 和其他公有云对象存储服务 api 协议的指令
安装 s3cmd
s3cmd 是 python 开发的,所以它的安装方式非常简单
pip install s3cmd配置: ~/.s3cfg
在访问对象存储之前,我们需要在当前用户目录下放置 .s3cfg 文件,配置密钥
以访问在本地启动的 minio 地址 localhost:9000 为例:
# 下载 miniowget https://dl.min.io/server/minio/release/linux-amd64/minio# 启动./minio server --address :9000# ~/.s3cfg[default]access_key = access keysecret_key = secret keyhost_base = localhost:9000host_bucket = localhost:9000/testuse_https = False文件操作
和 linux 本地文件操作的指令基本类似
# 上传单个文件、目录s3cmd put --recursive shell-tools s3://test/coding/# 查看目录s3cmd ls s3://test/coding/# 下载文件s3cmd get s3://test/coding/shell-tools/README.md# 统计目录大小s3cmd du -H s3://test/coding/shell-tools# 删除目录s3cmd rm --recursive s3://test/paimon示例:统计一张存入来自 flink datagen 产生的 1kw 条数据的 paimon 表(数据接入 minio ),并查看这个表实际占用磁盘空间大小:

HDFS
❝大数据领域最经典的系统,希望以后还会更多地了解它
❞
既然说到了对象存储,去年笔者接触最多的组件 HDFS ,以及它的使用,自然也是非常值得回顾一下
安装 HDFS
HDFS 整个系统当然是非常复杂,不过既然它是一个 java 服务,安装还是比较简单的,从 apache 官网下载整个安装包即可
wget https://dlcdn.apache.org/hadoop/common/hadoop-3.3.6/hadoop-3.3.6.tar.gz运行 minicluster[6]
最快速运行一个 HDFS 服务的方式就是通过 minicluster 来启动,一行指令就够,也不需要进行繁多的配置了
但「千万千万」注意: 最好不要在公司已经启动了 Hadoop 集群的环境中测试 minicluster,否则很容易不小心就对现有集群执行了 format (重置)操作了。除非你了解怎么把 minicluster 和集群配置区分开,否则最好就是在独立服务器中启动
minicluster 会启动一个最小的 HDFS 和 Yarn “集群”,默认启动一个datanode 作为存储服务,一个 resourcemanager 和一个 nodemanager 用于运行计算任务
【注意】最后的参数 -format 在第二次启动时就不用加了,否则会重置集群数据
./bin/mapred minicluster -Dhdfs.minidfs.basedir=~/modules/hadoop/data/minicluster -Dmapreduce.framework.name=yarn -Dyarn.resourcemanager.webapp.address=0.0.0.0:30071 -nnhttpport 30072 -rmport 30073 -writeConfig ~/modules/hadoop/etc/hadoop/minicluster/core-site.xml -writeDetails ~/modules/hadoop/etc/hadoop/minicluster/hdfs.json -format访问 yarn 任务列表页面: http://localhost:30071/node
访问 namenode 页面: http://localhost:30072/dfshealth.html#tab-overview
启动后,我们就可以像在真正的 HDFS 集群环境那样,通过 hdfs 指令对本地的 minicluster 进行文件操作了
# 后续执行 hdfs 指令和任务之前,需要先设置 conf direxport HADOOP_CONF_DIR=~/modules/hadoop/etc/hadoop/miniclusterexport HADOOP_CLASSPATH=`./bin/hadoop classpath`# 再拷贝两个配置文件,用于 yarn 和 mapreduce 任务识别自己的配置文件cp ~/modules/hadoop/etc/hadoop/minicluster/core-site.xml ~/modules/hadoop/etc/hadoop/minicluster/yarn-site.xmlcp ~/modules/hadoop/etc/hadoop/minicluster/core-site.xml ~/modules/hadoop/etc/hadoop/minicluster/mapred-site.xml./bin/hdfs dfs -ls /
运行 distributed shell[7]
minicluster 同时启动了 HDFS 和 Yarn 组件,有 Yarn 之后我们当然还可以跑 mapreduce 任务
distributedshell 是 hadoop 提供的一个 mapreduce 任务示例,它可以让我们在 HDFS 集群节点上运行脚本
以下是运行 distributedshell 的方式
./bin/hadoop jar share/hadoop/yarn/hadoop-yarn-applications-distributedshell-3.4.3.jar org.apache.hadoop.yarn.applications.distributedshell.Client --jar share/hadoop/yarn/hadoop-yarn-applications-distributedshell-3.4.3.jar --num_containers 1 --container_vcores 1 --container_memory 1024 --shell_command 'sleep 300'任务运行起来之后,你可以在本地进程列表中查到一个正在 "sleep" 的进程,yarn 页面中也能看到这个任务
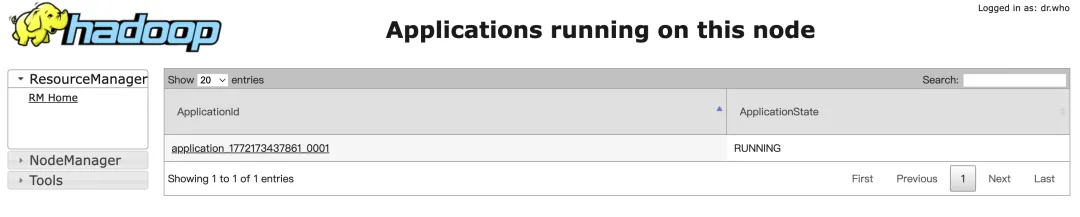

trdsql[8]
❝挺喜欢去了解一些开源的个人项目的,这些项目的开发动力,往往就是一个很实际,也很需要的小功能
❞
负责数据开发的同学,经常需要做的事情就是把用户、领导需要的数据,设计开发 SQL,再导出成表格发给别人
对于这类需求的标准答案,需要通过 BI ( Business Intelligence ) 软件( 比如 superset ),在页面操作一下导出数据
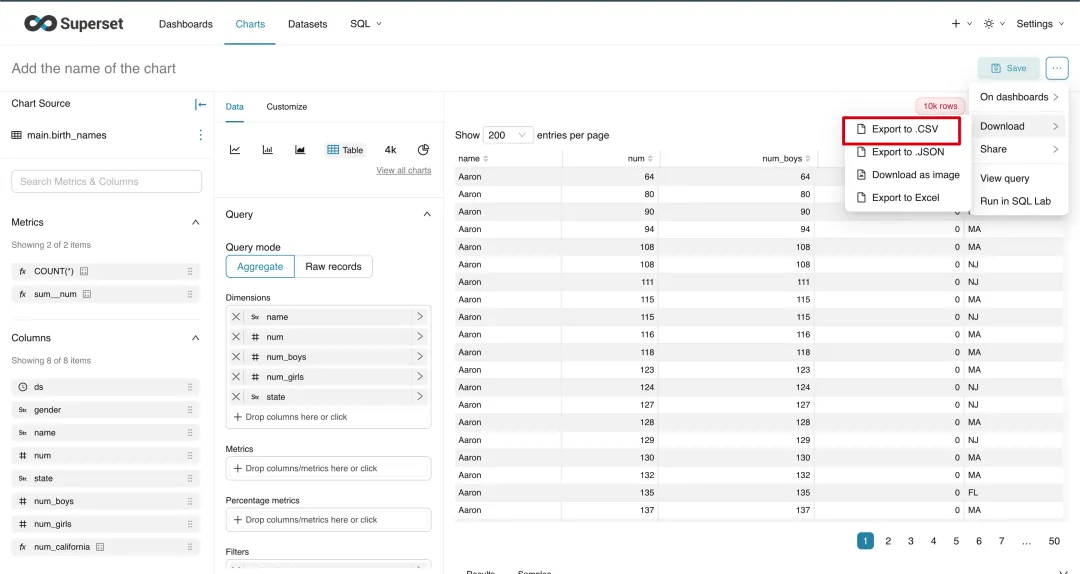
在 superset 导出 csv 文件
但假如没有装这种软件,又只给你一个 linux 命令行的环境,应该怎么操作呢
使用 mysql 指令直接执行 SQL 导出,这个思路是最直接的。先把数据查出来,再把默认的 tab 分隔符替换成 csv 默认的逗号分隔
# mysql 指令直接导出 excel 方式mysql -h127.0.0.1 -P3306 -uroot -p123456 -e "select * from table_name limit 10" | tr '\t' ',' > /tmp/test.csv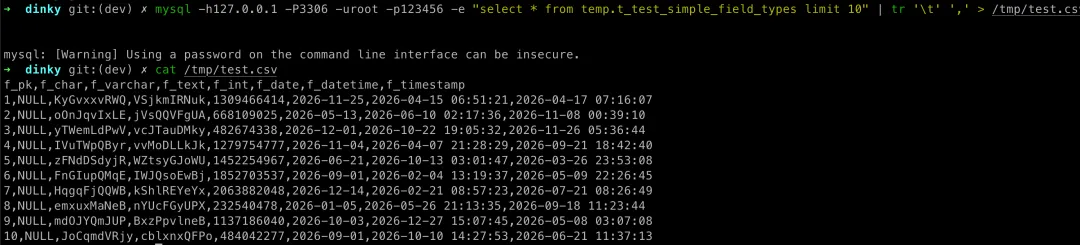
方法是很方便,也只需要安装 mysql client 原生客户端。但缺点就是如果数据本身就有逗号,由于 csv 默认是用逗号作为分隔符的,导出的 csv 就不能默认正常显示了,如下
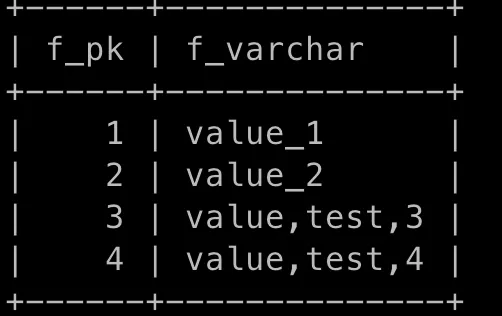
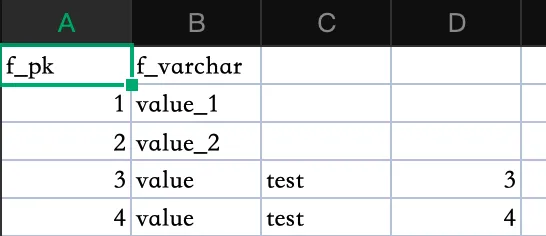
那有没有其他工具可以解决这种特殊字符带来的导数问题呢
没费很多时间,我找到了 trdsql ,它是 go 开发的一个工具,主要功能就是数据查询、导入或导出工具,导出格式支持 csv, json, yaml,支持查询 mysql, postgresql 和 sqlite 数据库
我们安装试用看看它是怎么解决这个问题的
安装
# 通过源码安装git clone https://github.com/noborus/trdsqlmakemake install导出 csv
这次我们用 trdsql,同样是导出刚才有逗号的数据,看看效果:
trdsql -driver mysql -dsn "root:123456@tcp(127.0.0.1:3306)/temp" -ocsv "select * from table_name limit 10" > /tmp/test.csv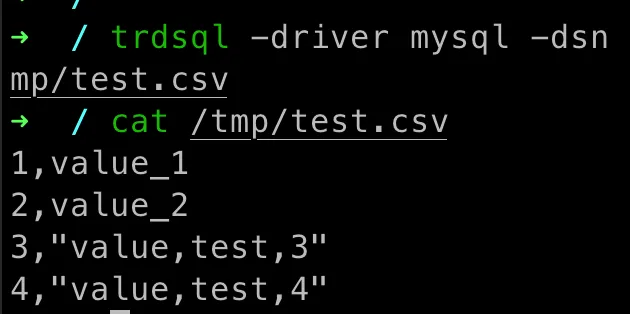
这么就能看出来它是如何解决问题的了: csv 在列数据中有逗号时,给整列加上双引号,最后的 csv 就能正常展示(属 csv 数据展示规范)
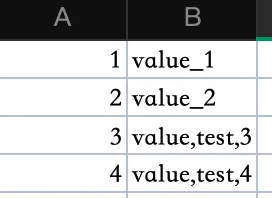
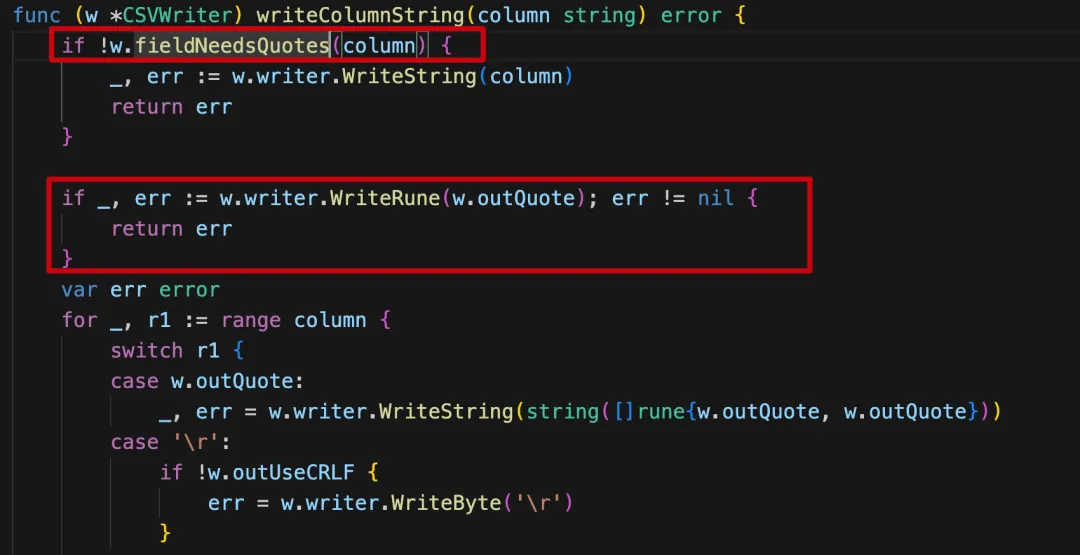
稍微看看源码是怎么实现的,就是在每一列导出之前,先判断内容中是否含有逗号,有就在列两边加上双引号,没有就不做任何字符处理直接展示
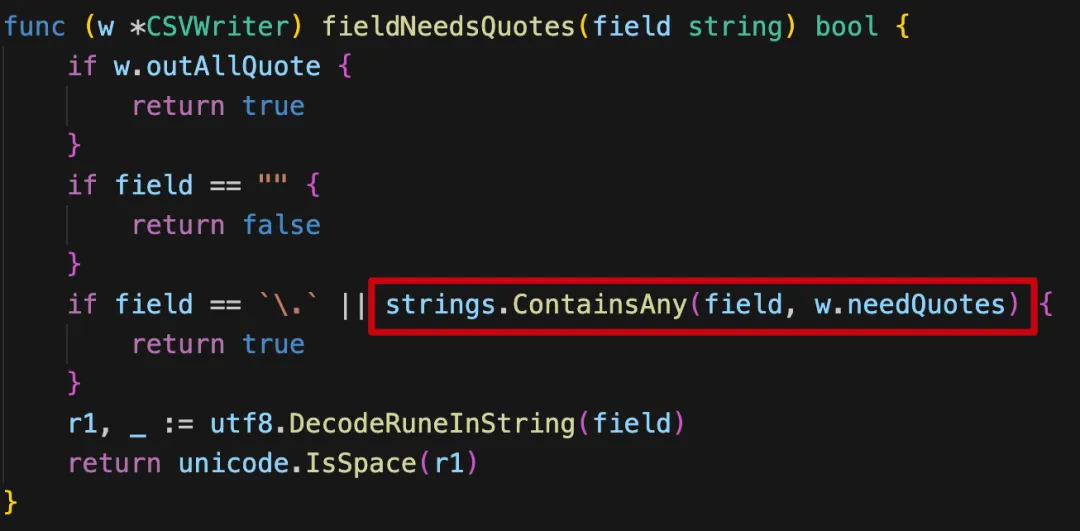
从 csv 查询数据
trdsql 还有一个主打功能,是可以像在数据库查询那样,在 csv 等文件中直接通过 SQL 查数据
这里我从 kaggle[9] 下载了一个畅销书榜单数据集
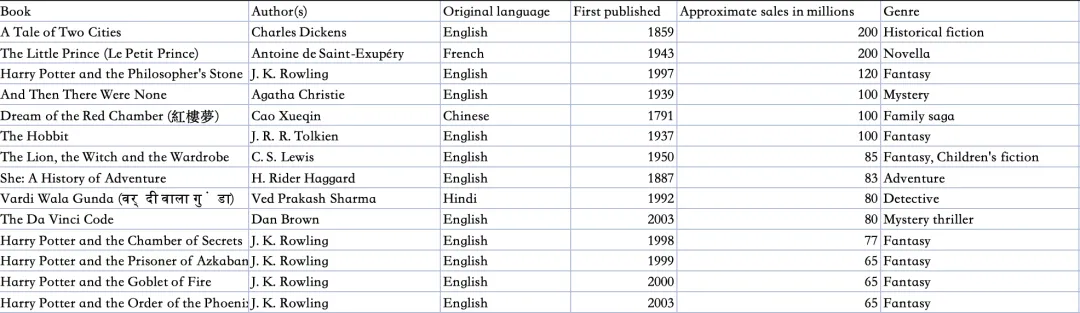
如果我们想筛选出哈利波特相关的书籍,就像在 mysql 那样写个简单的 SQL 就能查出来了
# c1, c2 表示列名trdsql "SELECT * from /tmp/best-selling-books.csv where c1 like 'Harry Potter%' limit 10"# 使用 sqlite3_ext ( https://github.com/multiprocessio/go-sqlite3-stdlib ),支持更多函数trdsql -driver sqlite3_ext "SELECT * from /tmp/best-selling-books.csv where c1 REGEXP 'Harry Potter.*' limit 10"
它的原理也容易理解,并不是对 csv 做了什么“魔法”让它能跑 SQL 了,而是先将 csv 导入到 sqlite 这个轻量且使用最广泛的数据库中(数据默认放在内存),再通过 SQL 去查,方法就这样简单又巧妙
k3s[10]
❝一个把复杂系统全部打包到最简单的服务的设计,就像是在纪念碑谷中,看到了整个世界的样子
❞
在之前对 jupyter on k8s 博客的介绍中我们用到了 minikube,它对于 windows 或者 mac,需要先启动虚拟机再启动容器的系统来说,是运行 k8s 最快捷的方式了
那在 linux 启动 k8s, 是否还有更快的选择呢?
当然有的,这就是把 k8s 的所有核心组件都打包到一个二进制文件中的 k3s
安装
以在 ubuntu 安装单点 k8s 为例,执行一行安装脚本就可以安装
# 一键安装curl -sfL https://get.k3s.io | sh -# 执行脚本前,可通过环境变量设置 k8s 的版本,以及安装路径export INSTALL_K3S_CHANNEL=v1.28.15+k3s1export INSTALL_K3S_EXEC="--data-dir /opt/data/k3s"
安装完成后,k8s 集群还不是马上可用状态,还需稍微等待镜像下载完成。不过 kubectl 相关的指令可以开始跑了,k3s 本身内置 kubectl ,只需在指令之前加上 k3s
# 查看集群所有 podk3s kubectl get pods -A
当然如果发现镜像一直无法下载,可以参考这篇博客[11],将镜像下载地址改成国内地址
所有 pod 都启动完成后效果:

官方脚本一键安装的 k3s 通过系统的 systemctl 来管理,因此 k3s 的启停方式如下
systemctl stop k3ssystemctl start k3ssystemctl restart k3s应用: 运行 flink 集群和任务
既然 k8s 装好了,我们就趁热打铁,来看如何在 k8s 上跑 flink 集群和应用吧
我们会用到 flink 官方提供的 flink-kubernetes-operator[12],通过它我们可以直接在 k8s 上部署 flink 相关的组件,包括 jobmanager 、taskmanager 和 flink 应用等
# 部署 cert-manager , flink operator 需要用到k3s kubectl apply -f https://github.com/jetstack/cert-manager/releases/download/v1.18.2/cert-manager.yaml# helm: k3s 没有内置 helm 指令,需要手动安装curl -fsSL -o get_helm.sh https://raw.githubusercontent.com/helm/helm/main/scripts/get-helm-4chmod 700 get_helm.sh./get_helm.sh# 通过 helm 安装和启动 flink operator# 指定 k8s 配置为 k3s 配置,否则 helm 无法访问 k8sexport KUBECONFIG=/etc/rancher/k3s/k3s.yamlhelm repo add flink-operator-repo https://downloads.apache.org/flink/flink-kubernetes-operator-1.14.0helm install flink-kubernetes-operator flink-operator-repo/flink-kubernetes-operator等待 flink operator 启动完成后,我们就可以通过 FlinkDeployment 来完成 flink 服务和应用的部署了:

# vim flink_deploy.yamlapiVersion:flink.apache.org/v1beta1kind:FlinkDeploymentmetadata:name:basic-examplespec:image:flink:1.20.1-java11flinkVersion:v1_20flinkConfiguration:taskmanager.numberOfTaskSlots:"2"serviceAccount:flinkjobManager:resource:memory:"2048m"cpu:1taskManager:resource:memory:"2048m"cpu:1job:jarURI:local:///opt/flink/examples/streaming/StateMachineExample.jarparallelism:2upgradeMode:statelessargs:["--error-rate","0.1"]以上配置将启动一个 jobmanager 和一个 taskmanager,即一个 flink 集群最简化的部署架构,再提交 flink examples 目录下的 StateMachineExample 任务,这个任务会持续采集机器信息,以 error-rate 设置的概率生成 alert ,每条 alert 会在标准输出中打印出来
# 使 FlinkDeployment 生效k3s kubectl apply -f flink_deploy.yaml于是我们只需等待容器 basic-example 启动完成,就可以通过 kubectl port-forward 和 kubectl logs 指令,查看 flink 集群和任务的运行情况了
# 暴露 jobmanager 端口k3s kubectl port-forward service/basic-example-rest 8081 --address='0.0.0.0'# 查看 basic-example pod 的日志,即 StateMachineExample 任务日志k3s kubectl logs -l app=basic-example -l component=taskmanager --tail=10 -f访问 http://机器ip:8081 即可查看 flink 原生页面
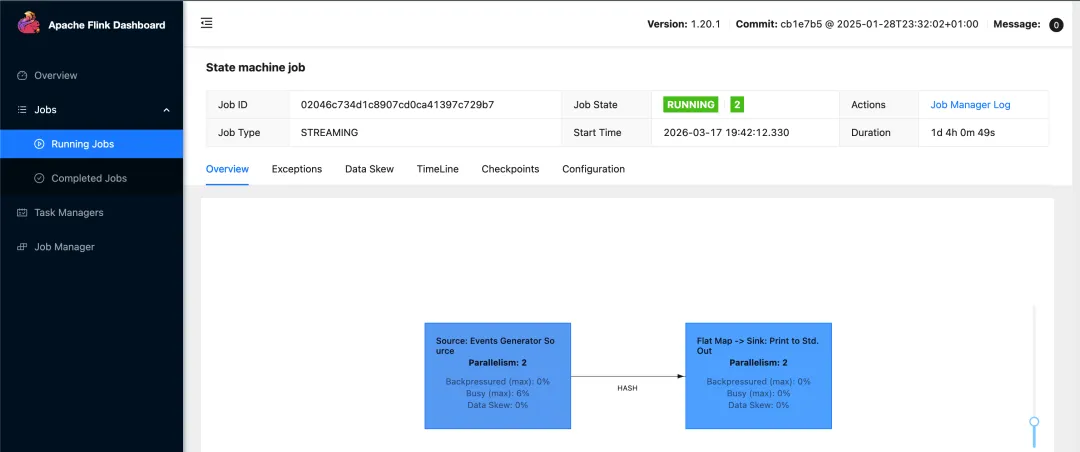
最后是查看 StateMachineExample 任务输出的日志,可通过 kubectl logs 或者直接在 jobmanager 页面中查看
k3s kubectl logs -l app=basic-example -l component=taskmanager --tail=10 -f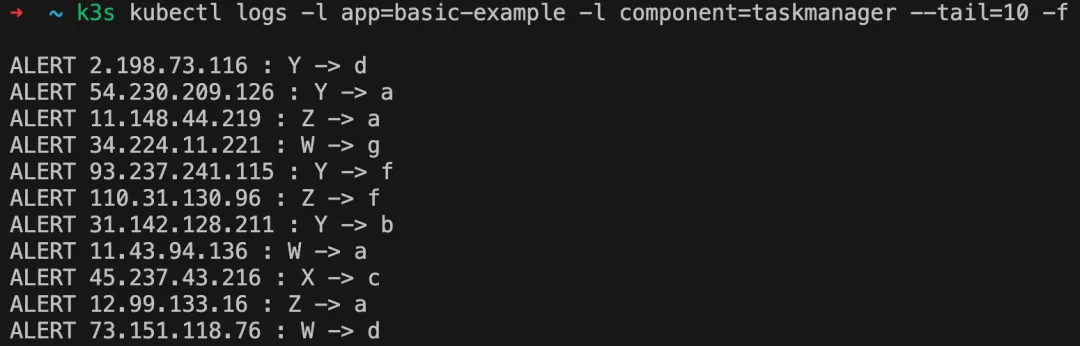
python
❝服务在发展,编程核心中的语言也在发展,类似 go install ,现在新语言都流行把项目安装成可以直接运行的二进制文件,而 python 早在 python2 就有类似的这种运行方式了,就是 -m + 模块名
❞
python 是一门越用越觉得强大的语言,最近笔者发现的,就是结合内置或者另外安装的模块,可以让 python 看起来只是跑代码的指令,摇身一变成小工具或者小服务
http.server
当我们想把一台服务器的文件或者目录共享到其他目录时,通常会用到 httpd 、 samba 等文件共享服务。当然它们都是常驻服务,需要安装,也会自动添加到系统服务管理(systemd)目录中,那有无更轻量更快捷的开启文件共享的方式呢?
当然有的,这就是 python 的 http.server
(注:http.server 更像是 httpd,作为文件下载服务器,其他节点可通过 wget 从主服务器下载文件,但不能上传,samba 的功能则会更多一点)
python3 -m http.server 7777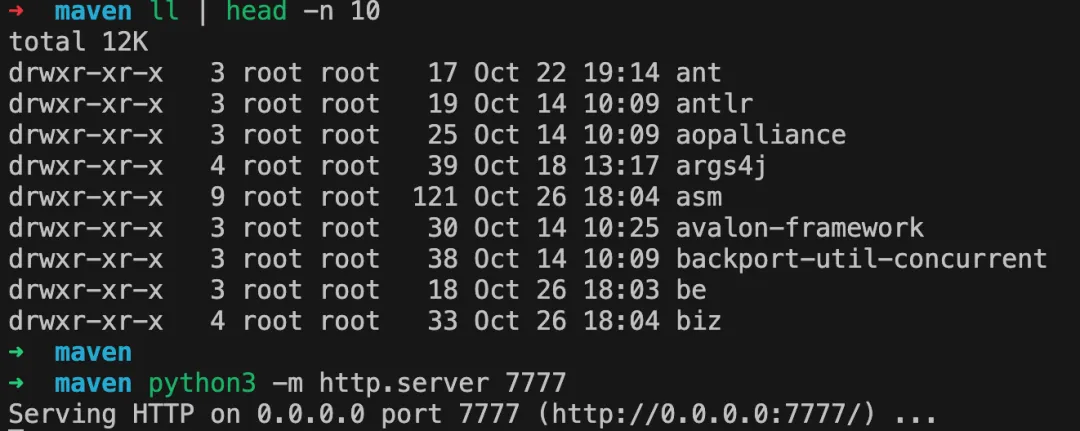
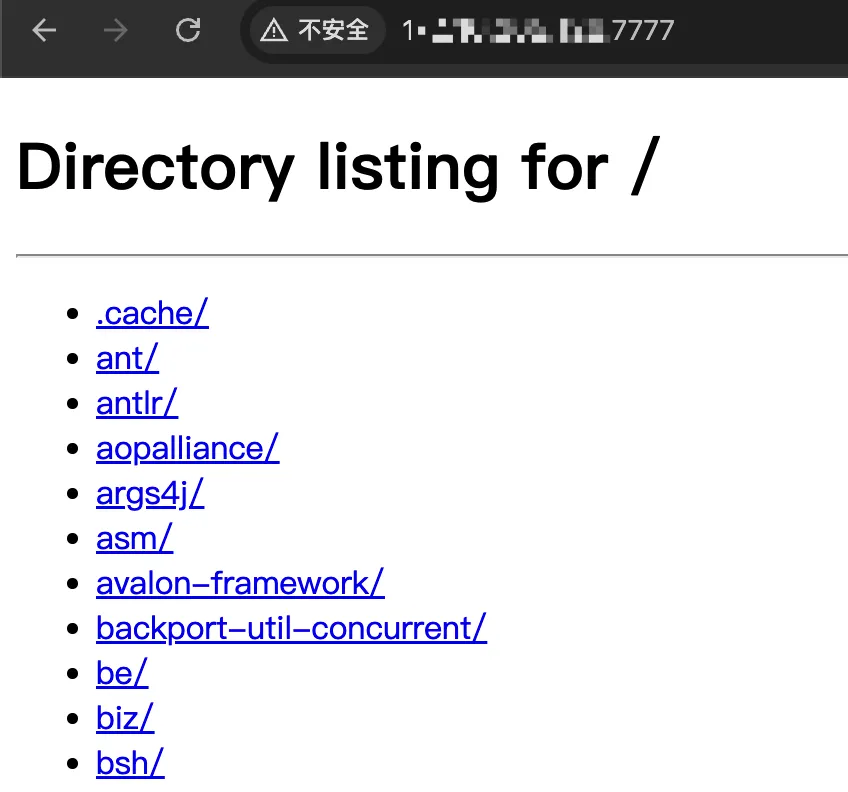
json.tool
json.tool 可以对 json 文件做简单的格式标准化
# 格式化python -m json.tool test.json# 2个空格格式化python -m json.tool --indent 2 test.json# 不加换行符,key 之间按一个空格分隔python -m json.tool --no-indent test.json# 完全紧凑,中间没有空格的排版python -m json.tool --compact test.json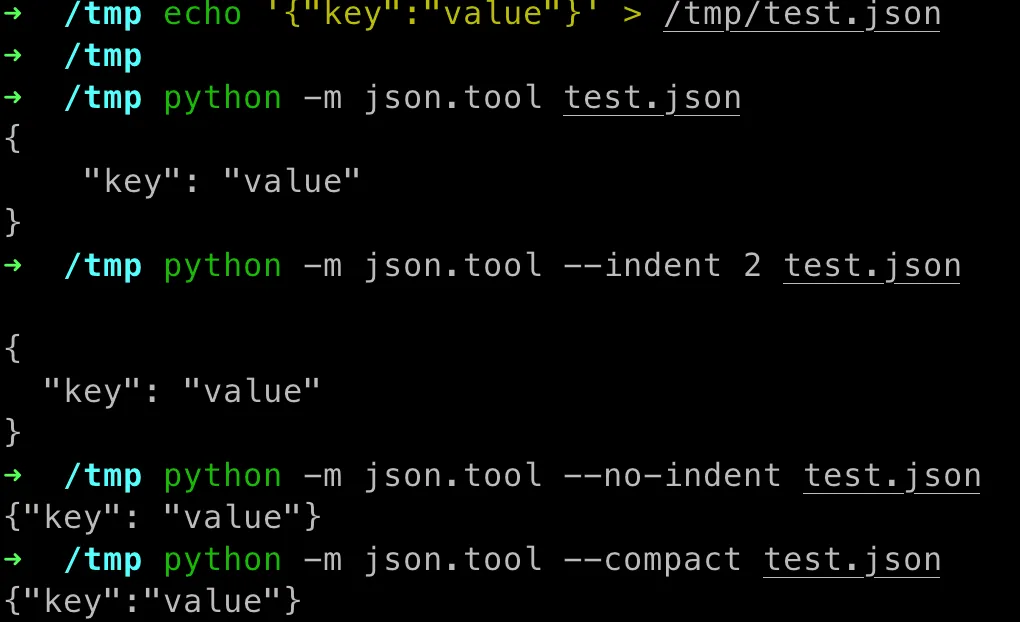
httpbin[13]
访问一个网站、调用一个 api 服务接口,都需要发起 HTTP 请求,背后涉及到 HTTP 请求的方法、请求头、请求 body 、返回状态等等各种信息,怎样可以系统地了解这些参数怎么传递,会有什么效果呢? httpbin可以帮上忙
httpbin 是 python 官方社区维护的,在本地可运行包含非常多 HTTP 请求类型场景的服务。想了解 HTTP 接口的各种用法,用它是非常合适的。当然除了本地部署,你也可以直接调用官方地址 https://httpbin.org
安装方式很简单,就是安装一个 pip 依赖
pip install httpbin==0.10.2python -m httpbin.core --host 0.0.0.0 --port 9000先来看它提供的 swagger 界面,包含所有接口的功能介绍:
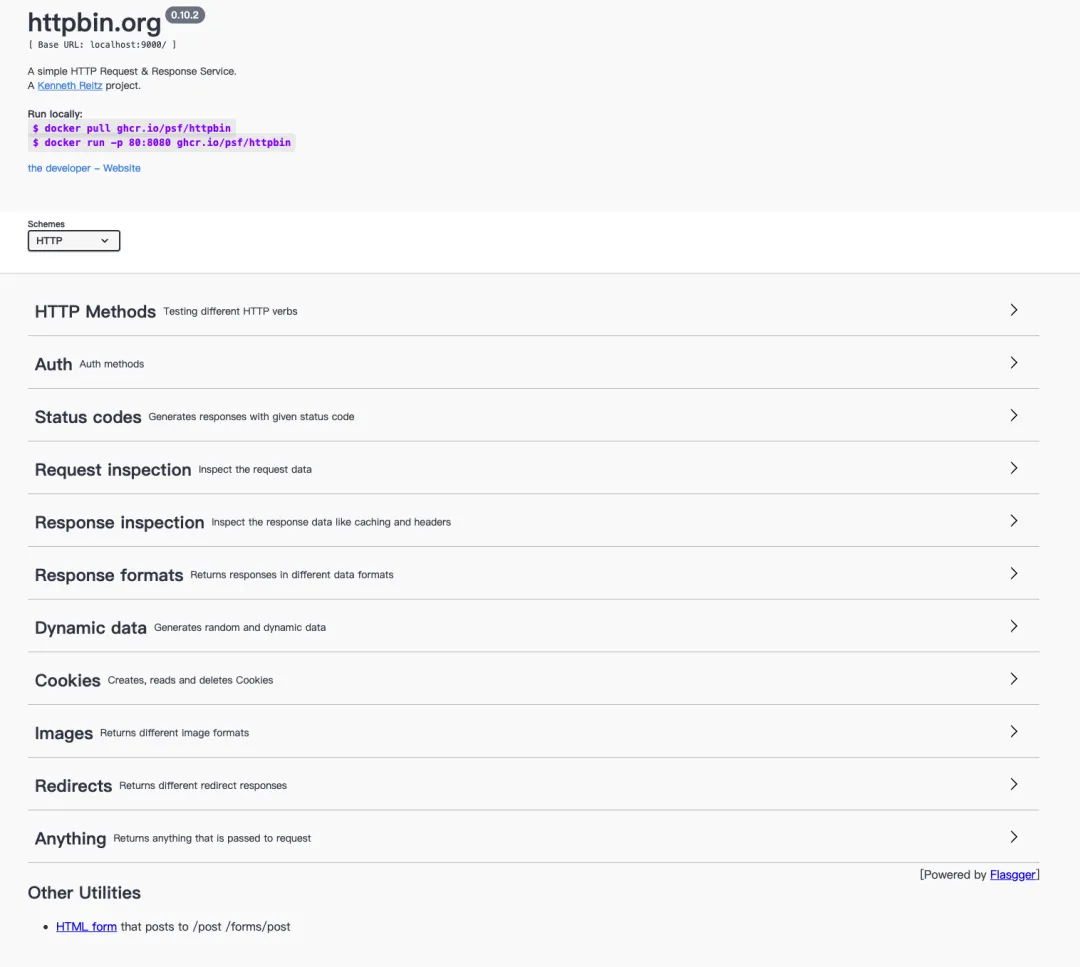
简单整理概括一下各个场景:
HTTP Methods: 基本的请求方法: GET、POST、PUT、DELETE 等
Auth: 提供 basic-auth 、 bearer 和 digest auth 加密算法
Status codes: 可以返回任意 HTTP 状态码
Request inspection: 获取请求头中的参数,如 ip 、 user-agent
Response inspection: 和服务端返回数据缓存相关的方法,可以了解到 Cache-Control 和 If-None-Match 请求头的用法
Response formats: 设置返回格式类型,如 json、xml,以及 robots.txt 禁止爬虫访问网站的机制
Dynamic data: 通过参数动态控制 reponse、返回延迟等,可用于客户端的接口超时测试
Cookies: cookie 查询、设置、删除相关方法
Images: 下载图片,通过 Accept 参数设置图片的 png, jpeg 等格式
Redirects: 跳转请求,对应 response header 中的 Location
Anything: 返回请求中的所有参数
以下是对每一种类型接口,都用 curl 或者浏览器直接访问的方式:
# HTTP Methods: POST 请求curl -i -X POST --data {"k": "v"} http://localhost:9000/post# Auth 通过 basic auth 调用认证接口curl -i --user user:pass http://localhost:9000/basic-auth/user/pass# Status codes: 返回 400curl -i http://localhost:9000/status/400# Request inspection: 获取访问来源 ip,即本地 ipcurl http://localhost:9000/ip# Response inspection: 模拟在 If-Match 和 cache key 不匹配的时候会返回 412curl -i -H "If-Match: cache2" http://localhost:9000/etag/cache1# Response formats: 返回 json 格式数据curl http://localhost:9000/json | python -m json.tool --indent 2# Dynamic data: 设置接口延迟、文件下载curl http://localhost:9000/delay/5curl -LO http://localhost:9000/drip?numbytes=400&duration=5&delay=1&code=200# Cookies: 设置、删除指定 cookiehttp://localhost:9000/cookies/set/k1/v1http://localhost:9000/cookies/delete?k1=v1# Images: 下载 pngcurl -H "Accept: image/png" http://localhost:9000/image --output image.png# Redirects: 跳转( curl 默认允许重定向最多 50 次)curl -i -L http://localhost:9000/absolute-redirect/10# Anything: 打印请求中的所有参数curl -i http://localhost:9000/anything如此多的场景,可以说总有一种,可以在你开发微服务接口,需要调试的时候用得上
patch
❝看一个大型的开源项目代码,有时会感到无从下手,这时从一个 commit 的代码变化去看细节是不错的思路,那么代码变更在哪里可以看呢?
❞
在看 bigtop 项目源码的时候,发现它是通过 patch 的方式去解决 hadoop 开源版本的编译错误问题的
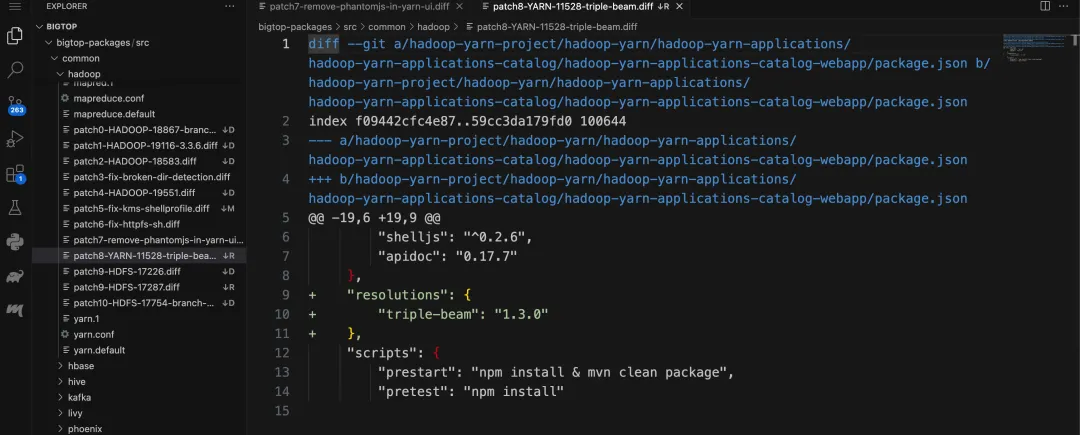
如上图,它会记录 hadoop 当前版本 ( 如 3.3.6 ) 本身的一些代码缺陷,以及为了适配在不同操作系统的编译问题的修复代码 。在执行 ./gradlew hadoop-pkg 构建 hadoop 安装包时,会先执行 patch 指令,将所有的 patch 文件应用到 hadoop 源码中,然后再执行 mvn install 进行编译
后来笔者在整理我自己维护的 hadoop 编译脚本的时候,遇到 yarn-ui 编译失败的问题( 对应 BIGTOP-3526[14] ),也试着通过 patch 的方式记录编译问题的修复文件,发现一用就离不开了,这种机制可以保证我每次重新编译 hadoop 都能成功
问题来了,如何生成 patch 文件,把代码变更记录进去呢?
还是以 flink cdc 项目为例: flink cdc 从 3.3 版本升级到最新代码后,将会支持对 starrocks 字段修改的更多语法,在 github 上我们看到代码的变更是这种效果
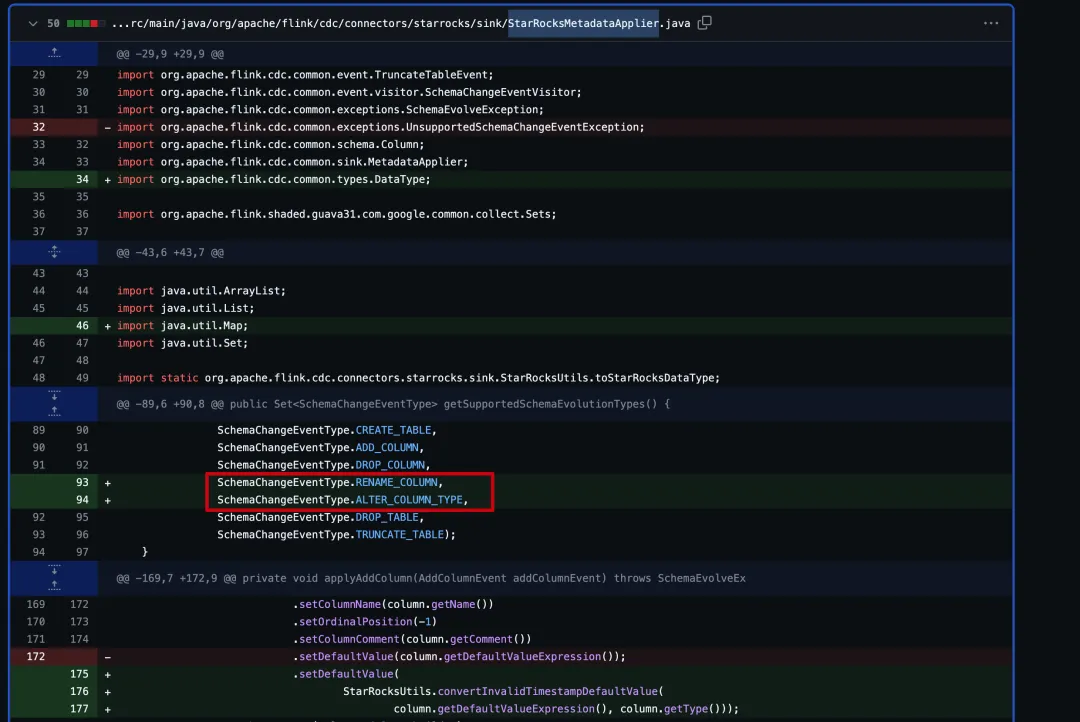
下面是将这些变更代码,生成到 patch 文件,以及如何将 patch 又作用到旧代码,生成修复后的代码的过程
# 先准备 StarRocksMetadataApplier.java 在 3.3 分支和最新分支的代码文件wget https://raw.githubusercontent.com/apache/flink-cdc/refs/heads/master/flink-cdc-connect/flink-cdc-pipeline-connectors/flink-cdc-pipeline-connector-starrocks/src/main/java/org/apache/flink/cdc/connectors/starrocks/sink/StarRocksMetadataApplier.java -O StarRocksMetadataApplier_master.javawget https://raw.githubusercontent.com/apache/flink-cdc/refs/tags/release-3.3.0/flink-cdc-connect/flink-cdc-pipeline-connectors/flink-cdc-pipeline-connector-starrocks/src/main/java/org/apache/flink/cdc/connectors/starrocks/sink/StarRocksMetadataApplier.java -O StarRocksMetadataApplier_3.3.java# 生成单个文件的变更 patch 文件diff -u StarRocksMetadataApplier_3.3.java StarRocksMetadataApplier_master.java > StarRocksMetadataApplier_3_3_to_master.patch# 验证 patch 是否可以生效,不会真正修改文件patch -p0 --dry-run StarRocksMetadataApplier_3.3.java < StarRocksMetadataApplier_3_3_to_master.patch# 应用 patch 变更patch -p0 /tmp/StarRocksMetadataApplier_3.3.java < StarRocksMetadataApplier_3_3_to_master.patch# 应用 patch 变更,并备份原始文件为 StarRocksMetadataApplier_3.3.java.bakpatch -p0 -b -z .bak StarRocksMetadataApplier_3.3.java < StarRocksMetadataApplier_3_3_to_master.patch# 回退patch -p0 -R StarRocksMetadataApplier_3.3.java < StarRocksMetadataApplier_3_3_to_master.patchpatch 文件内容如下图,和 github 上显示的效果基本一致
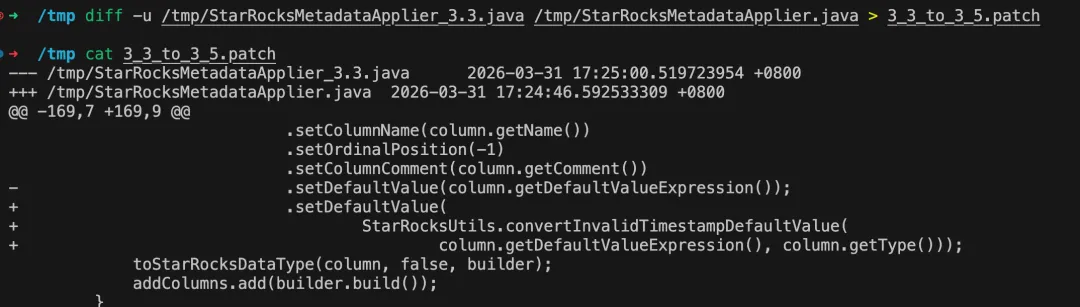
htop[15]
遇到服务器发生 cpu 和内存告警的时候,之前我第一反应是先用 top 指令,查找占用资源最多的进程,但 top 展示信息的直观程度稍弱 ,htop 完善了这一点
# 安装 htop: 直接通过安装器安装yum -y install htopapt -y install htop# 打开 htophtop# 设置 htop 延迟, 30 表示每 3s 刷新htop -d 30# 查看指定用户的进程htop -u postgres# 只查看指定 pidhtop -p 2318# sort by key# 根据 cpu 使用率倒序htop -s UTIME# 根据内存使用量排序htop -s M_RESIDENT# 隐藏进程树shift + H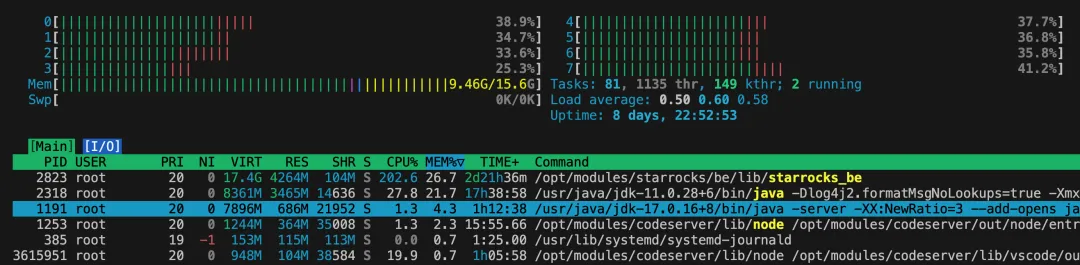
就使用体验来看,htop 对比 top 明显体验上有优势
进程的完整路径有打印
内存的使用率有一个进度条的展示
能看到每个核心的使用率
可以用鼠标滚动翻阅进程
总结
传统经典的操作系统,真的是怎么学都不会觉得无聊,总有新东西可以学
在慢慢写这篇博客的同时,也逐渐感受到,这些 linux 指令之间并不是孤立个体,而是可以串在一起形成整个开发工具链,成为个人开发最好的帮手
python 的 json.tool 支持简单的 json 格式化,继续了解的话,我们还可以用到更强大的 jq
HDFS 的 WordCount 是大数据的 hello world,同样,flink 也有一个 WordCount example, 有了 k3s, 我们就可以很方便地启动整个 flink 集群和跑应用了
最后,也期待今年可以对一些指令有更深入的使用体会,有机会再更新这个系列
Reference
scc: https://github.com/boyter/scc
[2]maven-repository-class-search: https://jar-download.com/maven-repository-class-search.php
[3]examples-data: https://github.com/apache-superset/examples-data
[4]coreutils: https://www.gnu.org/software/coreutils
[5]s3cmd: https://github.com/s3tools/s3cmd
[6]minicluster: https://hadoop.apache.org/docs/stable/hadoop-project-dist/hadoop-common/CLIMiniCluster.html
[7]distributed shell: https://hadoop.apache.org/docs/stable/hadoop-yarn/hadoop-yarn-site/WritingYarnApplications.html
[8]trdsql: https://github.com/noborus/trdsql
[9]kaggle: https://www.kaggle.com/datasets/drahulsingh/best-selling-books
[10]k3s: https://github.com/k3s-io/k3s
[11]这篇: https://www.cnblogs.com/amsilence/p/18744998
[12]flink-kubernetes-operator: https://github.com/apache/flink-kubernetes-operator
[13]httpbin: https://github.com/psf/httpbin
[14]BIGTOP-3526: https://github.com/apache/bigtop/pull/759
[15]htop: https://github.com/htop-dev/htop

