第一章:虚拟文件系统(VFS)的诞生背景与核心哲学
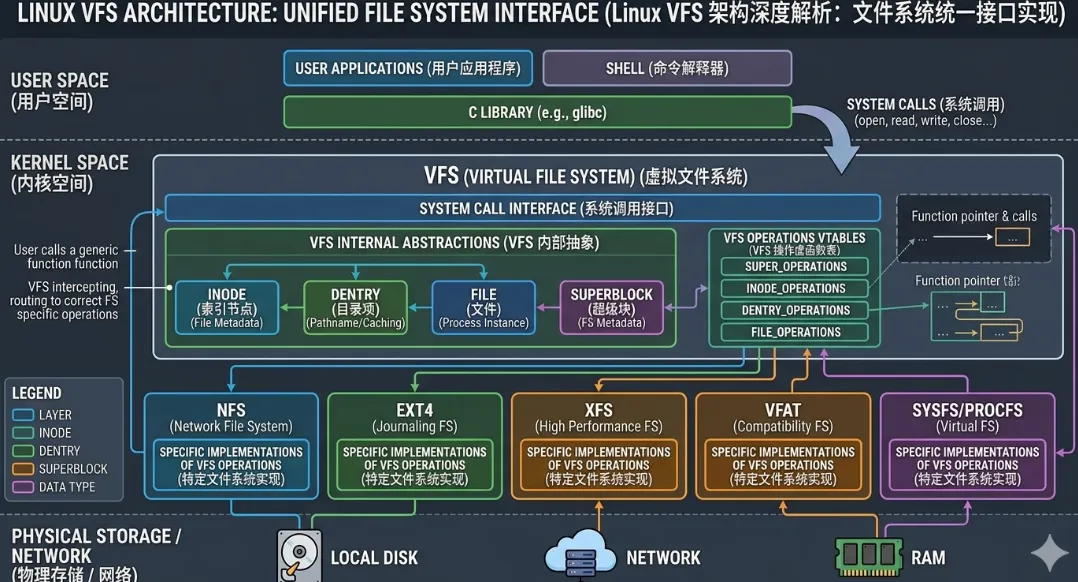
Linux 操作系统的成功很大程度上归功于其强大的抽象能力,而虚拟文件系统(Virtual File System, VFS)正是这种能力的集中体现。在早期的计算环境中,不同的硬件存储介质和文件格式(如 FAT、Ext2、NFS)拥有截然不同的访问逻辑,如果让应用程序直接处理这些差异,软件的兼容性将成为一场灾难。VFS 的核心哲学在于“万物皆文件”,它在内核态构建了一个中间层,为用户层屏蔽了底层物理介质的差异。这种设计的本质是面向对象思想在 C 语言中的极致应用,通过定义一组标准的数据结构和操作接口(如 read, write, open),无论底层是高速固态硬盘上的本地文件,还是通过网络传输的远程数据,亦或是存在于内存中的伪文件系统(如 procfs),对于用户程序而言,它们在表现形式上都是统一的文件描述符。
这种统一接口的实现并非简单的函数跳转,而是一套严密的层级化管理体系。从理论高度来看,VFS 扮演了“分发器”的角色。当进程发起系统调用时,内核首先进入 VFS 通用处理逻辑,根据路径名解析出对应的索引节点(inode),并找到该文件所属的具体文件系统类型。VFS 通过维护一套复杂的状态机,处理包括路径缓存(dentry cache)、挂载点管理以及文件权限检查在内的所有通用事务。这种解耦机制使得 Linux 内核能够极其方便地扩展新的文件系统类型:开发者只需按照 VFS 定义的规范实现特定的回调函数,即可让新文件系统即刻拥有与原生 Ext4 相同的系统调用支持。这种高度的灵活性和可扩展性,确保了 Linux 在从嵌入式设备到超算集群的各种场景下都能提供一致的存储体验。
第二章:VFS 四大核心对象之超级块(Superblock)
超级块是 VFS 架构中地位最高的数据结构,它代表了整个文件系统的元数据控制中心。每当一个文件系统被挂载(mount)到系统中时,VFS 都会创建一个超级块实例。它不仅记录了文件系统的基本参数(如块大小、文件系统类型、总容量、已用空间),更重要的是,它持有该文件系统的根目录索引节点以及指向具体文件系统操作函数的指针表 super_operations。在内存中,超级块是文件系统的“身份证”,通过它,内核可以快速定位该文件系统的所有管理逻辑。如果说文件系统是一本书,那么超级块就是这本书的版权页和目录索引的起始点,没有它,内核将无法理解存储介质上的原始字节流如何转化为有意义的文件结构。
从底层实现机制来看,超级块的管理涉及到复杂的同步与缓存策略。由于磁盘上的物理超级块(Disk Superblock)和内存中的 VFS 超级块(VFS Superblock)存在状态差异,内核必须负责处理脏数据写回(Dirty Writeback)。当文件系统挂载时,内核通过 read_super 函数将磁盘数据读入并填充 struct super_block。此后,所有的元数据修改都会先反映在内存副本中,并被标记为脏块,随后由内核线程在后台异步同步回物理介质。这种设计极大提升了系统响应速度。此外,super_operations 接口定义了诸如 alloc_inode、write_super 和 statfs 等核心行为,这使得 VFS 可以在完全不了解底层物理布局的情况下,驱动复杂的磁盘管理任务,实现了逻辑抽象与物理实现的完美隔离。
第三章:索引节点(Inode)的原理与元数据映射
索引节点(Inode)是 VFS 中最核心的实体,它代表了文件系统中一个具体的文件或目录。在 Linux 哲学中,文件名仅仅是人类可读的别名,而 inode 才是文件的真实身份标识(Inode Number)。每一个 inode 都包含了关于文件的物理位置、大小、创建时间、修改时间以及访问权限等关键信息。关键在于,inode 结构中并不包含文件名,这种设计巧妙地实现了硬链接(Hard Link)功能:多个文件名可以指向同一个 inode 编号。VFS 通过 struct inode 在内存中维护文件的活跃状态,并关联了一组极其重要的操作集 inode_operations,这些操作负责处理文件的逻辑属性修改,如创建链接、修改权限或重命名等。
在深入分析其映射机制时,我们需要关注 inode 与物理存储块之间的关联。在传统的块文件系统中,inode 记录了数据块的物理分布图(如多级寻址指针或 Extents)。当进程请求读取数据时,VFS 首先通过路径解析找到 inode,然后调用 i_op->lookup 等函数定位文件。为了提高效率,内核维护了一个全局的 inode 缓存(inode cache),通过散列表加速查找。对于嵌入式开发者而言,理解 inode 的生命周期至关重要:当文件的引用计数降为零且链接数为零时,inode 及其关联的存储块才会被真正释放。这种引用计数机制不仅保证了多进程并发访问的安全,也为实现原子性的文件覆盖和删除操作提供了理论基础。
第四章:目录项缓存(Dentry)与路径查找加速
如果说 inode 是文件的骨架,那么目录项(Dentry)就是文件系统的经络。在 VFS 中,dentry 的出现主要是为了解决路径名查找的性能瓶颈。由于 Linux 的路径是由多个层级组成的(如 /home/user/data.txt),如果每次访问文件都要从根目录开始逐层读取磁盘上的目录文件并进行字符串匹配,I/O 开销将难以承受。因此,VFS 引入了 struct dentry 对象,它在内存中建立起文件名与 inode 之间的快速映射。每个 dentry 代表路径中的一个组成部分,它们相互连接形成了一棵反映当前文件系统挂载状态的内存树。通过 dentry 缓存(dcache),内核可以将频繁访问的路径保留在高速内存中。
Dentry 的实现逻辑涉及复杂的哈希管理和引用计数。当用户输入一个路径时,内核首先在 dentry 哈希表中查找每一级目录。如果命中(Cache Hit),查找过程几乎是瞬时完成的;如果失效(Cache Miss),则需要调用底层文件系统的 lookup 函数从磁盘读取并填充新的 dentry 对象。需要注意的是,dentry 并没有对应的磁盘持久化结构,它完全是存在于内存中的动态对象。这种设计允许 VFS 在处理跨挂载点的路径时表现得异常透明:当路径穿过一个挂载点(Mount Point)时,dentry 树会自动切换到被挂载文件系统的根目录 dentry。此外,dentry 还有“负状态”(Negative Dentry)的概念,用于记录那些不存在的文件名,从而防止恶意程序通过频繁查询不存在的文件来实施拒绝服务攻击。
第五章:文件对象(File Object)与进程上下文
文件对象(File Object)代表了进程与文件之间的一次“对话”。与 inode 或 dentry 描述文件静态属性不同,文件对象 struct file 描述的是动态的访问状态。每当进程调用 open 系统调用时,内核都会创建一个新的 struct file。它包含了文件的当前偏移量(f_pos)、访问模式(只读、读写等)、状态标志(O_NONBLOCK 等)以及指向该文件所属 dentry 的指针。这意味着,如果两个进程同时打开同一个文件,它们会有各自独立的 struct file(即各自拥有独立的读写偏移量),但最终都指向同一个 dentry 和 inode。这种多对一的关系是实现进程间文件共享与隔离的基础。
文件对象通过 f_op 成员指向 file_operations 接口,这是驱动程序开发者最熟悉的结构。它包含了 read、write、mmap、ioctl 等函数指针。当进程执行 read 调用时,内核通过文件描述符在进程控制块(Task Struct)的打开文件表中找到对应的 struct file,进而调用 f_op->read。这一过程实现了从抽象接口到具体实现的精准跳转。对于高性能 I/O 开发,理解 struct file 的原子性操作和异步通知机制(如 FASYNC)至关重要。此外,文件对象的存在也支撑了文件锁定(flock)等并发控制功能,确保在多线程环境下文件读写位置的正确性,这种设计不仅优雅,而且极其高效。
第六章:VFS 挂载机制与命名空间隔离
挂载(Mounting)是 VFS 将物理设备集成到统一逻辑树的操作。在 Linux 中,挂载不仅仅是把磁盘分区关联到目录,它本质上是 VFS 管理结构的一次动态拼接。挂载过程由 mount 系统调用触发,内核会创建一个 vfsmount 结构来维护挂载点的信息。这个结构记录了父文件系统、当前文件系统的超级块以及挂载点所在的 dentry。通过这种设计,VFS 可以在遍历路径时检测到某个目录是否为挂载点,如果是,则平滑地切换到被挂载文件系统的根目录。这种递归的挂载能力支持了极其复杂的目录结构,例如在网络共享文件夹中再挂载一个虚拟的内存文件系统。
命名空间(Namespace)则是 VFS 挂载机制在容器化时代的进化。通过 CLONE_NEWNS 标志,Linux 允许每个进程拥有自己独立的挂载视图。这意味着在同一个物理系统内,进程 A 可能看到 /data 挂载在磁盘 1,而进程 B 看到 /data 挂载在磁盘 2。这种隔离是通过复制 vfsmount 树并进行局部修改实现的。在理论层面,这为实现轻量级虚拟化提供了核心支撑。VFS 的挂载管理还涉及传播属性(Shared, Private, Slave),这决定了在一个命名空间中的挂载操作是否会自动同步到其他命名空间。这种精细化的控制使得 VFS 能够完美支持 Docker 和 Kubernetes 等现代基础设施,成为了云原生技术栈的基石。
第七章:文件系统驱动注册与类型识别
为了支持五花八门的文件系统,VFS 必须拥有一套灵活的注册机制。每个文件系统驱动在初始化时,都会调用 register_filesystem 将自己的 file_system_type 结构体挂载到内核的全局链表中。这个结构体非常简洁,主要包含了文件系统的名称(如 "ext4")和指向 get_sb(或现代内核中的 mount)回调函数的指针。当用户执行挂载操作并指定 -t ext4 时,VFS 就会在这个全局链表中搜索对应的字符串,找到匹配的驱动程序来处理后续的物理初始化工作。这种基于字符串名称的动态匹配机制,体现了插件化设计的精髓。
在识别具体文件系统类型时,VFS 的处理逻辑体现了极强的健壮性。如果用户没有显式指定类型,内核可以尝试通过“魔数”(Magic Number)探测技术来自动识别磁盘格式。每种文件系统在磁盘的特定位置都会存储一个唯一的标识值。VFS 遍历已注册的驱动,依次调用它们的探测函数,直到某个驱动确认“这就是我的格式”。这一过程对用户是完全透明的。这种机制不仅简化了操作,也为系统引导时的根文件系统加载提供了保障。此外,通过 module_init 宏,文件系统驱动可以作为内核模块动态加载,这意味着无需重启系统即可获得对新文件格式的支持,极大提升了服务器环境下的运维灵活性。
第八章:VFS 层的数据缓存与 Page Cache 交互
VFS 并不是孤立运行的,它与内核的内存管理系统有着极深的耦合,其中最关键的纽带就是页缓存(Page Cache)。为了减少昂贵的磁盘 I/O 操作,VFS 几乎所有的读写操作都是围绕 Page Cache 展开的。当进程请求读取数据时,VFS 首先检查目标数据块是否已经缓存在物理内存页中。如果命中,则直接进行内存拷贝(Zero-Copy 技术的基础);如果缺失,则触发一次预读(Readahead)逻辑,从磁盘获取数据填充缓存。这种“缓存优先”的策略使得 Linux 在处理重复数据访问时表现出接近内存运行的惊人速度。
从实现细节来看,struct address_space 是连接 inode 与 Page Cache 的桥梁。每个 inode 都有一个 i_mapping 成员,它指向一个 address_space 结构,该结构管理着该文件所有在内存中的页面。它使用基数树(Radix Tree)或红黑树来维护文件偏移量到物理页面的映射。当系统内存不足时,内核的页面回收算法(LRU)会参考 VFS 的缓存状态,决定哪些干净页面可以释放,哪些脏页面需要写回磁盘。这种深度融合确保了系统在性能与数据一致性之间达到微妙的平衡。对于开发者来说,理解 O_DIRECT(绕过缓存)和 fsync(强制刷盘)的底层原理,本质上就是学习如何干预 VFS 与 Page Cache 的这种自动化交互行为。
第九章:VFS 架构的高级特性与未来演进
随着存储硬件的飞速发展,VFS 也在不断进化。一个重要的方向是异步 I/O 框架(如 io_uring)的深度集成。
传统的 VFS 调用是阻塞的,即使是非阻塞 I/O 在处理元数据操作时也可能发生停顿。io_uring 通过在用户态和内核态之间建立共享环形缓冲区,彻底改变了 VFS 的调用范式,使得成千上万的文件操作可以批量、异步地提交,极大地提升了 NVMe 存储时代的吞吐量。此外,为了支持非易失性内存(NVDIMM),VFS 引入了 DAX(Direct Access)模式,允许应用直接访问存储设备的物理地址,彻底绕过传统的 Page Cache 层。
 10个月宝宝每天需要喝多少奶粉?
10个月宝宝每天需要喝多少奶粉?
