现在,我们站在 Linux 操作系统内核的 “上帝视角”,撕开容器的所有封装:
Docker 容器从来都不是一个独立的操作系统实例,它的本质,就是宿主机上一组被内核特殊约束的进程(进程组)。
一、容器的底层真身--宿主机的一个普通进程罢了
当你在终端执行一条
docker run --rm -it ubuntu:22.04 bash
命令后,看似启动了一个完整的容器环境,底层发生的核心动作,其实和我们在 Linux 上启动一个普通应用程序没有本质区别。
Docker 引擎并不会凭空创建一个新的操作系统,它最终会通过底层的容器运行时(runc),调用 Linux 内核最基础的clone()系统调用,创建出一个或多个进程。这个进程,和我们宿主机上运行的 nginx、ssh、bash 进程,在操作系统内核的进程树上,拥有完全平等的地位。
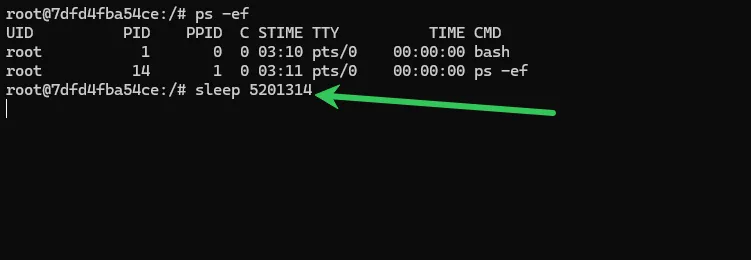
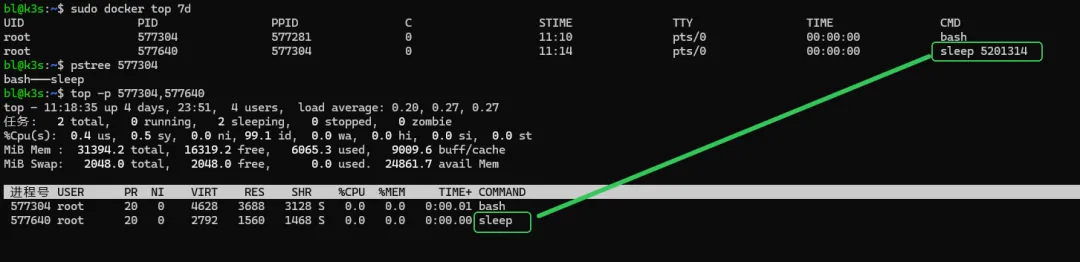
如果我们在宿主机上执行ps -ef、top命令,完全可以清晰看到容器内运行的所有进程 —— 包括容器内的 PID 1 进程,以及它衍生出的所有子进程。容器内的进程,在宿主机上都有对应的、真实的全局 PID,只是在容器内部,被内核做了一层 “PID 映射”,让它误以为自己是容器内的 1 号进程。我们通过下面的操作看看:
容器内查看进程
宿主机查看对应的映射进程
先在容器内跑一个简单的定时进程,卡住终端
宿主机查看
从内核的视角来看,容器里的进程,和宿主机上的普通进程,共享同一个 Linux 内核,共用同一套 CPU、内存、磁盘等硬件资源,没有任何本质的不同。
二、Namespace 的隔离魔法--为什么进程能 “伪装” 成独立操作系统?
既然容器就是普通进程,为什么它能表现得像一个独立的操作系统?为什么在容器内看不到宿主机的其他进程、看不到宿主机的文件系统、拥有自己独立的 IP 地址?
这一切的核心,都来自 Linux 内核原生提供的Namespace(命名空间)技术。Namespace 的核心作用,就是给进程套上一层 “单向滤镜”:让进程只能看到被 Namespace 限定的资源范围,从而构建出一个完全隔离的运行视图。
当 Docker 启动容器时,会为这个进程组创建一整套全新的 Namespace,包括:
PID Namespace
隔离进程 ID 空间。容器内的进程只能看到同 Namespace 内的进程,无法感知宿主机和其他容器的进程,同时让容器内的入口进程获得 PID 1 的身份,模拟出 init 系统进程的效果。Mount Namespace
隔离文件系统挂载点。容器内的进程看到的根目录/,是 Docker 镜像提供的 rootfs,而非宿主机的根文件系统。它可以随意修改自己的文件系统,不会影响宿主机和其他容器。Network Namespace
隔离网络栈。每个容器都拥有独立的虚拟网卡、IP 地址、路由表、端口监听规则,实现了网络层面的完全隔离,这也是容器端口映射的底层基础。UTS Namespace
隔离主机名与域名。容器可以拥有自己独立的主机名,就像一个独立的服务器。IPC Namespace
隔离进程间通信。容器内的进程只能在同 Namespace 内进行信号量、共享内存等通信,无法跨容器和宿主机直接交互。User Namespace
隔离用户与用户组。可以将容器内的 root 用户,映射为宿主机上的普通非特权用户,极大降低了容器突破隔离的安全风险。正是这一整套 Namespace,给普通进程穿上了 “独立操作系统” 的外衣,让它误以为自己独占了一整套运行环境。
三、光有隔离还不够,Cgroup -- 资源限制的底层基石
Namespace 解决的是 “进程能看到什么” 的隔离问题,
而Linux 内核的Cgroup(控制组) 技术,则解决的是“进程能用多少” 的资源限制问题。
一个普通的 Linux 进程,可以无限制地占用宿主机的 CPU、内存、磁盘 IO 等资源,极端情况下甚至会耗尽宿主机资源,导致其他进程崩溃。而容器作为一个生产环境可用的运行单元,必须有严格的资源上限。
Docker 在启动容器时,会将容器的整个进程组,加入到一个预先配置好的 Cgroup 组中。在这个 Cgroup 里,我们可以精准限制:容器最多能使用多少 CPU 核心、最大可用内存上限、磁盘 IO 的读写速率、网络带宽等等。(默认情况下,Docker容器不会做任何资源限制,需要显示指定)
我们可通过以下命令,实时查看容器资源占用
内核会严格监控这个 Cgroup 内所有进程的资源使用情况,一旦触及上限,就会通过内核机制进行限制、限流,甚至直接 OOM 终止进程。这就保证了容器之间不会互相抢占资源,实现了资源层面的安全隔离。
四、更精确的定义:容器是一个进程组
一个容器对应一个进程,这个说法并不完全准确。严格来说,一个运行中的 Docker 容器,对应的是一个进程组。
容器启动时,镜像定义的 Entrypoint 或 CMD 指令,会作为容器的入口进程,也就是容器内的 PID 1 进程。
如果这个进程后续创建了子进程 —— 比如 Nginx 的 master 进程 fork 出多个 worker 进程、Java 进程创建出多个业务线程对应的轻量级进程,这些子进程都会被自动纳入同一个 Namespace 和 Cgroup 中,归属到这个容器的进程组里。
容器的生命周期,也和这个进程组完全绑定:当容器的 PID 1 入口进程退出时,整个进程组内的所有子进程,都会被 Linux 内核自动回收或终止,容器也就随之进入停止状态。这也是为什么容器设计理念中,一直强调 “一个容器一个主进程” 的核心原因。
五、最终总结,看容器本质
站在 Linux 操作系统内核的上帝视角,看Docker 容器本质,就是一组被 Namespace 做了运行视图隔离、被 Cgroup 做了资源上限约束的 Linux 进程组;它的本质就是宿主机上的普通进程,创建的开销和启动一个进程完全一致,启动速度可以达到毫秒级。
所有关于容器的特性、优势、甚至安全风险,都可以从这个本质出发,找到最底层的答案。
毕竟,
它所有的能力,皆源自内核原生的累积;
它所有的封装,终归于进程约束的隔离。