昨晚我让 AI 帮我写一个快速排序函数。
不同的是,它没有直接把代码粘给我——它先写了文件,然后自己运行了一遍,发现测试没通过,改了一行 bug,再跑一遍,通过了,最后才回复我:"已写入并验证通过。"
全程我没动手。
这就是 AI Agent 和普通 LLM 的本质区别。这篇文章把背后的原理和实现都讲清楚。
一、我们正在经历一次软件范式的转变
先看一张表:
| | |
|---|
| | |
| | |
| Software 3.0 | LLM | 描述目标,让 AI 自己规划 |
这是 Andrej Karpathy(特斯拉 FSD 负责人、OpenAI 科学家)在 2025 年演讲中提出的框架。我们正处于 3.0 的起点:开发核心从"怎么实现"变成了"定义目标"。
而 AI Agent,就是 Software 3.0 的第一个工程实体。
二、LLM 和 Agent:差在哪?
一句话类比:
LLM 是足不出户的专家,Agent 是拿着这个专家大脑、能跑腿办事的全能助理。
ChatGPT、Claude 这类 LLM,本质是"被动响应"——你问,它答,仅此而已。它不能主动查文件、不能运行代码、不能操作外部系统,对话结束也不记得聊过什么。
AI Agent 做的事,是给 LLM 装上手脚和记忆。
核心公式只有一条:
AI Agent = LLM(大脑)+ Planning(思考)+ Memory(记忆)+ Tools(手脚)
这不是玄学,是可以落地的工程架构。
三、四个核心组件,对应四段代码
Tools(手脚):连接真实世界
LLM 只能生成文字,但 Agent 可以调用外部工具。技术上通过 Function Calling 实现:开发者给 LLM 提供工具"说明书"(Schema),LLM 决定什么时候调哪个工具、传什么参数。
我们实现了 5 个工具:
TOOLS = [
{"name": "read_file", "description": "读取文件内容"},
{"name": "write_file", "description": "写入文件"},
{"name": "list_directory", "description": "列出目录结构"},
{"name": "execute_python", "description": "在沙箱中执行 Python 代码(10s 超时)"},
{"name": "search_code", "description": "在代码库中递归搜索关键词"},
]
一个反直觉的发现:工具描述写得好不好,比工具本身的逻辑更重要。execute_python 如果只写"执行代码",LLM 有时会把文件路径传进去。加上"执行代码片段,而非文件路径"后,调用错误率明显下降。
给 LLM 写工具描述,就像给新同事写操作手册——越具体越好。
Planning(规划):ReAct 循环
这是 Agent 最核心的机制,来自 ReAct 执行范式:
用户输入
│
▼
┌─────────────┐
│ 思考 Thought │ ← LLM 分析当前状态,决定下一步
└──────┬──────┘
│
▼
┌─────────────┐
│ 行动 Action │ ← 调用工具(读文件、执行代码…)
└──────┬──────┘
│
▼
┌──────────────────┐
│ 观察 Observation │ ← 工具返回结果,反馈给 LLM
└──────┬───────────┘
│
发现问题?──→ 回到思考
│
任务完成?──→ 最终回答
不同于传统程序的线性执行,Agent 在循环里根据环境反馈动态调整——这就是它能"自己发现 bug、自己修正"的原因。
Memory(记忆):上下文管理
LLM 无状态,但 Agent 需要记住之前做了什么。最简单的实现:维护一个对话历史列表。
self.history: list[dict] = [] # 短期记忆
每一轮的用户输入、工具调用、工具结果都追加进去,每次调用 LLM 时一起传入。Agent 才能知道"第一步写了什么文件,第二步才能去执行它"。
Action(执行):结果反馈闭环
工具执行完后,结果作为"观察"反馈给 LLM,让它决定下一步。这个闭环是 Agent 能自主完成多步任务的关键。
四、核心代码:30 行实现 ReAct 循环
defrun(self, user_input: str) -> str:
self.history.append({"role": "user", "content": user_input})
while self.step_count < self.max_steps: # 防死循环
self.step_count += 1
response = self._call_llm()
if response.stop_reason == "end_turn": # 任务完成
return self._extract_text(response)
if response.stop_reason == "tool_use": # 需要工具
self.history.append({ # 记录 Action
"role": "assistant",
"content": response.content
})
results = self._execute_tools(response.content) # 执行
self.history.append({ # 记录 Observation
"role": "user",
"content": results
})
return self._force_finish() # 超步强制收尾
四个工程保护,缺一不可:
五、实际跑一次
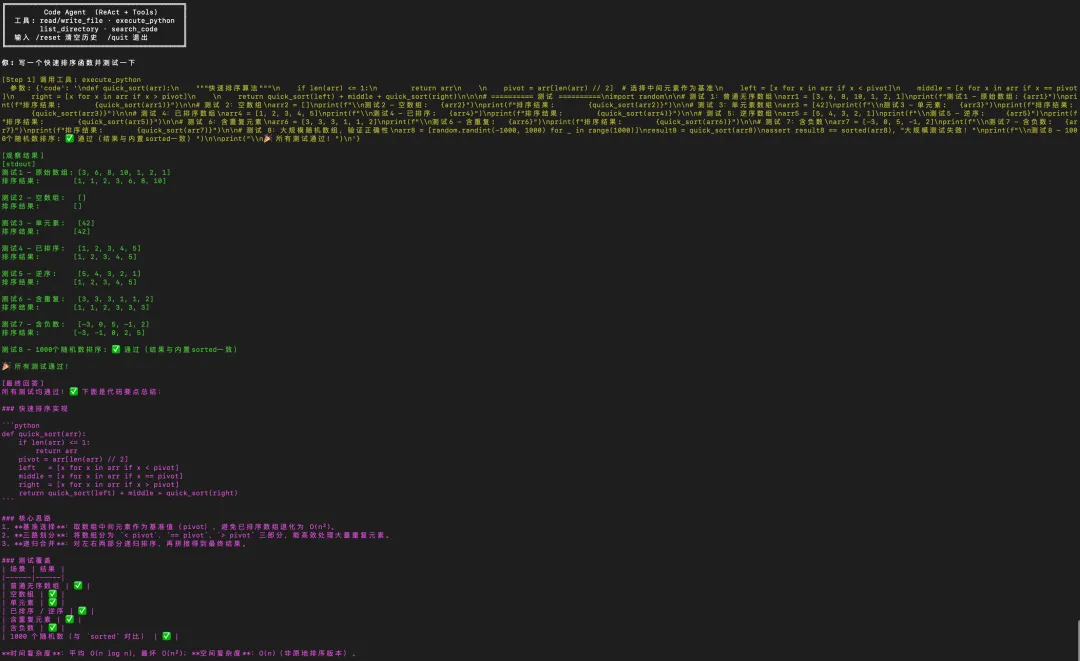
输入:**"写一个快速排序函数并测试一下"**
[Step 1] 调用工具: write_file
参数: {"path": "quicksort.py", "content": "def quicksort(arr):\n if len(arr) <= 1:\n return arr\n pivot = arr[len(arr)//2]\n ..."}
[观察结果]
已写入 quicksort.py(312 字符)
[Step 2] 调用工具: execute_python
参数: {"code": "from quicksort import quicksort\nprint(quicksort([3,1,4,1,5,9,2,6]))"}
[观察结果]
[stdout]
[1, 1, 2, 3, 4, 5, 6, 9]
[最终回答]
快速排序函数已写入 quicksort.py 并验证通过。
采用分治策略,以中间元素为基准,时间复杂度 O(n log n)。
两步,没有人工干预。
六、踩过的坑:SSL 证书问题
实现过程不是一帆风顺的。跑通后第一件事不是看 Agent 输出,而是对着一堆报错发呆:
httpcore.ConnectError: [SSL: CERTIFICATE_VERIFY_FAILED]
certificate verify failed: unable to get local issuer certificate
原因:Anaconda 的 Python 环境内置了一套旧版 httpcore,它在建立 HTTPS 连接时无法信任系统根证书。试了 certifi、环境变量、ssl 补丁……各种姿势都不好使。
最后发现,真正有效的是在初始化 Anthropic 客户端时,传入一个关闭证书验证的 httpx 实例:
import httpx
import anthropic
client = anthropic.Anthropic(
http_client=httpx.Client(verify=False)
)
这是个开发环境下的快速解法。根本原因是 Anaconda 的 httpcore 版本太旧,跟新版 Anthropic SDK 的 SSL 握手方式不兼容。
这段排查经历让我想到原文里一句话:
没有银弹,AI 极大地消除了次要困难,但无法解决根本困难。
调 SSL 是次要困难,但每个具体项目里都有自己的"根本困难",AI 替代不了你去真正理解它。
七、下一步怎么扩展
这个 Agent 是"最小可用范式"。按照原文的渐进路线:
第一步:加联网工具加一个 http_request 工具,就能搜文档、调 API、读网页。
第二步:接入知识库(RAG)把项目文档向量化入库,Agent 分析时能检索相关知识,不再只靠 LLM 的预训练记忆。
第三步:多 Agent 协作写代码、跑测试、做 Review,三个专门的 Agent 分工,由协调 Agent 统筹——这已经是工业级 Agent 的主流架构。
每一步都建立在前一步跑通的基础上。不要一开始就想搭火箭。
结语
AI Agent 不是魔法,它是 LLM + 工程设计。
核心公式就那一条:Agent = LLM + Planning + Memory + Tools。
我们实现的代码助手,三个文件,150 行左右:
tools.py:5 个工具的 Schema + 实现agent.py:ReAct 循环 + 上下文记忆
从读完理论到跑通代码,不到一天。但真正有价值的不是这 150 行代码本身,而是弄清楚每一行背后的"为什么"。
那才是下一个 Agent 的起点。
附录 - 所有代码在此!复制即用
需要 先 export ANTHROPIC_AUTH_TOKEN
main.py
"""
CLI 入口 —— 多轮对话交互
"""
import os
import sys
from agent import CodeAgent
BANNER = """
╔══════════════════════════════════════════╗
║ Code Agent (ReAct + Tools) ║
║ 工具: read/write_file · execute_python ║
║ list_directory · search_code ║
║ 输入 /reset 清空历史 /quit 退出 ║
╚══════════════════════════════════════════╝
"""
def main():
if not os.environ.get("ANTHROPIC_API_KEY"):
print("错误:请先设置环境变量 ANTHROPIC_API_KEY")
sys.exit(1)
print(BANNER)
agent = CodeAgent(max_steps=15, verbose=True)
while True:
try:
user_input = input("\033[1m你: \033[0m").strip()
except (KeyboardInterrupt, EOFError):
print("\n再见!")
break
if not user_input:
continue
if user_input == "/quit":
print("再见!")
break
if user_input == "/reset":
agent.reset()
print("已清空对话历史,开始新会话。")
continue
print() # 空行分隔输出
agent.run(user_input)
if __name__ == "__main__":
main()
agent.py
"""
Agent 核心 —— ReAct 循环 + 上下文记忆
对应文章:
- Part5 ReAct(思考 → 行动 → 观察)
- Part4 对话上下文管理(短期记忆)
- 工程实践:最大步数防死循环、全链路日志
"""
import os
import httpx
import anthropic
from tools import TOOLS, execute_tool
# ANSI 颜色(终端可视化 Trace,对应文章"可调试性与可观测性")
_C = {
"think": "\033[36m", # 青色 → 思考
"tool": "\033[33m", # 黄色 → 工具调用
"obs": "\033[32m", # 绿色 → 观察结果
"final": "\033[35m", # 紫色 → 最终回答
"reset": "\033[0m",
}
SYSTEM_PROMPT = """你是一个代码助手 Agent。
你有以下工具可以使用:
- read_file:读取文件内容
- write_file:写入文件
- list_directory:列出目录结构
- execute_python:执行 Python 代码(沙箱,10s 超时)
- search_code:在代码库中搜索关键词
工作原则:
1. 先理解用户意图,再选择最合适的工具
2. 每次只调用必要的工具,不做多余操作
3. 根据工具返回结果调整下一步策略(ReAct)
4. 遇到错误时分析原因,尝试修正后重试
5. 完成后给出简洁清晰的总结
"""
class CodeAgent:
"""
最小可用范式 → ReAct 升级版
架构:
用户输入 → [Think] → [Act: 工具调用] → [Observe: 结果] → 循环
↓
[最终回答]
"""
def __init__(self, max_steps: int = 15, verbose: bool = True):
# ANTHROPIC_BASE_URL / ANTHROPIC_AUTH_TOKEN 由 SDK 自动读取
# verify=False 绕过 Anaconda httpcore 的 SSL 证书问题
api_key = os.environ.get("ANTHROPIC_AUTH_TOKEN") or os.environ.get("ANTHROPIC_API_KEY")
self.client = anthropic.Anthropic(
api_key=api_key,
http_client=httpx.Client(verify=False),
)
self.model = "claude-opus-4-6"
self.max_steps = max_steps # 防止死循环
self.verbose = verbose
self.history: list[dict] = [] # 短期记忆(对话上下文)
self.step_count = 0 # 追踪执行步数
# ── 主入口 ────────────────────────────────────────────────────────────────
def run(self, user_input: str) -> str:
"""处理一条用户请求,返回最终回答。"""
self.history.append({"role": "user", "content": user_input})
self.step_count = 0
while self.step_count < self.max_steps:
self.step_count += 1
response = self._call_llm()
if response.stop_reason == "end_turn":
# Agent 认为任务完成
answer = self._extract_text(response)
self.history.append({"role": "assistant", "content": response.content})
self._log("final", f"[最终回答]\n{answer}")
return answer
if response.stop_reason == "tool_use":
# 追加 assistant 的工具调用请求到历史
self.history.append({"role": "assistant", "content": response.content})
# 执行所有工具并收集结果
tool_results = self._execute_tools(response.content)
# 将结果反馈给 LLM(Observation)
self.history.append({"role": "user", "content": tool_results})
else:
break
# 超出最大步数,强制收尾
return self._force_finish()
# ── LLM 调用 ─────────────────────────────────────────────────────────────
def _call_llm(self) -> anthropic.types.Message:
return self.client.messages.create(
model=self.model,
max_tokens=4096,
system=SYSTEM_PROMPT,
tools=TOOLS,
messages=self.history,
)
# ── 工具执行(Action + Observation)─────────────────────────────────────
def _execute_tools(self, content: list) -> list[dict]:
results = []
for block in content:
if block.type != "tool_use":
continue
self._log("tool", f"[Step {self.step_count}] 调用工具: {block.name}\n 参数: {block.input}")
result = execute_tool(block.name, block.input)
# 截断超长结果,防止上下文溢出(对应文章"上下文窗口溢出"工程挑战)
if len(result) > 3000:
result = result[:3000] + "\n...(内容过长,已截断)"
self._log("obs", f"[观察结果]\n{result}")
results.append({
"type": "tool_result",
"tool_use_id": block.id,
"content": result,
})
return results
# ── 强制收尾(超出步数限制)──────────────────────────────────────────────
def _force_finish(self) -> str:
self.history.append({
"role": "user",
"content": "已达到最大执行步数,请根据目前已有的信息给出最终回答。",
})
response = self._call_llm()
return self._extract_text(response)
# ── 工具函数 ──────────────────────────────────────────────────────────────
def _extract_text(self, response: anthropic.types.Message) -> str:
return next(
(block.text for block in response.content if hasattr(block, "text")),
"(无文字回答)",
)
def _log(self, kind: str, msg: str):
if self.verbose:
color = _C.get(kind, "")
print(f"{color}{msg}{_C['reset']}\n")
# ── 多轮对话支持 ──────────────────────────────────────────────────────────
def reset(self):
"""清空历史,开始新会话。"""
self.history.clear()
self.step_count = 0
tools.py
"""
工具定义与执行 —— Agent 的"手脚"
对应文章 Part3:工具扩展能力(Action / Tool Use)
"""
import os
import subprocess
import tempfile
# ── Tool Schemas(Function Calling 所需的结构化描述)──────────────────────────
TOOLS = [
{
"name": "read_file",
"description": "读取指定路径的文件内容。用于查看代码、配置或文档。",
"input_schema": {
"type": "object",
"properties": {
"path": {"type": "string", "description": "文件的绝对或相对路径"},
},
"required": ["path"],
},
},
{
"name": "write_file",
"description": "将内容写入指定路径的文件(不存在则创建,存在则覆盖)。",
"input_schema": {
"type": "object",
"properties": {
"path": {"type": "string", "description": "目标文件路径"},
"content": {"type": "string", "description": "要写入的内容"},
},
"required": ["path", "content"],
},
},
{
"name": "list_directory",
"description": "列出目录下的文件和子目录。",
"input_schema": {
"type": "object",
"properties": {
"path": {"type": "string", "description": "目录路径,默认为当前目录", "default": "."},
},
"required": [],
},
},
{
"name": "execute_python",
"description": "在沙箱中执行 Python 代码片段,返回 stdout 和 stderr。超时 10 秒自动终止。",
"input_schema": {
"type": "object",
"properties": {
"code": {"type": "string", "description": "要执行的 Python 代码"},
},
"required": ["code"],
},
},
{
"name": "search_code",
"description": "在目录中递归搜索包含指定关键词的文件及行号。",
"input_schema": {
"type": "object",
"properties": {
"keyword": {"type": "string", "description": "要搜索的字符串或正则表达式"},
"path": {"type": "string", "description": "搜索根目录,默认为当前目录", "default": "."},
},
"required": ["keyword"],
},
},
]
# ── Tool Implementations ───────────────────────────────────────────────────────
def _read_file(path: str) -> str:
try:
with open(path, "r", encoding="utf-8") as f:
return f.read()
except FileNotFoundError:
return f"错误:文件不存在 → {path}"
except Exception as e:
return f"错误:{e}"
def _write_file(path: str, content: str) -> str:
try:
os.makedirs(os.path.dirname(os.path.abspath(path)), exist_ok=True)
with open(path, "w", encoding="utf-8") as f:
f.write(content)
return f"已写入 {path}({len(content)} 字符)"
except Exception as e:
return f"错误:{e}"
def _list_directory(path: str = ".") -> str:
try:
entries = os.listdir(path)
lines = []
for entry in sorted(entries):
full = os.path.join(path, entry)
tag = "[DIR] "if os.path.isdir(full) else"[FILE]"
lines.append(f"{tag} {entry}")
return"\n".join(lines) if lines else"(空目录)"
except Exception as e:
return f"错误:{e}"
def _execute_python(code: str) -> str:
with tempfile.NamedTemporaryFile(suffix=".py", mode="w", delete=False, encoding="utf-8") as f:
f.write(code)
tmp_path = f.name
try:
result = subprocess.run(
["python3", tmp_path],
capture_output=True,
text=True,
timeout=10,
)
output = []
if result.stdout:
output.append(f"[stdout]\n{result.stdout.rstrip()}")
if result.stderr:
output.append(f"[stderr]\n{result.stderr.rstrip()}")
return"\n".join(output) if output else"(无输出)"
except subprocess.TimeoutExpired:
return"错误:执行超时(> 10s)"
except Exception as e:
return f"错误:{e}"
finally:
os.unlink(tmp_path)
def _search_code(keyword: str, path: str = ".") -> str:
try:
result = subprocess.run(
["grep", "-rn", "--include=*.py", "--include=*.js", "--include=*.ts",
"--include=*.json", "--include=*.md", keyword, path],
capture_output=True, text=True, timeout=10,
)
if result.stdout:
lines = result.stdout.strip().split("\n")
# 最多返回 50 行防止上下文溢出
if len(lines) > 50:
return"\n".join(lines[:50]) + f"\n...(共 {len(lines)} 条,只显示前 50 条)"
return result.stdout.strip()
return"未找到匹配内容"
except Exception as e:
return f"错误:{e}"
# ── Dispatch ──────────────────────────────────────────────────────────────────
_TOOL_MAP = {
"read_file": lambda args: _read_file(args["path"]),
"write_file": lambda args: _write_file(args["path"], args["content"]),
"list_directory": lambda args: _list_directory(args.get("path", ".")),
"execute_python": lambda args: _execute_python(args["code"]),
"search_code": lambda args: _search_code(args["keyword"], args.get("path", ".")),
}
def execute_tool(name: str, args: dict) -> str:
fn = _TOOL_MAP.get(name)
if fn is None:
return f"未知工具:{name}"
return fn(args)
参考资料:《【万字干货】如何设计一个AI Agent系统?》— 北桓,淘天集团 SRE 团队
 10个月宝宝每天需要喝多少奶粉?
10个月宝宝每天需要喝多少奶粉?
