每到月底,财务伙伴对着堆积如山的报销单,眼睛发酸是常事——人工审核像“大海捞针”,对于那些异常的费用,稍不注意就漏掉了。今天咱们用Python的孤立森林算法,把“找异常”变成“自动筛”,让大家少熬点夜!
二、孤立森林是啥?用“切西瓜挑榴莲”秒懂原理
我们想象有一筐圆滚滚的西瓜(正常数据)和几个浑身是刺的榴莲(异常数据),闭着眼分开它们:
榴莲“格格不入”,切1-2刀就能单独拎出来(异常数据特征特殊,孤立步数少);
西瓜长得像,得切好多刀才分得开(正常数据扎堆,孤立步数多)。
核心逻辑:异常数据的“孤立路径”更短,算法用这个特点精准“抓刺头”。
三、PyCharm实战:3步搞定异常报销识别
1. 装库+模拟数据
先装必备库(终端输命令):
pip install pandas numpy scikit-learn matplotlib
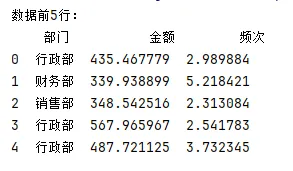
模拟1000条报销数据(含3个天价/高频异常),固定随机种子
import matplotlib.pyplot as pltimport pandas as pdimport numpy as npplt.rcParams['font.sans-serif'] = ['SimHei']plt.rcParams['axes.unicode_minus'] = False# 模拟1003条报销记录np.random.seed(42)data = {'部门': np.random.choice(['销售部', '技术部', '行政部', '财务部'], 1003),'金额': np.random.normal(500, 100, 1000).tolist() + [5000, 6000, 4500],'频次': np.random.normal(3, 1, 1000).tolist() + [15, 18, 20]}df = pd.DataFrame(data)print("数据前5行:")print(df.head())
2. 训练“侦察兵”:构建孤立森林模型
选金额、频次两个关键特征(数值型最管用),用IsolationForest建模:
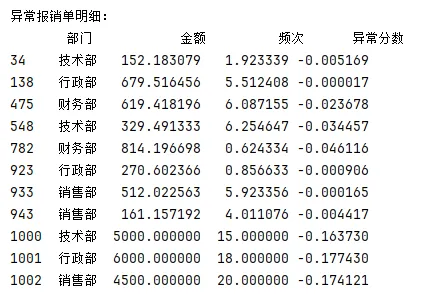
from sklearn.ensemble import IsolationForest# 选两个关键特征:金额和频次(数值型数据)X = df[['金额', '频次']]# 初始化模型:contamination=0.01表示预计有1%的异常数据model = IsolationForest(contamination=0.01, random_state=42)# 训练模型(fit)+ 预测异常(predict)df['异常标记'] = model.fit_predict(X) # -1表示异常,1表示正常df['异常分数'] = model.decision_function(X) # 分数越接近-1,越异常# 查看被标记为异常的报销单anomalies = df[df['异常标记'] == -1]print("\n异常报销单明细:")print(anomalies[['部门', '金额', '频次', '异常分数']])
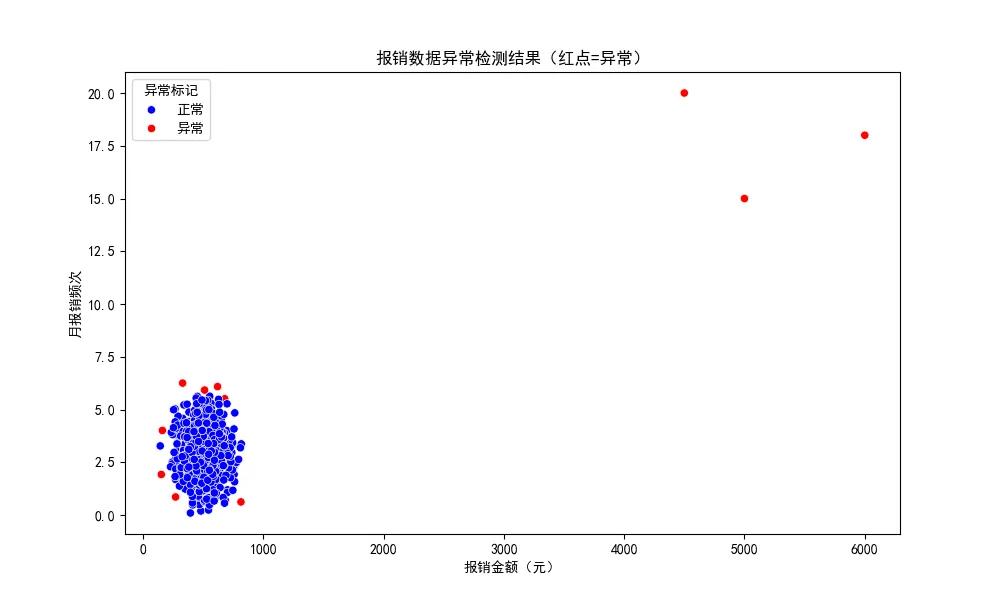
3. 可视化“抓现行”:红点=异常一目了然
用Seaborn画散点图,蓝色正常、红色异常:
importseabornassnsplt.figure(figsize=(10, 6))# 正常数据用蓝色,异常数据用红色sns.scatterplot(x='金额', y='频次', hue='异常标记', data=df, palette={1: 'blue', -1: 'red'})plt.title('报销数据异常检测结果(红点=异常)')plt.xlabel('报销金额(元)')plt.ylabel('月报销频次')plt.legend(title='异常标记', labels=['正常', '异常'])plt.show()
四、结果解读:这些“红点”该咋审?
红点特征:金额超5000、频次超15次(比如销售部小李月报18次招待费);
异常分数:-0.8比-0.2更可疑(分数越负,“孤立”越快);
实际价值:优先审红点单,效率提80%;若某部门连续多月有红点,得查是否虚报。
五、避坑指南:新手常踩的3个雷
数据预处理:金额单位统一(比如都转“元”),别让“1万”和“10000”打架;
参数调整:contamination按实际改(波动大就设0.05=5%异常);
特征加量:加“报销间隔”“同类占比”,模型更准(比如“同一商家月刷3次”)。
大家动起手来跑一跑,哪怕揪出1张异常单,也是省时半小时!
喜欢小居的文章:关注、点赞、转发。
有问题评论区留言,需要代码后台“机器学习07”。