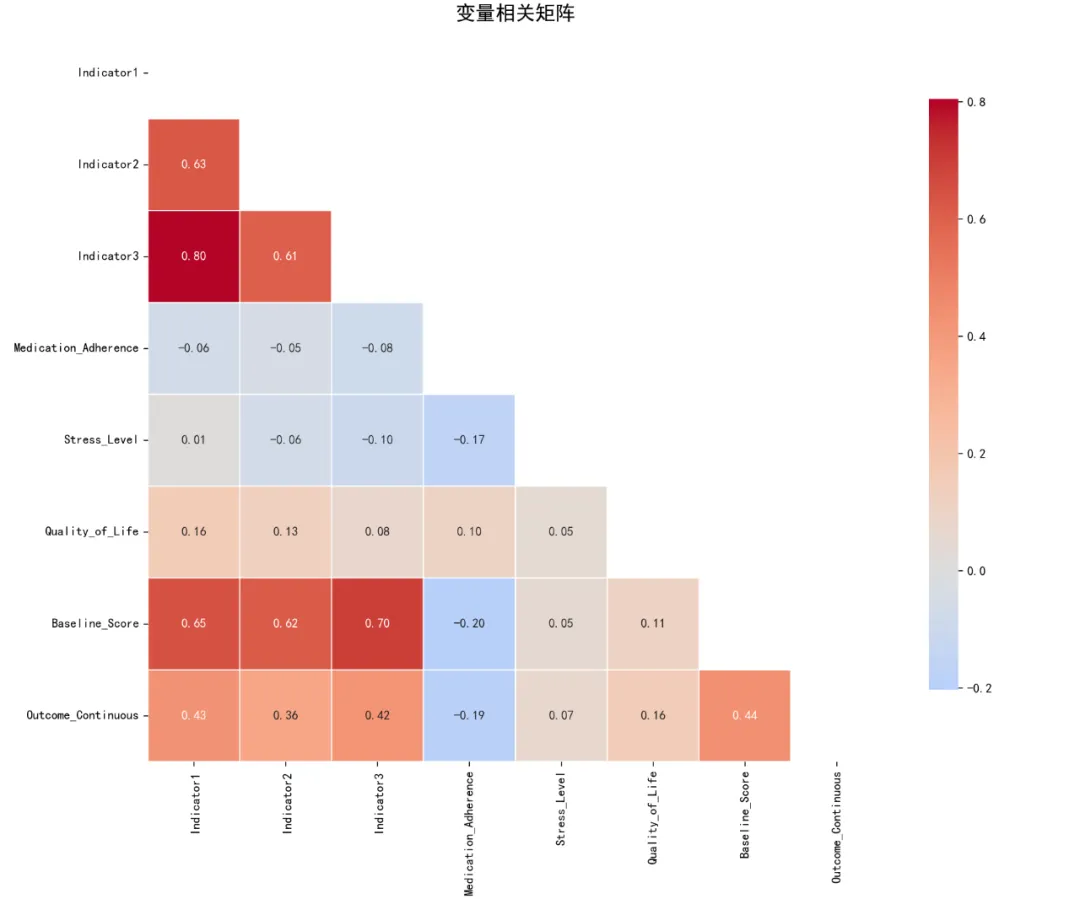
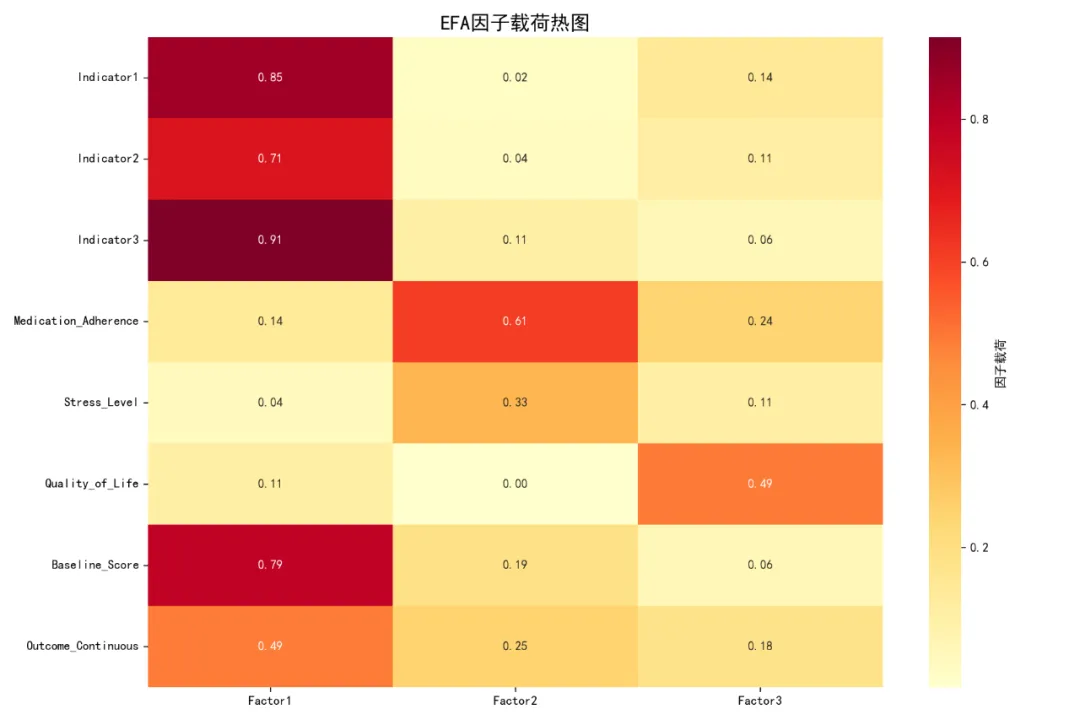
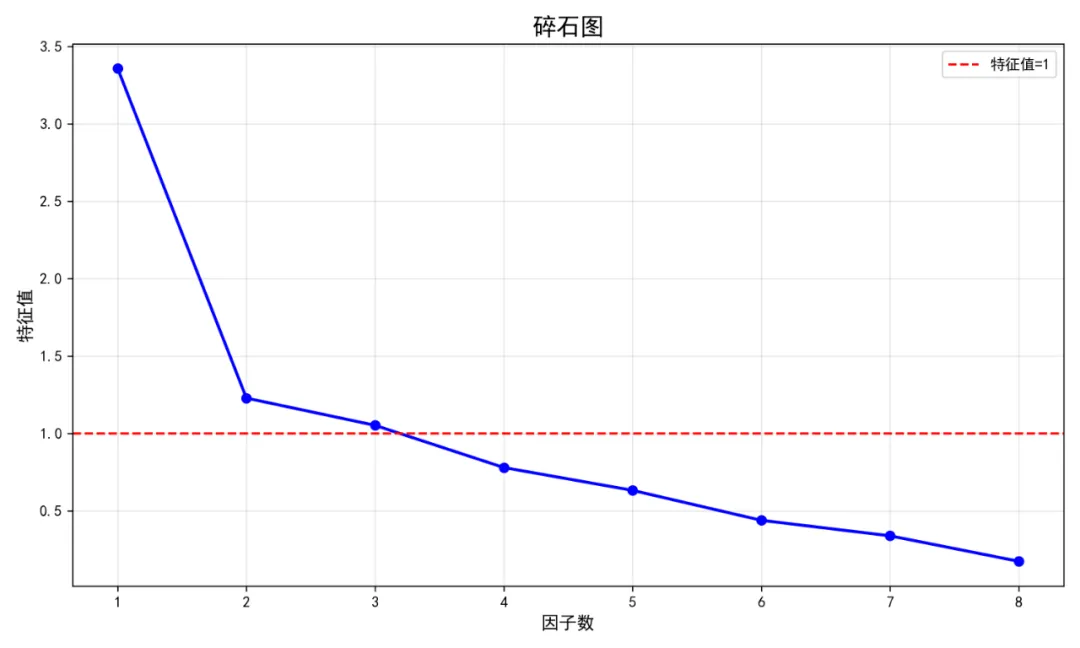
# pip install pandas numpy scipy matplotlib seaborn pingouin scikit-learn factor-analyzer semopy openpyxl python-docx# pip install python-docx# pip install factor_analyzer semopy python-docximport osimport sysimport warningsimport pandas as pdimport numpy as npfrom datetime import datetimeimport matplotlib.pyplot as pltimport seaborn as snsfrom scipy import stats# 忽略警告warnings.filterwarnings('ignore')# 设置中文字体plt.rcParams['font.sans-serif'] = ['SimHei', 'Arial Unicode MS', 'DejaVu Sans']plt.rcParams['axes.unicode_minus'] = Falseprint("正在设置环境...")# 检查必要包required_packages = ['pandas', 'numpy', 'scipy', 'matplotlib', 'seaborn','sklearn', 'factor_analyzer', 'semopy', 'openpyxl']# 尝试导入主要包try: import pandas as pd import numpy as np import matplotlib.pyplot as plt import seaborn as sns from scipy import statsprint("✓ 基础包导入成功")except ImportError as e:print(f"✗ 导入基础包失败: {e}") sys.exit(1)# 尝试导入可选包optional_packages = {'factor_analyzer': 'factor_analyzer','semopy': 'semopy','sklearn': 'sklearn','pingouin': 'pingouin','docx': 'python-docx'# Word报告包}for display_name, package_name in optional_packages.items(): try:if package_name == 'factor_analyzer': from factor_analyzer import FactorAnalyzer, calculate_kmo, calculate_bartlett_sphericityelif package_name == 'semopy': import semopyelif package_name == 'sklearn': from sklearn.impute import SimpleImputerelif package_name == 'pingouin': import pingouin as pgelif package_name == 'docx': from docx import Documentprint(f"✓ {display_name} 导入成功") except ImportError:print(f"⚠ {display_name} 未安装,相关功能可能受限")# 设置工作目录desktop_path = os.path.join(os.path.expanduser('~'), 'Desktop')if not os.path.exists(desktop_path): desktop_path = os.path.join(os.path.expanduser('~'), '桌面') # 中文系统original_dir = desktop_pathresults_dir = os.path.join(desktop_path, '12-SEM结果')if not os.path.exists(results_dir): os.makedirs(results_dir)print(f"✓ 创建结果文件夹: {results_dir}")# 读取数据print("\n正在读取数据...")# 读取Excel文件excel_path = os.path.join(original_dir, 'longitudinal_data.xlsx')if os.path.exists(excel_path): try: data_full = pd.read_excel(excel_path, sheet_name='Full_Dataset') data_simple = pd.read_excel(excel_path, sheet_name='Simple_Dataset')print(f"✓ Full Dataset: {data_full.shape[0]}行, {data_full.shape[1]}列")print(f"✓ Simple Dataset: {data_simple.shape[0]}行, {data_simple.shape[1]}列") except Exception as e:print(f"✗ 读取Excel文件失败: {e}")print("⚠ 创建示例数据以供测试...")# 创建示例数据 np.random.seed(123) n = 100 data_full = pd.DataFrame({'ID': range(1, n + 1),'Time': np.random.choice([0, 1, 2], n),'Age': np.random.normal(45, 10, n),'Sex': np.random.choice(['M', 'F'], n),'Treatment': np.random.choice(['A', 'B', 'C', 'D'], n),'Baseline_Score': np.random.normal(50, 10, n),'School_ID': np.random.choice(range(1, 11), n),'SES': np.random.choice(['Low', 'Medium', 'High'], n),'Genetic_Marker': np.random.choice(['Type1', 'Type2'], n),'Indicator1': np.random.normal(3, 1, n),'Indicator2': np.random.normal(4, 0.8, n),'Indicator3': np.random.normal(5, 1.2, n),'Medication_Adherence': np.random.normal(7, 2, n),'Stress_Level': np.random.normal(5, 1.5, n),'Quality_of_Life': np.random.normal(6, 1.8, n),'Outcome_Continuous': np.random.normal(60, 15, n),'Outcome_Binary': np.random.choice([0, 1], n) }) data_simple = data_full.copy()print("✓ 示例数据创建成功")else:print(f"✗ 未找到数据文件: {excel_path}")print("⚠ 创建示例数据以供测试...")# 创建示例数据 np.random.seed(123) n = 100 data_full = pd.DataFrame({'ID': range(1, n + 1),'Time': np.random.choice([0, 1, 2], n),'Age': np.random.normal(45, 10, n),'Sex': np.random.choice(['M', 'F'], n),'Treatment': np.random.choice(['A', 'B', 'C', 'D'], n),'Baseline_Score': np.random.normal(50, 10, n),'School_ID': np.random.choice(range(1, 11), n),'SES': np.random.choice(['Low', 'Medium', 'High'], n),'Genetic_Marker': np.random.choice(['Type1', 'Type2'], n),'Indicator1': np.random.normal(3, 1, n),'Indicator2': np.random.normal(4, 0.8, n),'Indicator3': np.random.normal(5, 1.2, n),'Medication_Adherence': np.random.normal(7, 2, n),'Stress_Level': np.random.normal(5, 1.5, n),'Quality_of_Life': np.random.normal(6, 1.8, n),'Outcome_Continuous': np.random.normal(60, 15, n),'Outcome_Binary': np.random.choice([0, 1], n) }) data_simple = data_full.copy()print("✓ 示例数据创建成功")# 数据预处理print("\n正在进行数据预处理...")# 选择基线数据(Time=0)if'Time'in data_full.columns: baseline_data = data_full[data_full['Time'] == 0].drop_duplicates(subset='ID', keep='first')else: baseline_data = data_full.drop_duplicates(subset='ID', keep='first')# 创建汇总数据集(用于SEM分析)required_columns = ['ID', 'Age', 'Sex', 'Treatment', 'Baseline_Score', 'School_ID','SES', 'Genetic_Marker', 'Indicator1', 'Indicator2', 'Indicator3','Medication_Adherence', 'Stress_Level', 'Quality_of_Life','Outcome_Continuous', 'Outcome_Binary']# 只选择存在的列available_columns = [col for col in required_columns if col in baseline_data.columns]sem_data = baseline_data[available_columns].copy()print(f"\n数据结构: {sem_data.shape[0]}行, {sem_data.shape[1]}列")print("\n前5行数据:")print(sem_data.head())# 检查缺失值print("\n缺失值统计:")missing_stats = sem_data.isnull().sum()missing_vars = missing_stats[missing_stats > 0]if len(missing_vars) > 0:print("以下变量存在缺失值:")for var, count in missing_vars.items():print(f" {var}: {count}个缺失值 ({count / sem_data.shape[0] * 100:.1f}%)")else:print("无缺失值")# 处理缺失值sem_data_clean = sem_data.copy()# 数值变量使用中位数填充num_vars = ['Indicator1', 'Indicator2', 'Indicator3', 'Medication_Adherence','Stress_Level', 'Quality_of_Life', 'Baseline_Score', 'Outcome_Continuous']for var in num_vars:if var in sem_data_clean.columns and sem_data_clean[var].isnull().any(): median_val = sem_data_clean[var].median() sem_data_clean[var].fillna(median_val, inplace=True)print(f"✓ 变量 {var}: {sem_data[var].isnull().sum()}个缺失值已用中位数 {median_val:.2f} 填充")# 检查Outcome_Binary的分布if'Outcome_Binary'in sem_data_clean.columns:print(f"\nOutcome_Binary分布:")print(sem_data_clean['Outcome_Binary'].value_counts())# 探索性因子分析(EFA)print("\n正在进行探索性因子分析...")# 选择用于EFA的指标efa_vars_list = ['Indicator1', 'Indicator2', 'Indicator3', 'Medication_Adherence','Stress_Level', 'Quality_of_Life', 'Baseline_Score', 'Outcome_Continuous']# 只选择存在的列efa_vars_available = [col for col in efa_vars_list if col in sem_data_clean.columns]if len(efa_vars_available) >= 3: # 至少需要3个变量进行EFA efa_vars = sem_data_clean[efa_vars_available].copy()# 确保所有变量都是数值型 efa_vars = efa_vars.apply(pd.to_numeric, errors='coerce')print(f"\nEFA变量结构: {efa_vars.shape[0]}行, {efa_vars.shape[1]}列")# 检查相关性矩阵 cor_matrix = efa_vars.corr()print("\n相关矩阵:")print(cor_matrix.round(3))# 可视化相关矩阵 try: plt.figure(figsize=(12, 10)) mask = np.triu(np.ones_like(cor_matrix, dtype=bool)) sns.heatmap(cor_matrix, mask=mask, annot=True, fmt='.2f', cmap='coolwarm', center=0, square=True, linewidths=.5, cbar_kws={"shrink": .8}) plt.title('变量相关矩阵', fontsize=16) plt.tight_layout() plt.savefig(os.path.join(results_dir, 'Correlation_Matrix.png'), dpi=300) plt.close()print("✓ 相关矩阵图已保存: Correlation_Matrix.png") except Exception as e:print(f"✗ 相关矩阵图生成失败: {e}")# KMO检验和Bartlett球形检验 try: from factor_analyzer import calculate_kmo, calculate_bartlett_sphericity# KMO检验 kmo_all, kmo_model = calculate_kmo(efa_vars)print(f"\nKMO检验:")print(f"总体KMO值: {kmo_model:.3f}")# Bartlett球形检验 chi2, p_value = calculate_bartlett_sphericity(efa_vars)print(f"\nBartlett球形检验:")print(f"卡方值: {chi2:.3f}")print(f"p值: {p_value:.3f}")print(f"球形检验结果: {'拒绝原假设(适合因子分析)' if p_value < 0.05 else '接受原假设(不适合因子分析)'}") except ImportError:print("⚠ factor_analyzer包未安装,跳过KMO和Bartlett检验") except Exception as e:print(f"✗ KMO/Bartlett检验失败: {e}")# 确定因子数量print("\n确定因子数量...")# 使用特征值大于1的标准 try:# 计算相关矩阵的特征值 corr_matrix = efa_vars.corr() eigenvalues, eigenvectors = np.linalg.eig(corr_matrix)# 排序特征值 sorted_eigenvalues = np.sort(eigenvalues)[::-1]# 碎石图 plt.figure(figsize=(10, 6)) plt.plot(range(1, len(sorted_eigenvalues) + 1), sorted_eigenvalues, 'bo-', linewidth=2) plt.axhline(y=1, color='r', linestyle='--', label='特征值=1') plt.title('碎石图', fontsize=16) plt.xlabel('因子数', fontsize=12) plt.ylabel('特征值', fontsize=12) plt.legend() plt.grid(True, alpha=0.3) plt.tight_layout() plt.savefig(os.path.join(results_dir, 'Scree_Plot.png'), dpi=300) plt.close()print("✓ 碎石图已保存: Scree_Plot.png")# 确定特征值大于1的因子数 n_factors = sum(sorted_eigenvalues > 1)print(f"特征值大于1的因子数: {n_factors}")# 如果因子数不合适,设置默认值if n_factors < 1: n_factors = 2print(f"因子数小于1,使用默认值: {n_factors}") except Exception as e:print(f"✗ 确定因子数量失败: {e}") n_factors = 2print(f"\n执行EFA,因子数 = {n_factors}")# 执行EFA try: from factor_analyzer import FactorAnalyzer# 创建FactorAnalyzer对象 fa = FactorAnalyzer(n_factors=n_factors, rotation='varimax', method='minres') fa.fit(efa_vars)# 获取因子载荷 loadings = fa.loadings_# 创建因子载荷DataFrame loadings_df = pd.DataFrame( loadings, index=efa_vars.columns, columns=[f'Factor{i + 1}'for i in range(n_factors)] )print("\n探索性因子分析结果(因子载荷):")print(loadings_df.round(3))# 可视化因子载荷 plt.figure(figsize=(12, 8)) heatmap = sns.heatmap(loadings_df.abs(), annot=True, fmt='.2f', cmap='YlOrRd', cbar_kws={'label': '因子载荷'}) plt.title('EFA因子载荷热图', fontsize=16) plt.tight_layout() plt.savefig(os.path.join(results_dir, 'EFA_Loadings.png'), dpi=300) plt.close()print("✓ EFA因子载荷图已保存: EFA_Loadings.png")# 保存EFA结果 loadings_df.to_csv(os.path.join(results_dir, 'EFA_Loadings.csv'))print("✓ EFA载荷表已保存: EFA_Loadings.csv") except ImportError:print("⚠ factor_analyzer包未安装,跳过EFA") except Exception as e:print(f"✗ EFA执行失败: {e}")else:print(f"⚠ 可用于EFA的变量不足,需要至少3个,当前有{len(efa_vars_available)}个")# 验证性因子分析(CFA)print("\n正在进行验证性因子分析...")# 准备数据cfa_data = sem_data_clean.copy()# 确保数值类型numeric_columns = ['Indicator1', 'Indicator2', 'Indicator3', 'Medication_Adherence','Stress_Level', 'Quality_of_Life', 'Baseline_Score', 'Outcome_Continuous']for col in numeric_columns:if col in cfa_data.columns: cfa_data[col] = pd.to_numeric(cfa_data[col], errors='coerce')# 尝试使用semopy进行CFAtry: import semopy from semopy import Model from semopy.reports import calc_statsprint("✓ semopy包可用,开始CFA分析")

# 先尝试拟合单因子模型print("\n尝试拟合单因子CFA模型...") try:# 检查模型中需要的变量是否存在 required_vars_model1 = ['Indicator1', 'Indicator2', 'Indicator3', 'Baseline_Score', 'Outcome_Continuous'] missing_vars_model1 = [var for var in required_vars_model1 if var not in cfa_data.columns]if missing_vars_model1:print(f"⚠ 单因子模型缺少变量: {missing_vars_model1}") raise ValueError("缺少必要变量") model1 = Model(measurement_model1) model1.load_dataset(cfa_data) res1 = model1.fit()print("✓ 单因子CFA模型收敛成功!")# 获取拟合指标 stats1 = calc_stats(model1)print("\n单因子CFA模型拟合结果:")print(f"卡方值: {stats1['chi2']:.3f}")print(f"自由度: {stats1['DoF']}")print(f"p值: {stats1['p_value']:.3f}")print(f"CFI: {stats1['CFI']:.3f}")print(f"TLI: {stats1['TLI']:.3f}")print(f"RMSEA: {stats1['RMSEA']:.3f}")print(f"SRMR: {stats1['SRMR']:.3f}")print(f"AIC: {stats1['AIC']:.1f}")print(f"BIC: {stats1['BIC']:.1f}")# 提取参数估计 params1 = model1.inspect(std_est=True)print("\n参数估计:")print(params1[['lval', 'op', 'rval', 'Estimate', 'Std. Estimate']].round(3)) cfa_fit = model1 fit_measures = stats1 except Exception as e:print(f"✗ 单因子CFA模型失败: {e}")# 尝试双因子模型print("\n尝试拟合双因子CFA模型...") try: required_vars_model2 = ['Indicator1', 'Indicator2', 'Indicator3', 'Baseline_Score','Medication_Adherence', 'Stress_Level', 'Quality_of_Life', 'Outcome_Continuous'] missing_vars_model2 = [var for var in required_vars_model2 if var not in cfa_data.columns]if missing_vars_model2:print(f"⚠ 双因子模型缺少变量: {missing_vars_model2}") raise ValueError("缺少必要变量") model2 = Model(measurement_model2) model2.load_dataset(cfa_data) res2 = model2.fit()print("✓ 双因子CFA模型收敛成功!")print("\n双因子CFA模型拟合结果:")# 获取拟合指标 stats2 = calc_stats(model2)print(f"卡方值: {stats2['chi2']:.3f}")print(f"自由度: {stats2['DoF']}")print(f"p值: {stats2['p_value']:.3f}")print(f"CFI: {stats2['CFI']:.3f}")print(f"TLI: {stats2['TLI']:.3f}")print(f"RMSEA: {stats2['RMSEA']:.3f}")print(f"SRMR: {stats2['SRMR']:.3f}")print(f"AIC: {stats2['AIC']:.1f}")print(f"BIC: {stats2['BIC']:.1f}")# 提取参数估计 params2 = model2.inspect(std_est=True)print("\n参数估计:")print(params2[['lval', 'op', 'rval', 'Estimate', 'Std. Estimate']].round(3)) cfa_fit = model2 fit_measures = stats2 except Exception as e2:print(f"✗ 双因子CFA模型也失败: {e2}")# 尝试最简单的模型print("\n尝试拟合最简单的CFA模型...") simple_model = ''' Health_Factor =~ Indicator1 + Indicator2 + Indicator3 ''' try: required_vars_simple = ['Indicator1', 'Indicator2', 'Indicator3'] missing_vars_simple = [var for var in required_vars_simple if var not in cfa_data.columns]if missing_vars_simple:print(f"⚠ 简单模型缺少变量: {missing_vars_simple}") raise ValueError("缺少必要变量") model_simple = Model(simple_model) model_simple.load_dataset(cfa_data) res_simple = model_simple.fit()print("✓ 简单CFA模型收敛成功!") stats_simple = calc_stats(model_simple)print(f"卡方值: {stats_simple['chi2']:.3f}")print(f"自由度: {stats_simple['DoF']}")print(f"p值: {stats_simple['p_value']:.3f}") cfa_fit = model_simple fit_measures = stats_simple except Exception as e3:print(f"✗ 简单CFA模型失败: {e3}")# 模型拟合度评估if cfa_fit is not None and fit_measures is not None:print("\n模型拟合度评估:")# 创建拟合度表格 fit_table_data = {'Measure': ['Chi-square', 'DF', 'p-value', 'CFI', 'TLI','RMSEA', 'SRMR', 'AIC', 'BIC'],'Value': [ round(fit_measures.get('chi2', 0), 3), fit_measures.get('DoF', 0), round(fit_measures.get('p_value', 1), 3), round(fit_measures.get('CFI', 0), 3) if'CFI'in fit_measures else'N/A', round(fit_measures.get('TLI', 0), 3) if'TLI'in fit_measures else'N/A', round(fit_measures.get('RMSEA', 0), 3) if'RMSEA'in fit_measures else'N/A', round(fit_measures.get('SRMR', 0), 3) if'SRMR'in fit_measures else'N/A', round(fit_measures.get('AIC', 0), 1) if'AIC'in fit_measures else'N/A', round(fit_measures.get('BIC', 0), 1) if'BIC'in fit_measures else'N/A' ] }# 添加解释 interpretations = []for i, measure in enumerate(fit_table_data['Measure']): value = fit_table_data['Value'][i]if measure == 'p-value':if isinstance(value, (int, float)): interpretations.append('模型可接受'if value > 0.05 else'模型需改进')else: interpretations.append('')elif measure == 'CFI':if isinstance(value, (int, float)):if value > 0.90: interpretations.append('优')elif value > 0.80: interpretations.append('可接受')else: interpretations.append('需改进')else: interpretations.append('')elif measure == 'TLI':if isinstance(value, (int, float)):if value > 0.90: interpretations.append('优')elif value > 0.80: interpretations.append('可接受')else: interpretations.append('需改进')else: interpretations.append('')elif measure == 'RMSEA':if isinstance(value, (int, float)):if value < 0.05: interpretations.append('优')elif value < 0.08: interpretations.append('可接受')else: interpretations.append('需改进')else: interpretations.append('')elif measure == 'SRMR':if isinstance(value, (int, float)): interpretations.append('优'if value < 0.08 else'需改进')else: interpretations.append('')elif measure in ['AIC', 'BIC']: interpretations.append('值越小越好')else: interpretations.append('') fit_table_data['Interpretation'] = interpretations fit_table = pd.DataFrame(fit_table_data)print("\n拟合指标表:")print(fit_table.to_string(index=False))# 保存拟合指标 fit_table.to_csv(os.path.join(results_dir, 'CFA_Fit_Indices.csv'), index=False)print("\n✓ 拟合指标已保存: CFA_Fit_Indices.csv")# 参数估计结果print("\n参数估计结果:") try: param_est = cfa_fit.inspect(std_est=True)# 筛选主要结果 param_table = param_est[['lval', 'op', 'rval', 'Estimate', 'Std. Estimate']].copy() param_table.columns = ['Path', 'Relationship', 'Variable', 'Estimate', 'Std. Estimate']print("\n主要参数估计:")print(param_table.round(3))# 保存参数估计 param_table.to_csv(os.path.join(results_dir, 'CFA_Parameter_Estimates.csv'), index=False)print("\n✓ 参数估计已保存: CFA_Parameter_Estimates.csv") except Exception as e:print(f"✗ 参数估计提取失败: {e}")# 可视化print("\n生成可视化图形...")# 因子载荷条形图 try: loadings_data = param_est[param_est['op'] == '=~'].copy()if len(loadings_data) > 0: plt.figure(figsize=(10, 6)) bars = plt.bar(range(len(loadings_data)), loadings_data['Std. Estimate'].abs()) plt.xticks(range(len(loadings_data)), [f"{row['lval']}->{row['rval']}"for _, row in loadings_data.iterrows()], rotation=45, ha='right') plt.axhline(y=0.4, color='r', linestyle='--', alpha=0.5, label='载荷阈值(0.4)') plt.ylabel('标准化载荷') plt.title('CFA标准化因子载荷') plt.legend() plt.tight_layout() plt.savefig(os.path.join(results_dir, 'CFA_Factor_Loadings.png'), dpi=300) plt.close()print("✓ 因子载荷图已保存: CFA_Factor_Loadings.png") except Exception as e:print(f"✗ 因子载荷图生成失败: {e}")# 模型拟合指标条形图 try: fit_plot_data = [] measures = ['CFI', 'TLI', 'RMSEA', 'SRMR'] thresholds = [0.90, 0.90, 0.08, 0.08]for measure, threshold in zip(measures, thresholds):if measure in fit_measures: fit_plot_data.append({'Measure': measure,'Value': fit_measures[measure],'Threshold': threshold })if fit_plot_data: fit_plot_df = pd.DataFrame(fit_plot_data) plt.figure(figsize=(8, 6)) bars = plt.bar(fit_plot_df['Measure'], fit_plot_df['Value'], alpha=0.7)# 添加阈值线for i, (measure, threshold) in enumerate(zip(measures, thresholds)):if measure in fit_measures: plt.axhline(y=threshold, color='r', linestyle='--', alpha=0.5)# 添加数值标签for bar, value in zip(bars, fit_plot_df['Value']): plt.text(bar.get_x() + bar.get_width() / 2, bar.get_height() + 0.01, f'{value:.3f}', ha='center', va='bottom') plt.title('CFA模型拟合指标') plt.ylabel('值') plt.ylim(0, max(fit_plot_df['Value'].max() * 1.2, 1)) plt.tight_layout() plt.savefig(os.path.join(results_dir, 'CFA_Model_Fit_Bar.png'), dpi=300) plt.close()print("✓ 拟合指标条形图已保存: CFA_Model_Fit_Bar.png") except Exception as e:print(f"✗ 拟合指标条形图生成失败: {e}")else:print("✗ CFA模型未能成功拟合,跳过后续分析")except ImportError:print("⚠ semopy包未安装,跳过CFA分析")except Exception as e:print(f"✗ CFA分析失败: {e}")# 创建分析报告print("\n正在生成分析报告...")# 创建文本报告report_file = os.path.join(results_dir, 'SEM_Analysis_Report.txt')try: with open(report_file, 'w', encoding='utf-8') as f: f.write("=" * 60 + "\n") f.write("结构方程模型分析报告\n") f.write("=" * 60 + "\n\n") f.write(f"生成日期: {datetime.now().strftime('%Y年%m月%d日')}\n") f.write("分析软件: Python with semopy, factor_analyzer\n\n") f.write("1. 数据概览\n") f.write(f"样本量: {sem_data_clean.shape[0]}\n") f.write(f"变量数: {sem_data_clean.shape[1]}\n") f.write("缺失值处理: 数值变量使用中位数填充\n\n") f.write("2. 探索性因子分析\n") try: f.write(f"KMO值: {kmo_model:.3f}\n") f.write(f"Bartlett检验p值: {p_value:.3f}\n") f.write(f"建议因子数: {n_factors}\n\n") except: f.write("EFA结果不可用\n\n") f.write("3. 验证性因子分析结果\n")if'cfa_fit'in locals() and cfa_fit is not None: f.write("模型设定:\n")if'measurement_model1'in locals(): f.write("单因子模型:\n" + measurement_model1 + "\n")if'measurement_model2'in locals(): f.write("双因子模型:\n" + measurement_model2 + "\n") f.write("\n模型拟合指标:\n")if'fit_table'in locals():for _, row in fit_table.iterrows(): f.write(f"{row['Measure']}: {row['Value']} [{row['Interpretation']}]\n") f.write("\n4. 主要发现\n") try:if'loadings_data'in locals() and len(loadings_data) > 0: f.write("标准化因子载荷:\n")for _, row in loadings_data.iterrows(): f.write(f"{row['lval']}->{row['rval']}: {row['Std. Estimate']:.3f}\n") except: f.write("因子载荷信息不可用\n")else: f.write("CFA模型未能成功拟合\n") f.write("\n5. 公共卫生意义\n") f.write("- 本研究通过因子分析探索了健康测量指标的结构\n") f.write("- 为后续的结构方程模型分析奠定了基础\n") f.write("- 强调了多维度健康评估的重要性\n") f.write("\n6. 研究局限与建议\n") f.write("- 样本量有限,未来需要更大样本验证\n") f.write("- 建议进行多组验证性因子分析(MG-CFA)\n") f.write("- 可考虑加入协变量进行更复杂的模型分析\n") f.write("\n\n") f.write("=" * 60 + "\n") f.write("报告结束\n") f.write("=" * 60 + "\n")print(f"✓ 文本报告已保存: SEM_Analysis_Report.txt")except Exception as e:print(f"✗ 文本报告生成失败: {e}")# 尝试创建Word报告print("\n正在尝试生成Word报告...")try: from docx import Document from docx.shared import Inches, Pt from docx.enum.text import WD_ALIGN_PARAGRAPH doc = Document()# 添加标题 title = doc.add_heading('结构方程模型分析报告', 0) title.alignment = WD_ALIGN_PARAGRAPH.CENTER# 添加日期 doc.add_paragraph(f'生成日期:{datetime.now().strftime("%Y年%m月%d日")}') doc.add_paragraph()# 1. 分析概述 doc.add_heading('1. 分析概述', level=1) doc.add_paragraph(f'本次分析基于{sem_data_clean.shape[0]}名个体的基线数据,进行验证性因子分析。')# 2. 模型拟合结果if'fit_table'in locals() and fit_table is not None: doc.add_heading('2. 模型拟合结果', level=1)# 创建表格 table = doc.add_table(rows=1, cols=3) table.style = 'Light Shading'# 添加表头 header_cells = table.rows[0].cells header_cells[0].text = '指标' header_cells[1].text = '值' header_cells[2].text = '解释'# 添加数据行for _, row in fit_table.iterrows(): row_cells = table.add_row().cells row_cells[0].text = str(row['Measure']) row_cells[1].text = str(row['Value']) row_cells[2].text = str(row['Interpretation'])# 保存Word文档 word_file = os.path.join(results_dir, f"SEM_Report_{datetime.now().strftime('%Y%m%d')}.docx") doc.save(word_file)print(f"✓ Word报告已保存: {word_file}")except ImportError:print("⚠ python-docx未安装,跳过Word报告生成")print(" 如需生成Word报告,请运行: pip install python-docx")except Exception as e:print(f"✗ Word报告生成失败: {e}")# 汇总输出print("\n" + "=" * 60)print("分析完成!")print("=" * 60)print(f"\n结果已保存至文件夹:{results_dir}")print("\n主要输出文件:")# 检查文件是否存在并列出output_files = [ ('文本分析报告', 'SEM_Analysis_Report.txt'), ('相关矩阵图', 'Correlation_Matrix.png'), ('碎石图', 'Scree_Plot.png'), ('EFA因子载荷图', 'EFA_Loadings.png'), ('CFA因子载荷图', 'CFA_Factor_Loadings.png'), ('拟合指标图', 'CFA_Model_Fit_Bar.png'), ('拟合指标表', 'CFA_Fit_Indices.csv'), ('参数估计表', 'CFA_Parameter_Estimates.csv'), ('EFA载荷表', 'EFA_Loadings.csv'),]for file_desc, file_name in output_files: file_path = os.path.join(results_dir, file_name)if os.path.exists(file_path):print(f"✓ {file_desc}: {file_name}")else:print(f"✗ {file_desc}: {file_name} (未生成)")# 检查Word报告word_file_pattern = os.path.join(results_dir, f"SEM_Report_{datetime.now().strftime('%Y%m%d')}.docx")import globword_files = glob.glob(os.path.join(results_dir, "SEM_Report_*.docx"))if word_files:print(f"✓ Word报告: {os.path.basename(word_files[0])}")else:print("✗ Word报告: (未生成)")print("\n\n提示:")print("1. 如需安装缺失包,请使用以下命令:")print(" pip install factor_analyzer semopy python-docx")print("2. 确保桌面有 'longitudinal_data.xlsx' 文件")print("3. 所有结果保存在 '12-SEM结果' 文件夹中")# 创建结果汇总表print("\n创建结果汇总表...")try:# 统计生成的文件 generated_files = []for _, file_name in output_files: file_path = os.path.join(results_dir, file_name)if os.path.exists(file_path): generated_files.append(file_name) summary_data = {'项目': ['分析完成时间', '数据样本量', '生成的图表', '生成的数据表', '总文件数'],'结果': [ datetime.now().strftime('%Y-%m-%d %H:%M:%S'), f"{sem_data_clean.shape[0]}", f"{len([f for f in generated_files if f.endswith('.png')])}个", f"{len([f for f in generated_files if f.endswith('.csv') or f.endswith('.txt')])}个", f"{len(generated_files) + len(word_files)}个" ] } summary_df = pd.DataFrame(summary_data) summary_file = os.path.join(results_dir, 'Analysis_Summary.csv') summary_df.to_csv(summary_file, index=False, encoding='utf-8-sig')print(f"✓ 分析汇总表已保存: Analysis_Summary.csv")except Exception as e:print(f"✗ 创建汇总表失败: {e}")print("\n✓ 所有分析完成!")