AI+Python丨计量经济学多源数据处理、机器学习预测及复杂因果识别
AI与Python双驱动计量经济学多源数据处理、机器学习预测及复杂因果识别全流程实战班直播时间:2026年4月18日-19日、25日-26日
【四天教学、提供全部资料、代码及长期回放】
随着数字经济时代的全面到来,经济学与管理学的研究范式正经历着一场深刻的“数据革命”。传统的计量经济学模型虽然在因果推断方面具有严谨的理论基础,但在面对海量、高维、非标准化、非结构化数据(如文本、图像)时,往往显得力不从心。与此同时,机器学习(Machine Learning)和深度学习等前沿计算方法,虽然展现了强大的预测能力,却常因“黑箱”属性而难以满足社会科学对“可解释性”与“因果机制”的严苛要求。当前,“计量经济学+机器学习”(Econometrics + ML)的交叉融合已成为国际顶刊发表的新趋势。如何将机器学习对高维数据的处理能力与计量经济学的因果推断框架有机结合(如双重机器学习DML),如何利用自然语言处理(NLP)技术从政策文本中提取量化指标,以及如何利用可解释人工智能(XAI)打开模型黑箱,已成为当代科研工作者亟需掌握的核心竞争力。本课程正是基于这一前沿学术背景,旨在打破学科壁垒,通过Python这一强大工具,并利用AI辅助编程,极大降低入门难度,平滑学习曲线,助力实现从经典计量到前沿机器学习方法的全面赋能。本课程面向经济学、管理学及相关社会科学领域的研究生与青年学者。课程设计不仅仅是代码教学,而是“方法论+工具流+发表导向”的深度融合。内容涵盖从科研起点的规范化构建,到高质量数据的清洗与宏观/微观数据库对接;从经典计量模型(OLS,Logit,DID,DEA,ARIMA,TWFE等)的Python实现,到前沿机器学习算法(XGBoost,Random Forest,SVM,Stacking等)的实战应用。特别强调因果推断与机器学习的结合,深入讲解双重机器学习(DML)在因果识别中的应用,以及如何利用SHAP、PDP等方法提高模型的可解释性。此外,课程还引入了文本分析(TF-IDF,LDA,Word2Vec)与空间聚类等拓展方法,帮助学员将非结构化、非标准化数据纳入经济学分析框架,全方位提升实证研究的广度与深度。2.超级福利:1个月ChatGPT会员【可同时使用Claude、Gemini、Grok等模型,无需科学上网】网络直播+助学群辅助+导师面对面实践工作交流(报名后加入助学群、查阅会议流程)
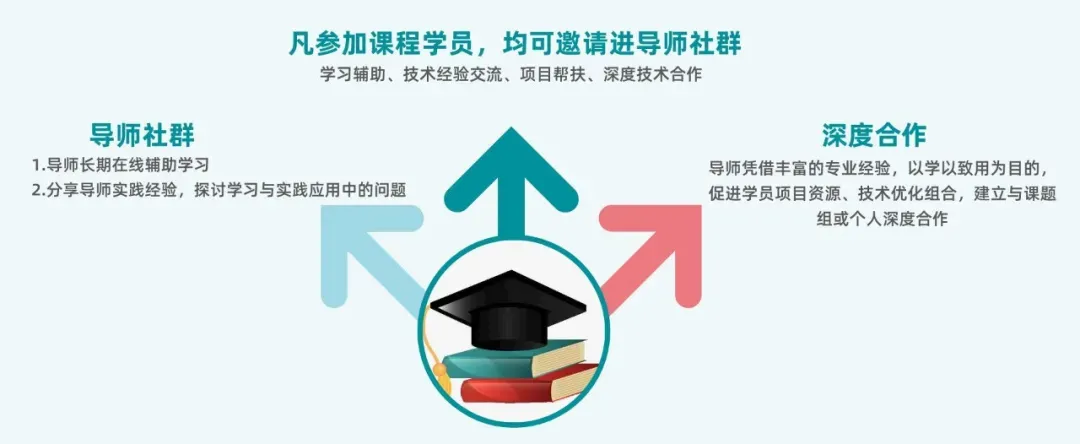
1.建立导师助学交流群,长期进行答疑及经验分享,辅助学习及应用;
2.课程结束后不定期召开线上答疑交流,辅助学习巩固工作实践问题处理交流;
1、原理深入浅出的讲解;
2、技巧方法讲解,提供所有案例数据及代码;
3、与项目案例相结合讲解实现方法,对接实际工作应用 ;
4、跟学上机操作、独立完成案例操作练习、全程问题跟踪解析;
5、课程结束专属助学群辅助巩固学习及实际工作应用交流,不定期召开线上答疑;
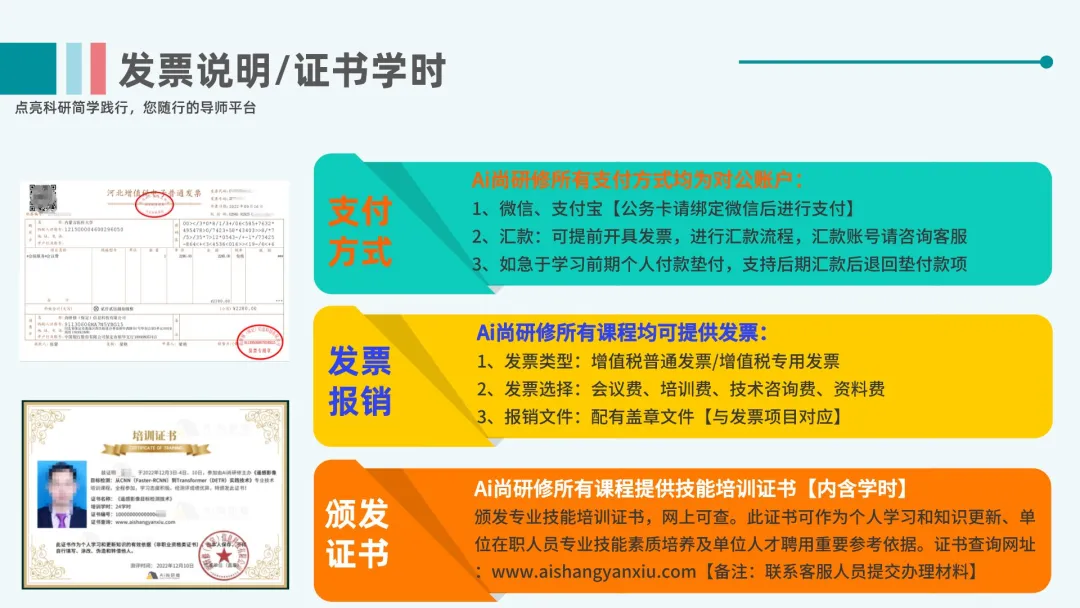
参加培训的学员可以获得《AI+Python计量经济学技术应用》专业技术证书及学时证明,网上可查。此证书可作为学时证明、个人学习和知识更新、单位在职人员专业技能素质培养及单位人才聘用重要参考依据。证书查询网址:www.aishangyanxiu.com注:办理证书需提供电子版2寸照片及姓名、身份证号信息,开课前发给会务组人员发票类别:培训费、会议费、资料费、技术咨询费等,配有盖章文件等,用于参会人员报销使用
专题一、科研写作框架(文献管理软件,资料分类整理方法)1.搭建科研写作框架(研究文献的粗读→研究问题的确定→研究框架搭建(引言、文献综述、研究设计、研究结果与分析、政策启示与结论、研究摘要与关键词)→论文撰写与发表)2.运用金字塔原理规范写作习惯(文字的高效精准表达与背后的原因);1.描述统计:均值/中位数、方差、四分位距、偏度/峰度;2.推断统计:抽样分布、置信区间构造、假设检验(t检验、ANOVA、卡方);专题三、多源异构数据整合(宏观数据库、微观调查与政策文本的获取与清洗)1.宏观数据:World Bank、CEADs(中国碳核算数据库)、国家统计局(统计年鉴、统计公报)、ESGF(气象数据cimp6)、国家气象科学数据中心;2.微观数据:CFPS(中国家庭追踪调查)、CHFS(中国家庭金融调查)、企业年报(Wind/CSMAR/Tushrae)结构解析;3.网络数据:Requests + BeautifulSoup爬取政策文本或新闻;4.清洗流程:缺失值处理(删除/插补)、异常值检测(IQR/Z-score)、变量标准化、面板数据构建(MultiIndex + merge)。专题四、经济学核心研究内容(综合评价、因果识别与预测)1.评价:单指标评价、多指标综合评价(AHP、PCA、DEA等)、自动分类评价(K-Means、SVM等)2.因果分析:在理论指导的前提下,建立模型,寻找真正的因果关系专题五、多指标综合评价(OPSIS-熵权法、DEA、K-Means)1.TOPSIS-熵权法:通过熵权法确定各指标的权重,再利用TOPSIS方法对评价对象进行排序,从而实现对多指标决策问题的科学评估;(重点)2.DEA:基于线性规划的非参数方法,用于评估多输入多输出决策单元(DMU)的相对效率;(重点)3.K-Means:通过迭代优化簇中心和数据点的分配,使得簇内距离最小化,从而实现数据的分组。专题六、经典因果推断方法(OLS、固定效应、双重差分(DID)与工具变量(IV))3.VAR:向量自回归模型(Vector Autoregression, VAR),用于分析多个时间序列变量之间动态关系的统计模型;4.ARIMA:(自回归积分滑动平均模型,Autoregressive Integrated Moving Average)是一种广泛应用于时间序列分析和预测的统计模型;5.门限回归:用于分析数据中存在结构变化或阈值效应的统计方法;6.DID:基于自然实验设计的计量经济学方法,用于评估政策或干预措施的因果效应;7.面板模型:固定效应(FE)vs 随机效应(RE),Hausman检验;8.聚类标准误(clustered SE)处理组内相关;(重点)专题七、机器学习赋能因果与预测(树模型、正则化回归与双重机器学习(DML)) 1.Decision Tree:通过一系列规则将数据划分为不同的类别或预测连续值,适用于非线性关系和分类问题;2.Gradient Boosting Decision Tree:通过逐步训练一系列决策树,每次训练都试图纠正前一次训练的残差(即误差),从而提高模型的整体预测性能;3.XGBoost:通过优化决策树的构建过程,提高模型的预测性能,适用于复杂数据集;4.Random Forest:集成多个决策树,通过随机抽样和特征选择提高模型的稳定性和准确性,适用于大规模数据集;5.SVM:主要用于分类和回归任务。其核心思想是通过寻找一个最优超平面,将不同类别的数据点分开,同时最大化分类间隔;6.Category Boost:基于梯度提升的机器学习算法,无需进行预处理。7.AdaBoost:基于提升(Boosting)的集成学习方法,通过组合多个弱学习器(通常是简单的模型,如决策树桩)来构建一个强学习器。9.提高均方误差(MSE,Mean Squared Error),平均绝对误差(MAE,Mean Absolute Error),决定系数(R2,R-squared)等3个指标,选取最优模型;10.DML:结合机器学习与传统计量经济学的因果推断框架,旨在高维数据和非线性关系下无偏估计处理变量对结果变量的因果效应。(重点)11.在确定存在因果关系的前提下,捕捉非线性关系,提高研究精度。Moran's I 空间聚类:用于衡量空间自相关性的统计指标,通过比较一个位置的值与邻近位置的值之间的相似性来确定空间自相关性。专题九、文本量化分析(LDA主题建模、词向量与语义指数构建)1.TF-IDF(Term Frequency-Inverse Document Frequency):通过计算词频(TF)和逆文档频率(IDF)来衡量单词在文档中的重要性。TF-IDF值随着单词在文档中出现的频率成正比增加,但同时会随着单词在语料库中出现的频率成反比下降;2.LDA(Latent Dirichlet Allocation):从文本数据中发现隐藏的主题结构。它假设每篇文档是由多个主题组成的混合体,每个主题又由多个单词组成;(重点)3.Word2Vec:通过神经网络模型将单词映射到低维向量空间,使得语义相似的单词在向量空间中靠近;4.Doc2Vec:通过将文档映射到低维向量空间,能够捕捉文档的语义信息。(重点)专题十、可解释机器学习(Explainable Machine Learning, XAI)(理解复杂机器学习模型的决策过程)1.SHAP(SHapley Additive exPlanations):来自合作博弈论,用于衡量每个特征对模型预测的贡献。SHAP值表示每个特征在所有可能的特征组合中的平均边际贡献;2.PDP(Partial Dependence Plots):展示了一个特征对模型预测的平均影响,通过固定其他特征,观察该特征变化对预测结果的影响;3.LIME(Local Interpretable Model-agnostic Explanations):通过在局部邻域内拟合一个简单的模型(如线性回归),解释复杂模型在单个预测样本上的行为。1.时间预测和条件预测:归因模型都可以用于条件预测,前提是找到合适的先行指标。2.Grey Prediction:通过灰色系统理论,对小样本数据进行预测。3.LSTM:能够学习数据中的长期依赖关系。它通过引入门控机制(输入门、遗忘门、输出门)来控制信息的流动,从而有效解决传统RNN的梯度消失问题,<在线课程推荐-提供全部资料及回放视频、导师群辅助答疑>添加客服微信宋老师:15383025520领取详细的培训通知



 NO1:平台逐步建立完整的教学方案,深度促进科研交叉技术融合,成为众多课题组及个人实践技术提升首选内容。NO2:Ai尚研修为了更好的发展,特邀30多位专家学者作为顾问专家,为Ai尚研修平台长期发展提供了宝贵的建议及工作指导。NO3:Ai尚研修创建云导师教学模式,最大化促进交叉学科的专业问答及交流,已经建立云导师社群300+,不仅可以学习,还为您身边带来专业的导师。NO4:Ai尚研修建立了长期免费学术讲座:聚焦基础原理、前沿热点技术、庖丁解文、实践技术、成果推广等专题,每月4期左右,已开展完200+期,上平台都可以免费观看前期讲座。NO5:为了深度对接用户需求,依托专家团队,针对技术咨询服务、数据处理合作、软件开发、搭建高性能计算平台等领域开展合作。
NO1:平台逐步建立完整的教学方案,深度促进科研交叉技术融合,成为众多课题组及个人实践技术提升首选内容。NO2:Ai尚研修为了更好的发展,特邀30多位专家学者作为顾问专家,为Ai尚研修平台长期发展提供了宝贵的建议及工作指导。NO3:Ai尚研修创建云导师教学模式,最大化促进交叉学科的专业问答及交流,已经建立云导师社群300+,不仅可以学习,还为您身边带来专业的导师。NO4:Ai尚研修建立了长期免费学术讲座:聚焦基础原理、前沿热点技术、庖丁解文、实践技术、成果推广等专题,每月4期左右,已开展完200+期,上平台都可以免费观看前期讲座。NO5:为了深度对接用户需求,依托专家团队,针对技术咨询服务、数据处理合作、软件开发、搭建高性能计算平台等领域开展合作。云导师【点亮科研简学践行、您的随行导师平台】
会员专享
如何成为会员:
1.凡参加Ai尚研修收费课程即为会员;2.充值5000元即可成为会员(费用直接使用)。
会员特权:
1.参加直播、视频课程费用累积进行折扣,享8.5折-7.5折 (一阶会员8.5折,高阶会员8折,尊享会员7.5折);2.参与课程组织与报名,推荐者可获得课程5%推荐现金;3.免费享受Ai尚研修会议平台中“会员免费”视频教程;4.长期免费参与针对各领域简学实用公开课(无门槛);5.免费参与开设的导师面对面线上答疑交流;6.Ai尚研修资源站分享中数据免费下载。
【报名方式】宋鹏:15383025520(微信)
声明: 本号旨在传播、传递、交流,对相关文章内容观点保持中立态度。涉及内容如有侵权或其他问题,请与本号联系,第一时间做出撤回。






 10个月宝宝每天需要喝多少奶粉?
10个月宝宝每天需要喝多少奶粉?
