这篇文章用"Excel 的 Python 版"来类比 pandas,带你从零掌握 DataFrame 的读取、筛选、排序、新增列、处理空值,最后完成一个完整的数据清洗实战。不需要任何数学背景。
前言
作为前端开发者,你每天处理的数据格式是 JSON。但在数据分析领域,最常见的是 CSV(表格数据)——就像一个 Excel 表格,每行是一条记录,每列是一个字段。
pandas 是 Python 数据处理的核心库。你可以把它理解为:可编程的 Excel + 超强的 SQL 查询能力。
不需要数学背景,不需要统计知识——本篇只讲前端开发者最能用上的数据处理操作:读、筛、排、改、清、存。
安装:
pip install pandas
一、DataFrame 是什么?
DataFrame 是 pandas 的核心数据结构,本质上就是一张带有行列索引的二维表格。
import pandas as pd
# 从字典创建 DataFrame(类比 JS 的对象数组)
data = {
"name": ["Alice", "Bob", "Charlie", "Diana"],
"age": [28, 30, 25, 32],
"city": ["北京", "上海", "广州", "深圳"],
"salary": [18000, 22000, 15000, 28000]
}
df = pd.DataFrame(data)
print(df)
输出:
name age city salary
0 Alice 28 北京 18000
1 Bob 30 上海 22000
2 Charlie 25 广州 15000
3 Diana 32 深圳 28000
最左边的 0, 1, 2, 3 是行索引(index),类似数组下标。列名就是字典的键。
二、读取数据
实际工作中数据来源于文件,不是手动创建的:
import pandas as pd
# 读取 CSV 文件
df = pd.read_csv("employees.csv")
# 读取 CSV(指定编码,中文文件常用)
df = pd.read_csv("employees.csv", encoding="utf-8")
# 读取 Excel 文件(需要额外安装 openpyxl)
df = pd.read_excel("report.xlsx", sheet_name="Sheet1")
# 从 JSON 文件读取
df = pd.read_json("data.json")
# 从 Python 列表/字典创建
records = [
{"name": "Alice", "score": 95},
{"name": "Bob", "score": 87}
]
df = pd.DataFrame(records)
读取后先快速了解数据:
print(df.shape) # (行数, 列数),如 (1000, 8)
print(df.dtypes) # 每列的数据类型
print(df.head(5)) # 查看前 5 行
print(df.tail(3)) # 查看最后 3 行
print(df.info()) # 完整概览:行数、列名、类型、非空数量
print(df.describe()) # 数值列的统计摘要(均值、最大值等)
三、选取数据:列和行
3.1 选取列
# 选取单列(返回 Series,类似一维数组)
names = df["name"]
print(names)
# 选取多列(返回 DataFrame)
subset = df[["name", "salary"]]
print(subset)
类比 JS:
// JS 对象数组取某几列
const subset = employees.map(({ name, salary }) => ({ name, salary }))
3.2 选取行:loc 和 iloc
# iloc:按行号选取(integer location,类比数组下标)
print(df.iloc[0]) # 第 0 行
print(df.iloc[0:3]) # 前 3 行(切片)
print(df.iloc[-1]) # 最后一行
# loc:按行标签选取(label based)
print(df.loc[0]) # 标签为 0 的行(默认标签等于行号)
# iloc 选行和列
print(df.iloc[0, 2]) # 第 0 行第 2 列的值
print(df.iloc[:, [0, 3]]) # 所有行,第 0 和第 3 列
四、筛选数据(条件过滤)
这是 pandas 最常用的操作,类比 JS 的 .filter():
df = pd.DataFrame({
"name": ["Alice", "Bob", "Charlie", "Diana", "Eve"],
"age": [28, 30, 25, 32, 27],
"city": ["北京", "上海", "北京", "深圳", "上海"],
"salary": [18000, 22000, 15000, 28000, 19000]
})
# 单条件筛选
young = df[df["age"] < 30]
print(young)
# Alice, Charlie, Eve
# 多条件筛选:& 表示 and,| 表示 or
# 注意:每个条件必须用括号括起来!
bj_young = df[(df["city"] == "北京") & (df["age"] < 30)]
print(bj_young)
# Charlie(北京且年龄<30)
high_salary_or_beijing = df[(df["salary"] > 20000) | (df["city"] == "北京")]
# isin():类比 JS 的 includes()
selected_cities = df[df["city"].isin(["北京", "上海"])]
# str.contains():模糊匹配(类比 JS 的 includes/indexOf)
# 假设有 description 列
# df[df["description"].str.contains("Python")]
对比 JS:
// JS 等价写法
const young = employees.filter(e => e.age < 30)
const bjYoung = employees.filter(e => e.city === "北京" && e.age < 30)
五、排序
# 按单列排序(升序)
df_sorted = df.sort_values("salary")
# 按单列排序(降序)
df_sorted = df.sort_values("salary", ascending=False)
# 按多列排序:先按城市升序,同城市内按薪资降序
df_sorted = df.sort_values(
["city", "salary"],
ascending=[True, False]
)
print(df_sorted)
对比 JS:
employees.sort((a, b) => b.salary - a.salary)
六、新增和修改列
# 新增列(向量化运算,不需要循环!)
df["annual_salary"] = df["salary"] * 12
# 基于条件新增列(类比 JS 的 map + 三元表达式)
df["level"] = df["salary"].apply(
lambda x: "高薪" if x >= 20000 else "普通"
)
# 用 np.where 更高效(类比三元运算符)
import numpy as np
df["is_senior"] = np.where(df["age"] >= 30, True, False)
# 修改列的值
df["city"] = df["city"].str.replace("北京", "BJ") # 字符串替换
# 修改列名
df = df.rename(columns={"name": "员工姓名", "salary": "月薪"})
# 删除列
df = df.drop(columns=["annual_salary"])
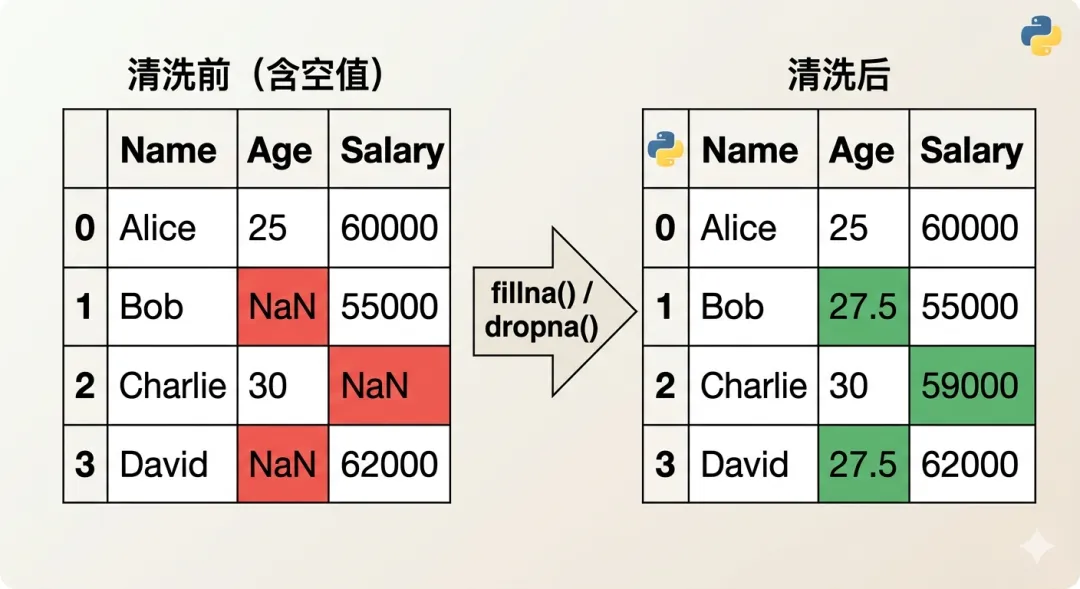
七、数据清洗:处理空值
真实数据几乎都有缺失值,这是数据清洗的核心工作:
import pandas as pd
import numpy as np
# 创建含空值的数据
df = pd.DataFrame({
"name": ["Alice", "Bob", None, "Diana"],
"age": [28, None, 25, 32],
"salary": [18000, 22000, None, 28000]
})
print(df)
# name age salary
# 0 Alice 28.0 18000.0
# 1 Bob NaN 22000.0
# 2 None 25.0 NaN
# 3 Diana 32.0 28000.0
# 检查空值
print(df.isnull()) # 每个格子是否为空(True/False)
print(df.isnull().sum()) # 每列的空值数量
print(df.isnull().any()) # 每列是否有空值
# 删除含空值的行(默认任意列有空就删)
df_clean = df.dropna()
# 只删除所有列都是空的行
df_clean = df.dropna(how="all")
# 只在特定列有空时才删除
df_clean = df.dropna(subset=["name"])
# 填充空值
df["age"] = df["age"].fillna(df["age"].mean()) # 用平均值填充
df["salary"] = df["salary"].fillna(0) # 用 0 填充
df["name"] = df["name"].fillna("未知") # 用字符串填充
df["salary"] = df["salary"].fillna(method="ffill") # 用前一个值填充
八、分组统计(groupby)
groupby 是 pandas 最强大的功能之一,类比 SQL 的 GROUP BY,或 JS 里用 reduce 做分组统计:
df = pd.DataFrame({
"name": ["Alice", "Bob", "Charlie", "Diana", "Eve"],
"department": ["技术", "产品", "技术", "设计", "产品"],
"salary": [18000, 22000, 25000, 16000, 20000],
"performance":["A", "B", "A", "C", "B"]
})
# 按部门分组,计算平均薪资
dept_avg = df.groupby("department")["salary"].mean()
print(dept_avg)
# department
# 产品 21000.0
# 技术 21500.0
# 设计 16000.0
# 按部门分组,同时计算多个统计量
dept_stats = df.groupby("department")["salary"].agg(["mean", "max", "min", "count"])
print(dept_stats)
# 多列分组
perf_dept = df.groupby(["department", "performance"])["salary"].mean()
对比 JS(实现同样效果需要更多代码):
// JS 分组统计
const grouped = employees.reduce((acc, e) => {
if (!acc[e.department]) acc[e.department] = []
acc[e.department].push(e.salary)
return acc
}, {})
const avgByDept = Object.fromEntries(
Object.entries(grouped).map(([dept, salaries]) => [
dept,
salaries.reduce((a, b) => a + b, 0) / salaries.length
])
)
pandas 的 groupby 一行搞定,JS 需要写一大段。
九、导出数据
# 导出为 CSV
df.to_csv("output.csv", index=False, encoding="utf-8-sig")
# index=False:不把行索引写入文件
# encoding="utf-8-sig":Excel 打开 CSV 不乱码
# 导出为 Excel
df.to_excel("output.xlsx", index=False, sheet_name="数据")
# 导出为 JSON
df.to_json("output.json", orient="records", force_ascii=False)
# orient="records":每行是一个 JSON 对象,[{...}, {...}]
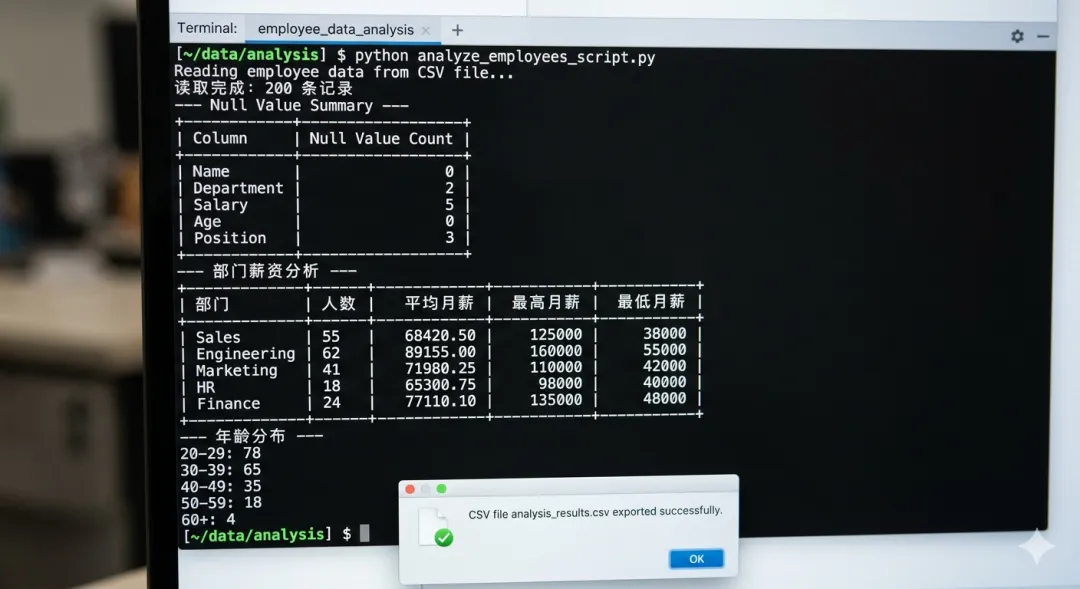
十、综合实战:员工数据清洗报告
import pandas as pd
import numpy as np
def analyze_employees(filepath: str) -> pd.DataFrame:
"""读取员工数据,清洗并生成分析报告"""
# 1. 读取数据
df = pd.read_csv(filepath, encoding="utf-8")
print(f"✅ 读取完成:{df.shape[0]} 条记录,{df.shape[1]} 个字段")
# 2. 查看数据质量
null_counts = df.isnull().sum()
print(f"\n空值统计:\n{null_counts[null_counts > 0]}")
# 3. 数据清洗
df["salary"] = df["salary"].fillna(df["salary"].median()) # 用中位数填充薪资
df["department"] = df["department"].fillna("未分配") # 填充部门
df = df.dropna(subset=["name", "age"]) # 删除姓名/年龄为空的行
# 4. 数据加工
df["age"] = df["age"].astype(int)
df["annual_salary"] = df["salary"] * 12
df["age_group"] = pd.cut(
df["age"],
bins=[0, 25, 30, 35, 100],
labels=["≤25岁", "26-30岁", "31-35岁", "35岁以上"]
)
# 5. 生成统计报告
print("\n=== 部门薪资分析 ===")
dept_analysis = df.groupby("department").agg(
人数=("name", "count"),
平均月薪=("salary", "mean"),
最高月薪=("salary", "max"),
最低月薪=("salary", "min")
).round(0).sort_values("平均月薪", ascending=False)
print(dept_analysis)
print("\n=== 年龄分布 ===")
print(df["age_group"].value_counts().sort_index())
# 6. 导出结果
df.to_csv("employees_cleaned.csv", index=False, encoding="utf-8-sig")
print("\n✅ 清洗后数据已保存到 employees_cleaned.csv")
return df
if __name__ == "__main__":
result = analyze_employees("employees.csv")
小结
| | |
|---|
| pd.read_csv() | Papa.parse() |
| df[df["col"] > x] | arr.filter() |
| df[["col1", "col2"]] | arr.map(({c1,c2}) => ({c1,c2})) |
| df["new"] = df["col"] * 2 | arr.map(x => ({...x, new: x.col * 2})) |
| df.sort_values("col") | arr.sort() |
| df.groupby("col").mean() | arr.reduce(...) |
| df.fillna() | |
| df.to_csv() | Papa.unparse() |
3 个新手必踩的坑:
- 多条件筛选时每个条件必须用括号括起来:df[(cond1) & (cond2)],不能用 and
- df["col"] = value 是修改/新增列,df[df["col"] > x] 是筛选行,看清楚
- to_csv 中文文件用 encoding="utf-8-sig" 而不是 utf-8,否则 Excel 打开乱码
下篇预告
第 15 篇:Python 爬虫入门:用 requests + BeautifulSoup 抓取网页数据
数据从哪来?很多时候要自己抓。下一篇用前端最熟悉的 DOM 操作来类比 BeautifulSoup 的 HTML 解析——querySelector 的 Python 版本,用起来超顺手。
 10个月宝宝每天需要喝多少奶粉?
10个月宝宝每天需要喝多少奶粉?
