总体思路:让 AI 写代码,我负责踩坑和封装
这次的玩法有点不一样——代码不是我一行行敲的,而是让 DeepSeek 帮我写的。
我先根据《河南省村庄规划数据库标准》,让 DeepSeek 整理出三张配置表:要素数据集、图层、字段。然后告诉它我的需求:用 Python 写个脚本,在 ArcGIS 10.7 里读这三张表,自动建库、建图层、加字段,还要带进度条和错误日志。
AI 吐出来的代码框架挺像回事,但一跑就各种水土不服。于是我的工作变成了:拿 AI 的代码当毛坯房,我来精装修——调试编码问题、修坐标系 bug、加名称清洗、补异常捕获,最后再挂到 ArcToolbox 里封装成标准工具。脚本运行逻辑:
读取 CSV 配置表 → 创建文件地理数据库 → 创建要素数据集 → 创建要素类 → 批量添加字段
添加脚本工具
写好的 .py 文件不能直接双击运行,得挂到 ArcGIS 的工具箱里才能用。这一步本身不复杂,但参数设置错了后面全白搭。我把配置步骤列出来,照着做就行。
1. 新建工具箱打开 ArcMap 或 ArcCatalog,在目录树里找到“我的工具箱”,右键 → 新建 → 工具箱,起个名字,比如“村庄规划工具”。
2. 添加脚本右键刚建好的工具箱 → 添加 → 脚本。弹出向导:
名称:填 村庄规划建库(这就是工具显示的名字)
标签:随便填,用于搜索
描述:写清楚工具干嘛的,可选
脚本文件:点文件夹图标,选你保存的 .py 文件
在进程中运行:不勾选(默认)
3. 设置参数
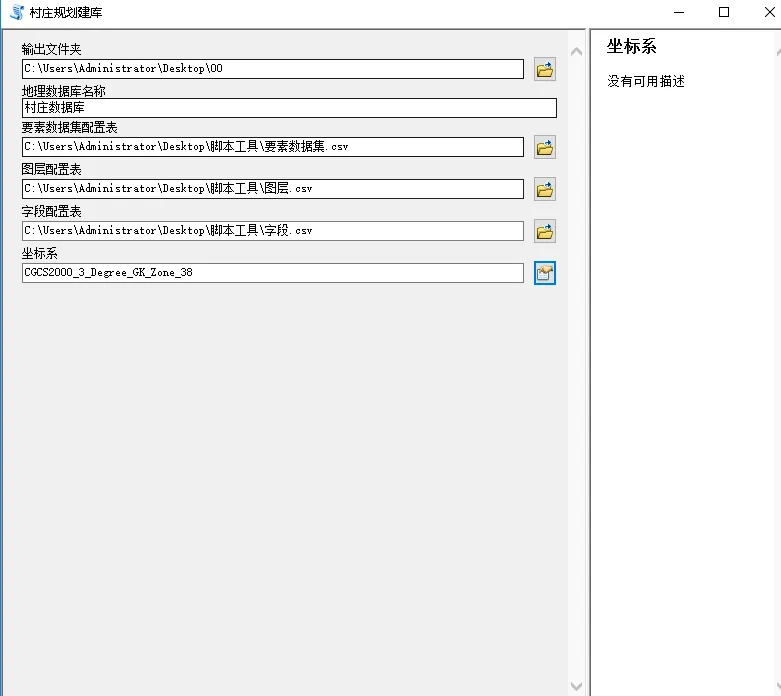
这一步决定了工具界面长什么样、用户要填哪些东西。按顺序添加 6 个参数:
重点说一下 参数属性 的细节:
配置完的界面长这样:
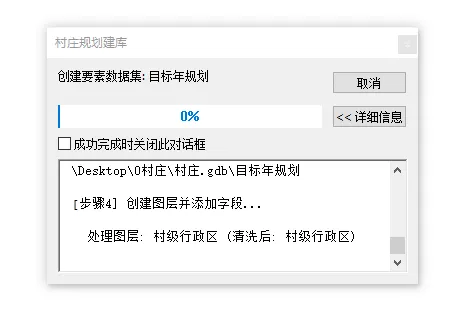
4. 运行测试填好参数,点确定。工具开始跑,进度条会显示当前步骤和剩余时间,地理处理窗口里实时输出日志。如果 CSV 配置没问题,很快就能看到数据库生成完毕。
避坑指南
坑 1:脚本一跑就 SyntaxError,连第一行都过不去
现象:工具刚点确定,地理处理窗口直接飙红,报 SyntaxError: EOL while scanning string literal,或者 UnicodeDecodeError。
原因:ArcGIS 10.7 自带的 Python 是 2.7 版本,对中文支持天生残疾。如果你的脚本存成了 UTF-8,但没在文件头声明编码,或者声明了但文件本身带 BOM,Python 解释器会用默认的 ASCII 去读文件,一碰到中文立马歇菜。
解决:我试了好几种组合,最后发现最稳妥的办法是:
cp936 就是 Windows 简体中文的代码页,这样 Python 用本地编码读文件,里面的中文注释、中文字符串全都老老实实,再也不报错了。
坑 2:读 Excel 比登天还难,xlrd 和 openpyxl 轮番掉链子
需求:从三张 Excel 表里读配置——要素数据集、图层、字段。
第一次尝试:用 xlrd。安装倒挺顺利,但一读中文路径就报 IOError,说找不到文件。查了半天,原来是 Python 2 里的 xlrd 对 Unicode 路径处理有 bug。换成英文路径能读了,但单元格里的中文又变成乱码。
第二次尝试:用 openpyxl。这个库对 .xlsx 支持好,安装也简单:pip install openpyxl==2.6.4。读取没问题了,但速度有点慢,而且共享给别人,别人还要安装openpyxl库。
终极方案:我一拍大腿,干嘛非得跟 Excel 较劲?用 CSV 不香吗?
CSV 是纯文本,Python 内置 csv 模块零依赖,编码完全可控。只需把 Excel 另存为 UTF-8 编码的 CSV,后续读取没啥问题。
CSV 读取核心代码(解决中文乱码的关键):
with open(csv_path, 'rb') as f: content = f.read().decode('utf-8')lines = content.splitlines()reader = csv.reader(lines)for row in reader: decoded_row = [cell.decode('utf-8') for cell in row]
注意:必须先用二进制模式读,整体解码成 Unicode,再用 csv.reader 解析。如果直接传 Unicode 给 csv.reader,Python 2 会再次用 ASCII 编码,照样报错。
坑 3:坐标系参数传进去就报“该值不是空间参考”
现象:工具界面明明选了坐标系(比如 CGCS2000 3 Degree GK Zone 38),运行到创建要素数据集那一步时,ArcGIS 直接甩脸:
原因:arcpy.GetParameter(5) 返回的可能是字符串(WKT 或名称),也可能是 SpatialReference 对象,但直接传给 CreateFeatureDataset_management 不一定兼容。尤其在 ArcGIS 10.7 里,工具界面的坐标系参数经常返回一个无法直接识别的字符串。
解决:写一个健壮的坐标系解析函数,不管输入什么格式,都强行转成可用的 SpatialReference 对象:
def get_spatial_reference(input_param): if hasattr(input_param, 'factoryCode'): return input_param sr_str = str(input_param) try: return arcpy.SpatialReference(int(sr_str)) except: pass try: return arcpy.SpatialReference(sr_str) except: pass if sr_str.endswith('.prj') and os.path.exists(sr_str): return arcpy.SpatialReference(sr_str) sr = arcpy.SpatialReference() sr.loadFromString(sr_str) return sr
有了这个函数,无论参数是啥,都能稳稳当当转成坐标系对象,再也没报过 000840。
坑 4:图层名称包含括号、空格,ArcGIS 直接拒绝
现象:CSV 里图层名叫 交通基础设施(点),看起来挺正常,结果创建要素类时 ArcGIS 报错:
原因:ArcGIS 要素类命名规则非常严格——只能包含字母、数字、下划线,且不能以数字开头。括号、空格、中文横线全都不允许。
解决:写一个名称清洗函数,把非法字符全替换成下划线,如果首字符是数字就加个前缀:
import redef sanitize_name(name): cleaned = re.sub(ur'[^\u4e00-\u9fa5a-zA-Z0-9_]', u'_', name) cleaned = re.sub(ur'_+', u'_', cleaned).strip(u'_') if cleaned and cleaned[0].isdigit(): cleaned = u'F' + cleaned return cleaned if cleaned else u'FeatureClass'
清洗后 交通基础设施(点) → 交通基础设施_点_。别名(Alias)还是用原来的中文名,既符合规范又不影响可读性。
坑 5:字段长度和精度读出来是文本,添加字段时报错
现象:字段添加时 ArcGIS 报 ERROR 001526: 字段长度无效。
原因:CSV 里字段长度列填的 18,但 csv 读出来全是字符串 '18',而 arcpy.AddField_management 要求整数。
解决:读取时强制类型转换,并加上 try-except 兜底:
length = Noneif row[idx_len]: try: length = int(row[idx_len]) except: arcpy.AddWarning(u"字段长度值无效,将使用默认值")
这样不管用户填的是数字还是文本,都能正确转成整数。
坑 6:进度条一动不动,用户以为工具卡死了
现象:创建大量图层和字段时,工具界面一片空白,进度条纹丝不动,同事跑过来问我:“你这工具是不是挂了?”
解决:用 arcpy.SetProgressor 和 SetProgressorLabel 实时更新状态。每完成一个子任务就调用 SetProgressorPosition(),顺便估算剩余时间:
arcpy.SetProgressor("step", u"正在创建数据库...", 0, total_steps, 1)for i, layer in enumerate(layers): arcpy.SetProgressorPosition(current_step) arcpy.SetProgressorLabel(u"正在创建:{0}".format(layer_name))
加上这个之后,用户能清楚看到当前进度和剩余时间,再也没人怀疑工具卡死了。
坑 7:出错后看不到真正原因,日志里只有 ERROR 999999
现象:脚本崩溃只显示 ERROR 999999,完全不知道哪里错了。
解决:在最外层 main() 里用 try-except 包裹,并用 traceback.format_exc() 打印完整堆栈:
except Exception as e: arcpy.AddError(u"错误信息:{0}".format(safe_unicode(e))) arcpy.AddError(traceback.format_exc()) raise
这样一来,出错时日志里会清清楚楚显示哪个文件的第几行、什么原因,调试效率直接翻倍。
最终效果:一键生成 10+ 图层的村庄规划空库
经过这七重磨砺,脚本终于稳定下来。看看最终成果:
工具界面清爽,运行日志详细,即使不懂代码的同事也能根据日志快速排查配置表错误。原本需要半天的手工建库工作,现在一杯咖啡的功夫就搞定了。
我的几点小感悟
Python 2.7 环境下的中文编码:Windows 下用 ANSI + cp936 声明最稳,别死磕 UTF-8。
数据源能用 CSV 就别碰 Excel:省去第三方库依赖,编码完全可控。
坐标系参数永远不要直接信任:封装一个万能的解析函数,以不变应万变。
名称清洗是必备工序:用户输入什么奇葩字符都有可能,自动清洗保平安。
进度条和日志是工具的脸面:让用户知道工具在干活,出错时能快速定位。
异常捕获要彻底:用 traceback 打印全堆栈,别让错误信息被吞掉。
最后说一句:工具是给人用的,多花一点时间让界面友好、日志清晰,能省下无数解释的时间。
需要完整脚本的朋友,可以在公众号后台回复「村庄规划建库」,我把 CSV 版脚本和示例配置表打包发给你。
技术之路,踩坑不断,填坑不止。与各位共勉!
📌 今日学习笔记
学到了什么:
代码对比:
之前:手工建库,半天起步
现在:一键运行,2 分钟搞定
用时:4小时
心情: 看着工具刷刷刷建库,成就感满满
📢 我是老李,35岁规划师,从零开始学AI。
每天1小时,记录真实学习路。不求成为大神,只为多一条出路。
如果你也在传统行业或者对未来感到焦虑,如果你也想学点新东西但一直没有开始
点击关注,我们一起进步;
也欢迎点赞 ❤️ 分享 ➕ 推荐,让更多同行者看到!
👇👇👇

 10个月宝宝每天需要喝多少奶粉?
10个月宝宝每天需要喝多少奶粉?
