在日常数据清洗与分析中,是选择 Python 的 Pandas 还是 SQL 更高效?当 Pandas 的内存操作模型遇到海量数据时,效率的边界在哪里?
- 2026-07-02 21:27:23
在数据分析中,工具选择往往不只是效率问题,更是计算范式、数据模型与工程结构之间的综合权衡。数据清洗与分析与数据规模、数据来源、计算资源分配、团队协作方式乃至分析目标深度相关。在这一背景下,Python生态中的 Pandas 与数据库语言 SQL 常常被并列讨论,但这种对比若仅局限在“哪个更快”这一层面,显然过于粗糙。
Pandas代表一种以内存为中心的数据操作模型,其核心是灵活的数据结构与丰富的函数接口;SQL则体现声明式查询思想,其关键在于将“做什么”交由数据库优化器转化为执行计划。在实践中,两者在不同问题结构下展现出不同的计算优势。问题的关键并不是“选哪一个”,而是“在何种约束条件下,哪种范式更契合任务本身”。
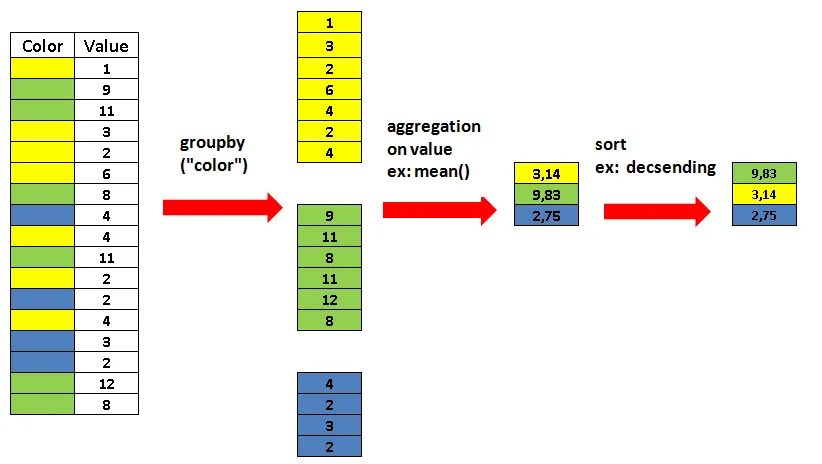
当数据规模从几千条增长到数亿条,当计算从简单筛选转向复杂特征构造,当单人分析演进为团队协作时,工具选择的影响将被逐步放大。那么,在日常数据清洗与分析任务中,Pandas 与 SQL 究竟如何进行理性选择?是否可以形成一套可复用的决策框架?
1. Pandas 与 SQL 的计算模型本质
在数据科学与分析实践中,理解工具的计算模型本质是构建高效分析流程的前提。Pandas 与 SQL 的差异不仅仅在语法层面,更深刻地体现在它们对数据的抽象方式、计算执行路径以及资源调度逻辑上。选择合适工具的关键在于识别任务的内在特性,并匹配最契合的计算范式。
1.1 数据结构与计算范式
Pandas 的核心数据结构是 DataFrame,它是一种二维表格结构,类似于电子表格,但在内存中以列为基础存储。每一列的数据类型可以独立定义,并且支持高效的向量化操作。其计算模型具有以下特点:
内存中心(In-Memory):所有数据需加载到内存中,内存容量直接限制数据规模。 过程式操作(Procedural):每条操作指令按照代码顺序执行,依赖用户明确的操作流程。 灵活自定义(Customizable Logic):支持任意 Python 函数、lambda 表达式以及复杂条件逻辑,用户可以对数据进行精细化处理。
可以用数学符号形式表达 Pandas 对数据的操作:设数据集为 ,操作序列为 ,则最后结果为:
这里每一步都依赖前一步结果,体现了严格的操作顺序性与内存依赖。
相比之下,SQL 所依赖的是关系模型(Relational Model),其数据通常存储在磁盘或分布式存储系统中,通过表(Table)、行(Row)、列(Column)构成关系。SQL 的核心特性包括:
声明式查询(Declarative Querying):用户描述“做什么”,而非“怎么做”,执行顺序由数据库优化器决定。 磁盘/分布式存储为中心(Disk/Distributed Storage):数据无需一次性加载到内存,通过索引、分页和分区实现高效访问。 优化执行计划(Execution Plan):数据库通过解析 SQL 语句生成查询树,使用成本模型(cost-based model)优化操作顺序和算法选择。
可以抽象地表示 SQL 的查询:
其中 SQL 优化器会选择最优执行路径 ,将声明式查询转化为物理执行操作:
这一过程意味着 SQL 更关注全局数据结构与访问策略,而非用户显式指定每一步操作。
从计算范式角度对比:
这一对比显示,Pandas 更适合需要复杂逻辑、精细化操作的分析任务,而 SQL 更擅长对大规模数据进行高效聚合、筛选和连接。
1.2 执行机制差异
深入分析执行机制,可以理解工具性能差异的根源。
1.2.1 Pandas 执行过程
Pandas 的操作遵循“逐步执行—生成中间结果”的流程:
数据加载:从 CSV、Excel、Parquet 等文件加载到内存中:
按顺序执行操作:每个操作都应用于当前 DataFrame:
生成中间结果:每步操作可能生成新的 DataFrame,增加内存占用。
这一执行机制的优点是可调控性强,缺点是对于大数据量时,内存压力和重复计算代价显著。
1.2.2 SQL 执行过程
SQL 查询的执行机制则更复杂,典型流程如下:
解析语句(Parsing):将 SQL 文本解析为抽象语法树(AST)。 生成逻辑计划(Logical Plan):表示查询逻辑,如 SELECT、WHERE、JOIN 等操作顺序。 代价估计(Cost Estimation):基于数据统计信息评估不同执行策略的代价。 物理优化(Physical Optimization):选择具体算法和顺序,如 Hash Join、Merge Join 或索引扫描。 执行(Execution):数据库引擎按优化计划读取数据,进行计算。
示例 SQL 查询:
优化器可能生成执行计划:
先筛选 A 中 value > 10的记录然后使用 Hash Join 将结果与 B 连接 最后输出结果
这种优化机制使 SQL 在处理数千万甚至数亿条记录时,依赖索引和分区策略可以显著降低 I/O 和计算成本。可以用公式表达 SQL 的执行时间:
而 Pandas 的时间复杂度在大多数操作中近似线性:
在数据量大时,这种差异尤为明显。
1.2.3 计算范式影响效率
过程式与声明式的本质区别决定了两者在优化空间上的不同:
Pandas:用户显式定义操作顺序,优化空间依赖于向量化、批量处理和内存布局。 SQL:优化器自动重写查询计划,实现全局优化,包括操作顺序、连接策略、索引选择、物化中间结果等。
因此,当分析任务涉及复杂多表连接、聚合和分组时,SQL 的优化器可以显著提升性能,而 Pandas 需要手动调优,如合理使用 merge、groupby、categorical 类型等。
1.3 表达能力与适用任务
从表达能力角度,可以将 Pandas 与 SQL 的优劣总结如下:
逻辑灵活性:Pandas 可直接调用任意 Python 函数,支持复杂逻辑和多条件处理。 聚合与连接:SQL 在多表 JOIN、聚合、窗口函数上更高效,并能自动选择最优算法。 文本与时间序列:Pandas 在时间序列重采样、滑动窗口计算、复杂正则处理上具有明显优势。 可重复性与共享:SQL 查询易于团队复用和嵌入 ETL 流程,而 Pandas 更适合分析原型开发和机器学习前处理。
在实践中,理解任务类型与数据规模是选择工具的前提:
当任务逻辑高度复杂、需要逐行处理或自定义函数时,Pandas 更适合。 当任务涉及大规模聚合、多表关联或分布式计算时,SQL 更适合。
通过对计算模型本质的分析,我们可以形成初步原则:
这为对性能边界、数据清洗任务适配性以及复杂分析任务的讨论提供了基础。
2. 数据规模与性能边界
在实际数据分析过程中,数据规模是影响工具选择的核心因素之一。Pandas 与 SQL 在处理不同量级数据时呈现出截然不同的性能特征和约束条件。理解这一点,需要从内存模型、计算复杂度、I/O 成本、分布式能力以及执行优化机制等多个维度进行分析。
2.1 小规模数据:Pandas 的优势区间
Pandas 的内存计算模型使其在小规模数据处理上具有优势。具体来说,小规模数据一般指数据量能够全部加载到本地内存中进行计算的场景,例如几万到几百万行的数据集。此时,Pandas 的特点包括:
加载速度快Pandas 可以直接从 CSV、Excel、Parquet、JSON 等本地文件或内存数据源读取数据,I/O 延迟低。例如:
import pandas as pddf = pd.read_csv('users.csv')相比之下,SQL 需要通过客户端-服务器通信协议进行数据请求,即便在本地数据库中,也有查询解析和优化的开销。
链式操作和高可读性Pandas 提供了链式调用(method chaining)能力,使数据清洗、转换、聚合逻辑可以以连续语句的形式表达:
df_filtered = (df[df['age'] > 30] .groupby('city')['income'] .mean() .reset_index())这种方式不仅直观,而且便于调试和快速迭代。
灵活的自定义逻辑Pandas 可以直接调用任意 Python 函数和第三方库,实现复杂的逻辑处理,如自定义函数映射、正则表达式处理或复杂特征构造。例如:
defcompute_score(row):return row['a'] * 0.3 + row['b'] * 0.7df['score'] = df.apply(compute_score, axis=1)顺序执行与可调控性Pandas 的计算严格按照代码顺序执行,每一步的中间结果可立即查看、调试或缓存。这对于小规模数据的探索性分析非常适合。
在时间复杂度方面,小规模数据中 Pandas 的大多数操作可以近似视作线性复杂度:
这里的 为行数,列数 通常影响内存占用,但对单步操作的 CPU 时间影响较小。
当数据量在内存可容纳范围内,Pandas 提供的高灵活性、可读性和快速迭代能力使其成为首选。
2.2 大规模数据:SQL 的扩展能力
当数据量扩大到数千万行甚至更高时,Pandas 的内存限制和计算开销迅速显现:
内存压力增大Pandas 需要将数据完全加载到内存中,数据量过大时可能导致系统频繁进行垃圾回收或直接瓦解。假设数据表有 行、 列,且每列平均占用 字节,则总内存需求为:
当 超过可用内存时,Pandas 的计算将不可行或极度缓慢。
数据复制成本高Pandas 的许多操作(如
merge,groupby)在内部可能产生数据拷贝,内存占用进一步上升。对于大数据集,每次复制都是显著的性能开销。运算时间随行数增长显著虽然 Pandas 的算法本身可能是线性复杂度,但内存分配、缓存命中率下降和垃圾回收会使实际执行时间呈非线性增长:
在这种情况下,SQL 显示出优势:
磁盘或分布式存储支持SQL 数据通常存储在磁盘或分布式存储中,不依赖客户端内存。数据库通过分页和缓冲区管理,确保即便数据量远超内存,查询依然可以顺利执行。
索引与执行优化SQL 数据库可以利用索引、分区或物化视图加速查询。例如,在用户表上建立
age与city的复合索引,可以使聚合查询的复杂度从线性下降至对数级别:示例 SQL 查询:
SELECT city, AVG(income)FROMusersWHERE age > 30GROUPBY city;分布式计算在大数据场景中,SQL 查询可以在分布式框架(如 Spark SQL、Hive)上执行,水平扩展能力强。计算任务可拆分到多个节点并行执行,性能曲线相对平缓:
其中 为节点数量,网络开销为数据分片和聚合过程中产生的通信成本。
当数据规模超出单机内存可容纳范围,SQL 或分布式 SQL 成为高效选择,尤其在聚合、筛选、连接等操作上具有优势。
2.3 内存模型与计算复杂度对比
对比 Pandas 与 SQL 的内存模型和计算复杂度,可以得到如下分析:
从上表可以看出:
Pandas 对小数据有优势,但随数据量增长,性能下降迅速; SQL 对大数据有适应性,尤其在索引、分区和分布式执行下,性能增长曲线更加平滑; 内存模型差异决定了工具选择的“临界点”,即数据量达到百万至千万行时,应考虑从 Pandas 向 SQL 迁移或混合使用。
2.4 决策启示
基于以上分析,可以提出数据规模与性能边界的初步决策原则:
小规模探索性分析():Pandas 优先,因其开发效率和灵活性最高。 中等规模数据():可采用 Pandas 或 SQL,根据内存可用性和计算复杂度进行选择;复杂逻辑建议先在 Pandas 中验证,再迁移至 SQL 优化执行。 大规模或分布式数据():SQL 或分布式计算框架优先;Pandas 可用于数据采样或特征验证。
这种分层策略不仅兼顾性能和内存约束,也为混合使用 Pandas 与 SQL 提供了理论依据。
通过对数据规模、内存模型与计算复杂度的分析,我们可以明确:
Pandas 更适合小规模、灵活性要求高的任务; SQL 更适合大规模、分布式、高性能要求的任务; 两者的选择边界依赖于内存容量、索引优化和数据处理复杂度。
这一分析为构建实际的数据处理决策框架提供了基础,为清洗任务适配性、工程化策略和复杂分析提供了性能参考。
3. 数据清洗任务的适配性分析
3.1 缺失值处理
Pandas 提供高度灵活的缺失值处理方式:
df.fillna(method='ffill')df.dropna(subset=['col1'])SQL 中的处理方式相对有限:
SELECTCOALESCE(col1, 0) FROMtable;当涉及复杂填充策略(如时间序列插值)时,Pandas 更具优势。
3.2 数据转换与特征构造
Pandas 支持任意 Python 函数:
df['score'] = df['a'] * 0.3 + df['b'] * 0.7SQL 虽支持表达式,但在复杂逻辑(如多层条件)时可读性下降:
CASE WHEN a > 10 THEN b * 2 ELSE c * 3 END3.3 字符串与文本处理
Pandas:
df['name'].str.lower().str.replace(' ', '_')SQL:
LOWER(REPLACE(name, ' ', '_'))两者能力接近,但 Pandas 在复杂文本处理(正则表达式、多步转换)方面更灵活。
4. 可维护性与团队协作
4.1 SQL 的可复用性
SQL 查询具备:
清晰的数据来源 明确的逻辑结构 易于嵌入数据管道
例如:
WITH filtered AS (SELECT * FROMusersWHERE age > 30)SELECT city, COUNT(*) FROM filtered GROUPBY city;这种结构适合团队共享与复用。
4.2 Pandas 的工程化能力
Pandas 更适合嵌入 Python 项目:
与机器学习框架结合(如 scikit-learn) 支持函数封装 支持单元测试
例如:
deftransform(df):return df[df['age'] > 30]4.3 可读性对比
SQL 更接近“数据逻辑描述”,而 Pandas 更接近“程序执行流程”。当逻辑复杂时:
SQL 更清晰(尤其是聚合与连接) Pandas 更灵活(尤其是条件逻辑)
5. 复杂分析任务中的表现差异
5.1 多表关联(JOIN)
SQL 在 JOIN 操作上具有优势:
SELECT *FROM AJOIN B ON A.id = B.id数据库优化器可以选择最优连接方式(Hash Join、Merge Join 等)。
Pandas:
pd.merge(A, B, on='id')虽然语法简洁,但在大数据场景下性能受限。
5.2 窗口函数
SQL 提供强大的窗口函数:
Pandas 需要通过 groupby + transform 实现,表达较复杂。
5.3 时间序列分析
Pandas 在时间序列方面具有显著优势:
df.resample('D').mean()SQL 需要依赖特定数据库扩展,通用性较低。
6. 混合使用策略
6.1 分层处理模型
一种常见策略是:
使用 SQL 进行数据筛选与聚合 使用 Pandas 进行细粒度分析
这种方式可以表示为:
6.2 ETL 流程中的角色划分
SQL:数据抽取与预处理 Pandas:数据清洗与特征工程
6.3 与大数据工具结合
在 Spark 环境中:
Spark SQL 处理大规模数据 Pandas 用于采样分析
7. 性能优化策略
7.1 Pandas 优化
使用向量化操作 避免循环 使用 categorical 类型降低内存占用
7.2 SQL 优化
建立索引 减少子查询 使用合适的 JOIN 顺序
8. 工具选择的决策框架
可以从以下维度进行判断:
8.1 数据规模
小规模:Pandas 大规模:SQL
8.2 任务复杂度
复杂逻辑:Pandas 聚合查询:SQL
8.3 实时性需求
低延迟分析:Pandas 批处理:SQL
8.4 团队结构
数据分析师:SQL 数据科学家:Pandas
9. 综合结论
在日常数据清洗与分析中,并不有绝对优越的工具。Pandas 与 SQL 的差异源于其计算模型、执行机制与适用场景的不同。合理的选择应基于数据规模、任务结构与工程需求,而非单一指标。
更重要的是,工具选择并非止点,而是分析路径的一部分。通过组合使用两种工具,可以在效率与灵活性之间取得更优平衡。
以下为专栏文章推荐
一、表示与谱结构:从局部传播到全局算子
在图学习框架中,节点之间的关系不仅仅是拓扑连接,更体现为一种算子作用下的函数变化形式。图卷积网络的传播机制可以被理解为对图拉普拉斯算子的一类函数变换(图卷积网络(GCN)和Laplacian Eigenmaps有什么联系?GCN传播是否等价于对拉普拉斯算子进行某函数变换?局部传播如何逐步逼近全局谱结构?)。
从数学表达来看,经典谱方法中有:
其中 为图拉普拉斯矩阵, 为度矩阵, 为邻接矩阵。而GCN的传播可写为:
这一传播是否可以被视为谱域滤波的低阶近似?进一步地,局部邻域的迭代传播为何能够逐步逼近全局特征分布?这实际上涉及函数空间中算子逼近的问题,即局部线性算子在多次复合后对全局谱信息的描述能力。
二、学习范式与泛化机制:知识迁移与快速适配
在学习理论中,模型究竟依赖“已有经验”还是“快速调整能力”?这一问题在元学习与迁移学习的对比中尤为突出(元学习(Meta Learning)与迁移学习(Transfer Learning)的区别联系是什么?面对新任务时,是更需要已有知识,还是更需要快速适应能力?)。
迁移学习强调跨任务共享表示,其核心假设是不同任务之间具有某种分布相似性;而元学习则关注学习“如何学习”,即优化初始化或更新规则,使模型在少量样本条件下迅速收敛。
当任务分布高度异质时,迁移是否仍然有效?当样本极度稀缺时,仅依赖参数初始化是否足够?这背后实际上涉及函数空间中的先验结构设计问题。
三、序列建模与结构优化:深度与泛化的张力
循环神经网络的层数选择涉及表示能力与泛化能力之间的平衡(LSTM/GRU网络一般几层好?在小数据集上,深层RNN为何容易出现泛化能力下降?GRU在深层结构中为何有时优于LSTM?如何确定最佳层数?)。
在理论上,深层结构能够表达更复杂的函数,但在有限数据条件下,模型复杂度增加会带来估计误差的上升。对于RNN而言,这种现象尤为明显,因为时间维度的递归结构会放大误差传播。
GRU为何在某些深层结构中优于LSTM?一个关键原因在于参数规模与门控机制的简化,使其在优化过程中更稳定。这提示一个更深层问题:结构复杂性是否一定带来表达优势,还是在特定条件下反而降低学习效率?
四、注意力机制与上下文建模:信息选择的优化问题
当注意力机制引入序列模型后,模型性能往往显著提升(深度学习模型LSTM和GRU在引入注意力机制后模型效果会有很大提升吗?如何解释LSTM与GRU在引入注意力机制后的优势和局限?)。其核心在于:模型能够对输入序列进行加权选择,而非均匀处理。
注意力可以形式化为:
这种加权机制是否本质上是一种自适应核函数?它在长序列中的优势来自何处?是否可以将其理解为一种动态低秩近似?
这些问题直接指向一个更深层的研究方向:如何在计算复杂度与表达能力之间取得更优平衡。
五、线性结构与优化理论:从代数到对偶
“线性”这一概念贯穿多个数学分支(数学上经常说「线性代数、线性空间、线性变换、……」,到底何为线性?为何在诸多概念中反复强调?基向量选择是否影响线性变换可解释性?)。线性性的本质在于保持加法与数乘结构:
这一性质使得问题可以在基空间中分解,从而显著降低计算复杂度。
进一步地,统计与优化中的多个概念之间也有深层联系(方差和协方差的关系,如何理解?为何要提出增广拉格朗日乘子法呢?线性空间的对偶空间和优化里的拉格朗日对偶有什么关系?专栏回顾)。例如,拉格朗日对偶可以视为在对偶空间中重新表述优化问题,其核心形式为:
对偶问题为何有时更易求解?这种转换是否意味着问题结构发生了某种“降维”?这些问题揭示了优化理论与线性结构之间的紧密联系。
六、概率推断与统计基础:不确定性描述
在统计学习中,贝叶斯方法与频率方法之间的差异受到关注(使用无信息先验的贝叶斯推断和频率派的极大似然的本质差别在哪里?当样本量不足时,贝叶斯推断为何表现优于极大似然估计?)。
极大似然估计关注参数的点估计,而贝叶斯方法则引入先验分布,通过后验分布表达不确定性:
关键当数据不足时,先验信息如何影响结果?这种影响是否可以被视为一种正则化机制?进一步地,在高维空间中,如何选择合理的先验结构?
七、大模型与系统工程:从算法到整体流程
随着大模型的发展,问题不再局限于单一模型结构,而是扩展到完整系统设计(开启Al能赋科研新时代 全流程 全场景 高级应用)。在这一背景下,检索增强生成(RAG)成为关键技术之一(如何高效提升大模型的RAG效果? 生成模型如何优化上下文理解能力,以更好地处理长文本?双向检索模型如何在RAG系统中起到关键作用?)。
RAG系统的核心在于将外部知识与生成模型结合,其关键挑战包括:
如何提高检索相关性? 如何在长文本中保持语义一致性? 检索与生成之间如何协同优化?
进一步可以提出:检索模块是否可以被视为一个外部信息存储函数?生成模型是否在进行条件概率建模:
这一方向已经从单一模型设计扩展到复杂系统协同问题。
八、机器学习本质:函数逼近与结构表达
归根结底,所有这些问题都指向一个核心命题(机器学习的本质是什么?当数据中包含噪声或不完整信息时,如何确保学习到的函数仍然具备可靠性?为何多层结构能够提升表示能力?):机器学习是否可以被理解为在函数空间中寻找最优近似?
在这一框架下,深度结构的优势来源于其分层表示能力,使复杂函数可以分解为多层简单函数的组合。然而,这种分解是否具有唯一性?不同结构是否对应不同的函数子空间?
欢迎你加入人工智能方向交流群!无论你是研究者、开发者还是AI爱好者,这里都为你提供一个开放的交流平台。目前建立了多个不同方向交流群(机器学习/深度学习/自然语言处理/计算机视觉/大模型/等)。期待与你一起探讨、学习和成长!
长按识别下方二维码
回复【AI+群方向(例如:机器学习等)】联系加群

感谢你的关注和支持!
欢迎你加入人工智能科学研究知识星球!
加入后,你将可以在知识星球有效期内随时阅览微信公众号的全部内容资源,包括所有付费专栏、付费文章与免费内容,知识总结/图谱/卡片。此外,还会定期提供研究笔记和论文精读,并额外赠送六七十篇精选付费文章。期待与你一起交流、学习、进步!
人工智能科学研究公众号专注于AI领域的前沿技术与研究动态,涵盖机器学习、深度学习、自然语言处理等热门方向,助你深入了解人工智能的最新进展。欢迎你的关注!

