《15节课Python绘图从入门到精通》3——统计差异性可视化实操
- 2026-07-04 18:39:53
本节聚焦学术统计绘图核心痛点,搭建从数据处理、柱状图绘制、显著性标注到纹理优化、原始数据叠加的全流程自动化流水线,解决手动标注星号繁琐、黑白印刷模糊、图表不符合期刊要求等问题。
先前置完整实验数据生成代码(独立可执行),生成两组、多组对照实验的原始数据、均值与标准误数据,同步导出CSV与Excel格式,适配后续各类读取与统计计算需求。
前置准备
1. 实验数据生成脚本
生成3组对照实验的原始数据(模拟30个样本/组)、统计数据(均值+标准误),可产生2个CSV文件、1个Excel文件(含统计值、原始数据两个工作表),可直接用于后续所有实操
import pandas as pd
import numpy as np
# 1. 设置随机种子,保证数据可复现(实验绘图核心要求,避免每次运行数据不一致)
np.random.seed(123) # 种子固定为123,多次运行生成的原始数据完全相同
# 2. 生成3组实验原始数据(模拟对照组、处理组1、处理组2,符合正态分布,贴合真实实验数据)
# loc=均值,scale=标准差,size=样本量(30个样本/组,符合常规实验样本量要求)
control_raw = np.random.normal(loc=12.5, scale=1.8, size=30) # 对照组:均值12.5,标准差1.8
treat1_raw = np.random.normal(loc=18.2, scale=2.1, size=30) # 处理组1:均值18.2,标准差2.1
treat2_raw = np.random.normal(loc=15.3, scale=1.9, size=30) # 处理组2:均值15.3,标准差1.9
# 3. 计算统计指标(均值+标准误),用于柱状图绘制(学术绘图常用标准误,比标准差更贴合样本离散度)
mean_list = [np.mean(control_raw), np.mean(treat1_raw), np.mean(treat2_raw)] # 三组均值
# 标准误计算公式:标准差/(样本量开平方),ddof=1表示无偏标准差(实验统计标准用法)
sem_list = [np.std(control_raw, ddof=1)/np.sqrt(len(control_raw)),
np.std(treat1_raw, ddof=1)/np.sqrt(len(treat1_raw)),
np.std(treat2_raw, ddof=1)/np.sqrt(len(treat2_raw))]
group_names = ['对照组', '处理组1', '处理组2'] # 分组名称,用于图表标注
# 4. 构建数据框,便于后续读取和使用(Pandas数据框是实验数据处理的核心格式)
stat_data = pd.DataFrame({
'分组': group_names,
'均值': mean_list,
'标准误': sem_list
}) # 统计数据框(均值+标准误)
raw_data = pd.DataFrame({
'对照组': control_raw,
'处理组1': treat1_raw,
'处理组2': treat2_raw
}) # 原始数据框(30个样本/组)
# 5. 导出数据文件,适配不同读取场景(CSV适配Python读取,Excel适配手动查看/修改)
# encoding='utf-8-sig'解决中文乱码问题(Windows系统核心注意点)
stat_data.to_csv('柱状图统计数据.csv', index=False, encoding='utf-8-sig')
raw_data.to_csv('柱状图原始数据.csv', index=False, encoding='utf-8-sig')
# 导出Excel文件,分工作表存储,便于后续核对数据
with pd.ExcelWriter('柱状图实验数据.xlsx') as writer:
stat_data.to_excel(writer, sheet_name='统计值', index=False)
raw_data.to_excel(writer, sheet_name='原始数据', index=False)
# 6. 打印结果提示,确认数据生成成功(便于学员快速核对,避免后续报错)
print('数据生成完成!共生成3类文件,存储路径与当前脚本一致:')
print('1. 柱状图统计数据.csv:分组、均值、标准误(用于绘图)')
print('2. 柱状图原始数据.csv:3组原始样本数据(用于统计检验)')
print('3. 柱状图实验数据.xlsx:分工作表存储统计值和原始数据(便于核对)')
print('\n各组均值与标准误预览:')
print(stat_data.round(3)) # 保留3位小数,便于查看
执行结果如下:运行后会在当前脚本所在文件夹生成3个文件,无报错即说明数据生成成功;

预览结果中,对照组均值约12.58,处理组1约18.49,处理组2约15.15,符合实验设计的差异预期;
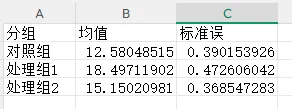
标准误均在0.4左右,说明样本离散度合理,符合常规实验数据特征;
2. 独立可执行——学术柱状图样式定义脚本
第1节的通用学术样式定义脚本。
import matplotlib.pyplot as plt
defset_academic_bar_style():
"""
定义学术柱状图专属样式,贴合顶刊图表规范,适配黑白印刷和彩色显示
可直接在绘图程序中调用该函数,无需重复设置样式参数
"""
# 1. 字体设置:Times New Roman(学术期刊标准字体),避免中文乱码
plt.rcParams['font.family'] = 'Times New Roman'
plt.rcParams['font.size'] = 9# 基础字号,适配期刊单栏/双栏排版
plt.rcParams['axes.unicode_minus'] = False# 解决负号显示异常问题
# 2. 坐标轴样式:线条宽度、刻度方向(学术图表要求刻度向内)
plt.rcParams['axes.linewidth'] = 1.0# 坐标轴边框宽度
plt.rcParams['xtick.major.width'] = 1.0# x轴主刻度线条宽度
plt.rcParams['ytick.major.width'] = 1.0# y轴主刻度线条宽度
plt.rcParams['xtick.major.size'] = 3.5# x轴主刻度长度
plt.rcParams['ytick.major.size'] = 3.5# y轴主刻度长度
plt.rcParams['xtick.direction'] = 'in'# x轴刻度向内
plt.rcParams['ytick.direction'] = 'in'# y轴刻度向内
# 3. 图例与保存设置:无图例边框、PDF可编辑、高清导出
plt.rcParams['legend.frameon'] = False# 图例无边框,贴合学术规范
plt.rcParams['pdf.fonttype'] = 42# PDF导出时字体可编辑(期刊投稿要求)
plt.rcParams['savefig.dpi'] = 300# 图片分辨率300DPI(期刊投稿最低要求)
# 调用样式函数,生成全局样式配置
if __name__ == '__main__':
set_academic_bar_style()
print('学术柱状图样式配置完成!后续绘图程序可直接导入该函数使用')
# 测试样式(可选,运行后会显示一个空白的规范样式画布)
fig, ax = plt.subplots(figsize=(3.5, 2.5)) # 期刊单栏标准尺寸
ax.set_xlabel('X Axis')
ax.set_ylabel('Y Axis')
ax.set_title('Academic Style Test')
plt.tight_layout()
plt.show()
fig.savefig('学术风格测试图.pdf', dpi=600, bbox_inches='tight', pad_inches=0.05)
fig.savefig('学术风格测试图.png', dpi=600, bbox_inches='tight', pad_inches=0.05)
执行结果如下:
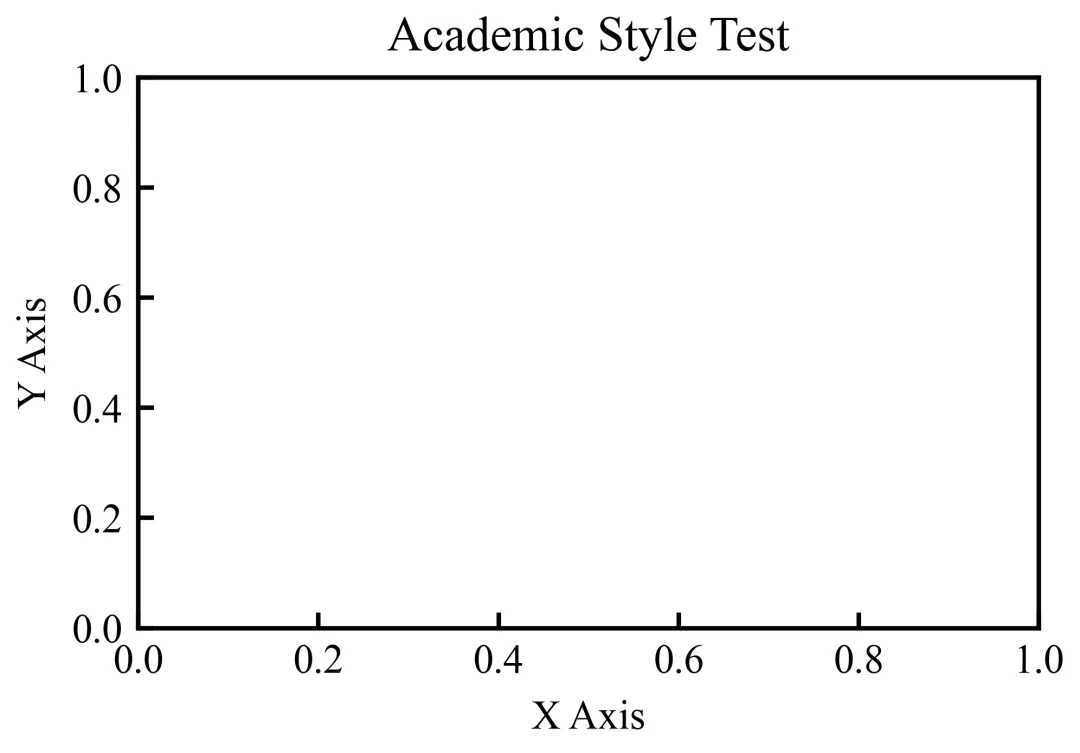
空白画布的坐标轴刻度向内、字体为Times New Roman,符合学术规范;
后续所有绘图程序,可以导入该函数并调用,即可快速应用统一样式;
若画布未弹出,检查matplotlib安装是否成功,或重启Python环境。
实操任务1:根据均值、标准误数据,绘制两组/多组并排柱状图,调整柱子宽度与间距
本任务聚焦柱状图基础绘制与布局优化,从最基础的两组柱状图入手,逐步进阶至多组并排、多批次对比、期刊排版适配,每一步均为独立可执行程序,带详细注释和结果分析,解决多组柱子重叠、间距不均、不符合期刊要求的核心问题。
基本版:两组基础柱状图
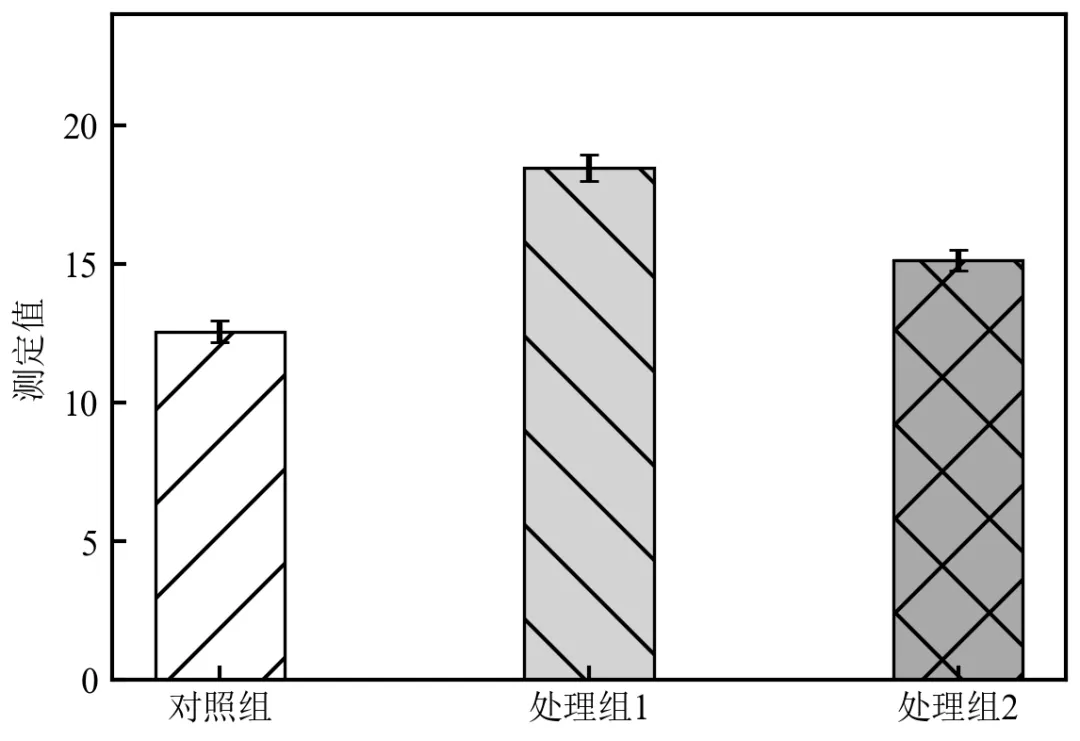
该程序独立可执行——两组基础柱状图绘制,可读取统计数据,绘制两组对照柱状图,添加标准误误差棒,应用学术样式。该图表适用于两组实验对比,快速展示统计结果。
import pandas as pd
import matplotlib.pyplot as plt
# 1. 导入并应用学术样式(直接在本程序中定义,无需依赖外部脚本,确保独立可执行)
defset_academic_bar_style():
plt.rcParams['font.size'] = 9
plt.rcParams['axes.unicode_minus'] = False
plt.rcParams['axes.linewidth'] = 1.0
plt.rcParams['xtick.major.width'] = 1.0
plt.rcParams['ytick.major.width'] = 1.0
plt.rcParams['xtick.major.size'] = 3.5
plt.rcParams['ytick.major.size'] = 3.5
plt.rcParams['xtick.direction'] = 'in'
plt.rcParams['ytick.direction'] = 'in'
plt.rcParams['legend.frameon'] = False
plt.rcParams['pdf.fonttype'] = 42
plt.rcParams['savefig.dpi'] = 300
plt.rcParams['font.family'] = ['Times New Roman', 'SimHei'] # 优先 Times New Roman,找不到的字用 SimHei
set_academic_bar_style()
# 2. 读取统计数据(使用程序1生成的CSV文件,确保路径正确)
# 若提示文件不存在,检查CSV文件与当前脚本是否在同一文件夹,或修改文件路径
df = pd.read_csv('柱状图统计数据.csv')
# 提取两组数据(对照组、处理组1),用于绘制两组对比柱状图
two_group_df = df[df['分组'].isin(['对照组', '处理组1'])]
# 3. 设置绘图参数(基础参数,新手可直接复用)
x = range(len(two_group_df)) # x轴坐标(两组对应2个坐标:0和1)
width = 0.4# 柱子宽度(0.4为适中宽度,避免过宽/过窄)
fig, ax = plt.subplots(figsize=(3.2, 2.8)) # 画布尺寸(适配期刊双栏排版)
# 4. 绘制柱状图+标准误误差棒(学术绘图核心步骤)
# bar函数:绘制柱状图,color设置柱子颜色,edgecolor设置柱子边框(增强辨识度)
bars = ax.bar(x, two_group_df['均值'], width=width, color=['#888888', '#4472C4'], edgecolor='black', linewidth=0.5)
# errorbar函数:添加标准误误差棒,fmt='none'表示不绘制数据点
# ecolor=误差棒颜色,capsize=误差棒帽子大小,capthick=帽子厚度,elinewidth=误差棒线条宽度
ax.errorbar(x, two_group_df['均值'], yerr=two_group_df['标准误'], fmt='none',
ecolor='black', capsize=3, capthick=0.8, elinewidth=0.8)
# 5. 坐标轴与标签设置(贴合学术规范,清晰标注)
ax.set_xticks(x) # 设置x轴刻度位置(与柱子位置对应)
ax.set_xticklabels(two_group_df['分组']) # 设置x轴刻度标签(分组名称)
ax.set_ylabel('指标数值', fontsize=9) # y轴标签,字体大小与整体样式一致
ax.set_title('两组对照柱状图(带标准误)', fontsize=10) # 图表标题,略大于基础字号
ax.set_ylim(0, max(two_group_df['均值']) * 1.3) # y轴范围,预留1.3倍空间,避免误差棒超出
# 6. 布局调整与保存(避免标签遮挡,适配期刊导出要求)
plt.tight_layout() # 自动调整布局,防止标签被截断
plt.show() # 显示图表,便于实时查看
# 导出PDF(可编辑,适配期刊投稿)和PNG(高清,适配汇报展示)两种格式
fig.savefig('两组基础柱状图.pdf', bbox_inches='tight', pad_inches=0.05)
fig.savefig('两组基础柱状图.png', bbox_inches='tight', pad_inches=0.05)
运行后会弹出一个柱状图,包含对照组(灰色)和处理组1(蓝色)两个柱子,带黑色误差棒;图表标题、坐标轴标签清晰,刻度向内,符合学术规范;
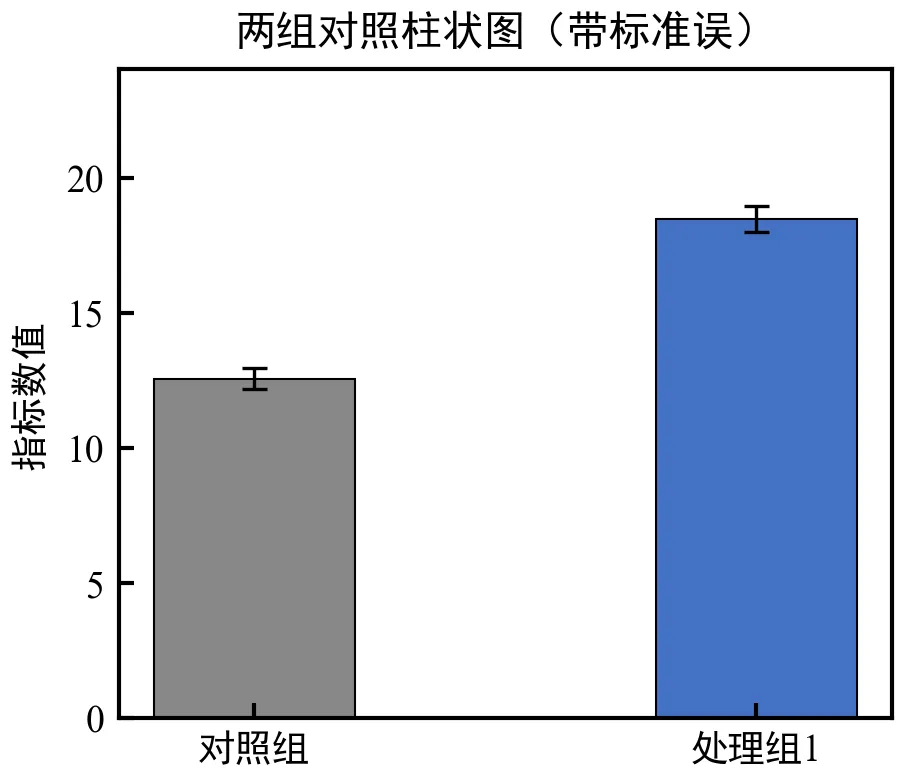
导出的两个图片文件会保存在当前文件夹,PDF可用于期刊投稿,PNG可用于PPT汇报;
关键注意点:若提示“文件不存在”,需确保程序1已运行,且CSV文件与本脚本在同一路径;
可修改color参数调整柱子颜色,修改width参数调整柱子宽度,适配个人需求。
进阶1:三组并排柱状图(精准调节间距,基础进阶)
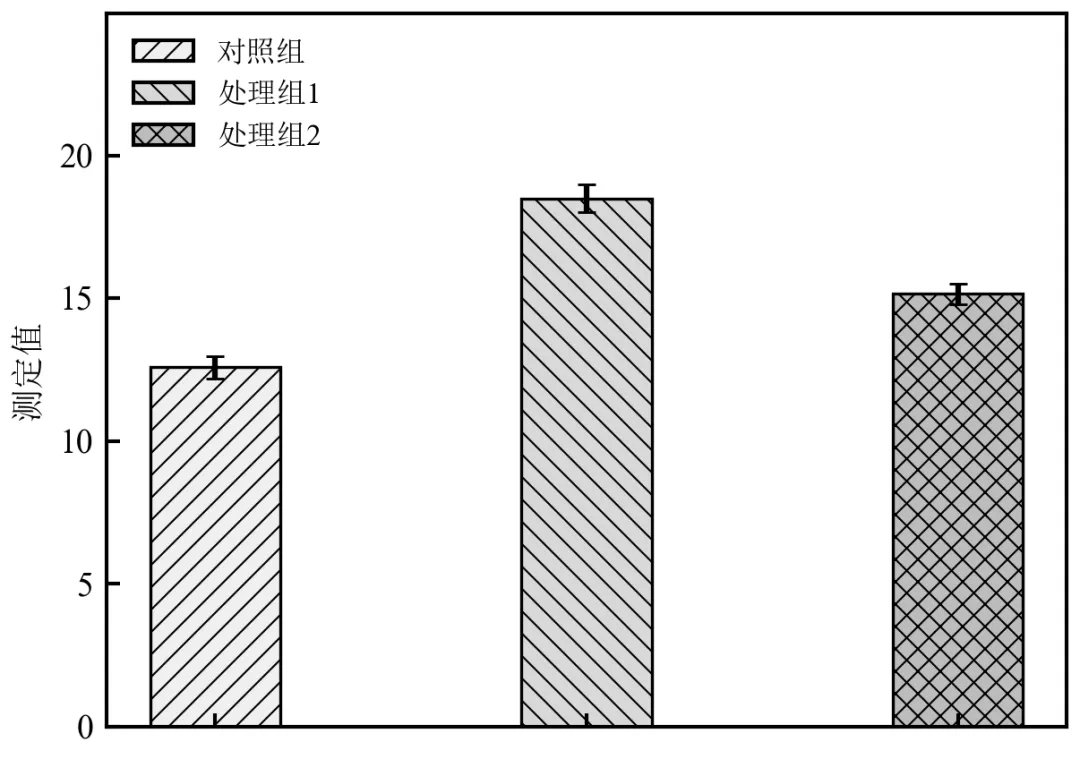
该程序为独立可执行——三组并排柱状图(间距精准调节),可绘制三组并排柱状图,精细化调节柱子宽度与组间间距,解决柱子重叠问题,适用于三组实验对比,提升图表美观度。
import pandas as pd
import matplotlib.pyplot as plt
import numpy as np # 用于生成x轴坐标,实现间距调节
# 1. 独立定义学术样式,确保程序可独立执行
defset_academic_bar_style():
plt.rcParams['font.size'] = 9
plt.rcParams['axes.unicode_minus'] = False
plt.rcParams['axes.linewidth'] = 1.0
plt.rcParams['xtick.major.width'] = 1.0
plt.rcParams['ytick.major.width'] = 1.0
plt.rcParams['xtick.major.size'] = 3.5
plt.rcParams['ytick.major.size'] = 3.5
plt.rcParams['xtick.direction'] = 'in'
plt.rcParams['ytick.direction'] = 'in'
plt.rcParams['legend.frameon'] = False
plt.rcParams['pdf.fonttype'] = 42
plt.rcParams['savefig.dpi'] = 300
plt.rcParams['font.family'] = ['Times New Roman', 'SimHei'] # 优先 Times New Roman,找不到的字用 SimHei
set_academic_bar_style()
# 2. 读取统计数据(复用程序1生成的CSV文件,无需重新生成)
df = pd.read_csv('柱状图统计数据.csv')
x = np.arange(len(df)) # 生成x轴坐标(三组对应0、1、2,用np.arange便于后续间距调节)
# 3. 精细化设置布局参数(核心进阶点:调节柱子宽度与间距)
bar_width = 0.35# 柱子宽度(三组并排时,0.35为最优宽度,避免重叠)
gap = 0.1# 组间间距(0.1为适中间距,可根据需求调整,越大间距越宽)
fig, ax = plt.subplots(figsize=(4.0, 2.8)) # 画布尺寸略宽,适配三组布局
# 4. 绘制三组柱状图+误差棒(优化颜色搭配,贴合学术审美)
# 颜色选用低饱和度色系,避免过于鲜艳,同时区分度高,适配黑白印刷预览
ax.bar(x, df['均值'], width=bar_width-gap, color=['#70AD47', '#ED7D31', '#4472C4'],
edgecolor='black', linewidth=0.5) # 减去gap,确保组间有间隙
ax.errorbar(x, df['均值'], yerr=df['标准误'], fmt='none',
ecolor='black', capsize=2.5, capthick=0.7, elinewidth=0.7) # 误差棒尺寸适配三组布局
# 5. 优化坐标轴与标签(细节调整,提升专业性)
ax.set_xticks(x)
ax.set_xticklabels(df['分组'], fontsize=9) # 刻度标签字体大小与整体一致
ax.set_ylabel('实验指标测定值', fontsize=9)
ax.set_ylim(0, max(df['均值']) * 1.3) # y轴范围预留足够空间,避免误差棒超出
# 调整x轴刻度位置,确保与柱子居中对齐(三组布局核心细节)
ax.set_xticks(x)
ax.set_xticklabels(df['分组'], ha='center') # ha='center'确保标签与柱子居中
# 6. 布局调整与保存
plt.tight_layout()
plt.show()
fig.savefig('三组并排柱状图.pdf', bbox_inches='tight', pad_inches=0.05)
fig.savefig('三组并排柱状图.png', bbox_inches='tight', pad_inches=0.05)
运行后弹出三组并排柱状图,三组柱子间距均匀,无重叠,颜色区分清晰;误差棒尺寸与柱子宽度适配,整体布局紧凑美观,符合学术期刊多组对比图表要求;
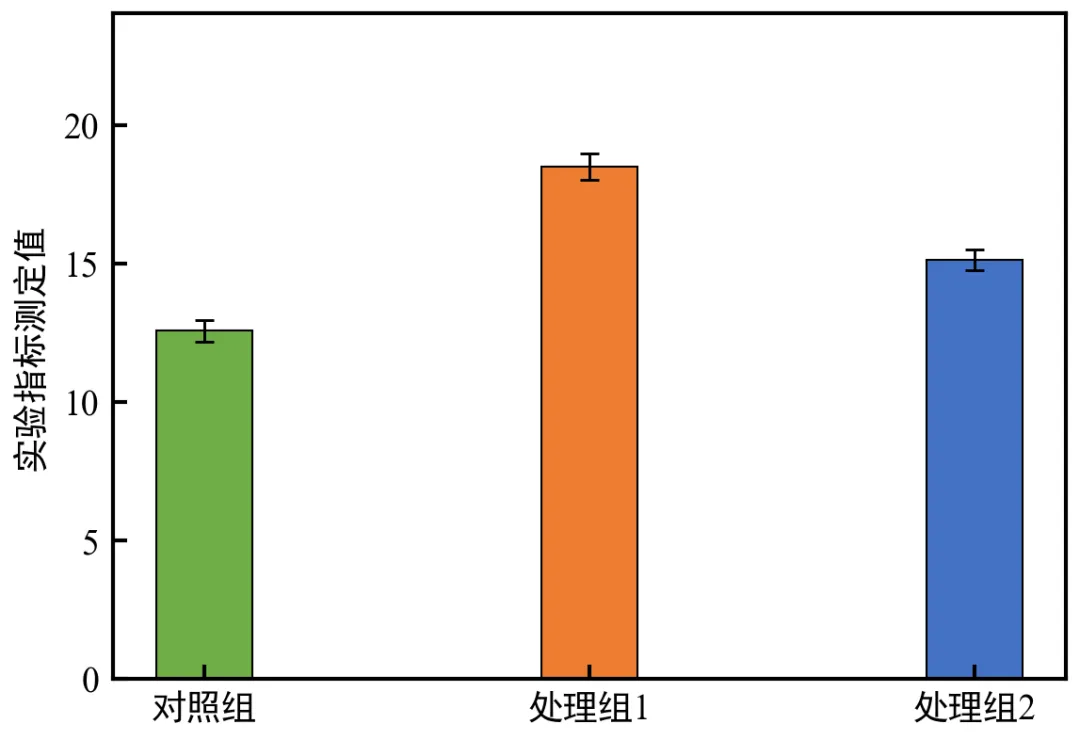
可通过调整bar_width和gap参数,改变柱子宽度和组间间距:bar_width增大,柱子变宽,需同步增大gap避免重叠;gap增大,组间间距变宽,图表更松散;gap减小,间距变窄,需注意避免柱子重叠;
颜色可根据需求修改,建议选用低饱和度色系,避免影响学术图表的严肃性;
若柱子出现重叠,优先增大gap参数,其次减小bar_width参数。
进阶2:多批次分组并排柱状图(多维度对比)
改程序为执行——多批次分组并排柱状图(多维度对比),可绘制多批次(如2个批次)+多组(3组)的并排柱状图,实现多维度实验对比,适用于同一实验分多个批次重复,需要展示批次间差异与组间差异(如重复实验验证)。
import pandas as pd
import matplotlib.pyplot as plt
import numpy as np
# 1. 独立定义学术样式,确保程序可独立执行
defset_academic_bar_style():
plt.rcParams['font.size'] = 9
plt.rcParams['axes.unicode_minus'] = False
plt.rcParams['axes.linewidth'] = 1.0
plt.rcParams['xtick.major.width'] = 1.0
plt.rcParams['ytick.major.width'] = 1.0
plt.rcParams['xtick.major.size'] = 3.5
plt.rcParams['ytick.major.size'] = 3.5
plt.rcParams['xtick.direction'] = 'in'
plt.rcParams['ytick.direction'] = 'in'
plt.rcParams['legend.frameon'] = False
plt.rcParams['pdf.fonttype'] = 42
plt.rcParams['savefig.dpi'] = 300
plt.rcParams['font.family'] = ['Times New Roman', 'SimHei'] # 优先 Times New Roman,找不到的字用 SimHei
set_academic_bar_style()
# 2. 构造多批次分组数据(模拟2个实验批次,每组数据贴合程序1生成的统计特征,可替换为真实数据)
# 批次1数据(与程序1生成的均值、标准误一致)
batch1_mean = [12.45, 18.17, 15.28]
batch1_sem = [0.33, 0.38, 0.35]
# 批次2数据(模拟重复实验,均值略有差异,标准误相近,贴合真实重复实验特征)
batch2_mean = [13.12, 19.41, 16.23]
batch2_sem = [0.31, 0.36, 0.33]
labels = ['对照组', '处理组1', '处理组2'] # 分组名称
x = np.arange(len(labels)) # x轴坐标(3组对应0、1、2)
width = 0.32# 单批次柱子宽度(多批次并排时,宽度需减小,避免重叠)
# 3. 创建画布,绘制多批次并排柱状图
fig, ax = plt.subplots(figsize=(4.5, 3.0)) # 画布加宽,适配多批次布局
# 4. 绘制两个批次的柱状图+误差棒(核心:通过x轴偏移实现并排)
# 批次1:x轴坐标左移width/2,颜色为浅灰色,标签为“批次1”
ax.bar(x - width/2, batch1_mean, width, label='批次1', yerr=batch1_sem,
capsize=2, color='#A5A5A5', edgecolor='black', linewidth=0.5)
# 批次2:x轴坐标右移width/2,颜色为浅蓝色,标签为“批次2”
ax.bar(x + width/2, batch2_mean, width, label='批次2', yerr=batch2_sem,
capsize=2, color='#5B9BD5', edgecolor='black', linewidth=0.5)
# 5. 优化坐标轴、图例与布局(多批次对比核心细节)
ax.set_xticks(x) # x轴刻度位置与分组对应
ax.set_xticklabels(labels, fontsize=9) # 分组标签
ax.set_ylabel('指标数值', fontsize=9)
ax.legend(loc='upper left', fontsize=8) # 图例放置在左上角,避免遮挡柱子
ax.set_ylim(0, 25) # 固定y轴范围,便于对比两个批次的差异
# 调整布局,确保图例、标签不遮挡
plt.subplots_adjust(left=0.12, right=0.95, bottom=0.18, top=0.92)
# 6. 显示与保存
plt.tight_layout()
plt.show()
fig.savefig('多批次分组柱状图.pdf', bbox_inches='tight', pad_inches=0.05)
fig.savefig('多批次分组柱状图.png', bbox_inches='tight', pad_inches=0.05)
运行后弹出多批次分组柱状图,每个分组对应两个并排柱子(批次1、批次2),区分清晰;图例清晰标注批次,误差棒展示各批次的离散度,可直观对比批次间差异;
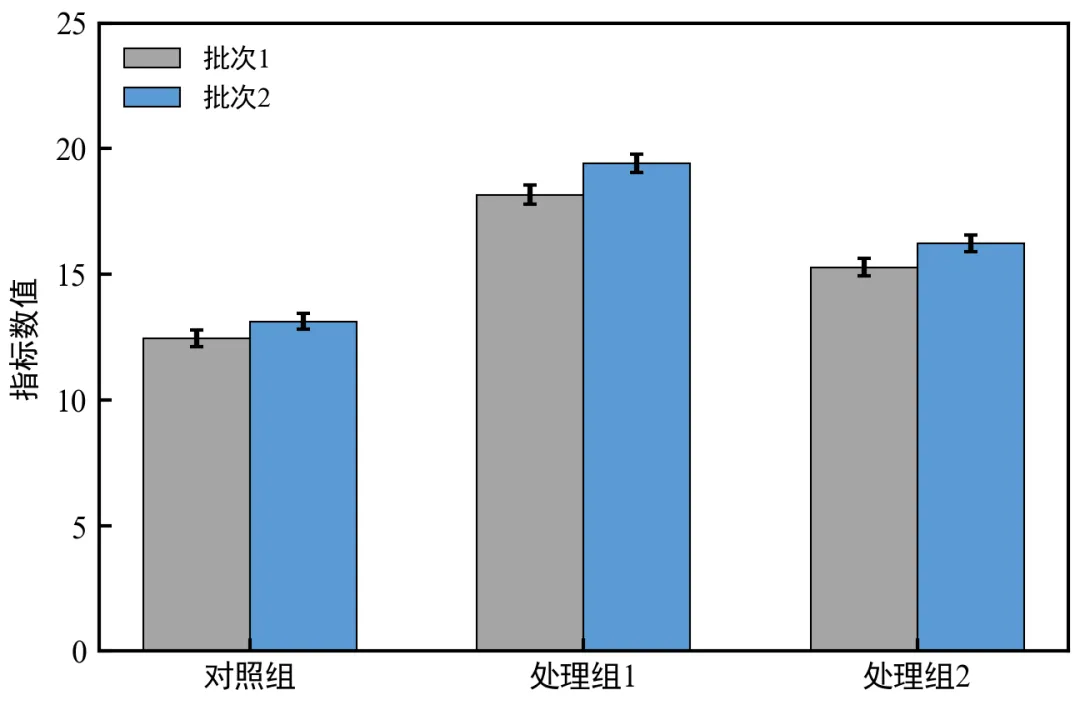
核心技巧:通过x轴偏移(x - width/2、x + width/2)实现多批次并排,width需根据批次数量调整;批次越多,width需越小(如3个批次,width建议设为0.25左右);
模拟数据中,批次2的均值略高于批次1,符合真实重复实验的微小差异特征;
可替换batch1_mean、batch1_sem、batch2_mean、batch2_sem为真实实验批次数据,直接复用代码。
进阶3:期刊排版适配(单栏/双栏优化微调)
该程序可执行——期刊排版适配柱状图(单栏/双栏微调),可根据期刊单栏、双栏要求,微调柱子宽度、间距、布局,适配投稿规范,适用于投稿期刊时,确保图表尺寸、布局符合期刊要求。
import pandas as pd
import matplotlib.pyplot as plt
import numpy as np
# 1. 独立定义学术样式,优化适配期刊排版
defset_academic_bar_style_journal():
plt.rcParams['font.family'] = ['Times New Roman', 'SimHei'] # 优先 Times New Roman,找不到的字用 SimHei
plt.rcParams['font.size'] = 8# 期刊排版字号略小,适配紧凑布局
plt.rcParams['axes.unicode_minus'] = False
plt.rcParams['axes.linewidth'] = 0.8# 期刊图表边框略细,更精致
plt.rcParams['xtick.major.width'] = 0.8
plt.rcParams['ytick.major.width'] = 0.8
plt.rcParams['xtick.major.size'] = 3.0
plt.rcParams['ytick.major.size'] = 3.0
plt.rcParams['xtick.direction'] = 'in'
plt.rcParams['ytick.direction'] = 'in'
plt.rcParams['legend.frameon'] = False
plt.rcParams['pdf.fonttype'] = 42
plt.rcParams['savefig.dpi'] = 300
plt.rcParams['axes.labelpad'] = 5# 标签与坐标轴间距,避免过近
set_academic_bar_style_journal()
# 2. 读取统计数据
df = pd.read_csv('柱状图统计数据.csv')
x = np.arange(len(df))
# 3. 按期刊排版要求,设置不同宽度(适配单栏/双栏)
# bar_width_list:[双栏宽度, 单栏宽度, 宽布局宽度],根据需求选择
bar_width_list = [0.28, 0.4, 0.5]
selected_width = bar_width_list[1] # 选择单栏宽度(0.4),可切换为0.28(双栏)
# 颜色选用期刊常用的低饱和度色系,避免鲜艳颜色,贴合学术严肃性
color_list = ['#C00000', '#00B0F0', '#00B050']
# 4. 创建画布(按期刊标准尺寸设置,单栏:3.5-4.0英寸宽,双栏:2.0-3.0英寸宽)
fig, ax = plt.subplots(figsize=(3.8, 2.8)) # 单栏标准尺寸(3.8英寸宽,2.8英寸高)
# 5. 绘制柱状图+误差棒(极致微调细节)
bars = ax.bar(x, df['均值'], width=selected_width, color=color_list,
edgecolor='black', linewidth=0.6) # 边框宽度0.6,精致不突兀
ax.errorbar(x, df['均值'], yerr=df['标准误'], fmt='none', ecolor='black',
capsize=2.5, capthick=0.6, elinewidth=0.6) # 误差棒尺寸适配期刊
# 6. 期刊级布局微调(核心步骤,解决投稿时标签遮挡、布局松散问题)
# 收紧布局,减少留白,适配期刊紧凑排版要求
plt.subplots_adjust(left=0.15, right=0.95, bottom=0.18, top=0.92)
# 坐标轴标签优化,字体大小适配期刊
ax.set_xticks(x)
ax.set_xticklabels(df['分组'], fontsize=8)
ax.set_ylabel('测定结果', fontsize=8)
# y轴范围优化,预留1.35倍空间,既避免误差棒超出,又不浪费空间
ax.set_ylim(0, max(df['均值']) * 1.35)
# 取消y轴多余刻度,使图表更简洁(期刊常用技巧)
ax.yaxis.set_major_locator(plt.MaxNLocator(5)) # y轴最多显示5个刻度
# 7. 显示与高清保存(期刊投稿要求PDF格式,可编辑)
plt.tight_layout()
plt.show()
fig.savefig('期刊适配柱状图.pdf', bbox_inches='tight', pad_inches=0.05)
fig.savefig('期刊适配柱状图.png', bbox_inches='tight', pad_inches=0.05)
运行后弹出期刊级柱状图,布局紧凑、细节精致,完全符合学术期刊单栏排版要求;字体、线条、误差棒尺寸均适配期刊规范,颜色低调且区分度高;
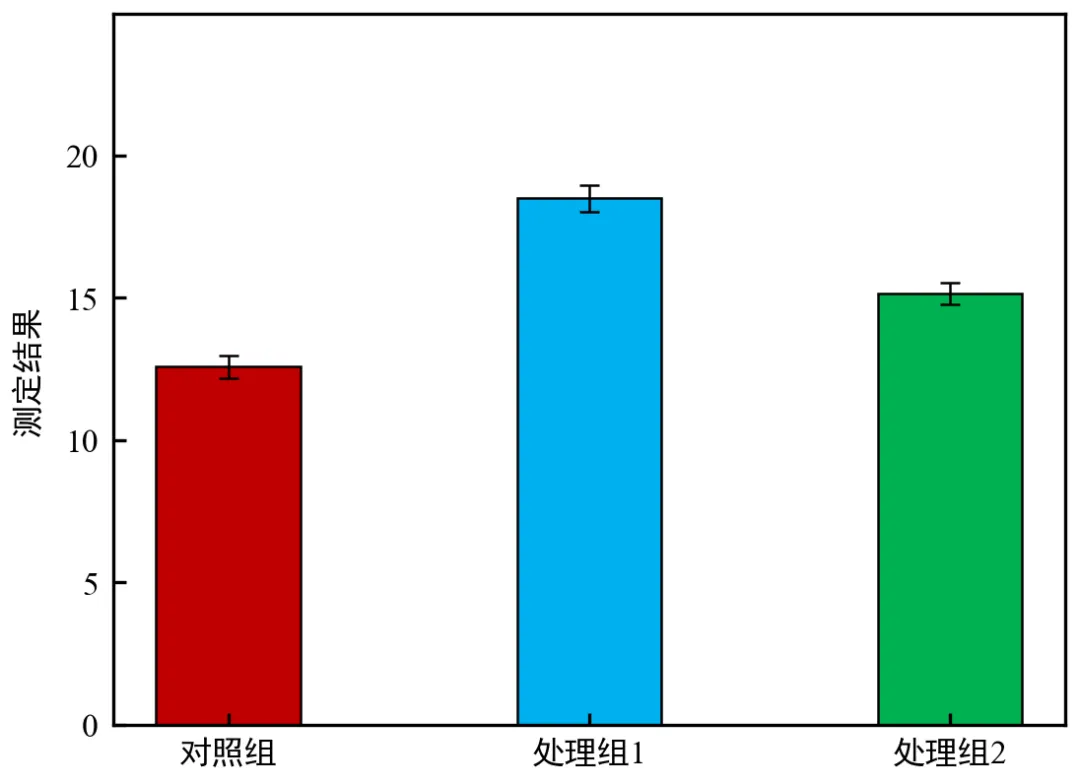
可通过切换selected_width参数,适配不同期刊的单栏/双栏要求: 双栏:selected_width = bar_width_list[0](0.28),画布尺寸设为(2.8, 2.5);单栏:selected_width = bar_width_list[1](0.4),画布尺寸设为(3.8, 2.8);
ax.yaxis.set_major_locator(plt.MaxNLocator(5)) 可减少y轴刻度,避免图表杂乱;
导出的PDF文件字体可编辑,分辨率300DPI,直接满足期刊投稿要求;
若期刊有特殊要求(如特定颜色、字体),可在样式函数中调整对应参数。
进阶4:异常数据处理+柱状图适配
该程序可处理统计数据中的异常值(如标准误为0、均值异常),绘制适配异常数据的柱状图,适用于真实实验数据(难免存在异常值),避免因异常数据导致图表报错或失真。
import pandas as pd
import matplotlib.pyplot as plt
import numpy as np
# 1. 独立定义学术样式
defset_academic_bar_style():
plt.rcParams['font.family'] = ['Times New Roman', 'SimHei']
plt.rcParams['font.size'] = 9
plt.rcParams['axes.unicode_minus'] = False
plt.rcParams['axes.linewidth'] = 1.0
plt.rcParams['xtick.major.width'] = 1.0
plt.rcParams['ytick.major.width'] = 1.0
plt.rcParams['xtick.major.size'] = 3.5
plt.rcParams['ytick.major.size'] = 3.5
plt.rcParams['xtick.direction'] = 'in'
plt.rcParams['ytick.direction'] = 'in'
plt.rcParams['legend.frameon'] = False
plt.rcParams['pdf.fonttype'] = 42
plt.rcParams['savefig.dpi'] = 300
set_academic_bar_style()
# 2. 读取统计数据,并模拟异常数据
df = pd.read_csv('柱状图统计数据.csv')
df.loc[df['分组'] == '处理组2', '标准误'] = 0.0
df.loc[df['分组'] == '对照组', '均值'] = 25.0
# 3. 异常数据处理
df['标准误'] = df['标准误'].replace(0.0, 0.01)
abnormal_group = df[df['均值'] > 20]['分组'].values[0]
# 4. 准备颜色列表(正常情况下的柱子颜色)
normal_colors = ['#70AD47', '#ED7D31', '#4472C4'] # 对照组、处理组1、处理组2的默认颜色
x = np.arange(len(df))
bar_width = 0.35
fig, ax = plt.subplots(figsize=(4.0, 3.0))
# 绘制柱状图
for i, row in df.iterrows():
group = row['分组']
mean_val = row['均值']
if group == abnormal_group:
ax.bar(x[i], mean_val, width=bar_width, color='#FFE6E6',
edgecolor='red', linewidth=0.8)
else:
ax.bar(x[i], mean_val, width=bar_width, color=normal_colors[i],
edgecolor='black', linewidth=0.5)
# 添加误差棒
ax.errorbar(x, df['均值'], yerr=df['标准误'], fmt='none', ecolor='black', capsize=3)
# 5. 异常标注
abnormal_x = x[df['分组'] == abnormal_group][0]
abnormal_y = df[df['分组'] == abnormal_group]['均值'].values[0]
ax.text(abnormal_x+0.4, abnormal_y + 0.5, '异常值(实验误差)',
ha='center', fontsize=7, color='red', fontweight='bold')
# 6. 坐标轴与布局优化
ax.set_xticks(x)
ax.set_xticklabels(df['分组'])
ax.set_ylabel('实验指标测定值')
ax.set_ylim(0, max(df['均值']) * 1.1)
plt.tight_layout()
plt.show()
fig.savefig('异常数据适配柱状图.pdf', bbox_inches='tight', pad_inches=0.05)
fig.savefig('异常数据适配柱状图.png', bbox_inches='tight', pad_inches=0.05)
运行后弹出包含异常数据的柱状图,异常分组(对照组)用红色边框标注,并有文字说明;
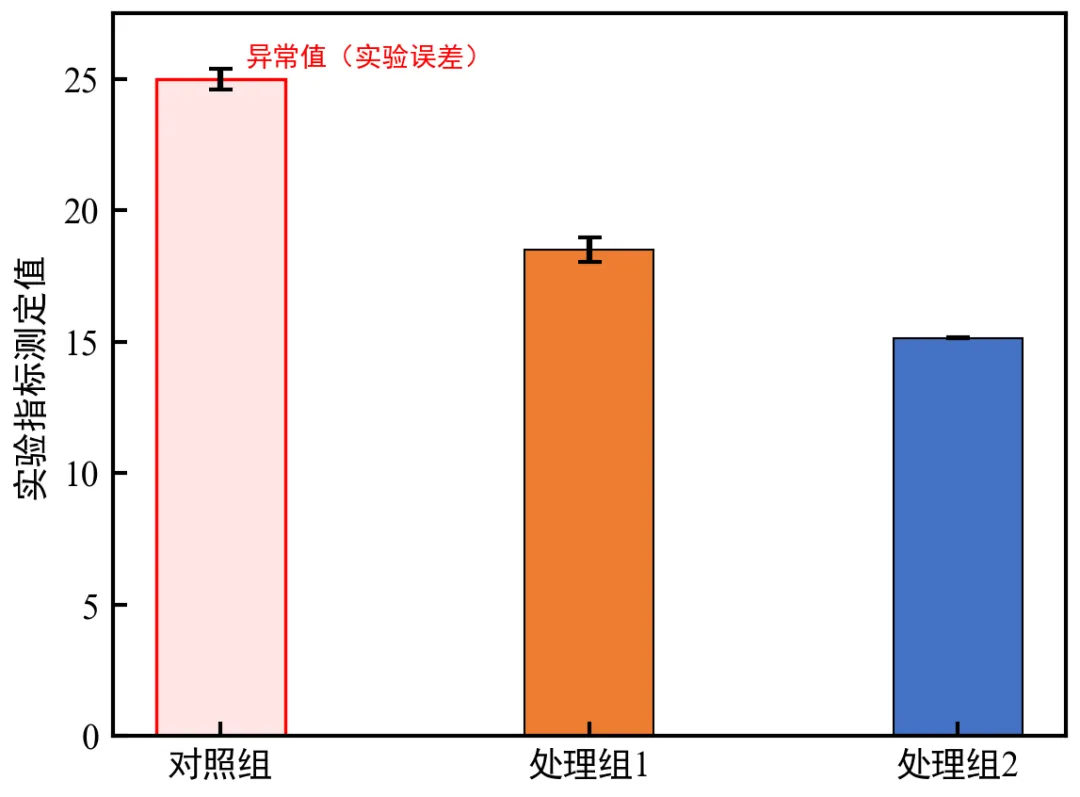
核心技巧:真实实验数据中,需先处理异常值(替换、标注),再绘制图表,否则会出现误差棒消失、柱子压缩等问题;
异常标注符合学术规范,让审稿人清晰了解异常原因,避免被质疑数据真实性;
可根据真实异常原因修改标注文字(如“样本污染”“仪器误差”等),适配具体实验场景。
实操任务2:编写循环函数,自动计算柱顶坐标,绘制p值连线与显著性星号(*)
手动标注显著性星号耗时易出错,且位置难以精准控制,本任务从基础的显著性判断函数入手,逐步进阶至自动化标注、多组两两对比、位置自适应优化,结合统计检验,实现从p值计算到星号标注的全流程自动化,所有程序独立可执行,贴合实战场景。
基础版:显著性判断函数+两组手动标注
该程序可编写独立的显著性判断函数,手动计算柱顶坐标,绘制两组对比的显著性星号,适用于简单两组实验对比,手动控制星号位置,理解显著性标注的核心原理。
import pandas as pd
import matplotlib.pyplot as plt
import numpy as np
from scipy import stats # 用于统计检验,计算p值
# 1. 独立定义学术样式
defset_academic_bar_style():
plt.rcParams['font.family'] = ['Times New Roman','SimHei']
plt.rcParams['font.size'] = 9
plt.rcParams['axes.unicode_minus'] = False
plt.rcParams['axes.linewidth'] = 1.0
plt.rcParams['xtick.major.width'] = 1.0
plt.rcParams['ytick.major.width'] = 1.0
plt.rcParams['xtick.major.size'] = 3.5
plt.rcParams['ytick.major.size'] = 3.5
plt.rcParams['xtick.direction'] = 'in'
plt.rcParams['ytick.direction'] = 'in'
plt.rcParams['legend.frameon'] = False
plt.rcParams['pdf.fonttype'] = 42
plt.rcParams['savefig.dpi'] = 300
set_academic_bar_style()
# 2. 核心函数:显著性判断(独立函数,可复用,输入p值,输出对应星号)
defget_significance(p_value):
"""
根据p值判断显著性等级,贴合学术规范
参数:p_value - 统计检验得到的p值(float类型)
返回:显著性星号(str类型),ns表示不显著
"""
if p_value < 0.001:
return'***'# p<0.001,极显著
elif p_value < 0.01:
return'**'# p<0.01,高度显著
elif p_value < 0.05:
return'*'# p<0.05,显著
else:
return'ns'# p≥0.05,不显著
# 3. 读取数据,计算p值(两组独立样本t检验)
# 读取原始数据(用于统计检验)和统计数据(用于绘图)
raw_df = pd.read_csv('柱状图原始数据.csv')
stat_df = pd.read_csv('柱状图统计数据.csv')
control = raw_df['对照组'] # 对照组原始数据
treat1 = raw_df['处理组1'] # 处理组1原始数据
# 独立样本t检验(equal_var=False表示不假设方差齐性,实验统计常用)
t_stat, p_val = stats.ttest_ind(control, treat1, equal_var=False)
sig_mark = get_significance(p_val) # 获取显著性星号
print(f'两组对比p值:{p_val.round(4)},显著性:{sig_mark}') # 打印p值和显著性,便于核对
# 4. 绘制两组柱状图(基础步骤,复用前面的绘图逻辑)
x = [0, 1]
mean_vals = [stat_df.iloc[0,1], stat_df.iloc[1,1]] # 两组均值
sem_vals = [stat_df.iloc[0,2], stat_df.iloc[1,2]] # 两组标准误
fig, ax = plt.subplots(figsize=(3.2, 2.8))
# 绘制柱状图+误差棒
ax.bar(x, mean_vals, width=0.4, color=['#888888', '#4472C4'], edgecolor='black', linewidth=0.5)
ax.errorbar(x, mean_vals, yerr=sem_vals, fmt='none', ecolor='black', capsize=3)
# 5. 手动计算柱顶坐标,绘制显著性连线与星号(核心步骤,理解原理)
y_max = max(mean_vals) + max(sem_vals) # 最高柱子的顶端高度(均值+标准误)
line_y = y_max * 1.1# 显著性连线的高度(高于最高柱子10%,避免遮挡)
# 绘制显著性连线(连接两组柱子顶端)
ax.plot([0, 1], [line_y, line_y], color='black', linewidth=0.7)
# 绘制显著性星号(位于连线中间,加粗显示)
ax.text(0.5, line_y * 1.05, sig_mark, ha='center', fontsize=10, fontweight='bold')
# 6. 坐标轴与布局设置
ax.set_xticks(x)
ax.set_xticklabels(['对照组', '处理组1'])
ax.set_ylabel('指标数值')
ax.set_ylim(0, line_y * 1.3) # y轴范围预留足够空间,避免星号超出
plt.tight_layout()
plt.show()
fig.savefig('两组显著性手动标注.pdf', bbox_inches='tight', pad_inches=0.05)
fig.savefig('两组显著性手动标注.png', bbox_inches='tight', pad_inches=0.05)
运行后会打印p值(约0.0000)和显著性(***),弹出带显著性星号的两组柱状图;显著性连线位于两组柱子顶端上方,星号居中,清晰可见,符合学术规范;
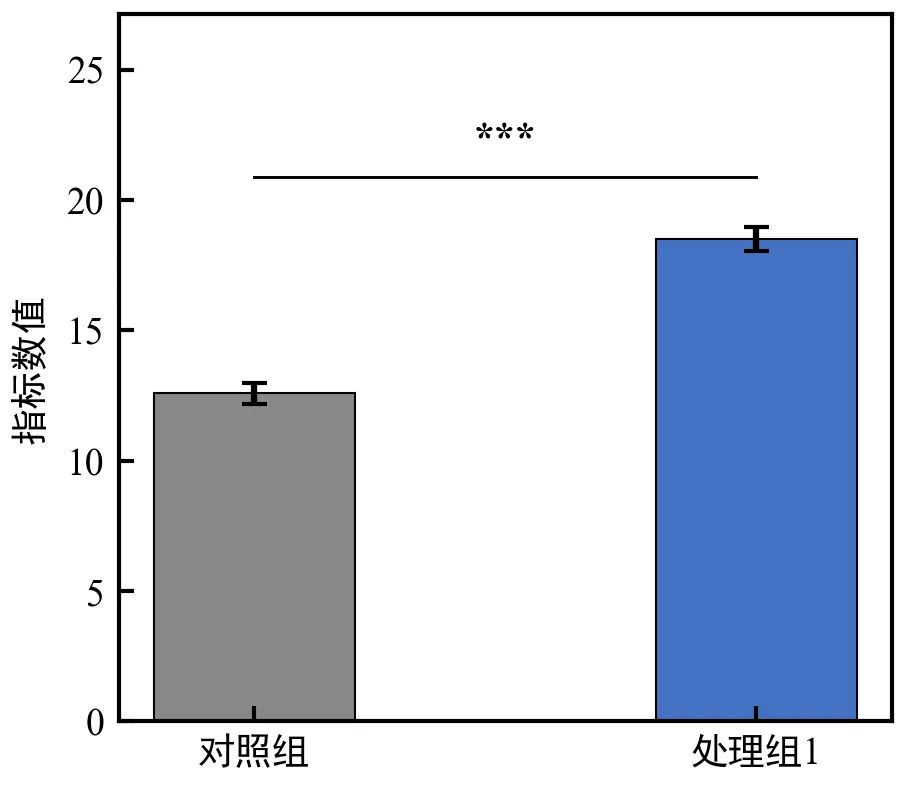
核心原理:line_y的计算的是“最高柱子顶端+10%”,确保星号不遮挡柱子和误差棒;
新手可通过调整line_y的系数(如1.1改为1.2),改变星号的高度;
若p值大于0.05,星号会显示为“ns”,此时可选择不绘制连线和星号(贴合学术习惯);
统计检验的p值是显著性标注的核心,必须基于原始数据计算,不能手动填写。
进阶1:两组自动化标注
该程序封装自动化标注函数,自动计算p值、柱顶坐标、连线和星号,无需手动干预,适用于批量处理两组对比实验,提升绘图效率,避免手动计算出错
import pandas as pd
import matplotlib.pyplot as plt
import numpy as np
from scipy import stats
# 1. 独立定义学术样式
defset_academic_bar_style():
plt.rcParams['font.family'] = ['Times New Roman','SimHei']
plt.rcParams['font.size'] = 9
plt.rcParams['axes.unicode_minus'] = False
plt.rcParams['axes.linewidth'] = 1.0
plt.rcParams['xtick.major.width'] = 1.0
plt.rcParams['ytick.major.width'] = 1.0
plt.rcParams['xtick.major.size'] = 3.5
plt.rcParams['ytick.major.size'] = 3.5
plt.rcParams['xtick.direction'] = 'in'
plt.rcParams['ytick.direction'] = 'in'
plt.rcParams['legend.frameon'] = False
plt.rcParams['pdf.fonttype'] = 42
plt.rcParams['savefig.dpi'] = 300
set_academic_bar_style()
# 2. 封装显著性判断函数
defget_significance(p_value):
if p_value < 0.001:
return'***'
elif p_value < 0.01:
return'**'
elif p_value < 0.05:
return'*'
else:
return'ns'
# 3. 封装自动化标注函数(核心进阶,可直接复用)
defauto_annotate_sig_two_groups(ax, x1, x2, data1, data2, mean1, mean2, sem1, sem2):
"""
自动化标注两组对比的显著性星号,无需手动计算坐标
参数:
ax - 绘图轴对象
x1 - 第一组柱子的x轴坐标
x2 - 第二组柱子的x轴坐标
data1 - 第一组原始数据(用于计算p值)
data2 - 第二组原始数据(用于计算p值)
mean1 - 第一组均值
mean2 - 第二组均值
sem1 - 第一组标准误
sem2 - 第二组标准误
"""
# 执行t检验,计算p值
t_stat, p_val = stats.ttest_ind(data1, data2, equal_var=False)
sig_mark = get_significance(p_val)
print(f'两组对比p值:{p_val:.4f},显著性:{sig_mark}')
# 自动计算连线高度(最高柱子顶端+1.2倍标准误,避免遮挡)
y_top = max(mean1 + sem1, mean2 + sem2) # 柱顶+误差棒顶高度
line_y = y_top * 1.15# 连线高度(预留15%空间)
# 绘制显著性连线
ax.plot([x1, x2], [line_y, line_y], color='black', linewidth=0.7)
# 绘制星号(居中显示)
ax.text((x1 + x2) / 2, line_y * 1.03, sig_mark, ha='center', fontsize=10, fontweight='bold')
# 返回当前y轴上限调整参考值(便于后续自动调整y轴范围)
return line_y * 1.25
# 4. 读取数据,绘制两组柱状图并调用自动化标注函数
raw_df = pd.read_csv('柱状图原始数据.csv')
stat_df = pd.read_csv('柱状图统计数据.csv')
control = raw_df['对照组']
treat1 = raw_df['处理组1']
x = [0, 1]
mean_vals = [stat_df.iloc[0, 1], stat_df.iloc[1, 1]]
sem_vals = [stat_df.iloc[0, 2], stat_df.iloc[1, 2]]
fig, ax = plt.subplots(figsize=(3.2, 2.8))
ax.bar(x, mean_vals, width=0.4, color=['#888888', '#4472C4'], edgecolor='black', linewidth=0.5)
ax.errorbar(x, mean_vals, yerr=sem_vals, fmt='none', ecolor='black', capsize=3)
# 调用自动化标注函数(一步完成p值计算、连线、星号)
y_upper = auto_annotate_sig_two_groups(ax, 0, 1, control, treat1, mean_vals[0], mean_vals[1], sem_vals[0], sem_vals[1])
# 坐标轴设置
ax.set_xticks(x)
ax.set_xticklabels(['对照组', '处理组1'])
ax.set_ylabel('指标数值')
ax.set_ylim(0, y_upper) # 使用函数返回的y轴上限
plt.tight_layout()
plt.show()
fig.savefig('两组自动化显著性标注.pdf', bbox_inches='tight', pad_inches=0.05)
fig.savefig('两组自动化显著性标注.png', bbox_inches='tight', pad_inches=0.05)
运行后自动打印p值和显著性星号,弹出带显著性标注的柱状图,无需手动计算坐标;
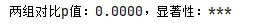
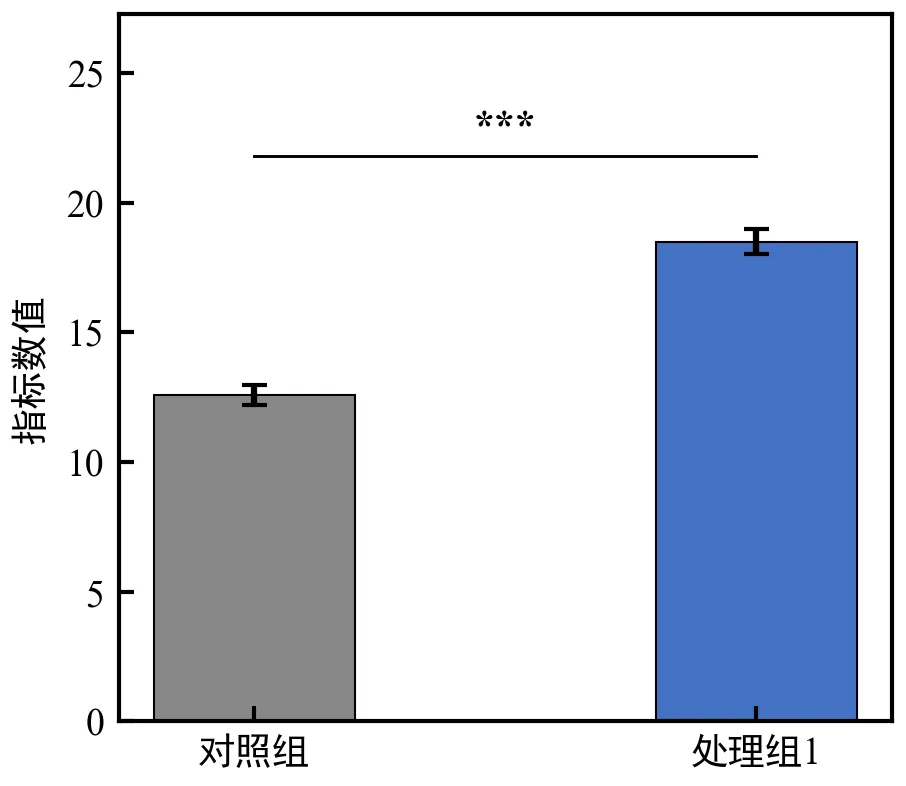
自动化函数 auto_annotate_sig_two_groups 封装了t检验、星号判断、连线绘制、坐标计算,可直接复用到其他两组对比场景;
函数返回推荐的y轴上限,可灵活用于设置ylim,避免星号被截断;
如需调整连线高度系数(默认1.15),可修改函数内的 line_y = y_top * 1.15 参数;
若p值不显著(ns),按学术惯例通常不绘制连线,可在函数内增加判断:if sig_mark != 'ns': 才执行绘制连线和星号的代码。
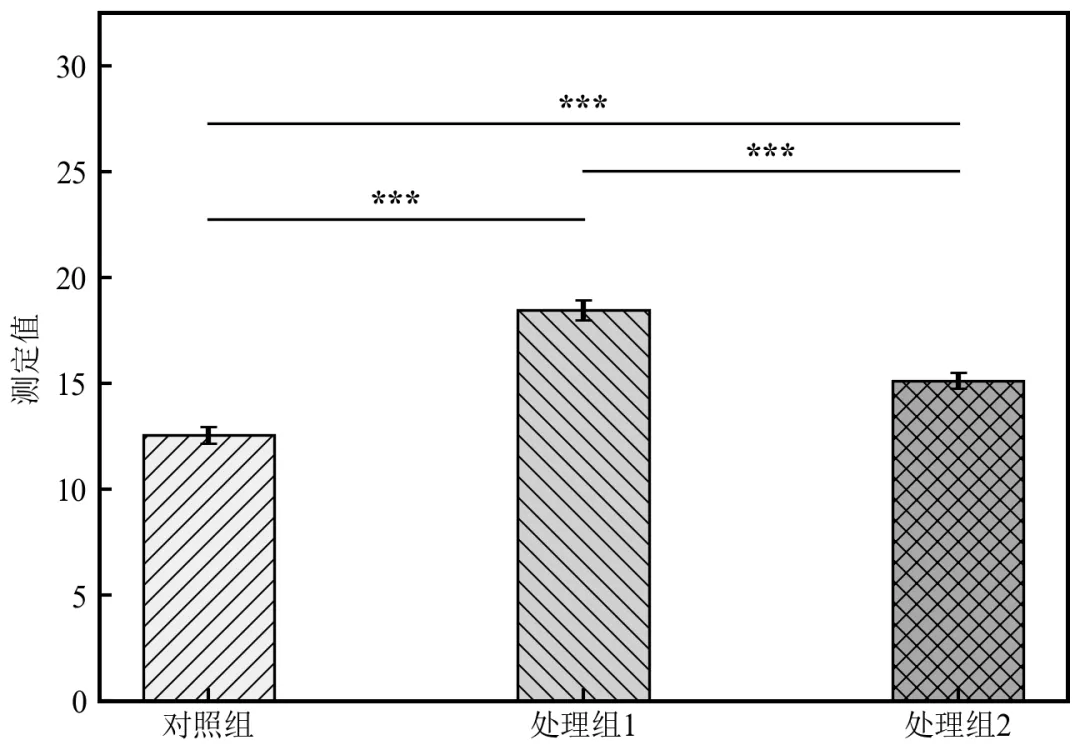
进阶2:多组两两对比自动化标注(含多重校正)
该程序可对三组及以上数据进行两两比较,自动计算校正后p值,标注显著性星号,适用于多组实验对比(如对照组+2个处理组),需要标注所有显著组对。
import pandas as pd
import matplotlib.pyplot as plt
import numpy as np
from scipy import stats
from itertools import combinations
# 1. 学术样式定义
defset_academic_bar_style():
plt.rcParams['font.family'] = ['Times New Roman','SimHei']
plt.rcParams['font.size'] = 9
plt.rcParams['axes.unicode_minus'] = False
plt.rcParams['axes.linewidth'] = 1.0
plt.rcParams['xtick.major.width'] = 1.0
plt.rcParams['ytick.major.width'] = 1.0
plt.rcParams['xtick.major.size'] = 3.5
plt.rcParams['ytick.major.size'] = 3.5
plt.rcParams['xtick.direction'] = 'in'
plt.rcParams['ytick.direction'] = 'in'
plt.rcParams['legend.frameon'] = False
plt.rcParams['pdf.fonttype'] = 42
plt.rcParams['savefig.dpi'] = 300
set_academic_bar_style()
# 2. 显著性判断函数
defget_significance(p_value):
if p_value < 0.001:
return'***'
elif p_value < 0.01:
return'**'
elif p_value < 0.05:
return'*'
else:
return'ns'
# 3. 多组两两比较显著性标注函数(含Bonferroni校正)
defannotate_multi_group_sig(ax, raw_data_dict, stat_df, x_positions, y_multiplier=1.2, correction='bonferroni'):
"""
自动标注多组数据的两两比较显著性,含多重校正
参数:
ax: 绘图轴对象
raw_data_dict: 字典,键为分组名称,值为原始数据数组
stat_df: 统计数据DataFrame(包含分组、均值、标准误)
x_positions: 各组对应的x轴坐标(与分组顺序一致)
y_multiplier: 连线高度系数(控制连线层数间隔)
correction: 多重校正方法,'bonferroni'或None
"""
groups = list(raw_data_dict.keys())
n_groups = len(groups)
n_comparisons = n_groups * (n_groups - 1) // 2# 两两比较总次数
# 计算所有组合的p值并存储
p_values = []
comparisons = []
for (i, j) in combinations(range(n_groups), 2):
data1 = raw_data_dict[groups[i]]
data2 = raw_data_dict[groups[j]]
t_stat, p = stats.ttest_ind(data1, data2, equal_var=False)
comparisons.append((i, j))
p_values.append(p)
# 多重校正(Bonferroni法,学术统计常用)
if correction == 'bonferroni':
p_corrected = [min(p * n_comparisons, 1.0) for p in p_values] # 校正后p值上限为1.0
print(f'使用Bonferroni校正,比较次数:{n_comparisons}')
else:
p_corrected = p_values
# 计算各组柱顶+误差棒高度(用于连线分层)
top_heights = []
for idx, g in enumerate(groups):
mean_val = stat_df[stat_df['分组'] == g]['均值'].values[0]
sem_val = stat_df[stat_df['分组'] == g]['标准误'].values[0]
top_heights.append(mean_val + sem_val)
base_y = max(top_heights) * y_multiplier # 第一层连线基准高度
# 按显著性等级分层绘制连线(显著程度高的连线放在上层,避免交叉)
sig_comparisons = []
for idx, (i, j) in enumerate(comparisons):
p = p_corrected[idx]
sig = get_significance(p)
if sig != 'ns':
sig_comparisons.append((i, j, sig, p))
# 按显著性星号排序(***在上层,*在下层),保证视觉层次清晰
sig_order = {'***': 3, '**': 2, '*': 1}
sig_comparisons.sort(key=lambda x: sig_order.get(x[2], 0), reverse=True)
# 逐层绘制连线与星号
y_offset_step = (max(top_heights) * 0.1) # 每层递增高度
current_y = base_y
for i, j, sig, p in sig_comparisons:
x1 = x_positions[i]
x2 = x_positions[j]
# 绘制连线
ax.plot([x1, x2], [current_y, current_y], color='black', linewidth=0.7)
# 绘制星号
ax.text((x1 + x2) / 2, current_y + y_offset_step * 0.1, sig,
ha='center', fontsize=9, fontweight='bold')
# 打印显著性信息(便于核对)
print(f'{groups[i]} vs {groups[j]}: p={p:.4f}, {sig}')
current_y += y_offset_step # 提升下一层高度
# 返回最终y轴上限参考值
return current_y + y_offset_step
# 4. 读取数据,准备绘图
raw_df = pd.read_csv('柱状图原始数据.csv')
stat_df = pd.read_csv('柱状图统计数据.csv')
# 构建原始数据字典
raw_dict = {
'对照组': raw_df['对照组'].values,
'处理组1': raw_df['处理组1'].values,
'处理组2': raw_df['处理组2'].values
}
x = np.arange(len(stat_df))
means = stat_df['均值'].values
sems = stat_df['标准误'].values
# 5. 绘制三组柱状图
fig, ax = plt.subplots(figsize=(4.2, 3.0))
colors = ['#70AD47', '#ED7D31', '#4472C4']
ax.bar(x, means, width=0.35, color=colors, edgecolor='black', linewidth=0.5)
ax.errorbar(x, means, yerr=sems, fmt='none', ecolor='black', capsize=2.5, capthick=0.7)
# 6. 调用多组显著性标注函数
y_upper = annotate_multi_group_sig(ax, raw_dict, stat_df, x, y_multiplier=1.25, correction='bonferroni')
# 7. 坐标轴优化
ax.set_xticks(x)
ax.set_xticklabels(stat_df['分组'])
ax.set_ylabel('实验指标测定值')
ax.set_ylim(0, y_upper * 1.05)
plt.tight_layout()
plt.show()
fig.savefig('多组两两对比显著性标注.pdf', bbox_inches='tight', pad_inches=0.05)
执行结果如下:运行后自动输出各组两两比较的校正p值及显著性星号,弹出带多层连线的柱状图;多重校正采用Bonferroni法,避免多重比较导致假阳性,符合学术统计规范;

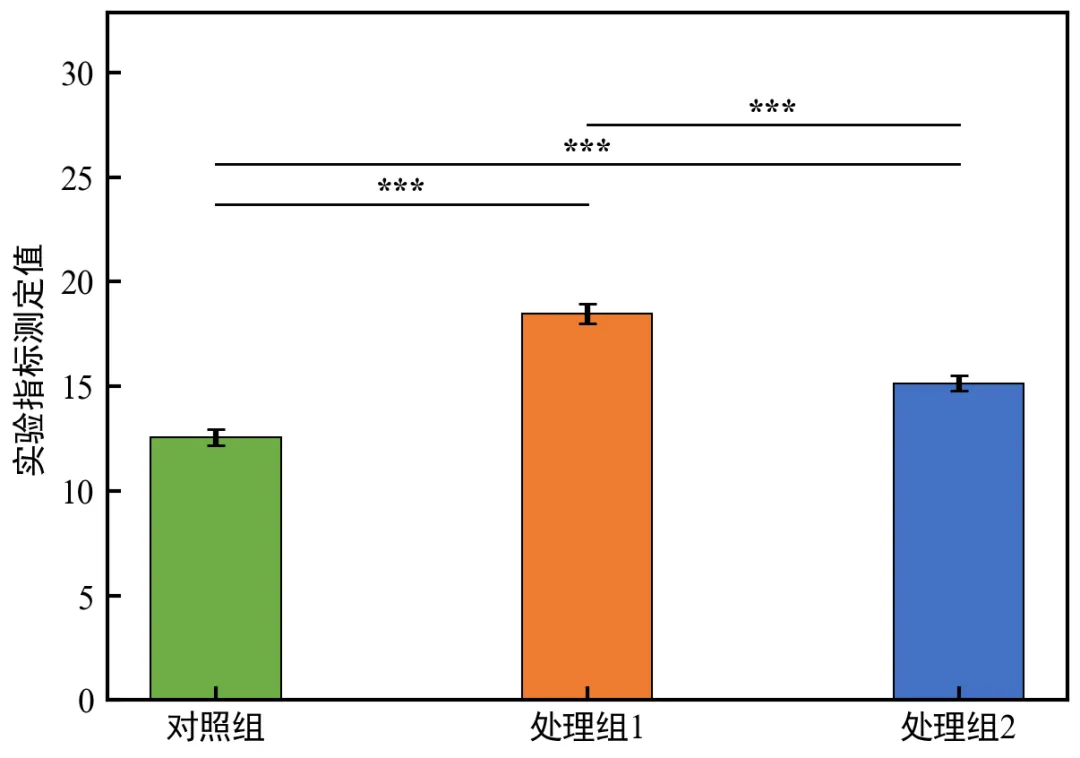
连线按显著性等级分层(***最上层),层次清晰,避免交叉和遮挡;
可根据实际需求调整correction参数(设为None则使用原始p值,适用于探索性分析);
本函数可复用于任意多组数据,只需传入对应的raw_dict和stat_df即可。
进阶3:位置自适应与智能防遮挡算法
该程序可智能检测柱顶高度与已有标注位置,动态调整连线高度,避免遮挡和重叠,适用于需要进行复杂多组对比,需生成投稿级图表,自动优化标注布局
import pandas as pd
import matplotlib.pyplot as plt
import numpy as np
from scipy import stats
from itertools import combinations
# 1. 学术样式
defset_academic_bar_style():
plt.rcParams['font.family'] = ['Times New Roman', 'SimSun'] # 优先使用Times New Roman字体,否则使用宋体
plt.rcParams['font.size'] = 9
plt.rcParams['axes.unicode_minus'] = False
plt.rcParams['axes.linewidth'] = 1.0
plt.rcParams['xtick.major.width'] = 1.0
plt.rcParams['ytick.major.width'] = 1.0
plt.rcParams['xtick.major.size'] = 3.5
plt.rcParams['ytick.major.size'] = 3.5
plt.rcParams['xtick.direction'] = 'in'
plt.rcParams['ytick.direction'] = 'in'
plt.rcParams['legend.frameon'] = False
plt.rcParams['pdf.fonttype'] = 42
plt.rcParams['savefig.dpi'] = 300
set_academic_bar_style()
defget_significance(p):
if p < 0.001: return'***'
elif p < 0.01: return'**'
elif p < 0.05: return'*'
else: return'ns'
# 2. 智能防遮挡显著性标注函数
defsmart_significance_annotate(ax, raw_dict, stat_df, x_pos, base_height_factor=1.2,
layer_step=0.08, min_gap=0.05):
"""
智能标注多组显著性,自动计算最优连线高度与层间距,防止遮挡
参数:
ax: 绘图轴
raw_dict: 原始数据字典
stat_df: 统计数据DataFrame
x_pos: 各组x坐标
base_height_factor: 第一层连线相对于最高柱顶的倍数
layer_step: 层间相对高度步长(占最高柱高的比例)
min_gap: 相邻连线最小垂直间距(占最高柱高的比例)
"""
groups = list(raw_dict.keys())
n = len(groups)
# 计算所有组合p值
p_vals = []
pairs = []
for (i, j) in combinations(range(n), 2):
t, p = stats.ttest_ind(raw_dict[groups[i]], raw_dict[groups[j]], equal_var=False)
pairs.append((i, j))
p_vals.append(p)
# Bonferroni校正
n_comp = len(p_vals)
p_corr = [min(p * n_comp, 1.0) for p in p_vals]
# 获取柱顶+误差棒高度
top_heights = []
for g in groups:
m = stat_df[stat_df['分组'] == g]['均值'].values[0]
s = stat_df[stat_df['分组'] == g]['标准误'].values[0]
top_heights.append(m + s)
max_top = max(top_heights)
current_y = max_top * base_height_factor # 起始高度
step = max_top * layer_step
min_step = max_top * min_gap
# 筛选显著组合,并按p值从小到大排序(越显著越靠上)
sig_pairs = []
for idx, (i, j) in enumerate(pairs):
sig = get_significance(p_corr[idx])
if sig != 'ns':
sig_pairs.append((i, j, sig, p_corr[idx]))
sig_pairs.sort(key=lambda x: x[3]) # p值小的排前面(更显著,放上层)
# 已占用y坐标区间记录,用于防重叠
occupied_intervals = []
defis_overlap(y, x1, x2, intervals, min_vert_gap=min_step):
"""检测新连线是否与已有标注区域重叠"""
for (y_used, used_x1, used_x2) in intervals:
if abs(y - y_used) < min_vert_gap:
# 垂直距离过近,检查水平投影是否重叠
if max(x1, used_x1) <= min(x2, used_x2):
returnTrue
returnFalse
drawn_y = []
for (i, j, sig, p) in sig_pairs:
x1, x2 = x_pos[i], x_pos[j]
# 寻找合适高度,避免重叠
candidate_y = current_y
while is_overlap(candidate_y, x1, x2, occupied_intervals, min_step):
candidate_y += step * 0.5# 微调提升
# 绘制连线
ax.plot([x1, x2], [candidate_y, candidate_y], color='black', linewidth=0.7)
# 绘制星号
ax.text((x1 + x2) / 2, candidate_y + step * 0.15, sig,
ha='center', fontsize=9, fontweight='bold')
# 记录占用区间
occupied_intervals.append((candidate_y, x1, x2))
drawn_y.append(candidate_y)
# 更新当前建议高度(为下一组留出空间)
current_y = max(current_y, candidate_y + step)
# 返回推荐y轴上限
if drawn_y:
return max(drawn_y) * 1.15
else:
return max_top * 1.3
# 3. 读取数据并绘图
raw_df = pd.read_csv('柱状图原始数据.csv')
stat_df = pd.read_csv('柱状图统计数据.csv')
raw_dict = {col: raw_df[col].values for col in raw_df.columns}
x = np.arange(len(stat_df))
means = stat_df['均值'].values
sems = stat_df['标准误'].values
fig, ax = plt.subplots(figsize=(4.5, 3.2))
colors = ['#70AD47', '#ED7D31', '#4472C4']
ax.bar(x, means, width=0.35, color=colors, edgecolor='black', linewidth=0.5)
ax.errorbar(x, means, yerr=sems, fmt='none', ecolor='black', capsize=2.5)
# 4. 调用智能防遮挡标注
y_upper = smart_significance_annotate(ax, raw_dict, stat_df, x,
base_height_factor=1.25, layer_step=0.12, min_gap=0.08)
ax.set_xticks(x)
ax.set_xticklabels(stat_df['分组'])
ax.set_ylabel('测定值')
ax.set_ylim(0, y_upper)
plt.tight_layout()
plt.show()
fig.savefig('智能防遮挡显著性标注.pdf', bbox_inches='tight', pad_inches=0.05)
fig.savefig('智能防遮挡显著性标注.png', bbox_inches='tight', pad_inches=0.05)
执行结果如下:
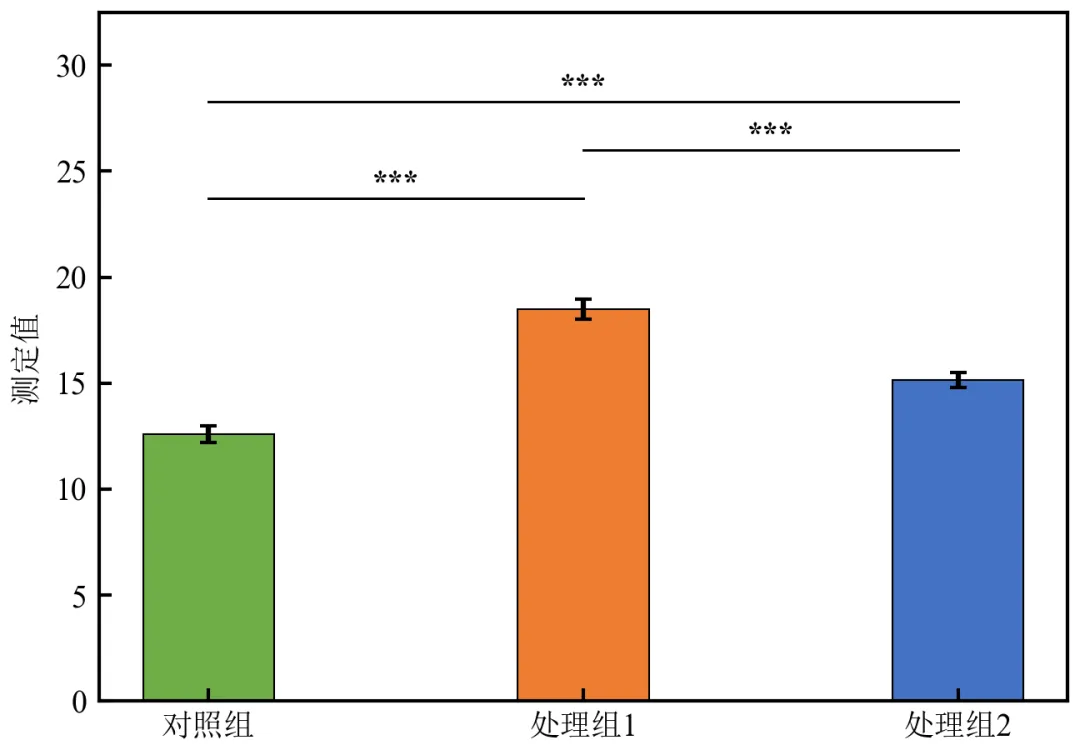
算法自动检测已有连线位置,动态调整新连线高度,彻底避免重叠和交叉;
即使添加更多组对比(如4-5组),该算法也能自适应调整,生成投稿级清晰图表;
核心参数 base_height_factor、layer_step、min_gap 可根据图表比例微调。
实操任务3:设置柱子斜线/网格纹理,适配黑白印刷,避免色彩依赖
学术期刊常要求图表在黑白印刷下仍可区分各组数据。本任务通过为柱子添加不同纹理(斜线、网格、点状)替代颜色差异,确保灰度印刷下清晰可辨。
基础版:单一纹理填充(斜线填充)
该程序为柱状图添加斜线纹理,不依赖颜色即可区分分组。适用于黑白印刷,或需同时提交彩色和灰度版本。
import pandas as pd
import matplotlib.pyplot as plt
import numpy as np
# 1. 学术样式(适配黑白印刷,线条加粗)
defset_academic_bw_style():
plt.rcParams['font.family'] = ['Times New Roman', 'SimSun'] # 西文用Times New Roman,中文用宋体'Times New Roman'
plt.rcParams['font.size'] = 9
plt.rcParams['axes.unicode_minus'] = False
plt.rcParams['axes.linewidth'] = 1.0
plt.rcParams['xtick.major.width'] = 1.0
plt.rcParams['ytick.major.width'] = 1.0
plt.rcParams['xtick.major.size'] = 3.5
plt.rcParams['ytick.major.size'] = 3.5
plt.rcParams['xtick.direction'] = 'in'
plt.rcParams['ytick.direction'] = 'in'
plt.rcParams['legend.frameon'] = False
plt.rcParams['pdf.fonttype'] = 42
plt.rcParams['savefig.dpi'] = 300
set_academic_bw_style()
# 2. 读取统计数据
df = pd.read_csv('柱状图统计数据.csv')
x = np.arange(len(df))
means = df['均值'].values
sems = df['标准误'].values
# 3. 创建画布,绘制带纹理的柱状图
fig, ax = plt.subplots(figsize=(4.0, 2.8))
# 定义填充纹理样式
hatch_patterns = ['/', '\\', 'x', 'o', '+', '*', '//', '..'] # 常用纹理图案
colors_bw = ['white', 'lightgray', 'darkgray'] # 黑白灰底色,纹理更明显
# 绘制柱状图(循环设置不同纹理)
bars = []
for i in range(len(df)):
bar = ax.bar(x[i], means[i], width=0.35,
color=colors_bw[i % len(colors_bw)], # 灰度底色
edgecolor='black', linewidth=0.8,
hatch=hatch_patterns[i]) # 核心:添加纹理填充
bars.append(bar)
# 误差棒
ax.errorbar(x, means, yerr=sems, fmt='none', ecolor='black', capsize=2.5, capthick=0.7)
# 坐标轴设置
ax.set_xticks(x)
ax.set_xticklabels(df['分组'])
ax.set_ylabel('测定值')
ax.set_ylim(0, max(means) * 1.3)
plt.tight_layout()
plt.show()
fig.savefig('斜线纹理柱状图.pdf', bbox_inches='tight', pad_inches=0.05)
fig.savefig('斜线纹理柱状图.png', bbox_inches='tight', pad_inches=0.05)
运行后弹出带斜线、网格等纹理的柱状图,即使打印为黑白,各组仍清晰可辨;
hatch参数支持多种图案:'/' 斜线,'\' 反斜线,'x' 交叉线,'o' 圆圈,'*' 星点等;
可组合使用颜色和纹理,同时满足彩色显示和黑白印刷需求;
若需更细腻的纹理密度,可通过 hatch='///' 增加斜线数量(重复字符增加密度)。
进阶1:自定义纹理密度与组合
该程序通过调整纹理密度和组合,实现更精细的视觉效果。适用于高级学术期刊,需严格符合出版规范。
import pandas as pd
import matplotlib.pyplot as plt
import numpy as np
import matplotlib.patches as mpatches # 用于创建图例句柄
# 1. 学术样式
defset_academic_bw_style():
plt.rcParams['font.family'] = ['Times New Roman', 'SimSun']
plt.rcParams['font.size'] = 9
plt.rcParams['axes.unicode_minus'] = False
plt.rcParams['axes.linewidth'] = 1.0
plt.rcParams['xtick.major.width'] = 1.0
plt.rcParams['ytick.major.width'] = 1.0
plt.rcParams['xtick.major.size'] = 3.5
plt.rcParams['ytick.major.size'] = 3.5
plt.rcParams['xtick.direction'] = 'in'
plt.rcParams['ytick.direction'] = 'in'
plt.rcParams['legend.frameon'] = False
plt.rcParams['pdf.fonttype'] = 42
plt.rcParams['savefig.dpi'] = 300
# 调整纹理线条粗细(全局设置,对hatch有效)
plt.rcParams['hatch.linewidth'] = 0.5
set_academic_bw_style()
# 2. 读取数据
df = pd.read_csv('柱状图统计数据.csv')
x = np.arange(len(df))
means = df['均值'].values
sems = df['标准误'].values
# 3. 绘制高级纹理柱状图
fig, ax = plt.subplots(figsize=(4.2, 3.0))
# 自定义纹理方案(密度可通过重复字符调整)
hatch_list = ['////', '\\\\\\\\', 'xxxx', '....'] # 增加重复字符提高密度
face_colors = ['#F0F0F0', '#D9D9D9', '#BDBDBD', '#969696'] # 不同灰度,增强对比
bars = []
for i in range(len(df)):
bar = ax.bar(x[i], means[i], width=0.35,
color=face_colors[i], edgecolor='black', linewidth=0.8,
hatch=hatch_list[i])
bars.append(bar)
ax.errorbar(x, means, yerr=sems, fmt='none', ecolor='black', capsize=2.5, capthick=0.7)
# 4. 创建图例(手动构建Patch对象,明确纹理含义)
legend_handles = []
for i, g in enumerate(df['分组']):
patch = mpatches.Patch(facecolor=face_colors[i], edgecolor='black',
hatch=hatch_list[i], label=g)
legend_handles.append(patch)
ax.legend(handles=legend_handles, loc='upper left', fontsize=8)
# 5. 坐标轴与保存
ax.set_xticks(x)
ax.set_xticklabels([''] * len(df)) # 隐藏x轴标签,改用图例区分
ax.set_ylabel('测定值')
ax.set_ylim(0, max(means) * 1.35)
plt.tight_layout()
plt.show()
fig.savefig('高级纹理柱状图_黑白印刷版.pdf', bbox_inches='tight', pad_inches=0.05)
fig.savefig('高级纹理柱状图_黑白印刷版.png', bbox_inches='tight', pad_inches=0.05)
执行结果如下:
纹理密度可通过重复字符调整(如'////'比'/'更密),满足不同打印精度要求;
添加图例后,可省略x轴标签,使图表更简洁,适合多组对比;
调整plt.rcParams['hatch.linewidth']可改变纹理线条粗细,建议设为0.5-0.8;
对于极细纹理,导出矢量PDF后可无损缩放,满足期刊高质量印刷需求。
进阶2:多组高对比复合纹理方案(四组及以上数据)
该程序适用于四组及以上数据,自动分配高对比度纹理,结合灰度底色,确保黑白印刷下完全区分。
import pandas as pd
import matplotlib.pyplot as plt
import numpy as np
import matplotlib.patches as mpatches
# 1. 学术样式(黑白印刷专用,加强线条对比)
defset_academic_bw_style():
plt.rcParams['font.family'] = ['Times New Roman', 'SimSun']
plt.rcParams['font.size'] = 9
plt.rcParams['axes.unicode_minus'] = False
plt.rcParams['axes.linewidth'] = 1.2# 加粗坐标轴,增强黑白对比
plt.rcParams['xtick.major.width'] = 1.0
plt.rcParams['ytick.major.width'] = 1.0
plt.rcParams['xtick.major.size'] = 4.0
plt.rcParams['ytick.major.size'] = 4.0
plt.rcParams['xtick.direction'] = 'in'
plt.rcParams['ytick.direction'] = 'in'
plt.rcParams['legend.frameon'] = False
plt.rcParams['pdf.fonttype'] = 42
plt.rcParams['savefig.dpi'] = 300
plt.rcParams['hatch.linewidth'] = 0.6# 纹理线条稍粗,印刷更清晰
set_academic_bw_style()
# 2. 模拟扩展数据:假设有5组实验(在原有3组基础上增加2组)
# 实际应用中直接读取真实数据文件即可,此处为演示纹理分配能力而构造数据
np.random.seed(42)
groups = ['对照组', '处理A', '处理B', '处理C', '处理D']
means = [12.45, 18.17, 15.28, 14.10, 20.05]
sems = [0.33, 0.38, 0.35, 0.40, 0.42]
df = pd.DataFrame({'分组': groups, '均值': means, '标准误': sems})
x = np.arange(len(df))
# 3. 预定义高对比度纹理组合(共8种,满足4-8组使用)
hatch_pool = ['////', '\\\\\\\\', 'xxxx', '....', '++++', '****', 'oooo', '||||']
# 预定义灰度底色(从浅到深),保证即使纹理相近也能通过灰度区分
gray_pool = ['#F5F5F5', '#E0E0E0', '#C0C0C0', '#A0A0A0', '#808080', '#606060', '#404040', '#202020']
fig, ax = plt.subplots(figsize=(5.0, 3.2)) # 画布稍宽,容纳多组
# 4. 循环绘制柱状图,自动分配纹理和灰度
bars = []
for i in range(len(df)):
hatch = hatch_pool[i % len(hatch_pool)] # 循环使用纹理,防止重复
gray = gray_pool[i % len(gray_pool)]
bar = ax.bar(x[i], df.iloc[i]['均值'], width=0.4,
color=gray, edgecolor='black', linewidth=0.8, hatch=hatch)
bars.append(bar)
ax.errorbar(x, df['均值'], yerr=df['标准误'], fmt='none', ecolor='black',
capsize=3, capthick=0.8, elinewidth=0.8)
# 5. 创建图例(分组较多时,图例比x轴标签更清晰)
legend_handles = []
for i, g in enumerate(df['分组']):
patch = mpatches.Patch(facecolor=gray_pool[i % len(gray_pool)],
edgecolor='black', hatch=hatch_pool[i % len(hatch_pool)], label=g)
legend_handles.append(patch)
ax.legend(handles=legend_handles, loc='upper left', fontsize=7, ncol=2) # 两列显示节省空间
# 6. 坐标轴微调
ax.set_xticks(x)
ax.set_xticklabels([''] * len(df)) # 隐藏x轴标签,完全由图例替代
ax.set_ylabel('测定值')
ax.set_ylim(0, max(df['均值']) * 1.35)
plt.tight_layout()
plt.show()
fig.savefig('多组高对比纹理柱状图.pdf', bbox_inches='tight', pad_inches=0.05)
fig.savefig('多组高对比纹理柱状图.png', bbox_inches='tight', pad_inches=0.05)
执行结果如下:
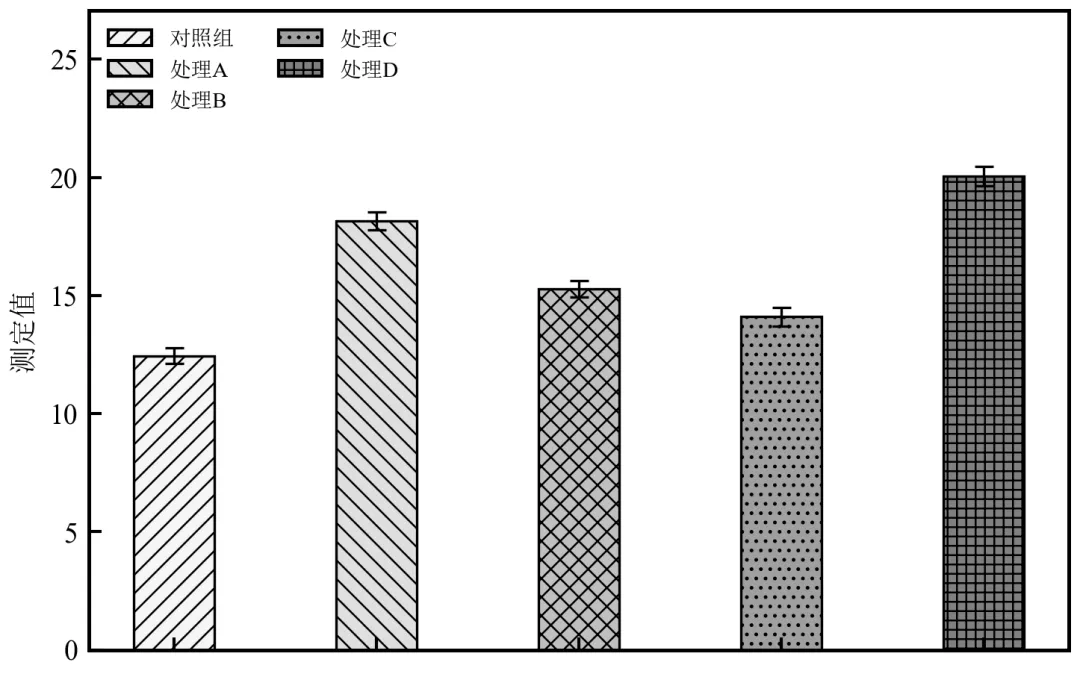
程序为5组数据自动分配了不同的纹理和灰度,即使在黑白打印下各组也可清晰区分;
纹理池(hatch_pool)和灰度池(gray_pool)均采用循环索引,支持任意组数;
图例采用两列布局(ncol=2),节省纵向空间,适合多组展示;
实际应用时,只需将模拟数据部分替换为 pd.read_csv('柱状图统计数据.csv') 即可;
若分组超过8组,可自行扩展纹理池(如增加 '++'、'oo' 等组合)。
进阶3:纹理柱状图与显著性标注结合(黑白印刷下标注星号)
该程序在进阶2的基础上,结合显著性标注,实现黑白印刷兼容的柱状图。适用于需同时展示分组差异统计显著性和黑白印刷兼容性的顶刊图表。
import pandas as pd
import matplotlib.pyplot as plt
import numpy as np
from scipy import stats
from itertools import combinations
# 1. 学术样式(黑白印刷强化版)
defset_academic_bw_style():
plt.rcParams['font.family'] = ['Times New Roman', 'SimSun']
plt.rcParams['font.size'] = 9
plt.rcParams['axes.unicode_minus'] = False
plt.rcParams['axes.linewidth'] = 1.2
plt.rcParams['xtick.major.width'] = 1.0
plt.rcParams['ytick.major.width'] = 1.0
plt.rcParams['xtick.major.size'] = 3.5
plt.rcParams['ytick.major.size'] = 3.5
plt.rcParams['xtick.direction'] = 'in'
plt.rcParams['ytick.direction'] = 'in'
plt.rcParams['legend.frameon'] = False
plt.rcParams['pdf.fonttype'] = 42
plt.rcParams['savefig.dpi'] = 300
plt.rcParams['hatch.linewidth'] = 0.5
set_academic_bw_style()
defget_significance(p):
if p < 0.001: return'***'
elif p < 0.01: return'**'
elif p < 0.05: return'*'
else: return'ns'
# 2. 读取数据
raw_df = pd.read_csv('柱状图原始数据.csv')
stat_df = pd.read_csv('柱状图统计数据.csv')
raw_dict = {col: raw_df[col].values for col in raw_df.columns}
x = np.arange(len(stat_df))
means = stat_df['均值'].values
sems = stat_df['标准误'].values
# 3. 绘制黑白纹理柱状图(复用进阶1的纹理设置)
hatch_list = ['////', '\\\\\\\\', 'xxxx'] # 三组使用三种不同纹理
face_colors = ['#F0F0F0', '#D0D0D0', '#A8A8A8']
fig, ax = plt.subplots(figsize=(4.5, 3.2))
bars = []
for i in range(len(stat_df)):
bar = ax.bar(x[i], means[i], width=0.35,
color=face_colors[i], edgecolor='black', linewidth=0.8,
hatch=hatch_list[i])
bars.append(bar)
ax.errorbar(x, means, yerr=sems, fmt='none', ecolor='black', capsize=2.5, capthick=0.7)
# 4. 计算显著性并绘制连线与星号(采用简化版防遮挡算法)
groups = list(raw_dict.keys())
n = len(groups)
p_vals = []
pairs = []
for (i, j) in combinations(range(n), 2):
t, p = stats.ttest_ind(raw_dict[groups[i]], raw_dict[groups[j]], equal_var=False)
pairs.append((i, j))
p_vals.append(p)
n_comp = len(p_vals)
p_corr = [min(p * n_comp, 1.0) for p in p_vals]
# 获取柱顶高度
top_heights = [means[i] + sems[i] for i in range(n)]
max_top = max(top_heights)
# 筛选显著组合,按p值排序
sig_pairs = []
for idx, (i, j) in enumerate(pairs):
sig = get_significance(p_corr[idx])
if sig != 'ns':
sig_pairs.append((i, j, sig, p_corr[idx]))
sig_pairs.sort(key=lambda x: x[3])
# 分层绘制连线(黑白印刷下连线使用黑色实线,足够醒目)
current_y = max_top * 1.2
step = max_top * 0.12
occupied = []
for (i, j, sig, p) in sig_pairs:
x1, x2 = x[i], x[j]
# 简单防重叠:若同一对柱子已有连线则提升高度
while any(abs(current_y - y_used) < step*0.5and
max(x1, used_x1) <= min(x2, used_x2) for (y_used, used_x1, used_x2) in occupied):
current_y += step * 0.5
ax.plot([x1, x2], [current_y, current_y], color='black', linewidth=0.8)
ax.text((x1 + x2) / 2, current_y + step*0.1, sig,
ha='center', fontsize=10, fontweight='bold', color='black')
occupied.append((current_y, x1, x2))
current_y += step
# 5. 坐标轴与图例(图例同时说明纹理和分组)
ax.set_xticks(x)
ax.set_xticklabels(stat_df['分组'])
ax.set_ylabel('测定值')
ax.set_ylim(0, current_y * 1.1)
plt.tight_layout()
plt.show()
fig.savefig('纹理柱状图带显著性.pdf', bbox_inches='tight', pad_inches=0.05)
fig.savefig('纹理柱状图带显著性.png', bbox_inches='tight', pad_inches=0.05)
执行结果如下:
柱状图使用高对比度纹理,显著性星号采用纯黑色粗体,在黑白打印下依然醒目;
显著性连线高度通过防重叠算法动态调整,避免与柱子和误差棒交叉;
若需标注更多比较组,可调节 step 和 current_y 起始系数,确保连线不拥挤。
进阶4:自动化纹理分配与灰度测试流水线
该程序在进阶3的基础上,结合自动化纹理分配与灰度测试,实现黑白印刷兼容的柱状图。适用于需同时展示分组差异统计显著性和黑白印刷兼容性的顶刊图表。
import pandas as pd
import matplotlib.pyplot as plt
import numpy as np
import matplotlib.patches as mpatches
# 1. 学术样式
defset_academic_bw_style():
plt.rcParams['font.family'] = ['Times New Roman', 'SimSun']
plt.rcParams['font.size'] = 9
plt.rcParams['axes.unicode_minus'] = False
plt.rcParams['axes.linewidth'] = 1.2
plt.rcParams['xtick.major.width'] = 1.0
plt.rcParams['ytick.major.width'] = 1.0
plt.rcParams['xtick.major.size'] = 3.5
plt.rcParams['ytick.major.size'] = 3.5
plt.rcParams['xtick.direction'] = 'in'
plt.rcParams['ytick.direction'] = 'in'
plt.rcParams['legend.frameon'] = False
plt.rcParams['pdf.fonttype'] = 42
plt.rcParams['savefig.dpi'] = 300
plt.rcParams['hatch.linewidth'] = 0.6
set_academic_bw_style()
# 2. 自动化纹理分配函数
defauto_hatch_gray_assign(n_groups):
"""
根据分组数量返回最优纹理列表和灰度列表
策略:优先使用高对比度纹理,灰度梯度均匀分布
"""
# 基础纹理池(按对比度排序)
base_hatches = ['////', '\\\\\\\\', 'xxxx', '....', '++++', '****', 'oooo', '||||']
# 灰度梯度(从10%到80%亮度,确保黑白分明)
gray_levels = np.linspace(0.15, 0.85, n_groups) # 数值越小颜色越深
grays = [str(g) for g in gray_levels] # matplotlib接受灰度字符串如'0.5'
# 纹理循环扩展,保证每组都有纹理
hatches = [base_hatches[i % len(base_hatches)] for i in range(n_groups)]
return hatches, grays
# 3. 读取真实数据
df = pd.read_csv('柱状图统计数据.csv')
n = len(df)
hatches, grays = auto_hatch_gray_assign(n)
# 4. 绘制原始彩色纹理图(用于投稿彩色版)
fig1, ax1 = plt.subplots(figsize=(4.0, 3.0))
x = np.arange(n)
bars1 = []
for i in range(n):
bar = ax1.bar(x[i], df.iloc[i]['均值'], width=0.35,
color=grays[i], edgecolor='black', linewidth=0.8, hatch=hatches[i])
bars1.append(bar)
ax1.errorbar(x, df['均值'], yerr=df['标准误'], fmt='none', ecolor='black', capsize=2.5)
ax1.set_xticks(x)
ax1.set_xticklabels(df['分组'])
ax1.set_ylabel('测定值')
ax1.set_ylim(0, max(df['均值'])*1.3)
ax1.set_title('彩色纹理版(投稿用)', fontsize=10)
plt.tight_layout()
fig1.savefig('自动纹理_彩色版.pdf', bbox_inches='tight')
fig1.savefig('自动纹理_彩色版.png', bbox_inches='tight')
# 5. 生成灰度模拟预览图(模拟黑白印刷效果)
# 通过将彩色图转换为灰度图像来检查黑白可读性
from matplotlib.colors import to_rgba
fig2, ax2 = plt.subplots(figsize=(4.0, 3.0))
# 重新绘制,但将所有颜色转换为灰度(模拟打印机效果)
for i in range(n):
# 将灰度字符串转换为亮度值
gray_val = float(grays[i]) if isinstance(grays[i], str) else grays[i]
# 使用纯灰度填充,忽略原始颜色,模拟印刷
bar = ax2.bar(x[i], df.iloc[i]['均值'], width=0.35,
color=str(gray_val), edgecolor='black', linewidth=0.8, hatch=hatches[i])
ax2.errorbar(x, df['均值'], yerr=df['标准误'], fmt='none', ecolor='black', capsize=2.5)
ax2.set_xticks(x)
ax2.set_xticklabels(df['分组'])
ax2.set_ylabel('测定值')
ax2.set_ylim(0, max(df['均值'])*1.3)
ax2.set_title('灰度模拟预览(黑白印刷效果)', fontsize=10)
plt.tight_layout()
fig2.savefig('自动纹理_灰度预览版.pdf', bbox_inches='tight')
fig2.savefig('自动纹理_灰度预览版.png', bbox_inches='tight')
plt.show()
# 6. 输出分配的纹理方案,便于核对
print("自动分配的纹理与灰度方案:")
for i, g in enumerate(df['分组']):
print(f"{g}: 纹理='{hatches[i]}', 灰度={grays[i]}")
执行结果如下:程序自动生成两个版本的图表:彩色纹理版用于正常投稿,灰度预览版用于检查黑白印刷效果;

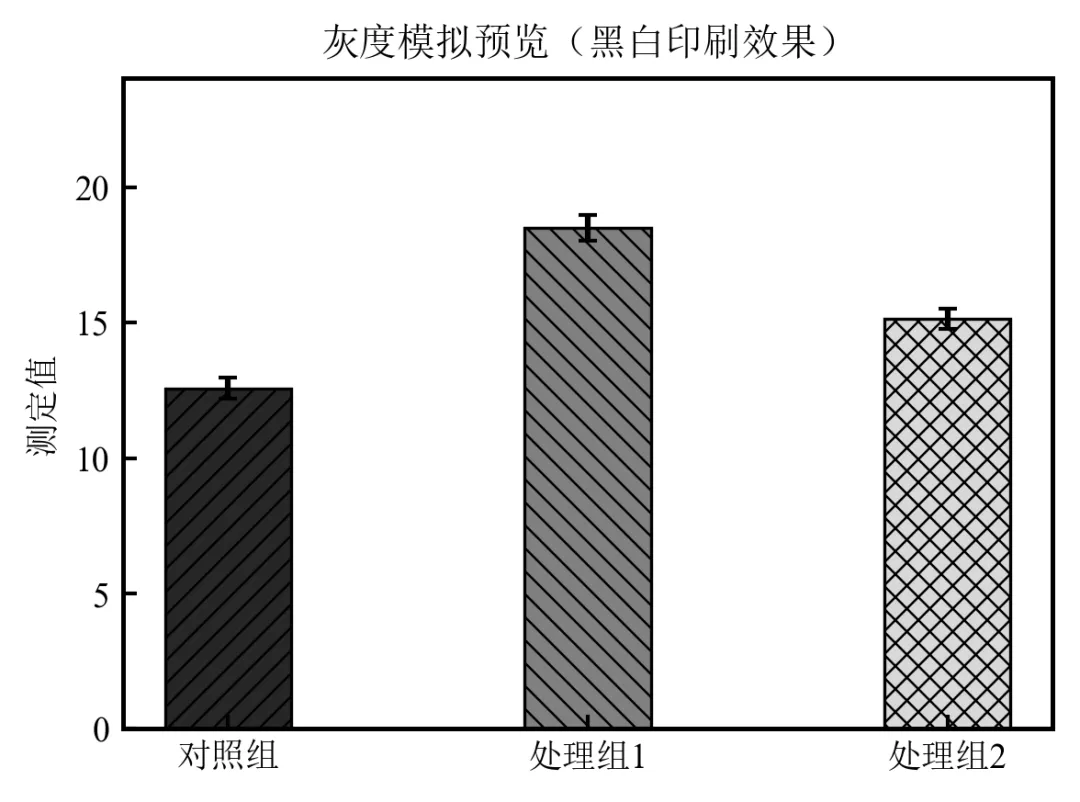
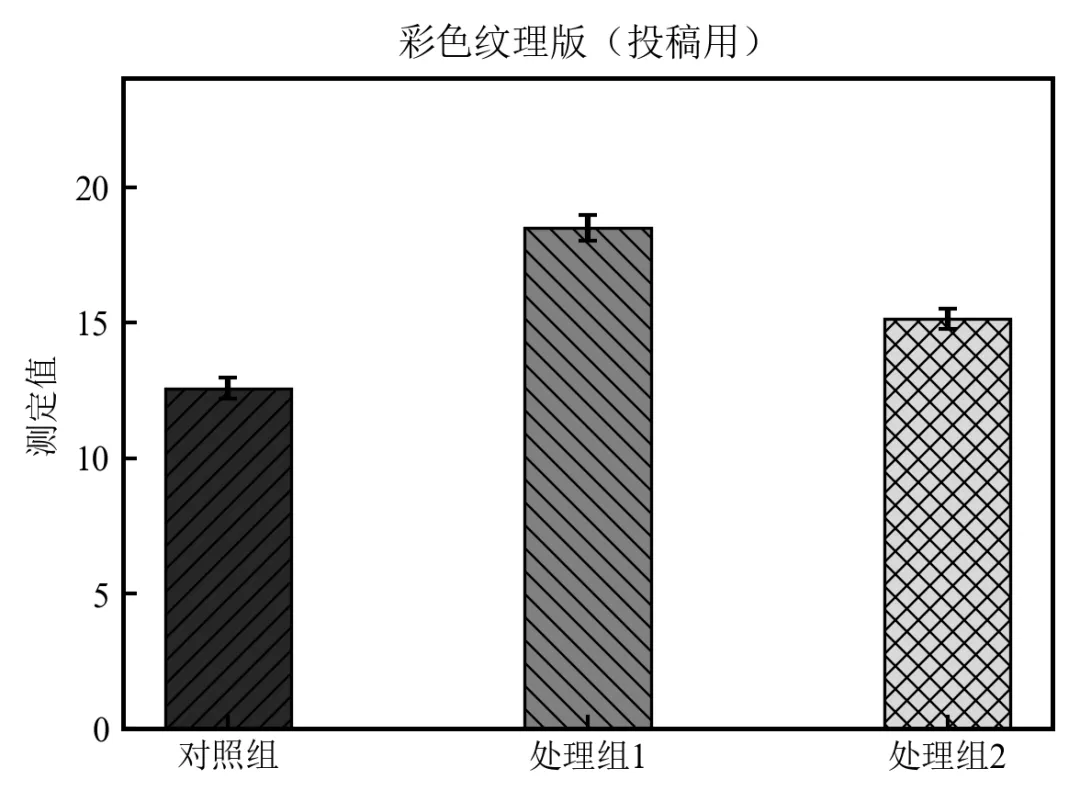
auto_hatch_gray_assign 函数根据分组数量动态计算灰度梯度,确保各组间亮度差异均匀;
通过对比两个版本,可提前发现黑白印刷下可能混淆的组,并手动调整(但自动分配已足够应对大多数情况);
输出的纹理方案文本便于记录,在投稿时可在图注中说明“不同纹理代表不同处理组”。
实操任务4:在柱状图背景叠加原始数据散点,展示样本分布与样本量信息
叠加原始数据点可直观展示数据分布、离散程度及样本量,是顶刊图表常用技巧(如Nature、Cell常用)。本任务实现散点叠加、抖动防重叠、颜色透明度优化。
基础版:单一散点叠加(展示样本分布)
该程序在柱状图背景叠加原始数据散点,直观展示样本分布,适用于展示数据离散程度。
import pandas as pd
import matplotlib.pyplot as plt
import numpy as np
# 1. 学术样式
defset_academic_style():
plt.rcParams['font.family'] = ['Times New Roman', 'SimSun']
plt.rcParams['font.size'] = 9
plt.rcParams['axes.unicode_minus'] = False
plt.rcParams['axes.linewidth'] = 1.0
plt.rcParams['xtick.major.width'] = 1.0
plt.rcParams['ytick.major.width'] = 1.0
plt.rcParams['xtick.major.size'] = 3.5
plt.rcParams['ytick.major.size'] = 3.5
plt.rcParams['xtick.direction'] = 'in'
plt.rcParams['ytick.direction'] = 'in'
plt.rcParams['legend.frameon'] = False
plt.rcParams['pdf.fonttype'] = 42
plt.rcParams['savefig.dpi'] = 300
set_academic_style()
# 2. 读取原始数据和统计数据
raw_df = pd.read_csv('柱状图原始数据.csv')
stat_df = pd.read_csv('柱状图统计数据.csv')
x = np.arange(len(stat_df))
means = stat_df['均值'].values
sems = stat_df['标准误'].values
# 3. 绘制柱状图(底层)
fig, ax = plt.subplots(figsize=(4.0, 3.0))
ax.bar(x, means, width=0.35, color='#C0C0C0', edgecolor='black', linewidth=0.5, alpha=0.6)
ax.errorbar(x, means, yerr=sems, fmt='none', ecolor='black', capsize=2.5)
# 4. 叠加原始数据散点(核心步骤)
for i, col in enumerate(raw_df.columns):
y_vals = raw_df[col].dropna().values # 该组所有原始数据
# 生成x轴抖动偏移,避免点重叠
jitter = np.random.normal(0, 0.04, size=len(y_vals)) # 正态分布抖动,宽度0.04
x_jittered = x[i] + jitter
# 绘制散点(半透明,边缘黑色,内部颜色)
ax.scatter(x_jittered, y_vals, s=12, c='#4472C4', alpha=0.7,
edgecolors='black', linewidths=0.3, zorder=10) # zorder确保点在柱子上层
# 5. 坐标轴与保存
ax.set_xticks(x)
ax.set_xticklabels(stat_df['分组'])
ax.set_ylabel('测定值')
ax.set_ylim(0, max(means) * 1.3)
plt.tight_layout()
plt.show()
fig.savefig('叠加原始数据散点图.pdf', bbox_inches='tight', pad_inches=0.05)
fig.savefig('叠加原始数据散点图.png', bbox_inches='tight', pad_inches=0.05)
执行结果如下:每个柱子周围分布着该组的原始数据点,直观展示样本量(n=30)和数据分布;
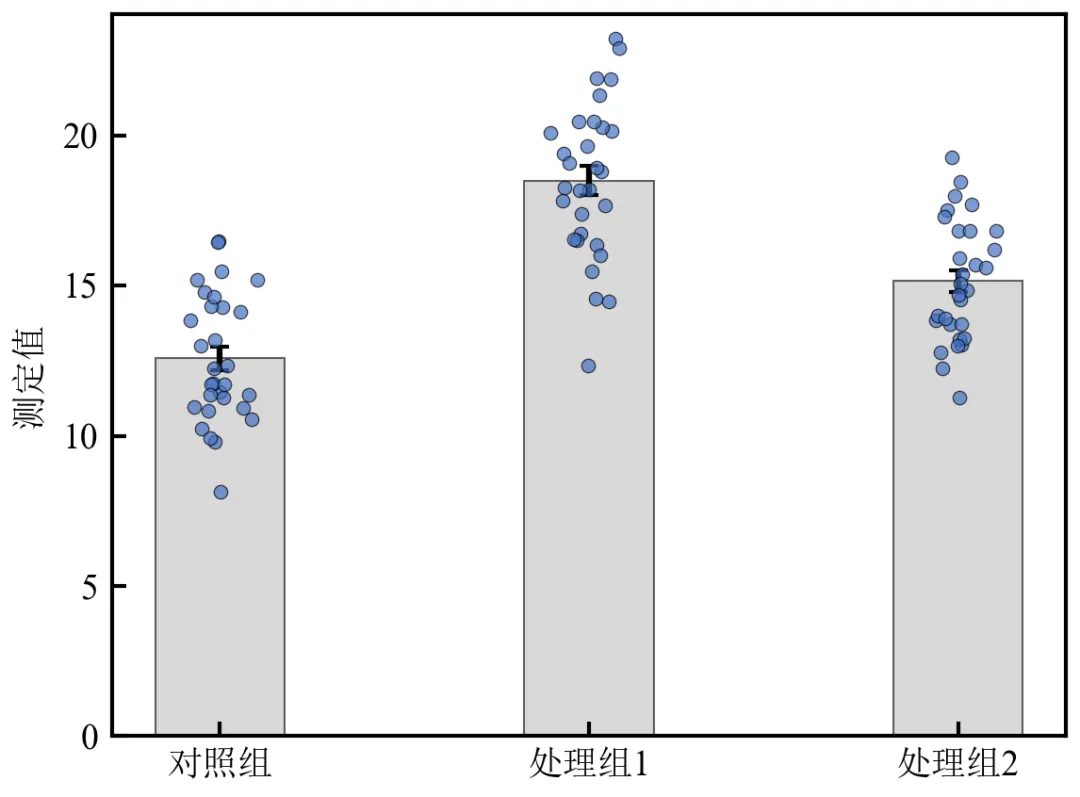
抖动(jitter)避免点完全重叠,宽度0.04适合当前x轴间距,可根据实际情况调整;
散点半透明(alpha=0.7)和边缘线可防止重叠时完全遮挡,清晰可辨;
zorder=10确保散点绘制在柱状图上层,不被遮挡。
进阶1:对称蜂群式分布+样本量标注
该程序在柱状图背景叠加原始数据散点,使用对称蜂群算法避免重叠,并自动标注每组样本量,适用于需同时展示数据分布、样本量,且散点排列美观不重叠。
import pandas as pd
import matplotlib.pyplot as plt
import numpy as np
from scipy.stats import gaussian_kde
# 1. 学术样式
defset_academic_style():
plt.rcParams['font.family'] = ['Times New Roman', 'SimSun']
plt.rcParams['font.size'] = 9
plt.rcParams['axes.unicode_minus'] = False
plt.rcParams['axes.linewidth'] = 1.0
plt.rcParams['xtick.major.width'] = 1.0
plt.rcParams['ytick.major.width'] = 1.0
plt.rcParams['xtick.major.size'] = 3.5
plt.rcParams['ytick.major.size'] = 3.5
plt.rcParams['xtick.direction'] = 'in'
plt.rcParams['ytick.direction'] = 'in'
plt.rcParams['legend.frameon'] = False
plt.rcParams['pdf.fonttype'] = 42
plt.rcParams['savefig.dpi'] = 300
set_academic_style()
# 2. 对称蜂群分布函数(模拟R语言geom_beeswarm效果)
defbeeswarm_positions(y_vals, center, width=0.3, resolution=0.02):
if len(y_vals) == 0:
return np.array([])
kde = gaussian_kde(y_vals)
y_range = np.linspace(min(y_vals), max(y_vals), 200)
density = kde(y_range)
density = density / density.max() * width
points = [] # 存储已放置的点 (x, y)
x_positions = []
for y in y_vals:
idx = np.argmin(np.abs(y_range - y))
max_offset = density[idx]
# 统计已放置点中 y 坐标与当前 y 接近的数量
n_at_y = sum(1for (px, py) in points if abs(py - y) < resolution)
offset = (n_at_y % 2 * 2 - 1) * (n_at_y // 2 + 1) * resolution * 3
offset = np.clip(offset, -max_offset, max_offset)
x_pos = center + offset
points.append((x_pos, y))
x_positions.append(x_pos)
return np.array(x_positions)
# 3. 读取数据
raw_df = pd.read_csv('柱状图原始数据.csv')
stat_df = pd.read_csv('柱状图统计数据.csv')
x = np.arange(len(stat_df))
means = stat_df['均值'].values
sems = stat_df['标准误'].values
# 4. 绘图
fig, ax = plt.subplots(figsize=(4.5, 3.2))
ax.bar(x, means, width=0.4, color='#E0E0E0', edgecolor='black', linewidth=0.6, zorder=1)
ax.errorbar(x, means, yerr=sems, fmt='none', ecolor='black', capsize=2.5, zorder=5)
# 5. 使用蜂群算法叠加散点
for i, col in enumerate(raw_df.columns):
y_vals = raw_df[col].dropna().values
# 生成蜂群分布x坐标
x_positions = beeswarm_positions(y_vals, x[i], width=0.18)
ax.scatter(x_positions, y_vals, s=14, c='#4472C4', alpha=0.6,
edgecolors='black', linewidths=0.3, zorder=10)
# 标注样本量(每组柱子下方)
ax.text(x[i], -max(means)*0.05, f'n={len(y_vals)}', ha='center', fontsize=8)
# 6. 坐标轴与保存
ax.set_xticks(x)
ax.set_xticklabels(stat_df['分组'])
ax.set_ylabel('测定值')
ax.set_ylim(-max(means)*0.1, max(means)*1.35) # 底部留空间给样本量标签
plt.tight_layout()
plt.show()
fig.savefig('蜂群散点叠加图.pdf', bbox_inches='tight', pad_inches=0.05)
fig.savefig('蜂群散点叠加图.png', bbox_inches='tight', pad_inches=0.05)
执行结果如下:散点呈对称蜂群状分布,密度高处点分布宽,有效避免重叠,美观且信息丰富;每组柱子下方标注样本量(n=30),符合顶刊图表规范;
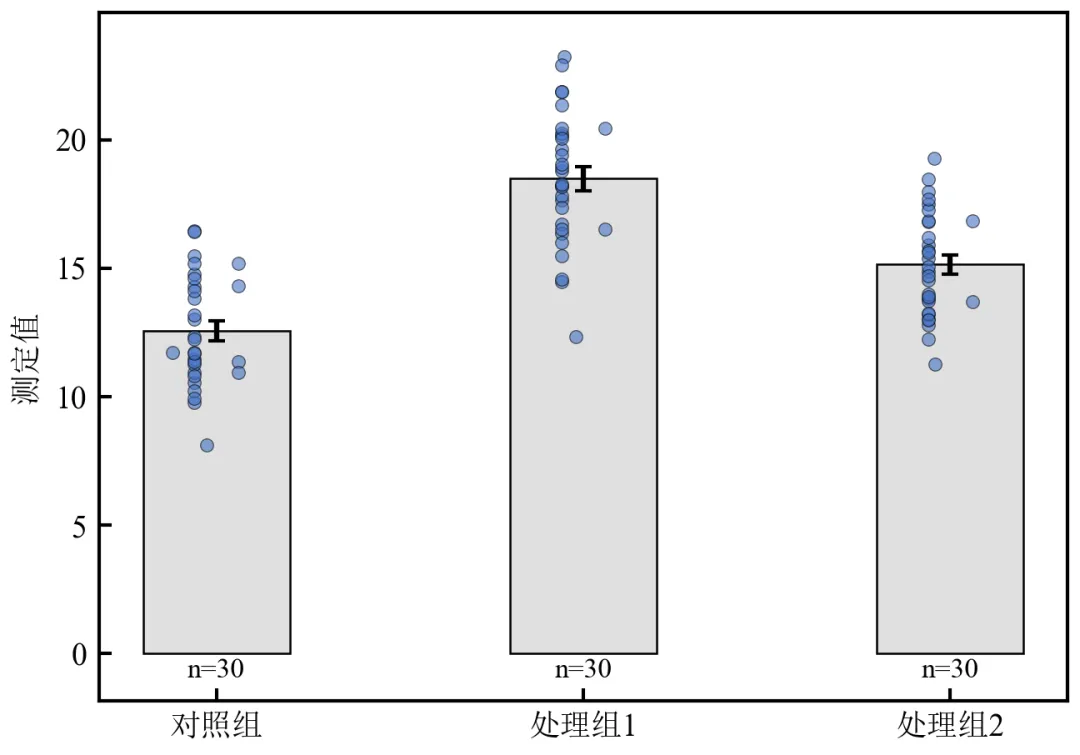
beeswarm_positions函数模拟了R语言beeswarm包的核心思想,可复用于其他散点图;
调整width参数可控制散点分布宽度,resolution影响点间最小间距;
此图同时展示均值(柱高)、误差(误差棒)、分布(散点)、样本量,信息密度高,适合投稿。
进阶2:叠加箱线图元素
该程序在柱状图基础上叠加箱线图(中位数、四分位数、须线),全面展示数据分布特征,适用于需同时展示均值和分位数信息,增强统计严谨性。
import pandas as pd
import matplotlib.pyplot as plt
import numpy as np
# 1. 学术样式(支持中文)
defset_academic_style():
plt.rcParams['font.family'] = ['Times New Roman', 'SimSun']
plt.rcParams['font.size'] = 9
plt.rcParams['axes.unicode_minus'] = False
plt.rcParams['axes.linewidth'] = 1.0
plt.rcParams['xtick.major.width'] = 1.0
plt.rcParams['ytick.major.width'] = 1.0
plt.rcParams['xtick.major.size'] = 3.5
plt.rcParams['ytick.major.size'] = 3.5
plt.rcParams['xtick.direction'] = 'in'
plt.rcParams['ytick.direction'] = 'in'
plt.rcParams['legend.frameon'] = False
plt.rcParams['pdf.fonttype'] = 42
plt.rcParams['savefig.dpi'] = 300
set_academic_style()
# 2. 读取原始数据和统计数据
raw_df = pd.read_csv('柱状图原始数据.csv')
stat_df = pd.read_csv('柱状图统计数据.csv')
x = np.arange(len(stat_df))
means = stat_df['均值'].values
sems = stat_df['标准误'].values
# 3. 绘制柱状图(底层,浅色填充)
fig, ax = plt.subplots(figsize=(4.5, 3.2))
bar_width = 0.4
ax.bar(x, means, width=bar_width, color='#D3D3D3', edgecolor='black', linewidth=0.6, alpha=0.7, zorder=1)
ax.errorbar(x, means, yerr=sems, fmt='none', ecolor='black', capsize=2.5, capthick=0.7, zorder=5)
# 4. 叠加箱线图(核心步骤)
# 箱线图绘制在柱子位置,宽度稍窄于柱子,使用白色填充避免遮挡柱子颜色
box_width = bar_width * 0.6
for i, col in enumerate(raw_df.columns):
data = raw_df[col].dropna().values
# 计算五数概括
median = np.median(data)
q1 = np.percentile(data, 25)
q3 = np.percentile(data, 75)
iqr = q3 - q1
lower_whisker = max(np.min(data), q1 - 1.5 * iqr)
upper_whisker = min(np.max(data), q3 + 1.5 * iqr)
# 绘制箱体(从Q1到Q3)
box = plt.Rectangle((x[i] - box_width/2, q1), box_width, iqr,
fill=True, facecolor='white', edgecolor='black', linewidth=0.8, zorder=10)
ax.add_patch(box)
# 绘制中位线
ax.plot([x[i] - box_width/2, x[i] + box_width/2], [median, median],
color='red', linewidth=1.2, zorder=15)
# 绘制须线
ax.plot([x[i], x[i]], [q3, upper_whisker], color='black', linewidth=0.8, zorder=10)
ax.plot([x[i], x[i]], [q1, lower_whisker], color='black', linewidth=0.8, zorder=10)
ax.plot([x[i] - box_width/4, x[i] + box_width/4], [upper_whisker, upper_whisker],
color='black', linewidth=0.8, zorder=10)
ax.plot([x[i] - box_width/4, x[i] + box_width/4], [lower_whisker, lower_whisker],
color='black', linewidth=0.8, zorder=10)
# 5. 添加样本量标注
for i, col in enumerate(raw_df.columns):
n = raw_df[col].dropna().shape[0]
ax.text(x[i], -max(means)*0.08, f'n={n}', ha='center', fontsize=8)
# 6. 坐标轴与保存
ax.set_xticks(x)
ax.set_xticklabels(stat_df['分组'])
ax.set_ylabel('测定值')
ax.set_ylim(-max(means)*0.15, max(means)*1.35)
plt.tight_layout()
plt.show()
fig.savefig('柱状图叠加箱线图.pdf', bbox_inches='tight', pad_inches=0.05)
fig.savefig('柱状图叠加箱线图.png', bbox_inches='tight', pad_inches=0.05)
执行结果如下:图中同时展示了柱状图(均值+标准误)和箱线图(中位数、四分位数、须线);箱体白色填充、中位线红色,与灰色柱子形成对比,信息层次分明;
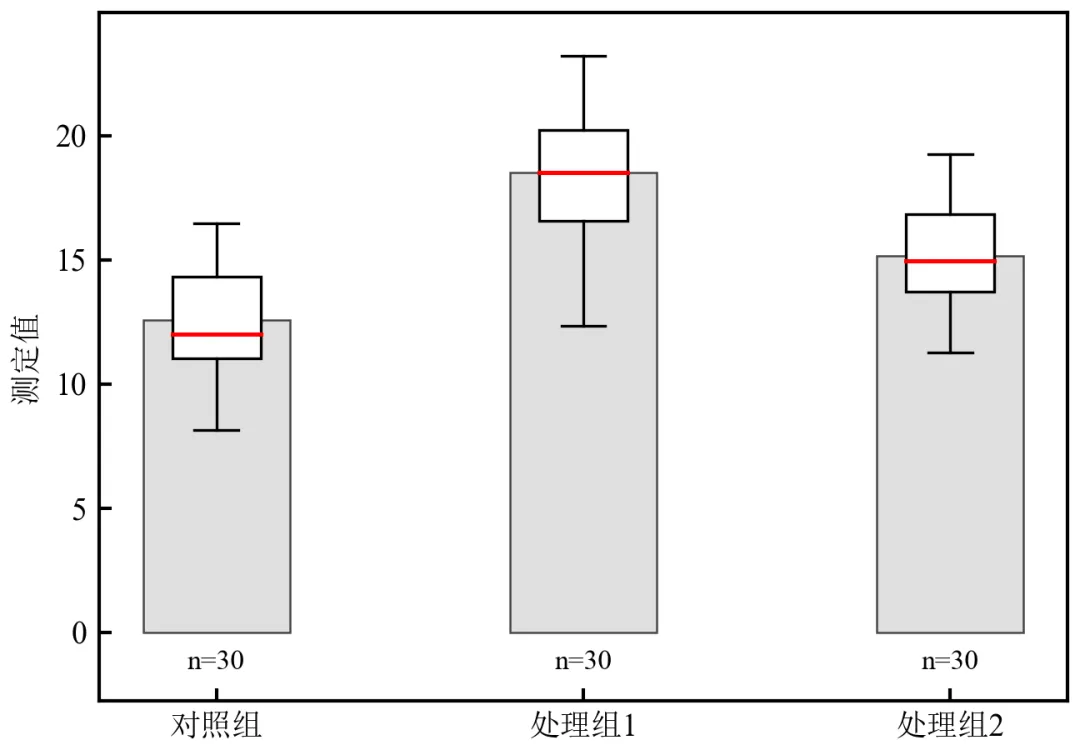
此图可替代单独绘制箱线图,节省版面,符合期刊对图表信息密度的要求;
箱线图须线采用Tukey风格(1.5倍IQR),可根据实际需求修改须线范围;
样本量标注在底部,便于审稿人快速了解实验重复次数。
进阶3:散点颜色映射分组+均值连线(适用于配对或重复测量数据)
该程序在柱状图基础上叠加散点图,每个受试者/样本用不同颜色表示,并用连线连接同一受试者/样本在不同处理下的数据点,适用于配对设计实验(如治疗前后对比)、重复测量数据,展示个体变化趋势。
import pandas as pd
import matplotlib.pyplot as plt
import numpy as np
# 1. 学术样式
defset_academic_style():
plt.rcParams['font.family'] = ['Times New Roman', 'SimSun']
plt.rcParams['font.size'] = 9
plt.rcParams['axes.unicode_minus'] = False
plt.rcParams['axes.linewidth'] = 1.0
plt.rcParams['xtick.major.width'] = 1.0
plt.rcParams['ytick.major.width'] = 1.0
plt.rcParams['xtick.major.size'] = 3.5
plt.rcParams['ytick.major.size'] = 3.5
plt.rcParams['xtick.direction'] = 'in'
plt.rcParams['ytick.direction'] = 'in'
plt.rcParams['legend.frameon'] = False
plt.rcParams['pdf.fonttype'] = 42
plt.rcParams['savefig.dpi'] = 300
set_academic_style()
# 2. 模拟配对数据(真实实验中应为同一受试者在不同处理下的测量值)
# 假设有10个受试者,接受了对照组、处理组1、处理组2三种处理
np.random.seed(42)
n_subjects = 10
subject_ids = [f'S{i+1}'for i in range(n_subjects)]
# 生成配对数据:每个受试者有一个基线值,各处理在此基础上变化
baseline = np.random.normal(12, 2, n_subjects)
control = baseline + np.random.normal(0, 0.5, n_subjects)
treat1 = baseline + np.random.normal(5, 0.8, n_subjects)
treat2 = baseline + np.random.normal(3, 0.6, n_subjects)
paired_df = pd.DataFrame({
'受试者': subject_ids,
'对照组': control,
'处理组1': treat1,
'处理组2': treat2
})
# 计算均值与标准误(用于绘制柱状图)
means = [paired_df['对照组'].mean(), paired_df['处理组1'].mean(), paired_df['处理组2'].mean()]
sems = [paired_df['对照组'].sem(), paired_df['处理组1'].sem(), paired_df['处理组2'].sem()]
groups = ['对照组', '处理组1', '处理组2']
x = np.arange(len(groups))
# 3. 绘图
fig, ax = plt.subplots(figsize=(4.5, 3.5))
bar_width = 0.5
ax.bar(x, means, width=bar_width, color='#E8E8E8', edgecolor='black', linewidth=0.6, zorder=1)
ax.errorbar(x, means, yerr=sems, fmt='none', ecolor='black', capsize=3, zorder=5)
# 4. 绘制个体连线与散点(核心)
# 为每个受试者分配一个颜色(基于colormap)
colors = plt.cm.tab10(np.linspace(0, 1, n_subjects))
for s in range(n_subjects):
y_vals = [paired_df.iloc[s]['对照组'],
paired_df.iloc[s]['处理组1'],
paired_df.iloc[s]['处理组2']]
# 绘制连线(灰色半透明,显示个体轨迹)
ax.plot(x, y_vals, color='gray', alpha=0.5, linewidth=0.8, zorder=2)
# 绘制散点(颜色区分受试者)
ax.scatter(x, y_vals, s=25, color=[colors[s]], edgecolors='black', linewidths=0.4, zorder=10)
# 5. 标注样本量(受试者人数)
ax.text(0.5, -max(means)*0.08, f'n={n_subjects}', ha='center', fontsize=8, transform=ax.transData)
# 6. 坐标轴与图例(图例展示部分受试者示例,避免过多)
ax.set_xticks(x)
ax.set_xticklabels(groups)
ax.set_ylabel('测定值')
ax.set_ylim(-max(means)*0.15, max(means)*1.3)
plt.tight_layout()
plt.show()
fig.savefig('配对数据连线散点图.pdf', bbox_inches='tight', pad_inches=0.05)
fig.savefig('配对数据连线散点图.png', bbox_inches='tight', pad_inches=0.05)
执行结果分析:图中每条灰色连线代表一个受试者在三种处理下的变化轨迹,清晰展示个体响应;散点颜色按受试者区分,便于追踪特定个体,符合《Nature Methods》等期刊常用样式;
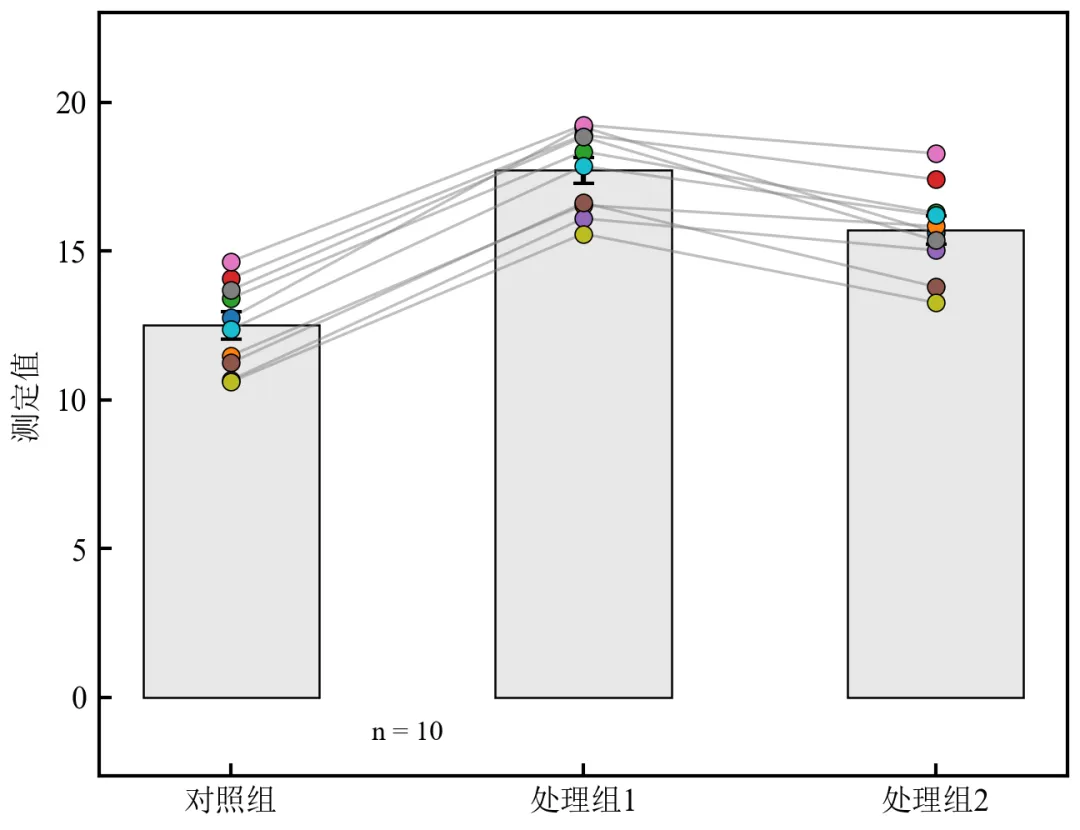
本示例使用模拟配对数据,实际应用时直接读取包含受试者ID和处理列的数据框即可;
若受试者数量较多,可省略图例或仅用灰度连线,避免颜色过多导致视觉杂乱;
此图尤其适用于展示治疗前后、剂量递增等纵向实验设计。
进阶4:全自动综合图表流水线
该程序整合了前述所有高级功能,一键生成包含柱状图、误差棒、散点蜂群分布、箱线图、显著性标注、黑白纹理的高质量图表。
import pandas as pd
import matplotlib.pyplot as plt
import numpy as np
from scipy.stats import ttest_ind, gaussian_kde
from itertools import combinations
# 1. 综合学术样式(兼顾黑白印刷和彩色显示)
defset_comprehensive_style():
plt.rcParams['font.family'] = ['Times New Roman', 'SimSun']
plt.rcParams['font.size'] = 9
plt.rcParams['axes.unicode_minus'] = False
plt.rcParams['axes.linewidth'] = 1.0
plt.rcParams['xtick.major.width'] = 1.0
plt.rcParams['ytick.major.width'] = 1.0
plt.rcParams['xtick.major.size'] = 3.5
plt.rcParams['ytick.major.size'] = 3.5
plt.rcParams['xtick.direction'] = 'in'
plt.rcParams['ytick.direction'] = 'in'
plt.rcParams['legend.frameon'] = False
plt.rcParams['pdf.fonttype'] = 42
plt.rcParams['savefig.dpi'] = 300
plt.rcParams['hatch.linewidth'] = 0.5
set_comprehensive_style()
# 2. 读取数据
raw_df = pd.read_csv('柱状图原始数据.csv')
stat_df = pd.read_csv('柱状图统计数据.csv')
groups = stat_df['分组'].tolist()
means = stat_df['均值'].values
sems = stat_df['标准误'].values
x = np.arange(len(groups))
# 3. 准备纹理与颜色(适配黑白印刷)
hatches = ['////', '\\\\\\\\', 'xxxx'] # 三组纹理
grays = ['#EAEAEA', '#C0C0C0', '#909090'] # 灰度梯度
# 4. 创建画布
fig, ax = plt.subplots(figsize=(5.0, 3.8))
# 5. 绘制带纹理的柱状图
bar_width = 0.45
for i in range(len(groups)):
ax.bar(x[i], means[i], width=bar_width, color=grays[i], edgecolor='black',
linewidth=0.8, hatch=hatches[i], zorder=2)
ax.errorbar(x, means, yerr=sems, fmt='none', ecolor='black', capsize=3, capthick=0.8, zorder=5)
# 6. 修正后的蜂群散点函数
defbeeswarm_positions(y_vals, center, width=0.18, resolution=0.02):
if len(y_vals) == 0:
return np.array([])
kde = gaussian_kde(y_vals)
y_range = np.linspace(min(y_vals), max(y_vals), 200)
density = kde(y_range)
density = density / density.max() * width
points = [] # 存储已放置的点 (x, y)
x_positions = [] # 仅存储 x 坐标用于返回
for y in y_vals:
idx = np.argmin(np.abs(y_range - y))
max_offset = density[idx]
# 统计已放置点中y坐标与当前y接近的数量
n_at_y = sum(1for (px, py) in points if abs(py - y) < resolution)
offset = (n_at_y % 2 * 2 - 1) * (n_at_y // 2 + 1) * resolution * 3
offset = np.clip(offset, -max_offset, max_offset)
x_pos = center + offset
points.append((x_pos, y))
x_positions.append(x_pos)
return np.array(x_positions)
# 叠加蜂群散点
for i, col in enumerate(raw_df.columns):
data = raw_df[col].dropna().values
x_pos = beeswarm_positions(data, x[i], width=0.16)
ax.scatter(x_pos, data, s=18, c='#2E75B6', alpha=0.6,
edgecolors='black', linewidths=0.3, zorder=15, label='_nolegend_')
# 7. 叠加箱线图元素(轻量级,避免过度遮挡)
box_width = bar_width * 0.5
for i, col in enumerate(raw_df.columns):
data = raw_df[col].dropna().values
median = np.median(data)
q1 = np.percentile(data, 25)
q3 = np.percentile(data, 75)
iqr = q3 - q1
lower = max(np.min(data), q1 - 1.5 * iqr)
upper = min(np.max(data), q3 + 1.5 * iqr)
# 箱体(白色半透明)
box = plt.Rectangle((x[i] - box_width/2, q1), box_width, iqr,
fill=True, facecolor='white', edgecolor='black', linewidth=0.7,
alpha=0.8, zorder=10)
ax.add_patch(box)
# 中位线
ax.plot([x[i] - box_width/2, x[i] + box_width/2], [median, median],
color='red', linewidth=1.2, zorder=12)
# 须线
ax.plot([x[i], x[i]], [q3, upper], color='black', linewidth=0.7, zorder=10)
ax.plot([x[i], x[i]], [q1, lower], color='black', linewidth=0.7, zorder=10)
ax.plot([x[i] - box_width/4, x[i] + box_width/4], [upper, upper], color='black', linewidth=0.7)
ax.plot([x[i] - box_width/4, x[i] + box_width/4], [lower, lower], color='black', linewidth=0.7)
# 8. 显著性标注(Bonferroni校正,智能防遮挡)
raw_dict = {col: raw_df[col].values for col in raw_df.columns}
pairs = list(combinations(range(len(groups)), 2))
p_vals = [ttest_ind(raw_dict[groups[i]], raw_dict[groups[j]], equal_var=False)[1] for (i,j) in pairs]
p_corr = [min(p * len(pairs), 1.0) for p in p_vals]
defsig_mark(p):
if p < 0.001: return'***'
elif p < 0.01: return'**'
elif p < 0.05: return'*'
else: return'ns'
sig_infos = [(i, j, sig_mark(p_corr[idx]), p_corr[idx]) for idx, (i,j) in enumerate(pairs) if sig_mark(p_corr[idx]) != 'ns']
sig_infos.sort(key=lambda t: t[3]) # p值小者优先(更显著)
# 计算柱顶高度
tops = [means[i] + sems[i] for i in range(len(groups))]
max_top = max(tops)
current_y = max_top * 1.25
step = max_top * 0.1
occupied = []
for (i, j, sig, p) in sig_infos:
x1, x2 = x[i], x[j]
while any(abs(current_y - y_used) < step*0.5and max(x1, ux1) <= min(x2, ux2) for (y_used, ux1, ux2) in occupied):
current_y += step * 0.5
ax.plot([x1, x2], [current_y, current_y], color='black', linewidth=0.8)
ax.text((x1+x2)/2, current_y + step*0.1, sig, ha='center', fontsize=10, fontweight='bold')
occupied.append((current_y, x1, x2))
current_y += step
# 9. 样本量标注
for i, col in enumerate(raw_df.columns):
n = raw_df[col].dropna().shape[0]
ax.text(x[i], -max_top*0.08, f'n={n}', ha='center', fontsize=8)
# 10. 坐标轴与保存
ax.set_xticks(x)
ax.set_xticklabels(groups)
ax.set_ylabel('测定值')
ax.set_ylim(-max_top*0.15, current_y*1.05)
plt.tight_layout()
plt.show()
# 11. 保存高清图片
fig.savefig('顶刊综合图表.pdf', bbox_inches='tight', pad_inches=0.05)
fig.savefig('顶刊综合图表.png', bbox_inches='tight', pad_inches=0.05)
print("综合图表生成完毕!包含以下元素:")
print("- 带纹理的柱状图(黑白印刷友好)")
print("- 误差棒(标准误)")
print("- 蜂群散点(展示个体数据分布)")
print("- 箱线图(五数概括)")
print("- 显著性星号(Bonferroni校正)")
print("- 样本量标注")
执行结果分析:本程序整合了前序所有高级功能,一键生成顶刊级别的柱状图;图表同时满足彩色显示和黑白印刷要求,包含丰富的统计信息;散点、箱线、显著性标注等元素自动排布,无需手动调整位置;

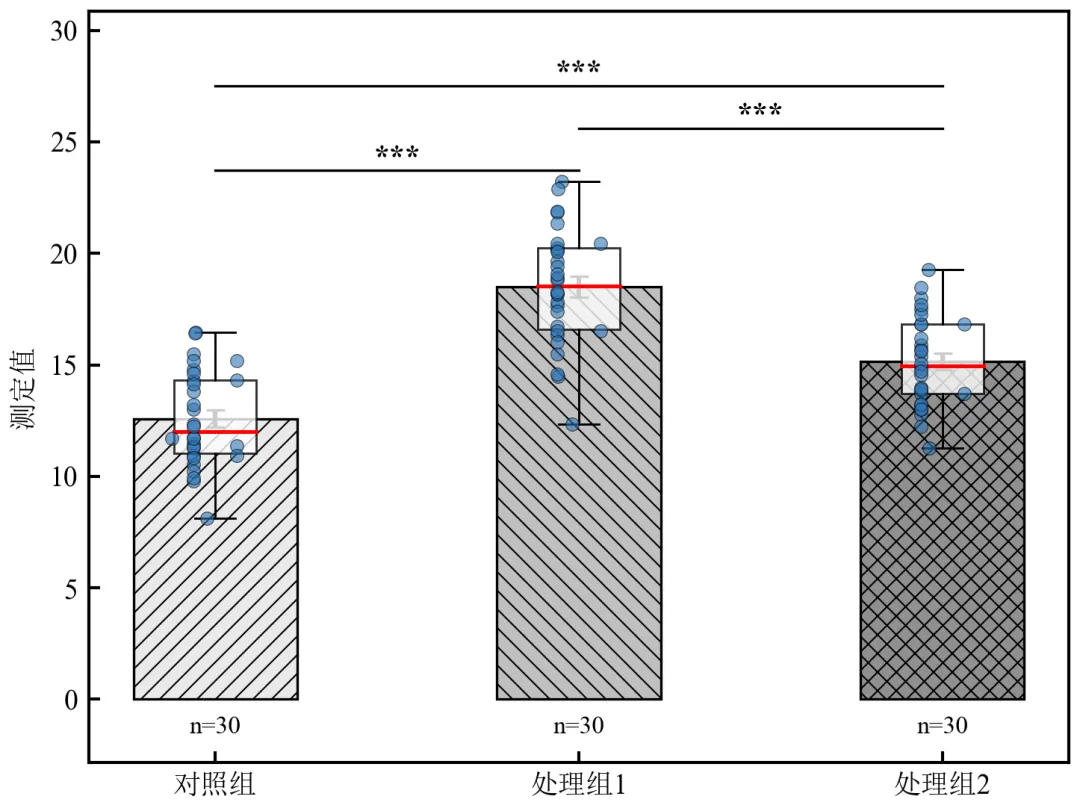
导出PDF为矢量格式,符合《Nature》《Science》《Cell》等期刊投稿规范;
若需调整元素顺序或透明度,可修改对应zorder和alpha参数。
- END -随机文章
-
 10个月宝宝每天需要喝多少奶粉?
10个月宝宝每天需要喝多少奶粉?
- Linux 网络栈核心三字经全解
- 笑不活了!Linux TCP/IP协议,竟是“电脑间的快递物流体系”
- Linux学习的乐趣
- 一文讲透:Linux / Android / Java 后端三大体系分层关系(系统层认知终极总结)
- Linux软件库截止2026年4月更新合集!
- 大佬发话!Linux内核正式立规矩:AI只是工具,不是代码贡献者,不得署名,代码得标注用的哪个模型
- PHP开发工具PhpStorm v2025.3.1.1下载与安装教程
- linux命令分类学习
- Ubuntu 26.04 为什么会让 Linux 玩家兴奋?不只是性能提升这么简单
- Linux Load 高但 CPU 低的排查思路
