作为Python小白,我是如何上手LangGraph的?
- 2026-06-28 13:54:40
作为Python小白,我是如何上手LangGraph的?欢迎点击下方👇关注我,记得星标哟~ 文末会有重磅福利赠送 State、Node、Edge、Chat Models、Messages、Tools之类的。 但在AI时代,完全不用这么麻烦!自己做一个最小的实验,不等完美,先跑起来。 比如,当我想要运行一个构建聊天机器人的这段代码: 




至此,可以正确运行的案例有了,并且逐行进行了代码解释,是不是学起来so easy了? 最后,推荐一下我的Java面试辅导和职场付费咨询。 面试辅导:托尼学长的一对一Java面试辅导说明书 职场付费咨询:托尼学长的一对一职场付费咨询说明书 也欢迎扫下方👇🏻二维码加我微信,备注【面试题】,免费领取价值199元的Java高频场景面试题详解。 
不得不感慨,AI时代学习一个新技术简直太容易了,信息差、准入门槛真的低了太多太多!
就拿学习Python技术栈的LangGraph来说,古法编程的程序员怎么学呢?当然是先学习一阵子Python语法对吧,然后再学习LangGraph的各种概念,比如:
from langchain_openai import ChatOpenAIfrom langgraph.graph import StateGraph, MessagesState, START, END# 定义节点:调用 LLM ## 或者使用装饰器定义节点 @node,后面可以直接 graph.add_node(chatbot)def chatbot(state: MessagesState):return {"messages": [ChatOpenAI(model="gpt-5-nano").invoke(state["messages"])]}# 构建图graph = StateGraph(MessagesState)graph.add_node("chatbot", chatbot)graph.add_edge(START, "chatbot")graph.add_edge("chatbot", END)# 编译并运行图。这个 app 就是我们构建的图,有时候也会命名为 graphapp = graph.compile()res = app.invoke({"messages": [("user", "你好,请用一句话介绍 LangGraph")]})print(res["messages"][-1].content)(res["messages"]) ## 查看完整的对话信息# 🎨 可视化图结构from IPython.display import Image, displaydisplay(Image(app.get_graph().draw_mermaid_png()))
但我的只有通义千问的api key,我就打开豆包,把上面的这段代码、提示词(将这段代码改为可以通过阿里千问运行的代码),以及相关配置信息输入进去。
随后,豆包就给我直接返回一段融合了阿里千问大模型的代码。
from langchain_anthropic import ChatAnthropic # 兼容阿里千问的入口from langgraph.graph import StateGraph, MessagesState, START, END# 初始化 阿里云千问 LLM(你提供的配置)llm = ChatAnthropic(model="qwen3.5-plus",api_key="sk-05bd3dxxxxxxxxxxxxxxxxxxxxxxx",base_url="https://dashscope.aliyuncs.com/apps/anthropic",max_tokens=1024)# 定义节点:调用 LLMdef chatbot(state: MessagesState):return {"messages": [llm.invoke(state["messages"])]}# 构建图graph = StateGraph(MessagesState)graph.add_node("chatbot", chatbot)graph.add_edge(START, "chatbot")graph.add_edge("chatbot", END)# 编译并运行图app = graph.compile()res = app.invoke({"messages": [("user", "你好,请用一句话介绍 LangGraph")]})print(res["messages"][-1].content)# 可视化图结构try:from IPython.display import Image, displaydisplay(Image(app.get_graph().draw_mermaid_png()))except Exception:print("可视化需要在 Jupyter/Notebook 环境中运行")
并且告诉我这些信息:
随后我在代码运行过程中,出现了这样一个警告,于是我把信息重新发给豆包。
豆包又重新给我生成了一段新的代码,改动点是最上面的两行代码。
import warningswarnings.filterwarnings("ignore") # 屏蔽无关警告from langchain_anthropic import ChatAnthropicfrom langgraph.graph import StateGraph, MessagesState, START, END# 阿里云千问 LLMllm = ChatAnthropic(model="qwen3.5-plus",api_key="sk-05bd3d14XXXXXXXXXxxxxxxxxxx",base_url="https://dashscope.aliyuncs.com/apps/anthropic",max_tokens=1024)# 定义节点def chatbot(state: MessagesState):return {"messages": [llm.invoke(state["messages"])]}# 构建图graph = StateGraph(MessagesState)graph.add_node("chatbot", chatbot)graph.add_edge(START, "chatbot")graph.add_edge("chatbot", END)# 运行app = graph.compile()res = app.invoke({"messages": [("user", "你好,请用一句话介绍 LangGraph")]})print(res["messages"][-1].content)
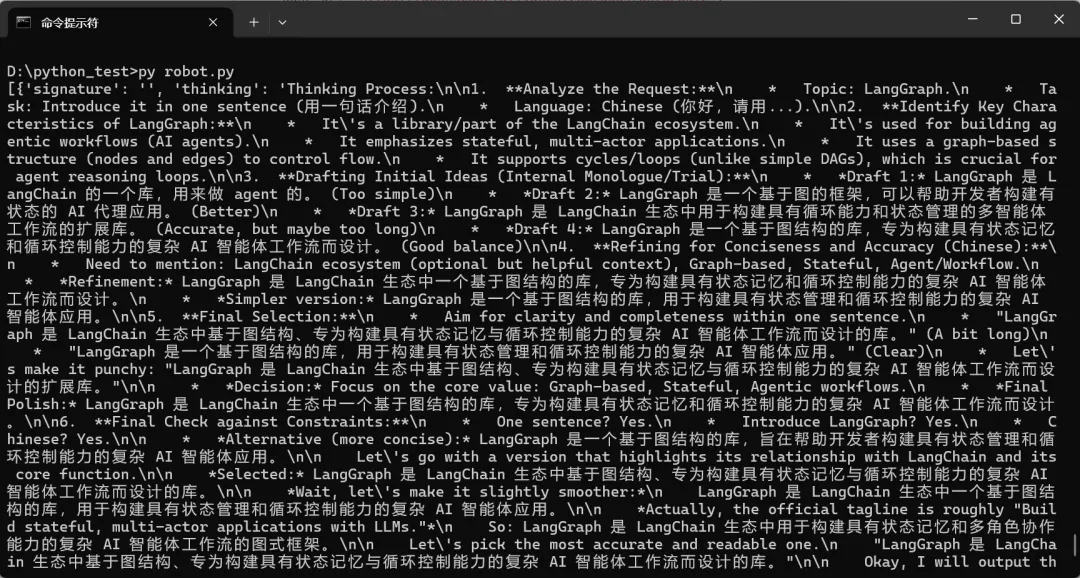
程序可以运行了,但给我输出了一大段内容,感觉还是不太对。
于是我就把这些输出内容发给豆包。
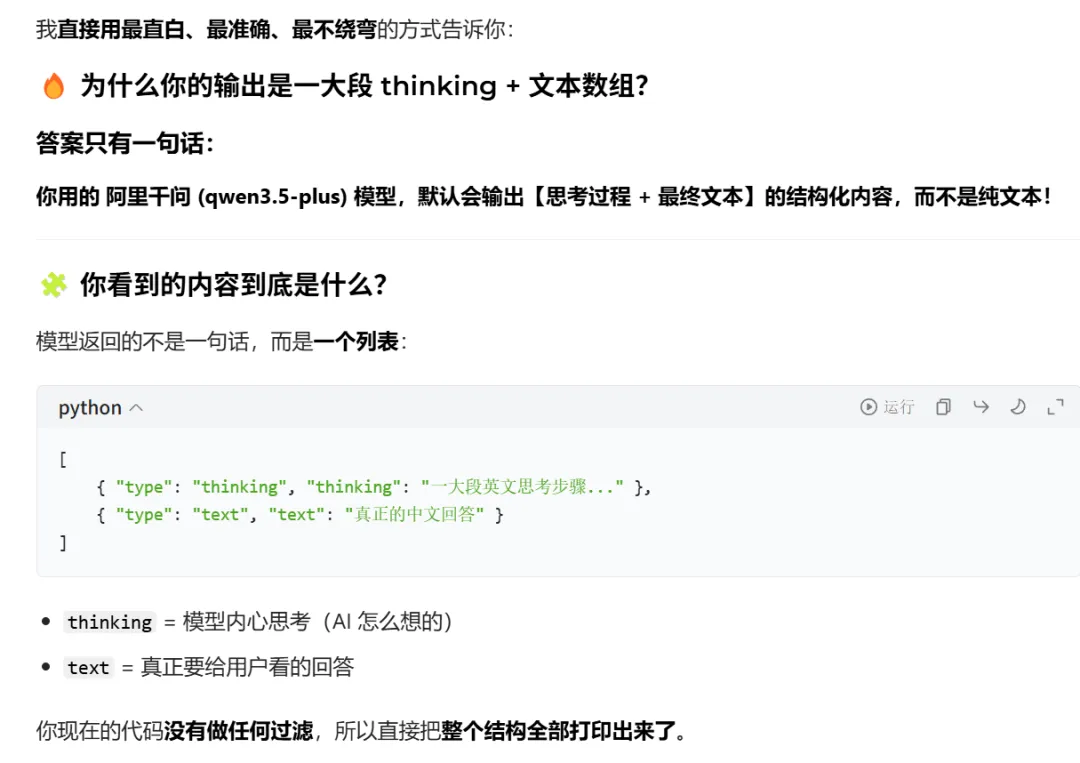
豆包给我的解释是:
然后又给我生成了一次代码,甚至在代码中很贴心地用注释告诉我,改动的几行代码在什么位置。
import warningswarnings.filterwarnings("ignore")from langchain_anthropic import ChatAnthropicfrom langgraph.graph import StateGraph, MessagesState, START, ENDllm = ChatAnthropic(model="qwen3.5-plus",api_key="sk-05bd3d14XXXXXXXXXxxxxxxxxxx",base_url="https://dashscope.aliyuncs.com/apps/anthropic",max_tokens=1024)# ===================== 【唯一改动:在这里】 =====================def chatbot(state: MessagesState):response = llm.invoke(state["messages"])# 只提取 text 回答,过滤 thinkingif isinstance(response.content, list):for item in response.content:if item["type"] == "text":response.content = item["text"]breakreturn {"messages": [response]}# =================================================================graph = StateGraph(MessagesState)graph.add_node("chatbot", chatbot)graph.add_edge(START, "chatbot")graph.add_edge("chatbot", END)app = graph.compile()res = app.invoke({"messages": [("user", "你好,请用一句话介绍 LangGraph")]})print(res["messages"][-1].content)from IPython.display import Image, displaydisplay(Image(app.get_graph().draw_mermaid_png()))
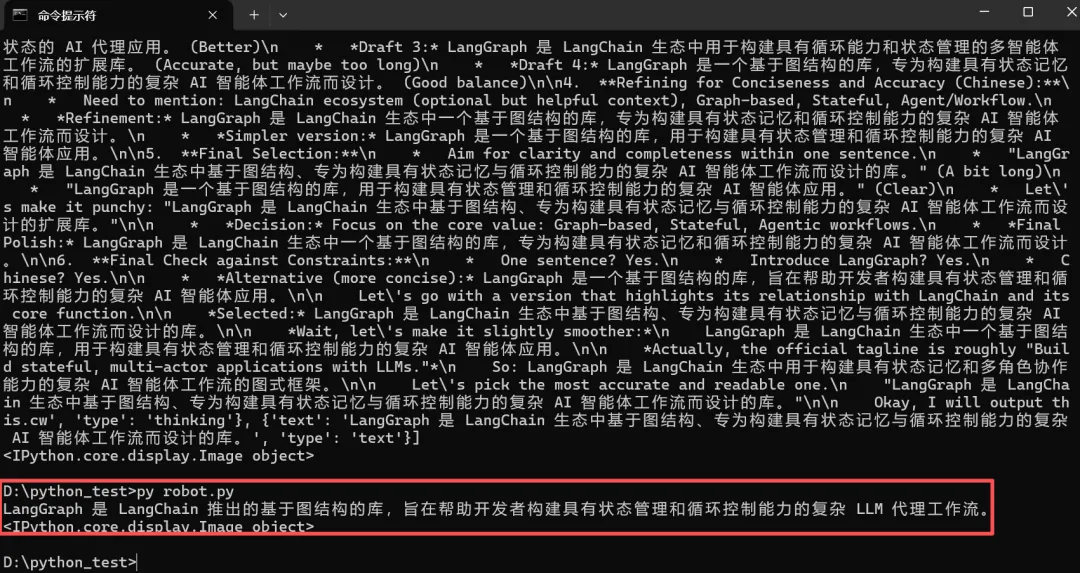
我将代码复制粘贴后,再次执行,这次总算输出了正常的结果。
也就是说,哪怕是一个一行Python代码都不懂的小白,仅仅借助于豆包,在不到20分钟的时间里,就完成了LangGraph更换大模型、消除警告,以及输出正确执行结果的事情。
这在非AI时代完全是不可想象的事情,估计得查各种资料,各种调试才行。
最后,既然代码可以运行出来了,接下来就需要了解每行代码是什么意思了,我再次给豆包输入指令。
豆包给我返回的结果,果然每行代码都戴上了注释。
# 1. 导入警告库,并且忽略无关的警告信息import warningswarnings.filterwarnings("ignore")# 2. 导入阿里千问需要的包from langchain_anthropic import ChatAnthropic# 3. 导入 LangGraph 画图、状态、开始结束节点from langgraph.graph import StateGraph, MessagesState, START, END# 4. 创建阿里千问大模型(你自己的配置)llm = ChatAnthropic(model="qwen3.5-plus", # 模型名称api_key="sk-xxx", # 你的API Keybase_url="https://dashscope.aliyuncs.com/apps/anthropic", # 阿里接口地址max_tokens=1024 # 最大生成长度)# 5. 定义一个节点:chatbot(AI 大脑在这里)def chatbot(state: MessagesState):# 6. 调用模型,拿到返回结果response = llm.invoke(state["messages"])# ===================== 【核心:过滤思考过程】 =====================# 7. 判断:如果模型返回的是一个列表(thinking + text)if isinstance(response.content, list):# 8. 遍历列表内容for item in response.content:# 9. 找到真正的回答(type = text)if item["type"] == "text":# 10. 把内容替换成纯文本response.content = item["text"]break # 找到就退出# ==================================================================# 11. 返回处理后的结果return {"messages": [response]}# 12. 创建流程图graph = StateGraph(MessagesState)# 13. 添加节点:chatbotgraph.add_node("chatbot", chatbot)# 14. 开始 → chatbotgraph.add_edge(START, "chatbot")# 15. chatbot → 结束graph.add_edge("chatbot", END)# 16. 编译流程图,变成可运行的程序app = graph.compile()# 17. 运行程序,传入问题res = app.invoke({"messages": [("user", "你好,请用一句话介绍 LangGraph")]})# 18. 打印最终结果print(res["messages"][-1].content)# 19. 画出流程图(在 Jupyter 里显示)from IPython.display import Image, displaydisplay(Image(app.get_graph().draw_mermaid_png()))
我是托尼学长,前美团高级技术经理,前新东方技术总监,曾就职于京东和去哪儿网,现自由职业中。
本文来自网友投稿或网络内容,如有侵犯您的权益请联系我们删除,联系邮箱:wyl860211@qq.com 。

