用Python爬取小破站单个视频(详解)
- 2026-07-04 18:28:47
前言 🎬
***郑重说明:本爬虫仅限个人学习研究,非商业、非盈利,请合规使用爬虫,否则违规爬取由此产生的一切后果,请自行承担,与本人无关***
Hello,大家好啊!我是亮娃儿,平时喜欢踢球,就想着能在小破站(B站)多学习些骚气的过人动作,所以就想着把B站的视频爬下来多看几遍。
首先,我们要知道B站视频的一大特点,B站的视频和音频是分离的两部分,我们抓下来以后,还需要把视频和音频给拼接起来才行哟 ❗
说了一大堆废话,正式开始写爬虫实现的基本流程 👇
一、数据来源分析 🕵️♂️
1.明确需求 🎯
这是今天采集的视频内容主角:《静止也能过人 5招实用技巧 轻松晃开防守球员》
2.抓包分析 🔍
按 F12 调出浏览器的开发者工具分析数据位置,这里我们用到的是 Google浏览器
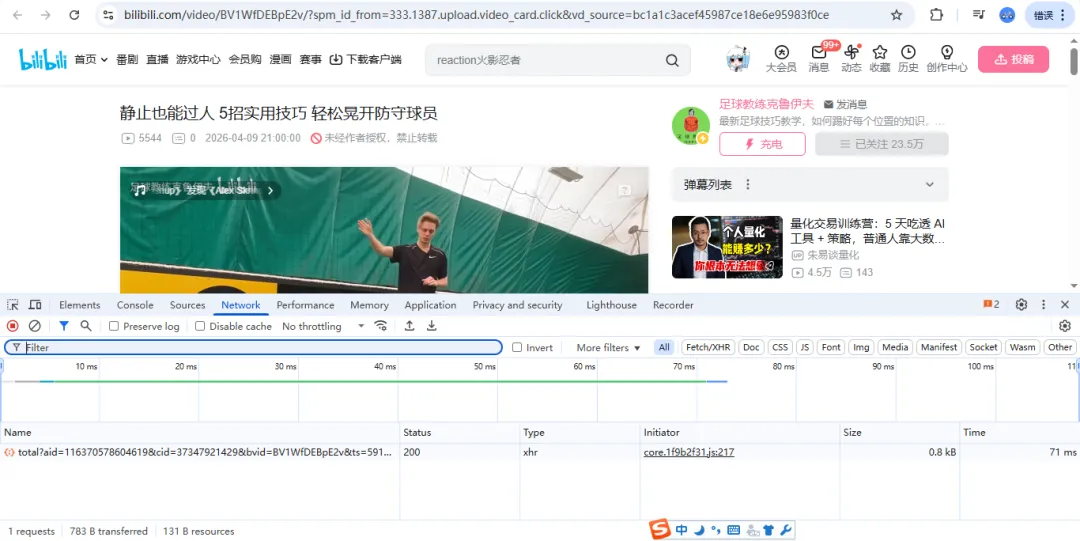
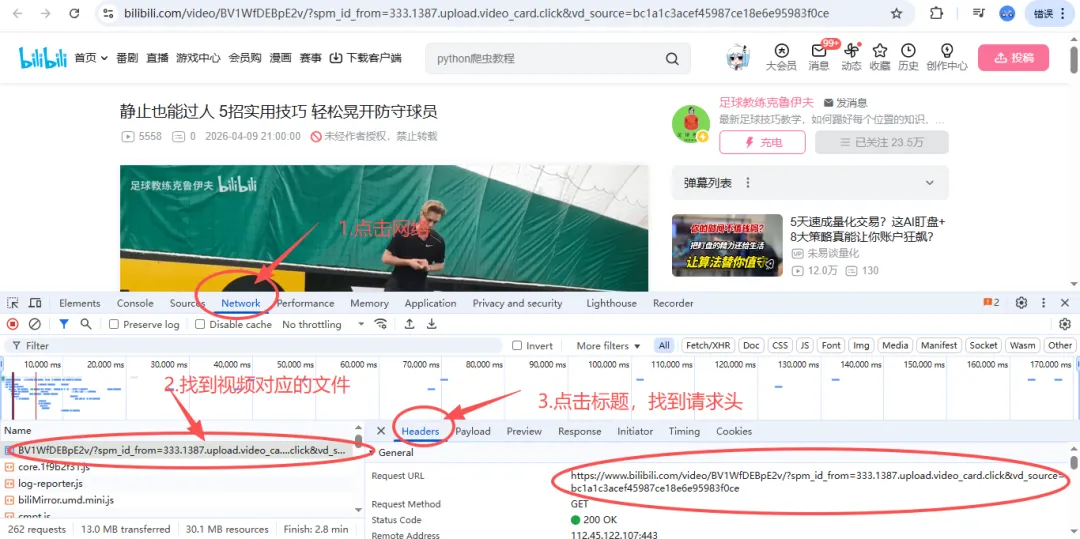
下一步,咱们点击 Network(网络)标签,再点击 crtl+R刷新,重新加载一遍数据内容,找到视频对应的文件,继续点击 headers 标题,可以找到视频对应的请求网址:
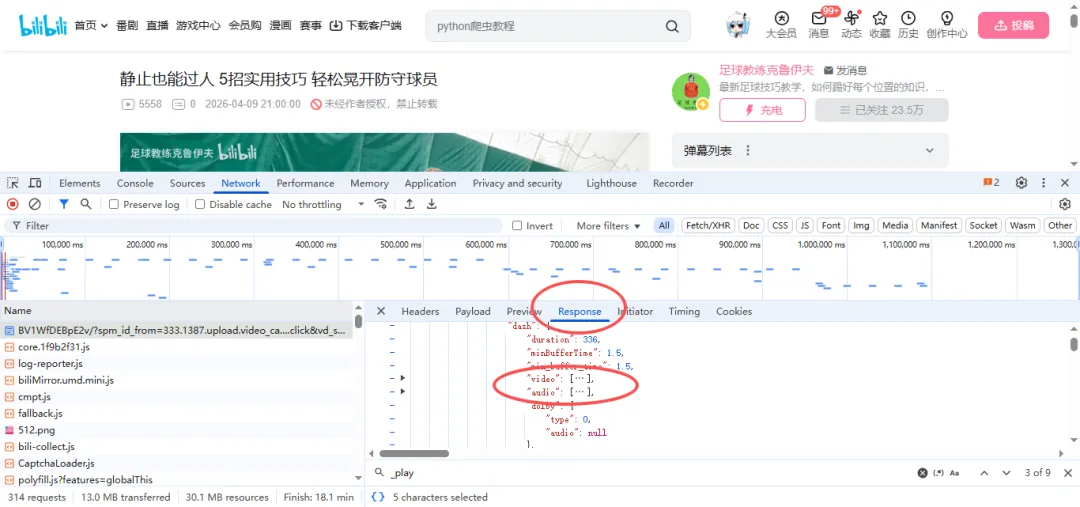
咱们可以继续在 Response(响应)标签下,因为B站的视频比较特殊,一个视频文件分为视频和音频两部分,如图所示为该视频的视频画面和音频内容。
二、代码实现步骤 💻
1.发送请求
模拟伪装浏览器,对于url地址发送请求,避开反爬限制
# 导入数据请求模块import requests# 发送请求def get_response(url, params=None): # 模拟浏览器 headers = { # cookie 用户信息,常用于检测是否有登陆账号(登陆与否都有cookie)"cookie": "你自己的cookie号", # referer 防盗链,告诉服务器请求网址从哪里跳转过来的"referer": "https://space.bilibili.com/50062810/upload/video", # user-agent 用户代理,表示浏览器/设备基本身份信息"user-agent": "你自己的浏览器" } # 发送请求 response = requests.get(url=url, params=params, headers=headers)return response那有小伙伴又会问了,cookie 和 useragent 在哪找呢 ❓
模拟浏览器使用请求头中的参数内容进行模拟伪装,在代码中需要用 字典 接收参数内容
cookie和useragent均在请求头中:
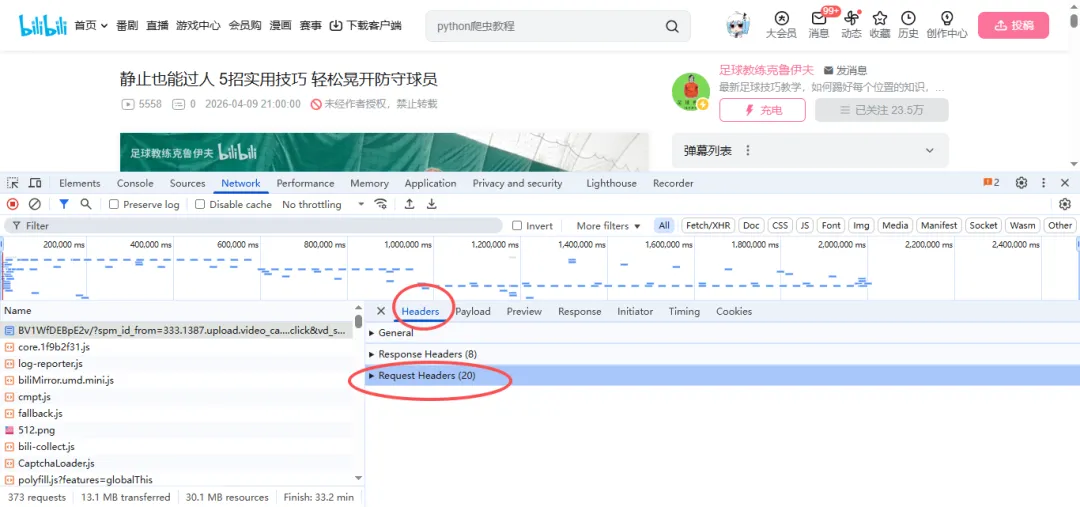
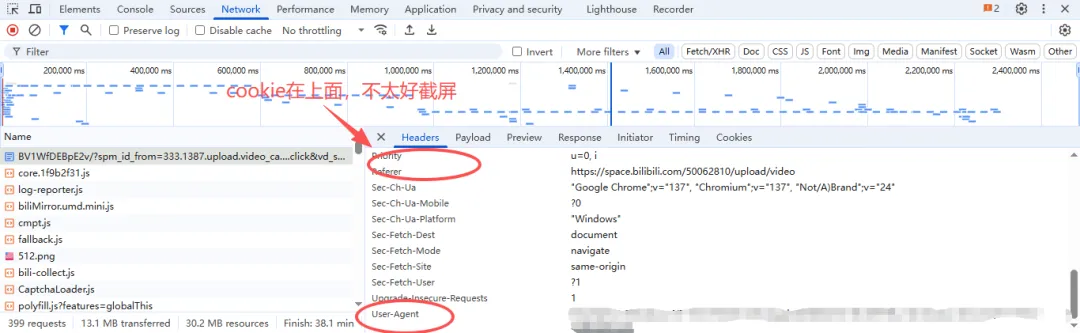
2.获取和解析数据
获取服务器返回响应数据,提取数据内容,精准定位音视频链接 ✅
import re# 获取视频信息def get_video_info(): # 播放页面链接 url = "https://www.bilibili.com/video/BV1WfDEBpE2v/" # 构建查询参数 params = {"spm_id_from": "333.1387.upload.video_card.click","vd_source": "bc1a1c3acef45987ce18e6e95983f0ce" } # 调用发送请求函数,获取响应的文本数据 html = get_response(url, params).text # # 提取视频标题 title = re.findall('"title":"(.*?)","pubdate"',html)[0] # 提取信息,json数据格式字符串 info = re.findall('<script>window.__playinfo__=(.*?)</script>', html)[0] # print(info) # 把json字符串转成字典 json_data = json.loads(info) # print(json_data) # 提取视频链接 video_url = json_data['data']['dash']['video'][0]['baseUrl'] # 提取音频链接 audio_url = json_data['data']['dash']['audio'][0]['baseUrl'] print(title) print(video_url) print(audio_url)return title,video_url,audio_url首先,咱们来说一说这串代码的播放链接,就是用的这个请求网址 👇
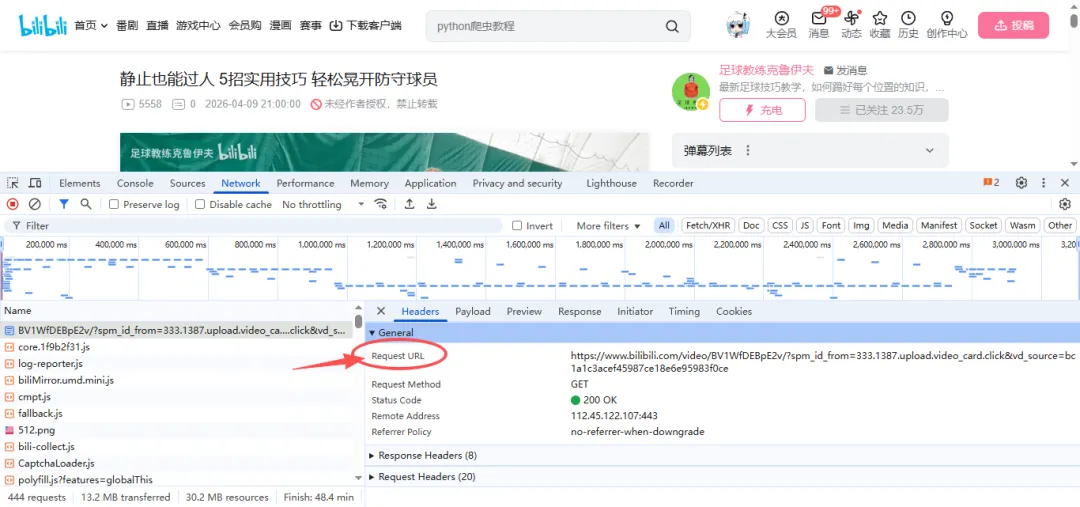
构建的查询参数用的这里的:
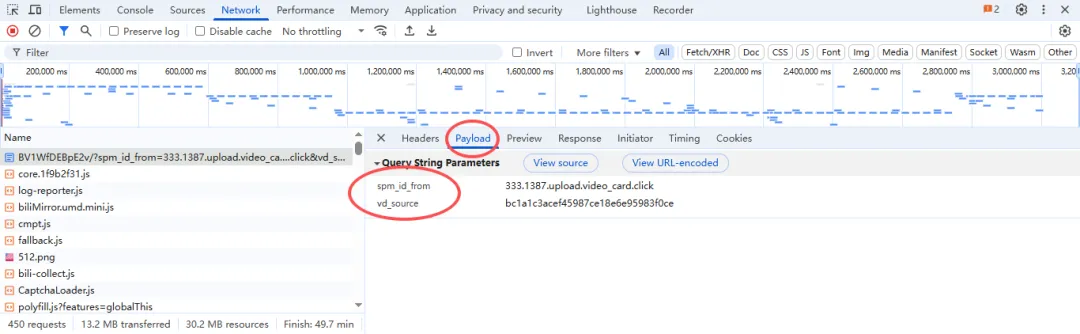
提取视频标题用到的是正则表达式:
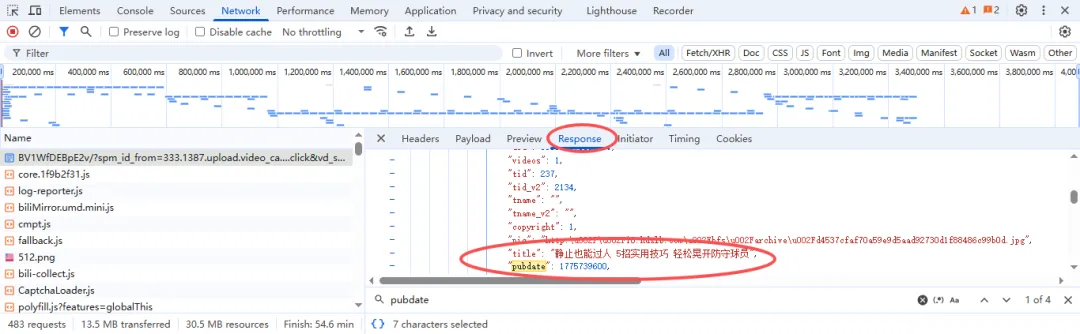
提取信息也同样用的是 正则表达式 :
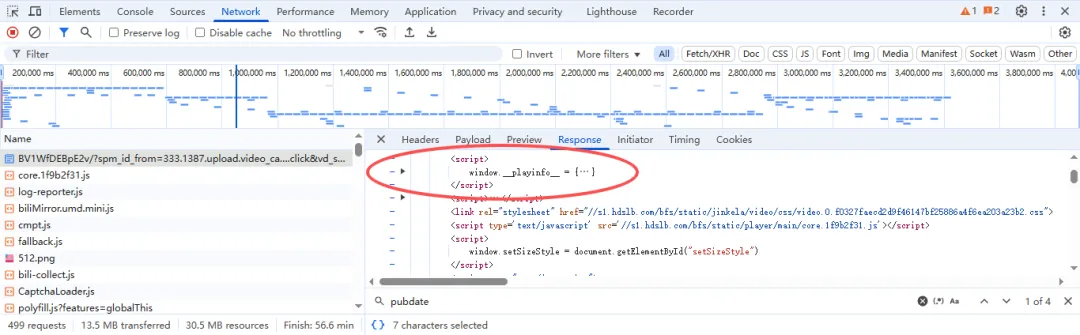
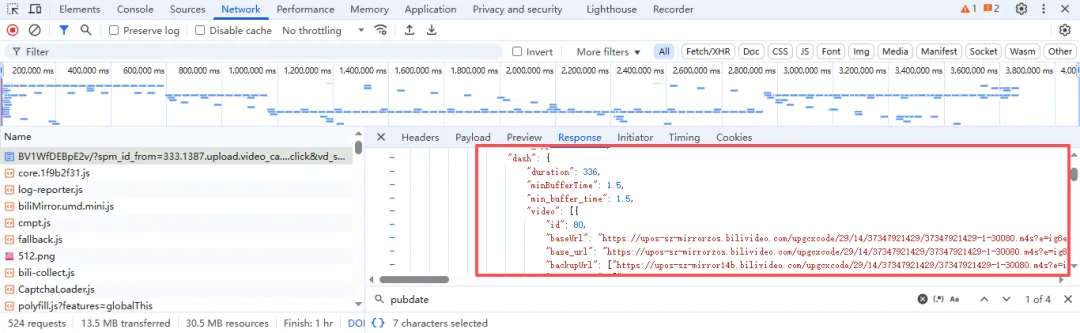
提取到的内容为json数据格式的 字符串,并不是字典,所以我们需要用json.loads(info)把他转换成字典,从而方便用大括号提取到视频链接和音频链接
3.保存数据
把提取出来的数据保存到本地文件中,顺带完成音视频合并,一步到位 💾
# 保存数据import subprocessimport osdef save(title,video_url,audio_url): # 确保保存目录存在 save_dir = "D:\\b站"if not os.path.exists(save_dir): os.makedirs(save_dir) # 清理标题中的特殊字符 title = re.sub('[\\/:*?"<>|]', '', title) title = title.strip() # 构建文件路径 video_path = os.path.join(save_dir, f"{title}.mp4") audio_path = os.path.join(save_dir, f"{title}.mp3") final_path = os.path.join(save_dir, f"{title}(最终版).mp4") # 获取视频内容 video_content = get_response(video_url).content # 获取音频内容 audio_content = get_response(audio_url).content # 数据保存with open(video_path,'wb')as video: video.write(video_content) with open(audio_path,'wb')as audio: audio.write(audio_content) # 通过代码进行合并 cmd = f"ffmpeg -i \"{video_path}\" -i \"{audio_path}\" -c:v copy -c:a aac -strict experimental \"{final_path}\"" subprocess.run(cmd,shell=True) # 清理临时文件if os.path.exists(video_path): os.remove(video_path)if os.path.exists(audio_path): os.remove(audio_path)解释一下,这里数据保存,我们用到的with open简单的写入,最后因为生成了三个文件,一个光有视频的文件,一个光有音频的文件和一个合成了音频的视频文件,所以我们需要清理掉两个不需要的光有视频和音频的文件。
重点说一下,关于音频和视频合并,我们需要用到 cmd 的命令,所以需要引入subprocess包,另外我们需要用到一个工具 ffmpeg工具,具体的配置见下图所示:
1.官网下载ffmpeg 📥
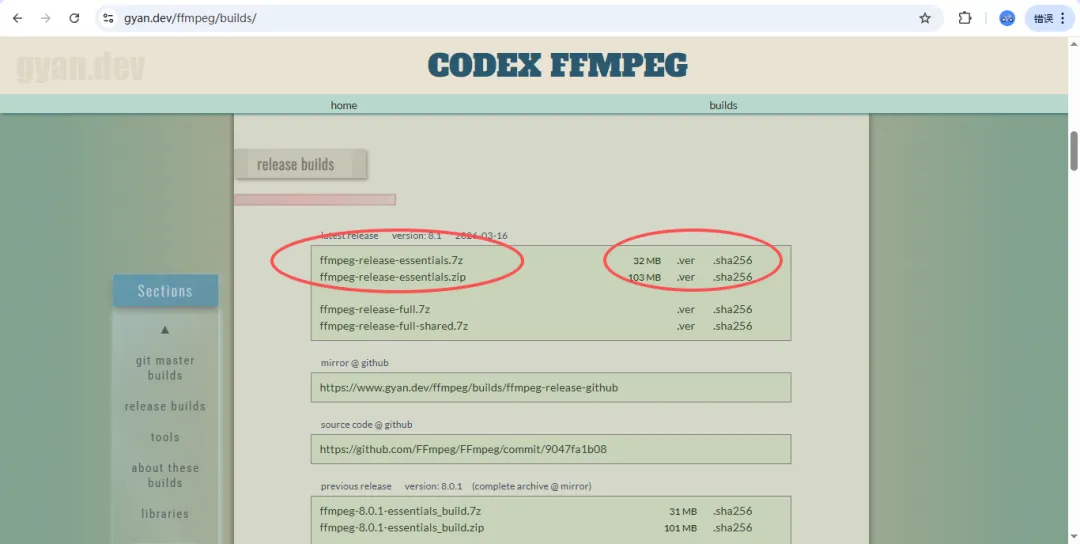
进入 Download FFmpeg,点击下载windows版ffmpeg
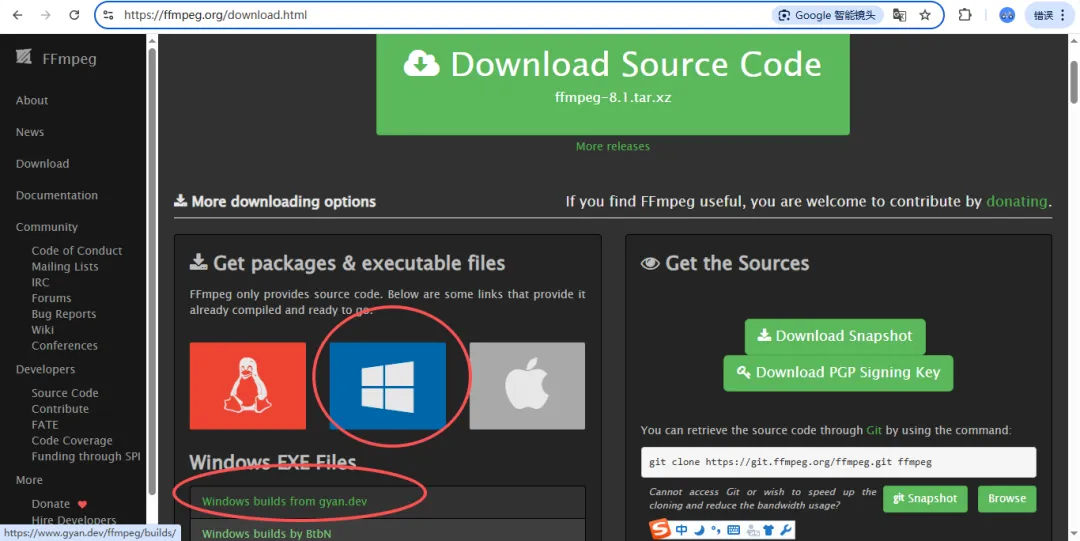
在release builds第一个绿框里面选择一个版本下载
2.配置 ⚙️
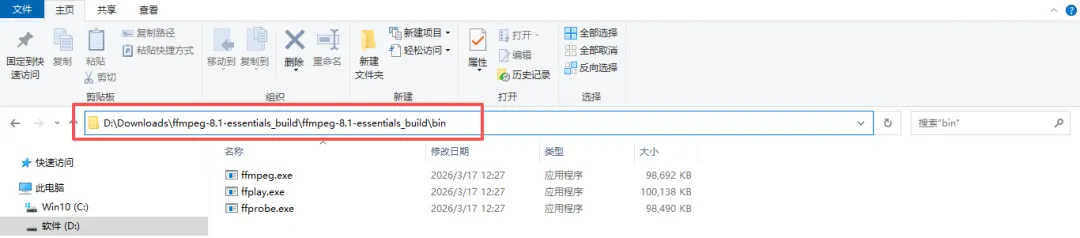
下载完成后解压该压缩包:

在bin文件里会有三个exe文件,复制此时的地址
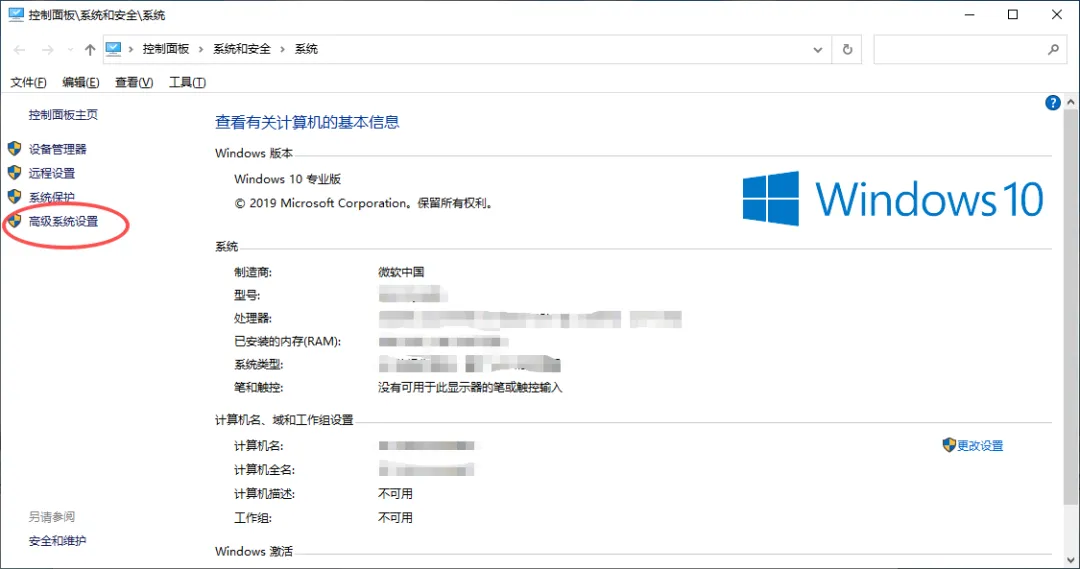
鼠标点击我的电脑右键点属性 ---> 高级系统设置
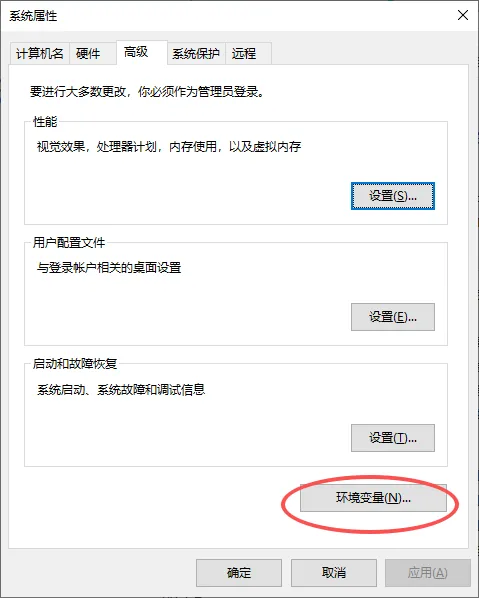
点击环境变量
在系统变量中找到Path,双击打开
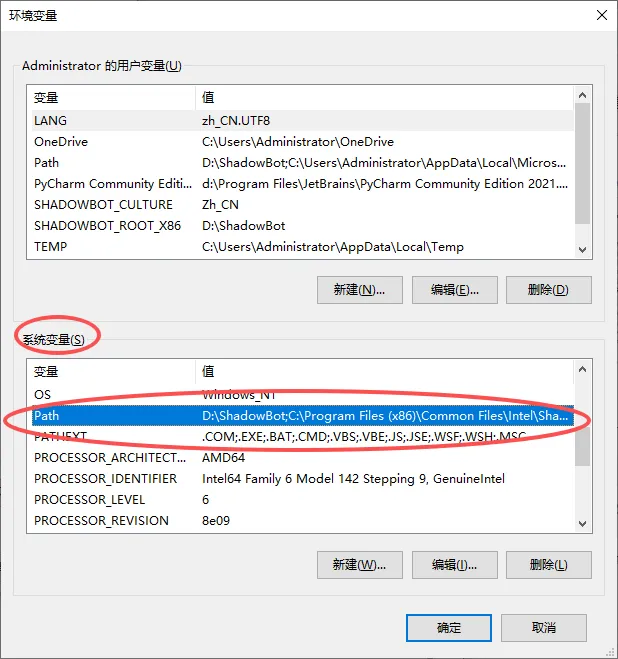
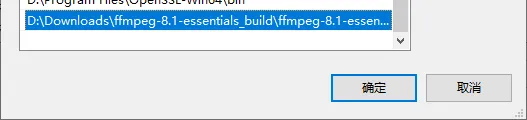
点击新建,把最开始复制的地址粘贴进来,点击确定
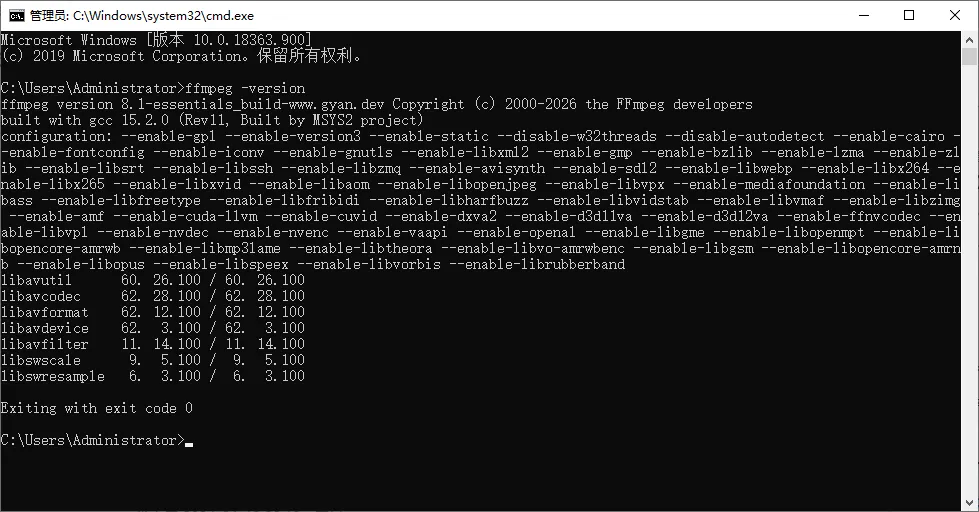
保存完毕后,打开任意shell 输入ffmpeg -version,如果正常输出版本号则表示安装成功
最后,咱们来交代一下完整的代码,直接复制就能跑 🚀
import jsonimport requestsimport reimport subprocessimport os# 发送请求def get_response(url, params=None): # 模拟浏览器 headers = { # cookie 用户信息,常用于检测是否有登陆账号(登陆与否都有cookie)"cookie": "你自己的cookie号", # referer 防盗链,告诉服务器请求网址从哪里跳转过来的"referer": "https://space.bilibili.com/50062810/upload/video", # user-agent 用户代理,表示浏览器/设备基本身份信息"user-agent": "你自己的浏览器" } # 发送请求 response = requests.get(url=url, params=params, headers=headers)return response# 获取视频信息def get_video_info(): # 播放页面链接 url = "https://www.bilibili.com/video/BV1WfDEBpE2v/" # 构建查询参数 params = {"spm_id_from": "333.1387.upload.video_card.click","vd_source": "bc1a1c3acef45987ce18e6e95983f0ce" } # 调用发送请求函数,获取响应的文本数据 html = get_response(url, params).text # # 提取视频标题 title = re.findall('"title":"(.*?)","pubdate"',html)[0] # 提取信息,json数据格式字符串 info = re.findall('<script>window.__playinfo__=(.*?)</script>', html)[0] # print(info) # 把json字符串转成字典 json_data = json.loads(info) # print(json_data) # 提取视频链接 video_url = json_data['data']['dash']['video'][0]['baseUrl'] # 提取音频链接 audio_url = json_data['data']['dash']['audio'][0]['baseUrl'] print(title) print(video_url) print(audio_url)return title,video_url,audio_url# 保存数据def save(title,video_url,audio_url): # 确保保存目录存在 save_dir = "D:\\b站"if not os.path.exists(save_dir): os.makedirs(save_dir) # 清理标题中的特殊字符 title = re.sub('[\\/:*?"<>|]', '', title) title = title.strip() # 构建文件路径 video_path = os.path.join(save_dir, f"{title}.mp4") audio_path = os.path.join(save_dir, f"{title}.mp3") final_path = os.path.join(save_dir, f"{title}(最终版).mp4") # 获取视频内容 video_content = get_response(video_url).content # 获取音频内容 audio_content = get_response(audio_url).content # 数据保存with open(video_path,'wb')as video: video.write(video_content) with open(audio_path,'wb')as audio: audio.write(audio_content) # 通过代码进行合并 cmd = f"ffmpeg -i \"{video_path}\" -i \"{audio_path}\" -c:v copy -c:a aac -strict experimental \"{final_path}\"" subprocess.run(cmd,shell=True) # 清理临时文件if os.path.exists(video_path): os.remove(video_path)if os.path.exists(audio_path): os.remove(audio_path)# 主函数def main(): title,video_url,audio_url = get_video_info() print(title) # print(title,video_url,audio_url) save(title,video_url,audio_url)if __name__ == '__main__': main()视频运行实录 🎥
最后,有些小伙伴又会说了,那我如果想批量爬取多个视频又咋整呢 😜?这个也很简单,卖个关子,留在下一篇我的公众号里写出来分享给大家,敬请期待!
***郑重说明:本爬虫仅限个人学习研究,非商业、非盈利,请合规使用爬虫,否则违规爬取由此产生的一切后果,请自行承担,与本人无关***
数据&完整代码获取方式 🎁
关注公众号,后台留言我,即可获取相关代码,我的微信:shangliang87
历史推荐 📚
✅ - 《夜神模拟器自动化爬取抖音用户信息数据实战:uiautomator2+Fiddler+Mitmproxy完美组合》
交流群 💬
QQ:892186377,随时互动、提建议。另有交流群(内含资料),欢迎加入!

未完待续,欢迎关注!🥰动动您发财的小手点个赞吧 👍 !欢迎转发!🔁
随机文章
-
 10个月宝宝每天需要喝多少奶粉?
10个月宝宝每天需要喝多少奶粉?
- 【能力建设】Linux 老系统装不上 Claude Code / Codex?一篇搞定
- 10 款适合初学者的 Linux 发行版
- 【python3.10.1】python3.10.1setup安装包获取方式,适合新手的安装说明
- Linux运维转网安,顺序千万别搞反!90天保姆级路线,照着做直接拿offer
- 学Linux不迷茫!从0到精通的完整路线
- Linux 网络栈核心三字经全解
- 笑不活了!Linux TCP/IP协议,竟是“电脑间的快递物流体系”
- Linux学习的乐趣
- 一文讲透:Linux / Android / Java 后端三大体系分层关系(系统层认知终极总结)
- Linux软件库截止2026年4月更新合集!
