《15节课Python绘图从入门到精通》4——双变量关系实操
- 2026-06-28 20:24:49
前置数据准备(沿用第3节数据并扩展一列第三维度)
为保证所有程序可直接运行,先运行以下代码生成包含第三维度的实验数据(无需单独保存,程序内已包含生成逻辑):
import pandas as pd
import numpy as np
np.random.seed(2024)
n = 50
# 模拟两列实验指标
x = np.random.normal(15, 3, n)
y = 2.5 * x + np.random.normal(0, 5, n) # 线性关系 + 噪声
# 第三维度:模拟药物剂量(连续值,用于颜色/大小映射)
dose = np.random.uniform(10, 100, n)
df = pd.DataFrame({'指标X': x, '指标Y': y, '剂量': dose})
df.to_csv('双变量数据.csv', index=False, encoding='utf-8-sig')
print("数据生成完成:双变量数据.csv(含指标X、指标Y、剂量三列)")
执行结果如下:
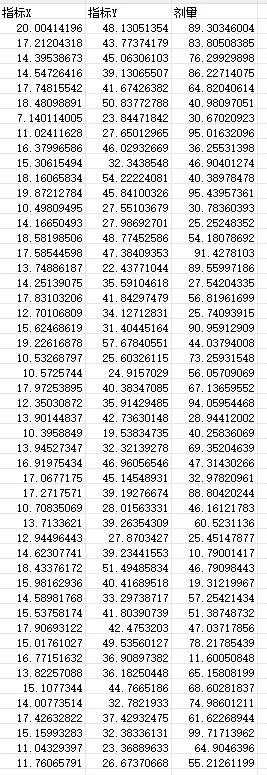
实操任务1:读取两列实验数据,绘制散点图,映射第三维度数据为散点颜色/大小
本任务从最基础的散点图绘制入手,逐步实现将第三维度(如基因表达量、药物剂量、样本年龄)映射为点的颜色或大小,符合顶刊多维数据展示规范。
基础版:双变量基础散点图(新手入门)
程序可读取两列数据,绘制符合学术规范的散点图,适用于初学者入门。
import pandas as pd
import matplotlib.pyplot as plt
# 1. 学术样式(支持中文)
defset_academic_style():
plt.rcParams['font.family'] = ['Times New Roman', 'SimSun']
plt.rcParams['font.size'] = 9
plt.rcParams['axes.unicode_minus'] = False
plt.rcParams['axes.linewidth'] = 1.0
plt.rcParams['xtick.major.width'] = 1.0
plt.rcParams['ytick.major.width'] = 1.0
plt.rcParams['xtick.major.size'] = 3.5
plt.rcParams['ytick.major.size'] = 3.5
plt.rcParams['xtick.direction'] = 'in'
plt.rcParams['ytick.direction'] = 'in'
plt.rcParams['legend.frameon'] = False
plt.rcParams['pdf.fonttype'] = 42
plt.rcParams['savefig.dpi'] = 300
set_academic_style()
# 2. 读取数据(若文件不存在,请先运行程序20生成)
df = pd.read_csv('双变量数据.csv')
x = df['指标X']
y = df['指标Y']
# 3. 绘制散点图
fig, ax = plt.subplots(figsize=(3.5, 3.0))
ax.scatter(x, y, s=20, c='#4472C4', alpha=0.7, edgecolors='black', linewidths=0.3)
# 4. 坐标轴标签与范围
ax.set_xlabel('指标 X', fontsize=9)
ax.set_ylabel('指标 Y', fontsize=9)
ax.set_xlim(min(x)*0.9, max(x)*1.1)
ax.set_ylim(min(y)*0.9, max(y)*1.1)
plt.tight_layout()
plt.show()
fig.savefig('基础散点图.pdf', bbox_inches='tight', pad_inches=0.05)
fig.savefig('基础散点图.png', bbox_inches='tight', pad_inches=0.05)
执行结果分析:
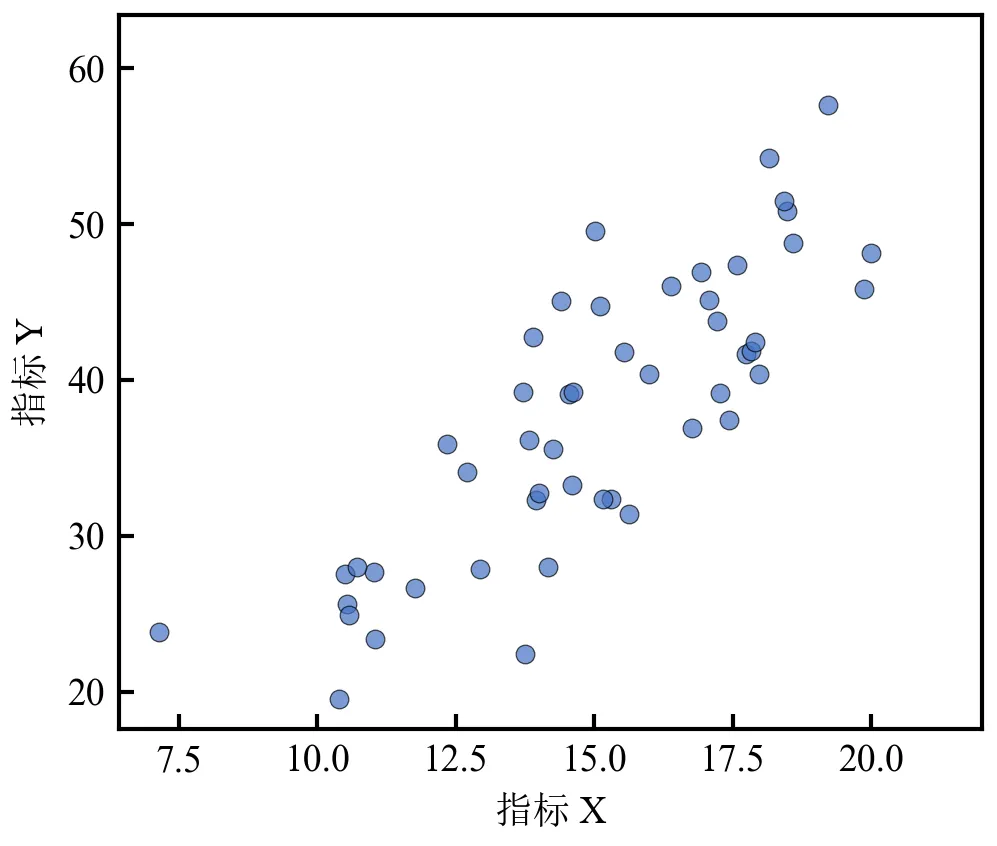
弹出符合学术规范的散点图,点边缘黑色、内部蓝色,半透明避免重叠遮挡;坐标轴刻度向内,标签清晰,整体尺寸适配期刊单栏排版;可调整s参数改变点的大小,alpha调节透明度。
进阶1:第三维度映射为散点颜色(连续色阶+颜色条)
该程序将第三维度(如剂量)映射为散点颜色,并添加颜色条图例,展示多维信息,适用于数据存在第三维度的场景。
import pandas as pd
import matplotlib.pyplot as plt
import numpy as np
defset_academic_style():
plt.rcParams['font.family'] = ['Times New Roman', 'SimSun']
plt.rcParams['font.size'] = 9
plt.rcParams['axes.unicode_minus'] = False
plt.rcParams['axes.linewidth'] = 1.0
plt.rcParams['xtick.major.width'] = 1.0
plt.rcParams['ytick.major.width'] = 1.0
plt.rcParams['xtick.major.size'] = 3.5
plt.rcParams['ytick.major.size'] = 3.5
plt.rcParams['xtick.direction'] = 'in'
plt.rcParams['ytick.direction'] = 'in'
plt.rcParams['legend.frameon'] = False
plt.rcParams['pdf.fonttype'] = 42
plt.rcParams['savefig.dpi'] = 300
set_academic_style()
df = pd.read_csv('双变量数据.csv')
x = df['指标X']
y = df['指标Y']
c = df['剂量'] # 第三维度,用于颜色映射
# 绘制散点图,c参数指定颜色映射值,cmap选择学术常用渐变色
fig, ax = plt.subplots(figsize=(3.8, 3.0))
sc = ax.scatter(x, y, s=25, c=c, cmap='viridis', alpha=0.8,
edgecolors='black', linewidths=0.3)
# 添加颜色条(colorbar),标签为第三维度含义
cbar = plt.colorbar(sc, ax=ax)
cbar.set_label('剂量 (mg/kg)', fontsize=8)
cbar.ax.tick_params(labelsize=7)
ax.set_xlabel('指标 X')
ax.set_ylabel('指标 Y')
ax.set_xlim(min(x)*0.9, max(x)*1.1)
ax.set_ylim(min(y)*0.9, max(y)*1.1)
plt.tight_layout()
plt.show()
fig.savefig('颜色映射散点图.pdf', bbox_inches='tight', pad_inches=0.05)
fig.savefig('颜色映射散点图.png', bbox_inches='tight', pad_inches=0.05)
执行结果分析:
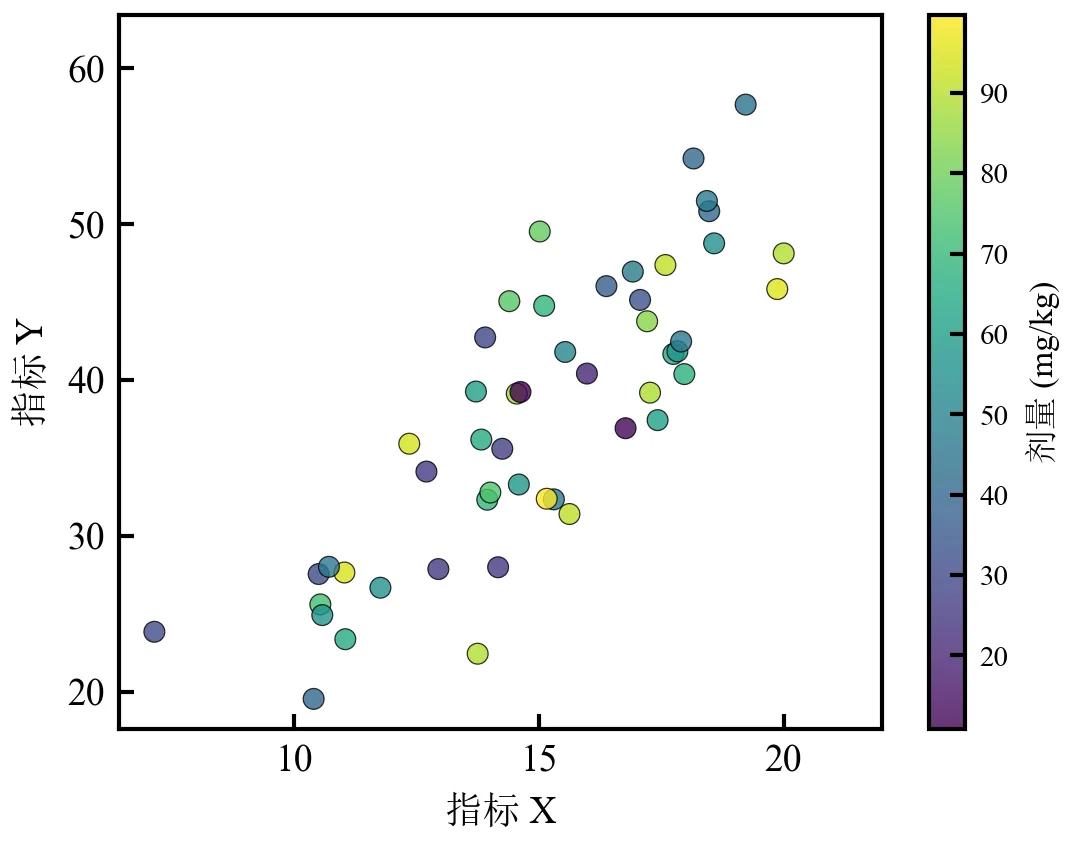
散点颜色随剂量值变化(viridis为色盲友好渐变色,顶刊常用);颜色条清晰标注第三维度含义,便于读者解读;可替换cmap参数为其他渐变色(如'plasma', 'inferno', 'cividis');若数据存在极端值,可通过vmin/vmax参数固定颜色映射范围。
进阶2:第三维度同时映射颜色和大小(气泡图风格)
该程序将第三维度(如剂量)同时映射为散点颜色和大小,强化第三维度视觉权重,适用于数据存在第三维度的场景。
import pandas as pd
import matplotlib.pyplot as plt
import numpy as np
defset_academic_style():
plt.rcParams['font.family'] = ['Times New Roman', 'SimSun']
plt.rcParams['font.size'] = 9
plt.rcParams['axes.unicode_minus'] = False
plt.rcParams['axes.linewidth'] = 1.0
plt.rcParams['xtick.major.width'] = 1.0
plt.rcParams['ytick.major.width'] = 1.0
plt.rcParams['xtick.major.size'] = 3.5
plt.rcParams['ytick.major.size'] = 3.5
plt.rcParams['xtick.direction'] = 'in'
plt.rcParams['ytick.direction'] = 'in'
plt.rcParams['legend.frameon'] = False
plt.rcParams['pdf.fonttype'] = 42
plt.rcParams['savefig.dpi'] = 300
set_academic_style()
df = pd.read_csv('双变量数据.csv')
x = df['指标X']
y = df['指标Y']
c = df['剂量'] # 颜色映射
size = df['剂量'] # 大小映射(可单独设定另一变量)
# 将剂量线性映射到点大小范围(15~100)
size_norm = 15 + (size - size.min()) / (size.max() - size.min()) * 85
fig, ax = plt.subplots(figsize=(4.0, 3.2))
sc = ax.scatter(x, y, s=size_norm, c=c, cmap='plasma', alpha=0.7,
edgecolors='black', linewidths=0.3)
# 颜色条
cbar = plt.colorbar(sc, ax=ax)
cbar.set_label('剂量 (mg/kg)', fontsize=8)
# 手动创建大小图例(展示三个典型剂量值对应的点大小)
dose_vals = [20, 50, 80]
size_legend = [15 + (v - size.min()) / (size.max() - size.min()) * 85for v in dose_vals]
legend_handles = []
for v, s_val in zip(dose_vals, size_legend):
handle = ax.scatter([], [], s=s_val, c='gray', alpha=0.7,
edgecolors='black', linewidths=0.3, label=f'{v:.0f}')
legend_handles.append(handle)
ax.legend(handles=legend_handles, title='剂量', loc='upper left', fontsize=7,
title_fontsize=8, frameon=False)
ax.set_xlabel('指标 X')
ax.set_ylabel('指标 Y')
ax.set_xlim(min(x)*0.9, max(x)*1.1)
ax.set_ylim(min(y)*0.9, max(y)*1.1)
plt.tight_layout()
plt.show()
fig.savefig('颜色大小双映射散点图.pdf', bbox_inches='tight', pad_inches=0.05)
fig.savefig('颜色大小双映射散点图.png', bbox_inches='tight', pad_inches=0.05)
执行结果分析:
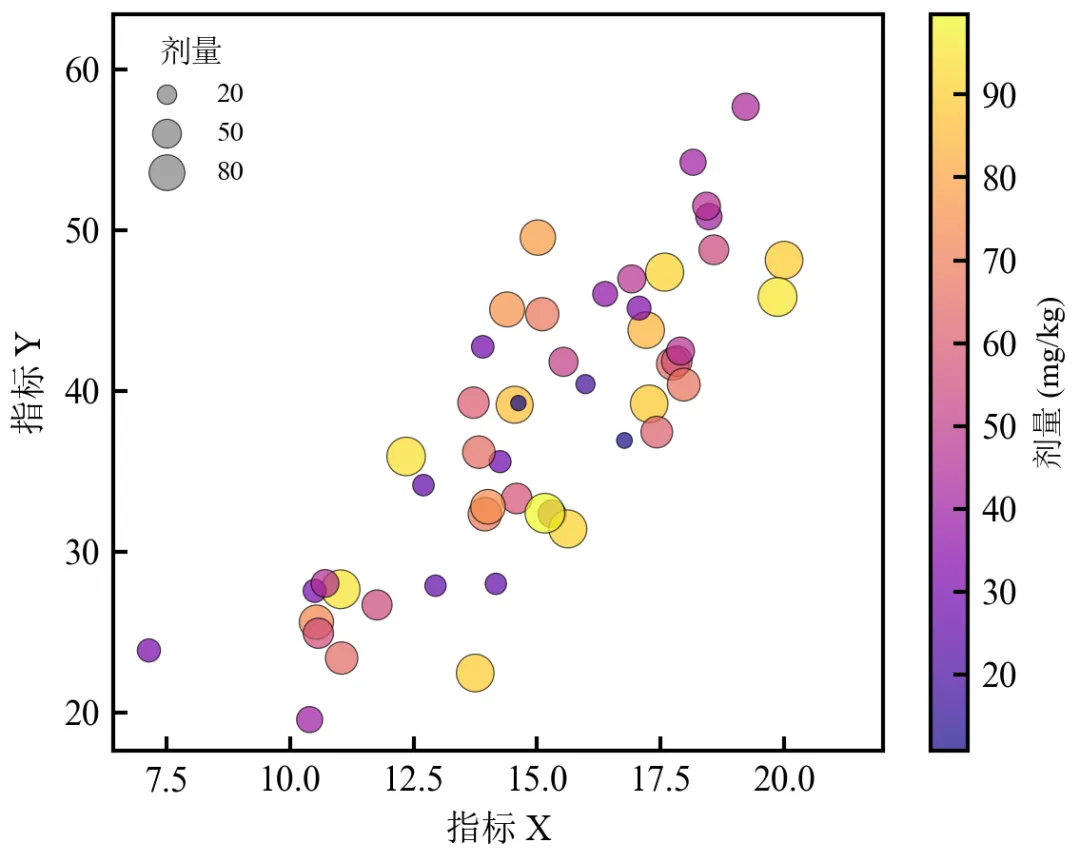
颜色和大小同步反映剂量,高剂量点颜色更亮、尺寸更大,视觉冲击强;大小图例通过人工构造三个剂量档位展示映射关系,清晰易懂;若颜色与大小映射不同变量,只需将size参数替换为另一列数据即可;点大小范围(15~100)可根据画布尺寸和点密度灵活调整。
进阶3:离散分组映射颜色 + 自动图例
该程序将第三维度(如处理组)映射为离散颜色,并自动生成图例,适用于数据存在第三维度的场景。
import pandas as pd
import matplotlib.pyplot as plt
import numpy as np
defset_academic_style():
plt.rcParams['font.family'] = ['Times New Roman', 'SimSun']
plt.rcParams['font.size'] = 9
plt.rcParams['axes.unicode_minus'] = False
plt.rcParams['axes.linewidth'] = 1.0
plt.rcParams['xtick.major.width'] = 1.0
plt.rcParams['ytick.major.width'] = 1.0
plt.rcParams['xtick.major.size'] = 3.5
plt.rcParams['ytick.major.size'] = 3.5
plt.rcParams['xtick.direction'] = 'in'
plt.rcParams['ytick.direction'] = 'in'
plt.rcParams['legend.frameon'] = False
plt.rcParams['pdf.fonttype'] = 42
plt.rcParams['savefig.dpi'] = 300
set_academic_style()
# 读取数据,并模拟一个分组变量(例如根据剂量高低分为三组)
df = pd.read_csv('双变量数据.csv')
# 按剂量百分位数分为三组:低、中、高剂量组
df['剂量组'] = pd.cut(df['剂量'], bins=3, labels=['低剂量', '中剂量', '高剂量'])
# 为每个分组分配固定颜色(色盲友好配色)
color_dict = {'低剂量': '#2E75B6', '中剂量': '#70AD47', '高剂量': '#ED7D31'}
fig, ax = plt.subplots(figsize=(3.8, 3.0))
# 分组绘制散点,便于生成图例
for group in df['剂量组'].unique():
subset = df[df['剂量组'] == group]
ax.scatter(subset['指标X'], subset['指标Y'], s=25,
c=color_dict[group], alpha=0.7, edgecolors='black',
linewidths=0.3, label=group)
ax.set_xlabel('指标 X')
ax.set_ylabel('指标 Y')
ax.legend(loc='upper left', fontsize=8, frameon=False)
ax.set_xlim(df['指标X'].min()*0.9, df['指标X'].max()*1.1)
ax.set_ylim(df['指标Y'].min()*0.9, df['指标Y'].max()*1.1)
plt.tight_layout()
plt.show()
fig.savefig('离散分组颜色散点图.pdf', bbox_inches='tight', pad_inches=0.05)
fig.savefig('离散分组颜色散点图.png', bbox_inches='tight', pad_inches=0.05)
执行结果分析:
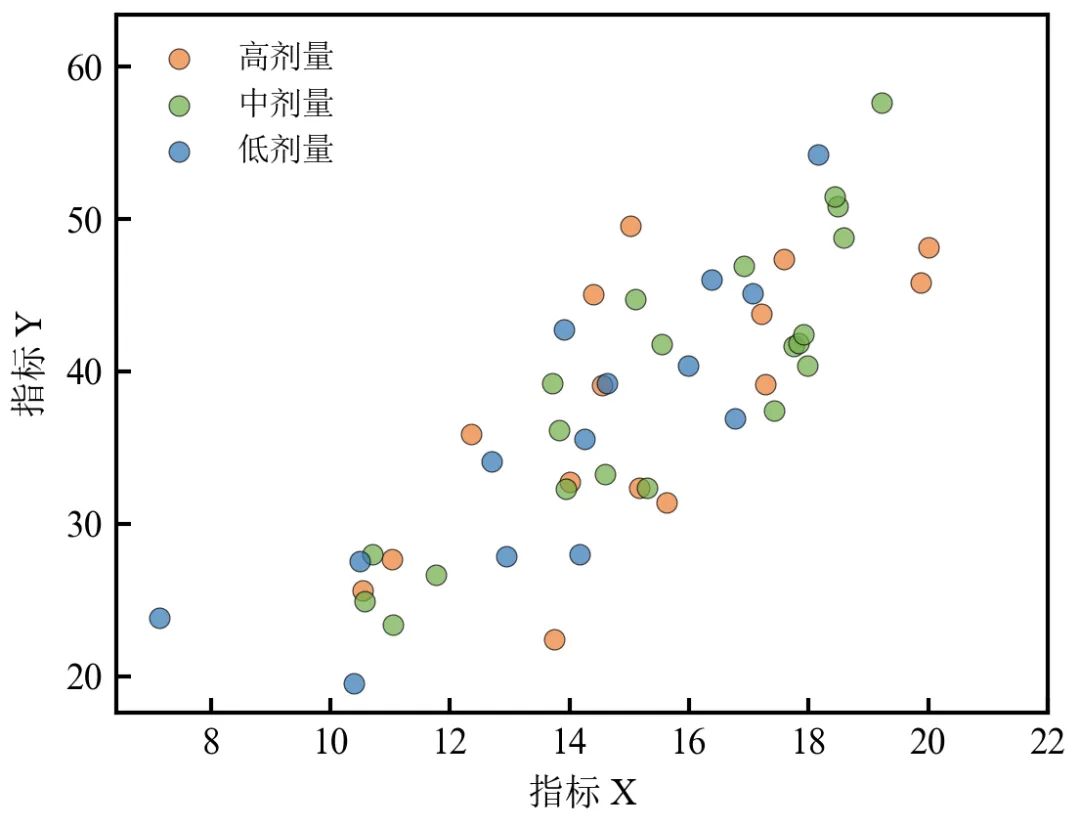
将连续剂量离散化为三组,便于进行分组对比;图例自动生成,颜色鲜明且互不干扰;实际应用中可直接使用已有的分类列(如'处理组')替代pd.cut步骤;分组颜色建议使用ColorBrewer或Tableau色系,符合学术审美。
进阶4:三维投影散点图(边缘分布+颜色映射组合)
该程序在主散点图基础上,于上方和右侧添加变量的边缘直方图,展示单变量分布,适用于数据存在第三维度的场景。
import pandas as pd
import matplotlib.pyplot as plt
import numpy as np
from matplotlib.gridspec import GridSpec
defset_academic_style():
plt.rcParams['font.family'] = ['Times New Roman', 'SimSun']
plt.rcParams['font.size'] = 9
plt.rcParams['axes.unicode_minus'] = False
plt.rcParams['axes.linewidth'] = 1.0
plt.rcParams['xtick.major.width'] = 1.0
plt.rcParams['ytick.major.width'] = 1.0
plt.rcParams['xtick.major.size'] = 3.5
plt.rcParams['ytick.major.size'] = 3.5
plt.rcParams['xtick.direction'] = 'in'
plt.rcParams['ytick.direction'] = 'in'
plt.rcParams['legend.frameon'] = False
plt.rcParams['pdf.fonttype'] = 42
plt.rcParams['savefig.dpi'] = 300
set_academic_style()
df = pd.read_csv('双变量数据.csv')
x = df['指标X']
y = df['指标Y']
c = df['剂量']
# 创建网格布局:主图2x2,上方和右侧为直方图
fig = plt.figure(figsize=(4.5, 4.0))
gs = GridSpec(2, 2, width_ratios=[4, 1], height_ratios=[1, 4],
hspace=0.05, wspace=0.05)
ax_main = fig.add_subplot(gs[1, 0]) # 主散点图
ax_top = fig.add_subplot(gs[0, 0], sharex=ax_main) # 上方直方图
ax_right = fig.add_subplot(gs[1, 1], sharey=ax_main) # 右侧直方图
# 主散点图(颜色映射剂量)
sc = ax_main.scatter(x, y, s=20, c=c, cmap='viridis', alpha=0.8,
edgecolors='black', linewidths=0.3)
ax_main.set_xlabel('指标 X')
ax_main.set_ylabel('指标 Y')
# 上方直方图(X的分布)
ax_top.hist(x, bins=15, color='#C0C0C0', edgecolor='black', linewidth=0.5)
ax_top.set_ylabel('频数')
ax_top.tick_params(labelbottom=False)
# 右侧直方图(Y的分布,旋转方向)
ax_right.hist(y, bins=15, orientation='horizontal', color='#C0C0C0',
edgecolor='black', linewidth=0.5)
ax_right.set_xlabel('频数')
ax_right.tick_params(labelleft=False)
# 颜色条放置在主图右侧空隙
cbar_ax = fig.add_axes([0.88, 0.15, 0.02, 0.6]) # [左,下,宽,高]
cbar = fig.colorbar(sc, cax=cbar_ax)
cbar.set_label('剂量', fontsize=8)
plt.tight_layout(rect=[0, 0, 0.87, 1]) # 为颜色条留出空间
plt.show()
fig.savefig('三维投影散点图.pdf', bbox_inches='tight', pad_inches=0.05)
fig.savefig('三维投影散点图.png', bbox_inches='tight', pad_inches=0.05)
执行结果分析:
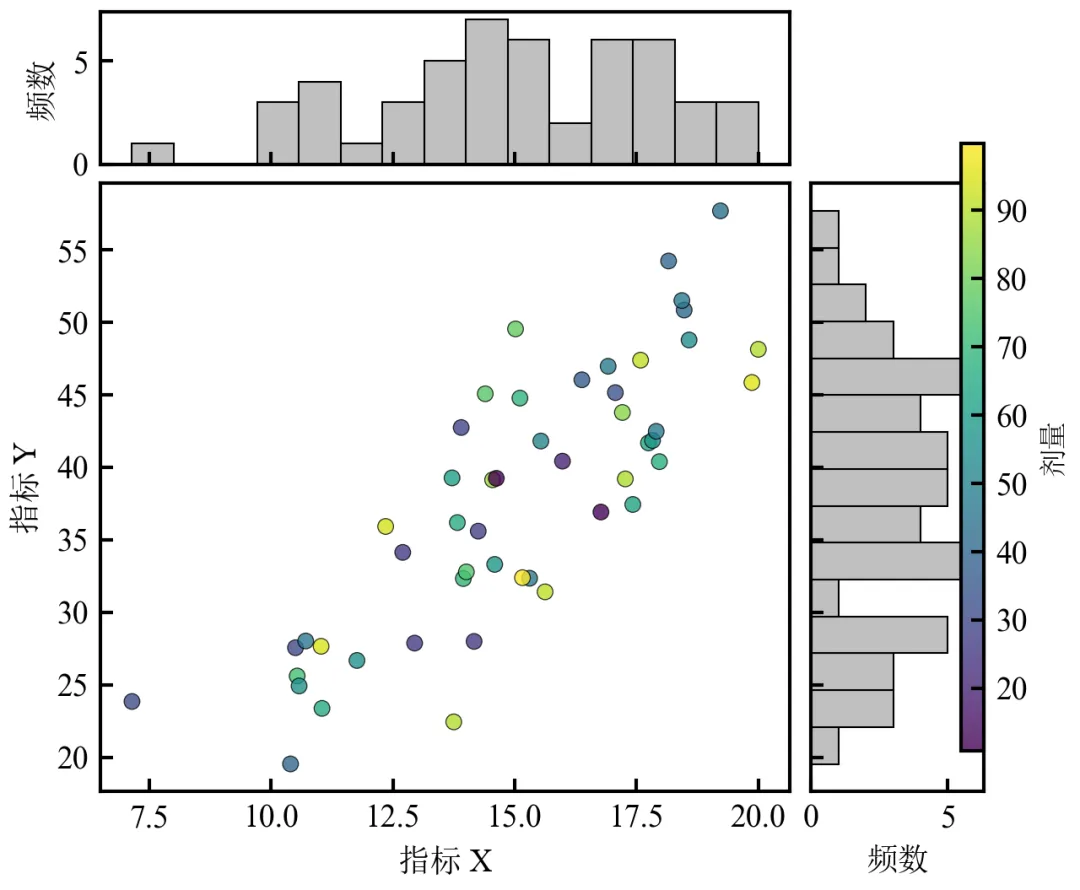
主散点图展示X-Y关系及剂量颜色映射,边缘直方图展示单变量分布;使用GridSpec灵活控制子图比例,实现出版级排版;颜色条通过add_axes精确定位,避免与直方图重叠;本图可同时呈现双变量关系、第三维度影响及单变量分布,信息密度极高。
实操任务2:用NumPy计算最小二乘回归线,绘制回归线并标注回归方程、值
基础版:简单线性回归与方程标注
该程序计算最小二乘回归参数,绘制回归线,并在图上标注方程和值。
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
# 1. 学术样式
defset_academic_style():
plt.rcParams['font.family'] = ['Times New Roman', 'SimSun']
plt.rcParams['font.size'] = 9
plt.rcParams['axes.unicode_minus'] = False
plt.rcParams['axes.linewidth'] = 1.0
plt.rcParams['xtick.major.width'] = 1.0
plt.rcParams['ytick.major.width'] = 1.0
plt.rcParams['xtick.major.size'] = 3.5
plt.rcParams['ytick.major.size'] = 3.5
plt.rcParams['xtick.direction'] = 'in'
plt.rcParams['ytick.direction'] = 'in'
plt.rcParams['legend.frameon'] = False
plt.rcParams['pdf.fonttype'] = 42
plt.rcParams['savefig.dpi'] = 300
set_academic_style()
# 2. 读取数据
df = pd.read_csv('双变量数据.csv')
x = df['指标X'].values
y = df['指标Y'].values
# 3. 使用NumPy计算最小二乘回归系数 (y = a * x + b)
# 公式:a = Cov(x,y) / Var(x);b = mean(y) - a * mean(x)
x_mean = np.mean(x)
y_mean = np.mean(y)
a = np.sum((x - x_mean) * (y - y_mean)) / np.sum((x - x_mean) ** 2)
b = y_mean - a * x_mean
# 4. 计算R² (决定系数)
y_pred = a * x + b
ss_res = np.sum((y - y_pred) ** 2) # 残差平方和
ss_tot = np.sum((y - y_mean) ** 2) # 总平方和
r2 = 1 - (ss_res / ss_tot)
# 5. 生成回归线的x坐标(覆盖数据范围)
x_line = np.linspace(x.min(), x.max(), 100)
y_line = a * x_line + b
# 6. 绘图
fig, ax = plt.subplots(figsize=(3.8, 3.0))
# 散点
ax.scatter(x, y, s=20, c='#4472C4', alpha=0.7, edgecolors='black', linewidths=0.3, zorder=5)
# 回归线
ax.plot(x_line, y_line, color='#C00000', linewidth=1.5, zorder=10, label='回归线')
# 7. 标注方程和R²
equation_text = f'y = {a:.3f}x {"+"if b >= 0else"-"}{abs(b):.3f}'# 格式化方程
r2_text = f'$R^2$ = {r2:.3f}'
# 将文本放置在左上角(相对于数据坐标)
ax.text(0.05, 0.95, equation_text + '\n' + r2_text,
transform=ax.transAxes, fontsize=9, verticalalignment='top',
bbox=dict(boxstyle='round', facecolor='white', alpha=0.8, edgecolor='none'))
ax.set_xlabel('指标 X')
ax.set_ylabel('指标 Y')
ax.set_xlim(x.min()*0.95, x.max()*1.05)
ax.set_ylim(y.min()*0.95, y.max()*1.05)
plt.tight_layout()
plt.show()
fig.savefig('线性回归标注图.pdf', bbox_inches='tight', pad_inches=0.05)
fig.savefig('线性回归标注图.png', bbox_inches='tight', pad_inches=0.05)
执行结果分析:
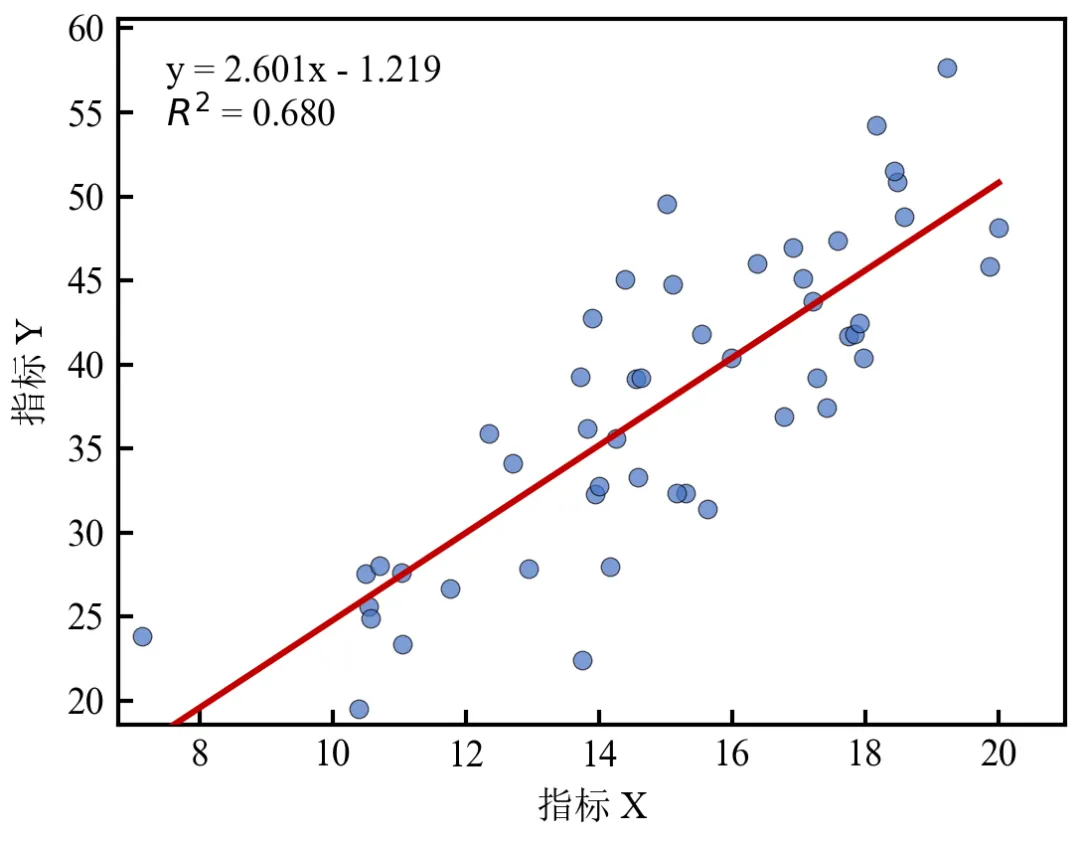
使用NumPy手动计算回归系数和R²,无需依赖scipy.stats;回归线为红色实线,散点在上层,方程标注带半透明白底,清晰不遮挡;可通过调整ax.text的坐标位置改变标注位置;若数据非线性,建议先对数据进行变换或使用非线性拟合。
进阶1:添加回归线的置信区间带
该程序计算最小二乘回归参数,绘制回归线,并在图上标注方程和值,同时添加回归线的置信区间带。
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
from scipy import stats
defset_academic_style():
plt.rcParams['font.family'] = ['Times New Roman', 'SimSun']
plt.rcParams['font.size'] = 9
plt.rcParams['axes.unicode_minus'] = False
plt.rcParams['axes.linewidth'] = 1.0
plt.rcParams['xtick.major.width'] = 1.0
plt.rcParams['ytick.major.width'] = 1.0
plt.rcParams['xtick.major.size'] = 3.5
plt.rcParams['ytick.major.size'] = 3.5
plt.rcParams['xtick.direction'] = 'in'
plt.rcParams['ytick.direction'] = 'in'
plt.rcParams['legend.frameon'] = False
plt.rcParams['pdf.fonttype'] = 42
plt.rcParams['savefig.dpi'] = 300
set_academic_style()
df = pd.read_csv('双变量数据.csv')
x = df['指标X'].values
y = df['指标Y'].values
# 使用scipy进行线性回归
slope, intercept, r_value, p_value, std_err = stats.linregress(x, y)
# 计算必要的统计量
n = len(x)
x_mean = np.mean(x)
Sxx = np.sum((x - x_mean)**2)
# 计算MSE(均方误差)
y_pred = slope * x + intercept
residuals = y - y_pred
MSE = np.sum(residuals**2) / (n - 2)
# 生成用于绘图的x序列
x_line = np.linspace(x.min(), x.max(), 100)
y_line = slope * x_line + intercept
# 计算置信区间(95%)
se_fit = np.sqrt(MSE * (1/n + (x_line - x_mean)**2 / Sxx))
t_val = stats.t.ppf(0.975, n - 2)
ci_lower = y_line - t_val * se_fit
ci_upper = y_line + t_val * se_fit
# 绘图
fig, ax = plt.subplots(figsize=(4.0, 3.2))
ax.scatter(x, y, s=20, c='#4472C4', alpha=0.7, edgecolors='black', linewidths=0.3, zorder=5)
# 置信带(半透明填充)
ax.fill_between(x_line, ci_lower, ci_upper, color='#C00000', alpha=0.2, label='95% 置信区间', zorder=3)
# 回归线
ax.plot(x_line, y_line, color='#C00000', linewidth=1.5, zorder=10, label='回归线')
# 标注方程和R²
equation_text = f'y = {slope:.3f}x {"+"if intercept >= 0else"-"}{abs(intercept):.3f}'
r2_text = f'$R^2$ = {r_value**2:.3f}'
ax.text(0.05, 0.95, equation_text + '\n' + r2_text,
transform=ax.transAxes, fontsize=9, verticalalignment='top',
bbox=dict(boxstyle='round', facecolor='white', alpha=0.8, edgecolor='none'))
ax.set_xlabel('指标 X')
ax.set_ylabel('指标 Y')
ax.set_xlim(x.min()*0.95, x.max()*1.05)
ax.set_ylim(y.min()*0.95, y.max()*1.05)
ax.legend(loc='lower right', fontsize=8)
plt.tight_layout()
plt.show()
fig.savefig('回归线置信区间图.pdf', bbox_inches='tight', pad_inches=0.05)
fig.savefig('回归线置信区间图.png', bbox_inches='tight', pad_inches=0.05)
执行结果分析:
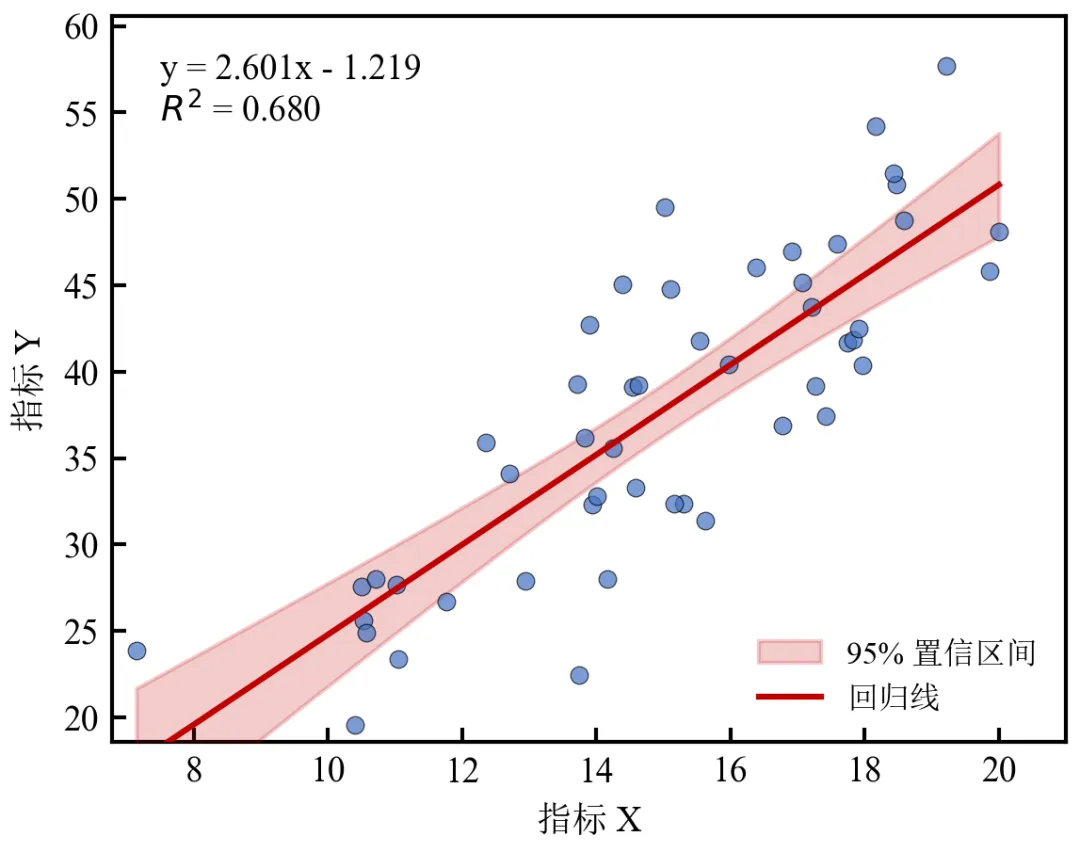
置信区间带在x均值处最窄,两端逐渐变宽,体现预测的不确定性;使用scipy.stats.linregress简化回归计算,直接获取标准误等参数;填充区域颜色与回归线同色系,透明度0.2,不遮挡散点;可调整置信水平(如改为0.99),对应修改t_val的ppf参数。
进阶2:分组回归线(按第三维度分类绘制多条回归线)
该程序根据第三维度(如剂量组)将数据分组,每组单独拟合回归线并对比。适用于数据存在多个类别,需要分别分析的情况。
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
from scipy import stats
defset_academic_style():
plt.rcParams['font.family'] = ['Times New Roman', 'SimSun']
plt.rcParams['font.size'] = 9
plt.rcParams['axes.unicode_minus'] = False
plt.rcParams['axes.linewidth'] = 1.0
plt.rcParams['xtick.major.width'] = 1.0
plt.rcParams['ytick.major.width'] = 1.0
plt.rcParams['xtick.major.size'] = 3.5
plt.rcParams['ytick.major.size'] = 3.5
plt.rcParams['xtick.direction'] = 'in'
plt.rcParams['ytick.direction'] = 'in'
plt.rcParams['legend.frameon'] = False
plt.rcParams['pdf.fonttype'] = 42
plt.rcParams['savefig.dpi'] = 300
set_academic_style()
df = pd.read_csv('双变量数据.csv')
# 创建分组变量(按剂量分为三组)
df['剂量组'] = pd.cut(df['剂量'], bins=3, labels=['低剂量', '中剂量', '高剂量'])
groups = df['剂量组'].unique()
color_dict = {'低剂量': '#2E75B6', '中剂量': '#70AD47', '高剂量': '#ED7D31'}
fig, ax = plt.subplots(figsize=(4.2, 3.4))
# 分组绘制散点和回归线
for group in groups:
subset = df[df['剂量组'] == group]
x = subset['指标X'].values
y = subset['指标Y'].values
# 散点
ax.scatter(x, y, s=20, c=color_dict[group], alpha=0.6,
edgecolors='black', linewidths=0.3, label=group, zorder=5)
# 回归拟合
if len(x) > 1:
slope, intercept, r, p, se = stats.linregress(x, y)
x_line = np.linspace(x.min(), x.max(), 50)
y_line = slope * x_line + intercept
ax.plot(x_line, y_line, color=color_dict[group], linewidth=2.0, zorder=10)
# 在线上标注R²(放在每组线条末端附近)
ax.annotate(f'$R^2$={r**2:.2f}', xy=(x_line[-1], y_line[-1]),
xytext=(5, 0), textcoords='offset points',
fontsize=7, color=color_dict[group], ha='left', va='center')
ax.set_xlabel('指标 X')
ax.set_ylabel('指标 Y')
ax.legend(loc='upper left', fontsize=8, frameon=False)
ax.set_xlim(df['指标X'].min()*0.95, df['指标X'].max()*1.05)
ax.set_ylim(df['指标Y'].min()*0.95, df['指标Y'].max()*1.05)
plt.tight_layout()
plt.show()
fig.savefig('分组回归线对比图.pdf', bbox_inches='tight', pad_inches=0.05)
fig.savefig('分组回归线对比图.png', bbox_inches='tight', pad_inches=0.05)
执行结果分析:
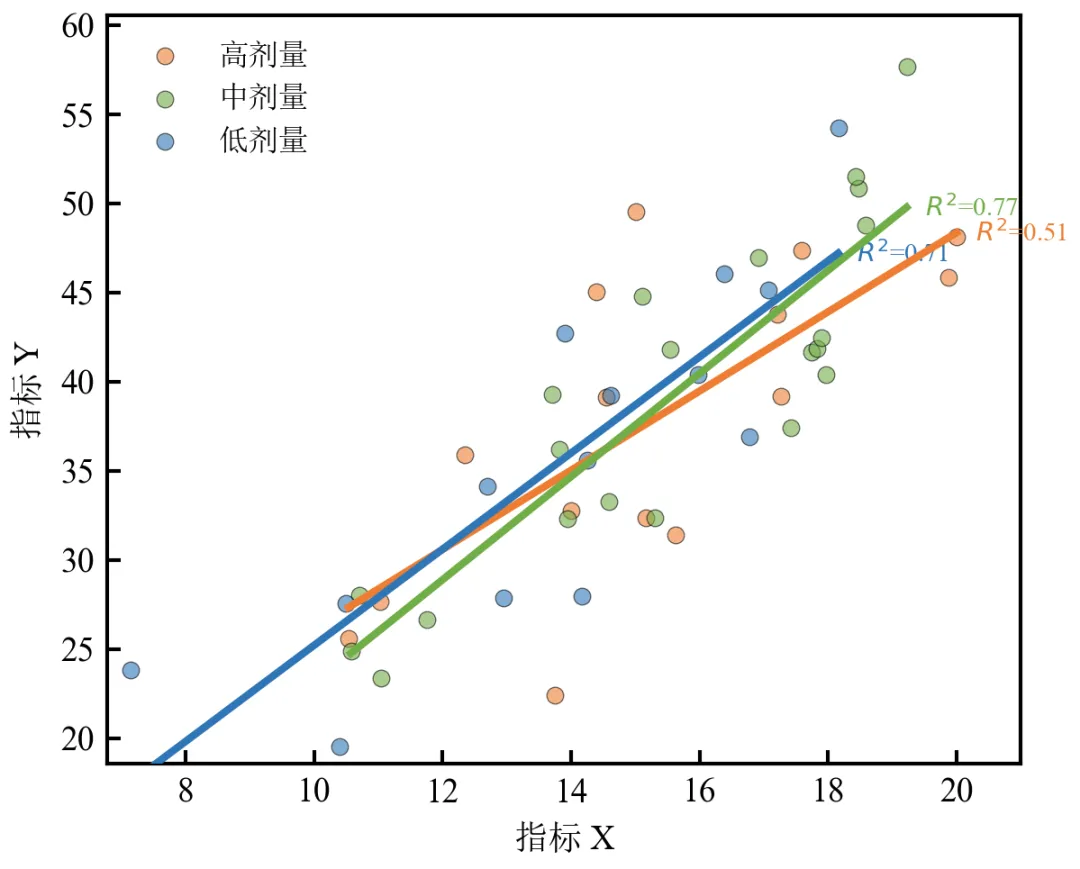
不同剂量组的回归线用不同颜色区分,散点颜色与回归线一致;每条回归线末端标注该组的值,便于快速比较拟合优度;若各组样本量差异大,可考虑加权回归或稳健回归;实际应用中分组变量可以是处理组、基因型等分类数据。
进阶3:稳健回归(Huber回归)与最小二乘对比
该程序对比最小二乘回归和稳健回归(对异常值不敏感)的差异,适用于数据存在异常值,需要稳健估计的情况。
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
from sklearn.linear_model import HuberRegressor, LinearRegression
defset_academic_style():
plt.rcParams['font.family'] = ['Times New Roman', 'SimSun']
plt.rcParams['font.size'] = 9
plt.rcParams['axes.unicode_minus'] = False
plt.rcParams['axes.linewidth'] = 1.0
plt.rcParams['xtick.major.width'] = 1.0
plt.rcParams['ytick.major.width'] = 1.0
plt.rcParams['xtick.major.size'] = 3.5
plt.rcParams['ytick.major.size'] = 3.5
plt.rcParams['xtick.direction'] = 'in'
plt.rcParams['ytick.direction'] = 'in'
plt.rcParams['legend.frameon'] = False
plt.rcParams['pdf.fonttype'] = 42
plt.rcParams['savefig.dpi'] = 300
set_academic_style()
df = pd.read_csv('双变量数据.csv')
# 人为添加两个异常点,用于展示稳健回归的优势
x = df['指标X'].values
y = df['指标Y'].values
# 添加异常点:x在正常范围,y偏离回归线较远
x_out = np.append(x, [12, 20])
y_out = np.append(y, [50, 5])
x = x_out.reshape(-1, 1)
y = y_out
# 最小二乘回归 (OLS)
ols = LinearRegression()
ols.fit(x, y)
y_pred_ols = ols.predict(x)
# Huber稳健回归
huber = HuberRegressor()
huber.fit(x, y)
y_pred_huber = huber.predict(x)
# 绘图
fig, ax = plt.subplots(figsize=(4.5, 3.4))
# 所有散点(正常点+异常点)
ax.scatter(x, y, s=20, c='#888888', alpha=0.6, edgecolors='black', linewidths=0.3, zorder=5, label='数据点')
# 标记异常点(最后两个)
ax.scatter(x[-2:], y[-2:], s=40, c='red', marker='x', edgecolors='red', linewidths=1.5,
zorder=6, label='异常点')
# 绘制回归线
x_line = np.linspace(x.min(), x.max(), 100).reshape(-1, 1)
ax.plot(x_line, ols.predict(x_line), color='#4472C4', linewidth=1.8,
linestyle='--', label='最小二乘 (OLS)', zorder=10)
ax.plot(x_line, huber.predict(x_line), color='#C00000', linewidth=1.8,
label='Huber稳健回归', zorder=10)
# 标注方程
ols_eq = f'OLS: y = {ols.coef_[0]:.2f}x + {ols.intercept_:.2f}'
huber_eq = f'Huber: y = {huber.coef_[0]:.2f}x + {huber.intercept_:.2f}'
ax.text(0.05, 0.95, ols_eq + '\n' + huber_eq, transform=ax.transAxes,
fontsize=8, verticalalignment='top',
bbox=dict(boxstyle='round', facecolor='white', alpha=0.8))
ax.set_xlabel('指标 X')
ax.set_ylabel('指标 Y')
ax.legend(loc='lower right', fontsize=8, frameon=False)
ax.set_xlim(x.min()*0.95, x.max()*1.05)
ax.set_ylim(y.min()*0.95, y.max()*1.05)
plt.tight_layout()
plt.show()
fig.savefig('稳健回归对比图.pdf', bbox_inches='tight', pad_inches=0.05)
fig.savefig('稳健回归对比图.png', bbox_inches='tight', pad_inches=0.05)
执行结果分析:
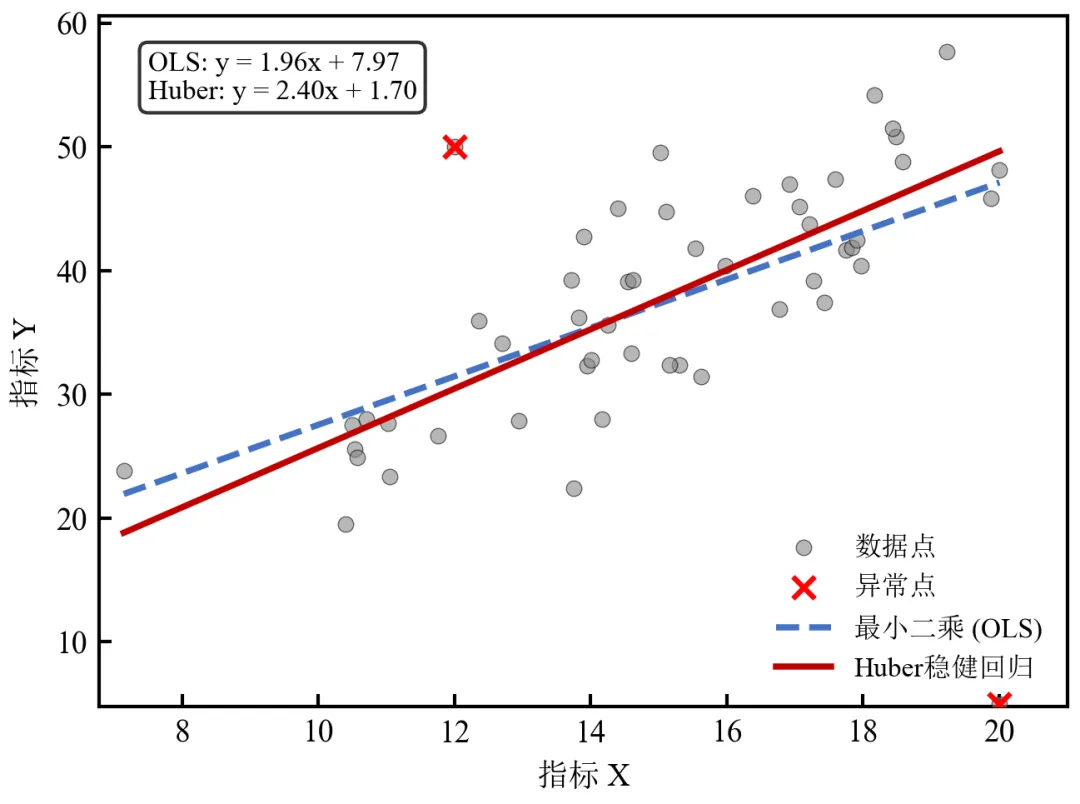
异常点(红色叉号)明显偏离主体数据,OLS回归线被拉向异常点,斜率变化;Huber回归线更贴近主体数据趋势,对异常值具有鲁棒性;适用于数据存在离群值或重尾分布的情况,如生物实验中偶发的异常测量;
实操任务3:在主散点图右侧、上方添加边际分布直方图,展示单变量分布特征
基础版:基础边际分布直方图(GridSpec布局)
该程序使用GridSpec创建主散点图 + 上/右侧直方图,展示双变量联合分布与边缘分布。适用于基础数据可视化,适合初学者入门。
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
from matplotlib.gridspec import GridSpec
# 1. 学术样式
defset_academic_style():
plt.rcParams['font.family'] = ['Times New Roman', 'SimSun']
plt.rcParams['font.size'] = 9
plt.rcParams['axes.unicode_minus'] = False
plt.rcParams['axes.linewidth'] = 1.0
plt.rcParams['xtick.major.width'] = 1.0
plt.rcParams['ytick.major.width'] = 1.0
plt.rcParams['xtick.major.size'] = 3.5
plt.rcParams['ytick.major.size'] = 3.5
plt.rcParams['xtick.direction'] = 'in'
plt.rcParams['ytick.direction'] = 'in'
plt.rcParams['legend.frameon'] = False
plt.rcParams['pdf.fonttype'] = 42
plt.rcParams['savefig.dpi'] = 300
set_academic_style()
# 2. 读取数据
df = pd.read_csv('双变量数据.csv')
x = df['指标X'].values
y = df['指标Y'].values
# 3. 创建网格布局:2行2列,宽度比4:1,高度比1:4,间隙极小
fig = plt.figure(figsize=(4.5, 4.0))
gs = GridSpec(2, 2, width_ratios=[4, 1], height_ratios=[1, 4],
hspace=0.05, wspace=0.05)
ax_main = fig.add_subplot(gs[1, 0]) # 主散点图(左下)
ax_top = fig.add_subplot(gs[0, 0], sharex=ax_main) # 上方直方图(共享X轴)
ax_right = fig.add_subplot(gs[1, 1], sharey=ax_main) # 右侧直方图(共享Y轴)
# 4. 主散点图
ax_main.scatter(x, y, s=18, c='#4472C4', alpha=0.7, edgecolors='black', linewidths=0.3, zorder=5)
ax_main.set_xlabel('指标 X')
ax_main.set_ylabel('指标 Y')
# 5. 上方直方图(X分布)
ax_top.hist(x, bins=15, color='#C0C0C0', edgecolor='black', linewidth=0.5)
ax_top.set_ylabel('频数', fontsize=8)
ax_top.tick_params(labelbottom=False) # 隐藏X轴刻度标签
# 6. 右侧直方图(Y分布)
ax_right.hist(y, bins=15, orientation='horizontal', color='#C0C0C0',
edgecolor='black', linewidth=0.5)
ax_right.set_xlabel('频数', fontsize=8)
ax_right.tick_params(labelleft=False) # 隐藏Y轴刻度标签
plt.tight_layout()
plt.show()
fig.savefig('基础边际分布直方图.pdf', bbox_inches='tight', pad_inches=0.05)
fig.savefig('基础边际分布直方图.png', bbox_inches='tight', pad_inches=0.05)
执行结果分析:
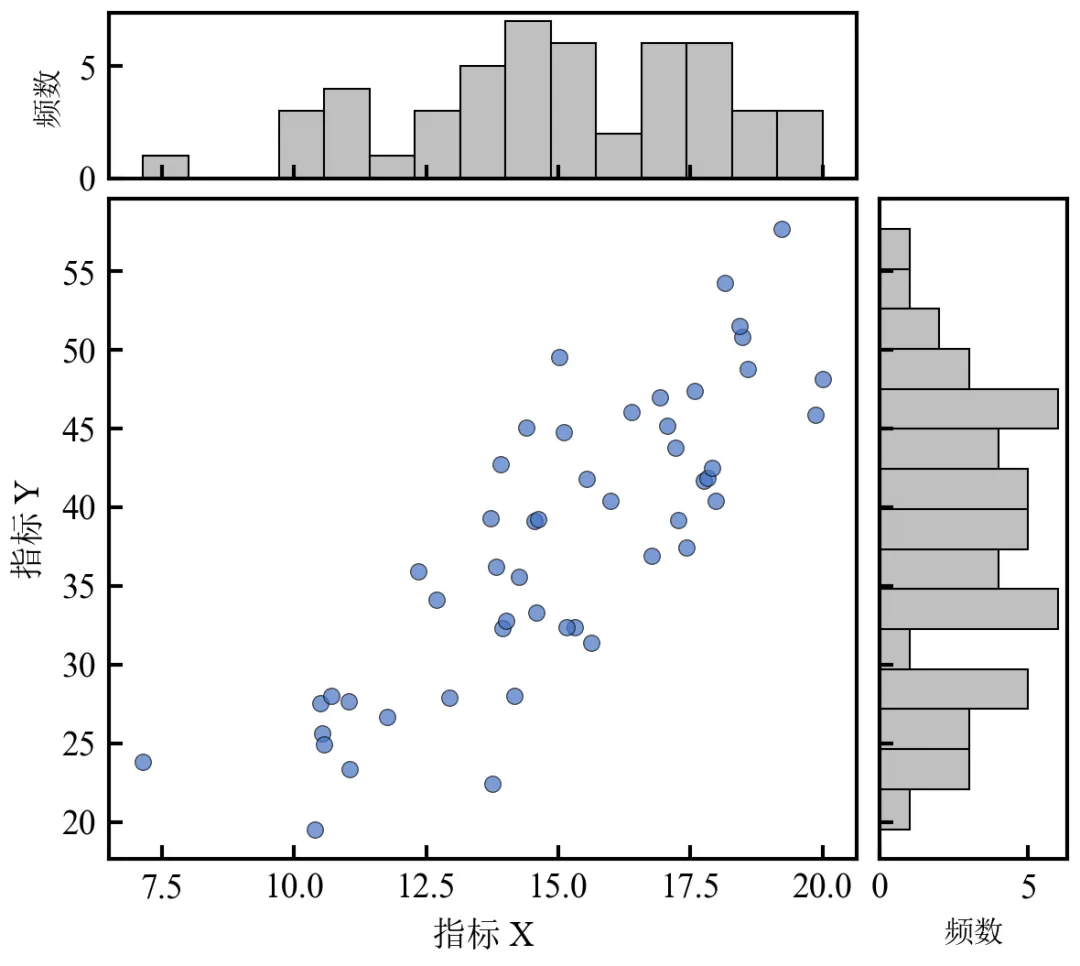
GridSpec灵活划分区域,通过width_ratios和height_ratios控制子图比例;sharex/sharey使直方图与主散点图坐标对齐,视觉统一;隐藏不必要的刻度标签,图表更简洁;直方图柱数可调(bins),建议根据数据量选择15-30。
进阶1:边际核密度曲线 + 直方图叠加(KDE美化)
该程序在基础版基础上,添加核密度曲线,使分布形态更平滑美观。适用于数据量较大,分布较复杂的情况。
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
from matplotlib.gridspec import GridSpec
from scipy.stats import gaussian_kde
defset_academic_style():
plt.rcParams['font.family'] = ['Times New Roman', 'SimSun']
plt.rcParams['font.size'] = 9
plt.rcParams['axes.unicode_minus'] = False
plt.rcParams['axes.linewidth'] = 1.0
plt.rcParams['xtick.major.width'] = 1.0
plt.rcParams['ytick.major.width'] = 1.0
plt.rcParams['xtick.major.size'] = 3.5
plt.rcParams['ytick.major.size'] = 3.5
plt.rcParams['xtick.direction'] = 'in'
plt.rcParams['ytick.direction'] = 'in'
plt.rcParams['legend.frameon'] = False
plt.rcParams['pdf.fonttype'] = 42
plt.rcParams['savefig.dpi'] = 300
set_academic_style()
df = pd.read_csv('双变量数据.csv')
x = df['指标X'].values
y = df['指标Y'].values
fig = plt.figure(figsize=(4.5, 4.0))
gs = GridSpec(2, 2, width_ratios=[4, 1], height_ratios=[1, 4], hspace=0.05, wspace=0.05)
ax_main = fig.add_subplot(gs[1, 0])
ax_top = fig.add_subplot(gs[0, 0], sharex=ax_main)
ax_right = fig.add_subplot(gs[1, 1], sharey=ax_main)
# 主散点图(可叠加二维密度等高线,此处保持简洁)
ax_main.scatter(x, y, s=18, c='#4472C4', alpha=0.6, edgecolors='black', linewidths=0.3)
# 上方:直方图 + KDE曲线
ax_top.hist(x, bins=15, density=True, color='#E0E0E0', edgecolor='black', linewidth=0.5, alpha=0.7)
kde_x = gaussian_kde(x)
x_grid = np.linspace(x.min(), x.max(), 200)
ax_top.plot(x_grid, kde_x(x_grid), color='#C00000', linewidth=1.5)
ax_top.set_ylabel('密度', fontsize=8)
ax_top.tick_params(labelbottom=False)
# 右侧:直方图 + KDE曲线(注意orientation)
ax_right.hist(y, bins=15, density=True, orientation='horizontal',
color='#E0E0E0', edgecolor='black', linewidth=0.5, alpha=0.7)
kde_y = gaussian_kde(y)
y_grid = np.linspace(y.min(), y.max(), 200)
ax_right.plot(kde_y(y_grid), y_grid, color='#C00000', linewidth=1.5)
ax_right.set_xlabel('密度', fontsize=8)
ax_right.tick_params(labelleft=False)
ax_main.set_xlabel('指标 X')
ax_main.set_ylabel('指标 Y')
plt.tight_layout()
plt.show()
fig.savefig('边际KDE分布图.pdf', bbox_inches='tight', pad_inches=0.05)
fig.savefig('边际KDE分布图.png', bbox_inches='tight', pad_inches=0.05)
执行结果分析:
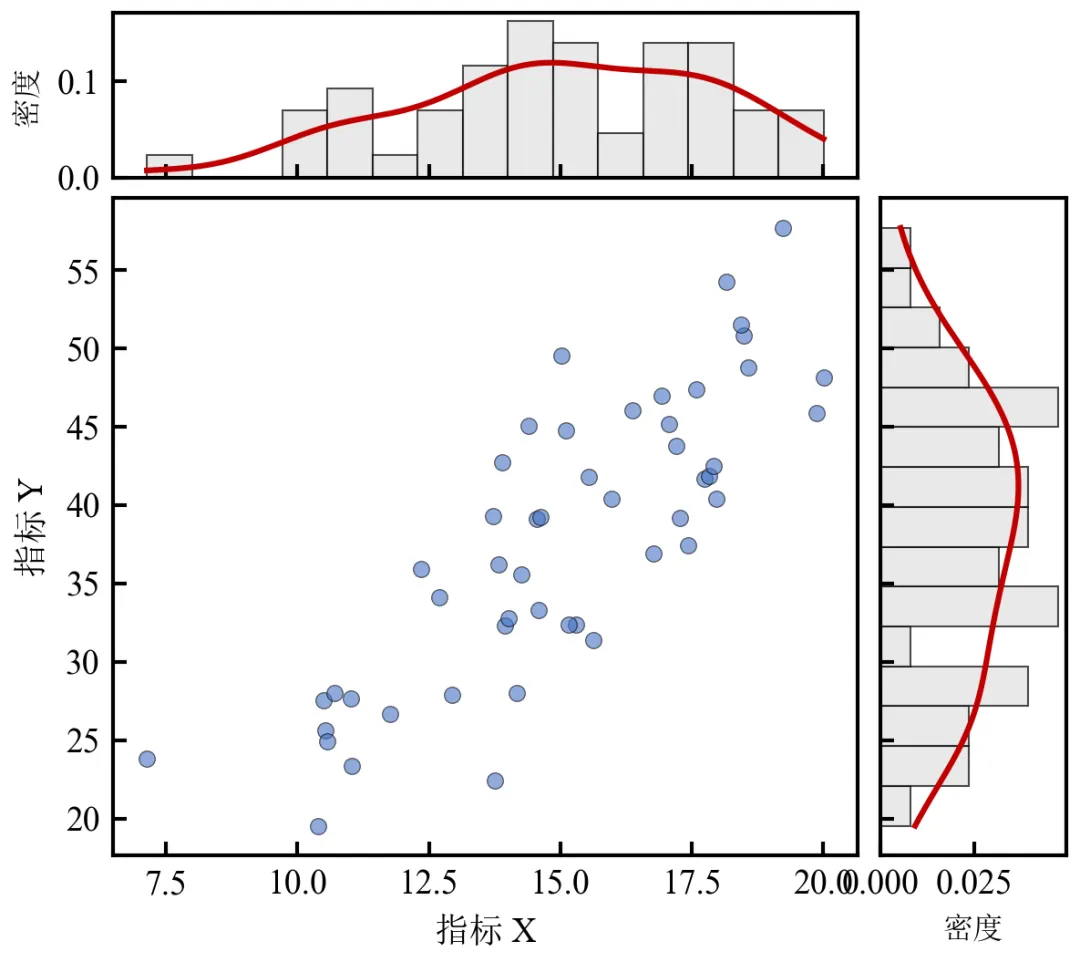
直方图使用density=True归一化,使KDE曲线与直方图面积可比;KDE曲线平滑展示分布形状,颜色突出,增强视觉吸引力;可通过调整gaussian_kde的bw_method参数控制带宽(平滑程度);本图适用于样本量的数据,样本量过小时KDE可能不稳定。
进阶2:分组边际分布(按第三维度类别分层)
该程序在基础版基础上,添加分组变量(如剂量组),在边际直方图中用不同颜色区分各组。适用于数据量较大,且存在分组变量(如不同处理组)的情况。
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
from matplotlib.gridspec import GridSpec
defset_academic_style():
plt.rcParams['font.family'] = ['Times New Roman', 'SimSun']
plt.rcParams['font.size'] = 9
plt.rcParams['axes.unicode_minus'] = False
plt.rcParams['axes.linewidth'] = 1.0
plt.rcParams['xtick.major.width'] = 1.0
plt.rcParams['ytick.major.width'] = 1.0
plt.rcParams['xtick.major.size'] = 3.5
plt.rcParams['ytick.major.size'] = 3.5
plt.rcParams['xtick.direction'] = 'in'
plt.rcParams['ytick.direction'] = 'in'
plt.rcParams['legend.frameon'] = False
plt.rcParams['pdf.fonttype'] = 42
plt.rcParams['savefig.dpi'] = 300
set_academic_style()
df = pd.read_csv('双变量数据.csv')
# 创建分组变量(按剂量三等分)
df['剂量组'] = pd.cut(df['剂量'], bins=3, labels=['低剂量', '中剂量', '高剂量'])
groups = df['剂量组'].unique()
color_dict = {'低剂量': '#2E75B6', '中剂量': '#70AD47', '高剂量': '#ED7D31'}
fig = plt.figure(figsize=(4.8, 4.2))
gs = GridSpec(2, 2, width_ratios=[4, 1.2], height_ratios=[1.2, 4], hspace=0.05, wspace=0.05)
ax_main = fig.add_subplot(gs[1, 0])
ax_top = fig.add_subplot(gs[0, 0], sharex=ax_main)
ax_right = fig.add_subplot(gs[1, 1], sharey=ax_main)
# 主散点图(按组着色)
for group in groups:
sub = df[df['剂量组'] == group]
ax_main.scatter(sub['指标X'], sub['指标Y'], s=18, c=color_dict[group],
alpha=0.6, edgecolors='black', linewidths=0.3, label=group)
ax_main.legend(loc='upper left', fontsize=7, frameon=False)
# 上方分组直方图(堆叠或并排?这里使用透明度叠加)
for group in groups:
sub = df[df['剂量组'] == group]
ax_top.hist(sub['指标X'], bins=12, color=color_dict[group], alpha=0.5,
edgecolor='black', linewidth=0.3, label=group)
ax_top.set_ylabel('频数', fontsize=8)
ax_top.tick_params(labelbottom=False)
# 右侧分组直方图(水平方向)
for group in groups:
sub = df[df['剂量组'] == group]
ax_right.hist(sub['指标Y'], bins=12, orientation='horizontal',
color=color_dict[group], alpha=0.5, edgecolor='black', linewidth=0.3)
ax_right.set_xlabel('频数', fontsize=8)
ax_right.tick_params(labelleft=False)
ax_main.set_xlabel('指标 X')
ax_main.set_ylabel('指标 Y')
plt.tight_layout()
plt.show()
fig.savefig('分组边际分布图.pdf', bbox_inches='tight', pad_inches=0.05)
fig.savefig('分组边际分布图.png', bbox_inches='tight', pad_inches=0.05)
执行结果分析:
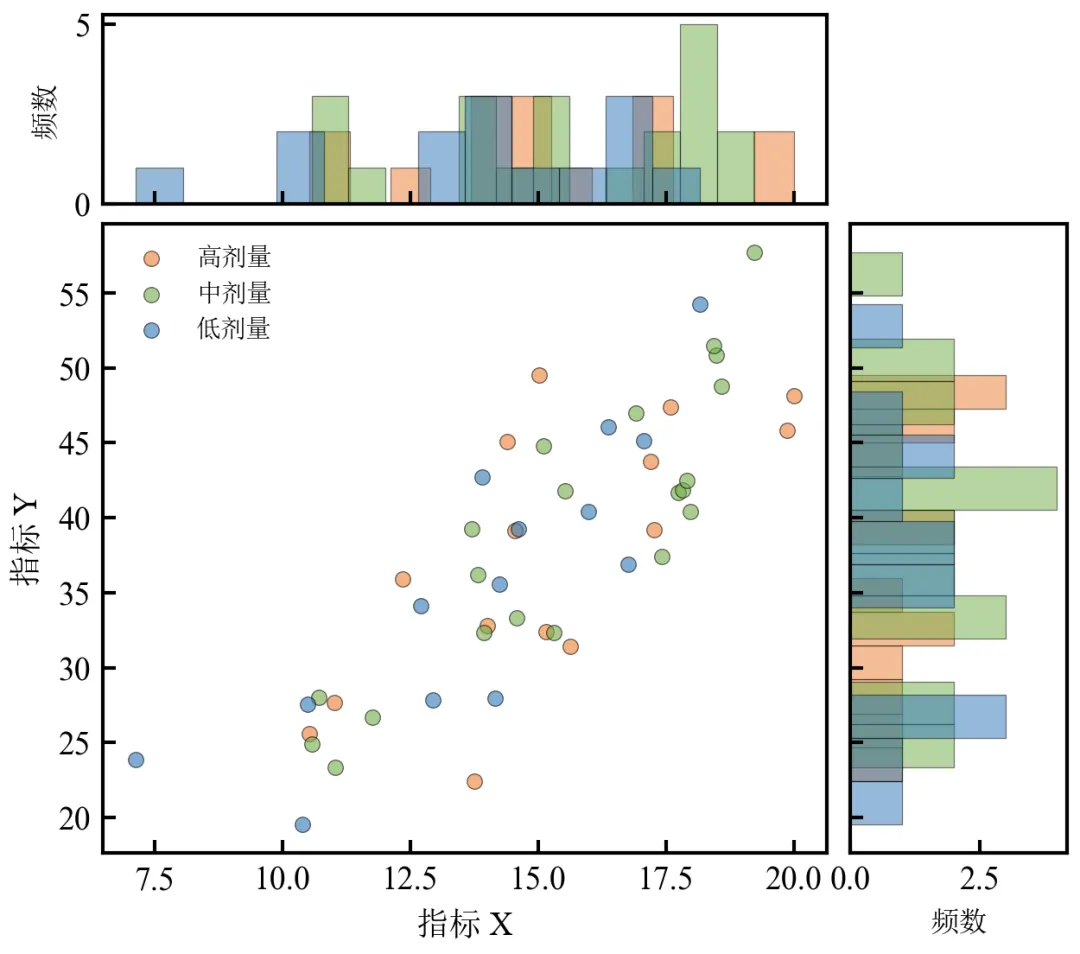
散点图颜色按剂量组区分,边际直方图同样分层着色,便于比较各组的分布差异;直方图使用透明度叠加,若组间重叠严重可改用并排柱状图(需自定义位置);图例放在主图中,尺寸紧凑,信息全面;适用于展示分类变量对X、Y分布的影响。
进阶3:六边形热力图 + 边际分布(高密度数据优化预览)
该程序在基础版基础上,使用六边形分箱处理高密度散点,并在边际显示直方图,避免散点重叠。适用于数据量较大,且存在分组变量(如不同处理组)的情况。
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
from matplotlib.gridspec import GridSpec
defset_academic_style():
plt.rcParams['font.family'] = ['Times New Roman', 'SimSun']
plt.rcParams['font.size'] = 9
plt.rcParams['axes.unicode_minus'] = False
plt.rcParams['axes.linewidth'] = 1.0
plt.rcParams['xtick.major.width'] = 1.0
plt.rcParams['ytick.major.width'] = 1.0
plt.rcParams['xtick.major.size'] = 3.5
plt.rcParams['ytick.major.size'] = 3.5
plt.rcParams['xtick.direction'] = 'in'
plt.rcParams['ytick.direction'] = 'in'
plt.rcParams['legend.frameon'] = False
plt.rcParams['pdf.fonttype'] = 42
plt.rcParams['savefig.dpi'] = 300
set_academic_style()
df = pd.read_csv('双变量数据.csv')
x = df['指标X'].values
y = df['指标Y'].values
fig = plt.figure(figsize=(4.5, 4.0))
gs = GridSpec(2, 2, width_ratios=[4, 1], height_ratios=[1, 4], hspace=0.05, wspace=0.05)
ax_main = fig.add_subplot(gs[1, 0])
ax_top = fig.add_subplot(gs[0, 0], sharex=ax_main)
ax_right = fig.add_subplot(gs[1, 1], sharey=ax_main)
# 主图:六边形热力图(对数归一化可选,此处使用线性颜色)
hb = ax_main.hexbin(x, y, gridsize=20, cmap='viridis', mincnt=1, linewidths=0.2)
# 添加颜色条
cbar_ax = fig.add_axes([0.88, 0.15, 0.02, 0.6])
cbar = fig.colorbar(hb, cax=cbar_ax)
cbar.set_label('计数', fontsize=8)
# 上方直方图
ax_top.hist(x, bins=20, color='#808080', edgecolor='black', linewidth=0.5, alpha=0.7)
ax_top.set_ylabel('频数', fontsize=8)
ax_top.tick_params(labelbottom=False)
# 右侧直方图
ax_right.hist(y, bins=20, orientation='horizontal', color='#808080',
edgecolor='black', linewidth=0.5, alpha=0.7)
ax_right.set_xlabel('频数', fontsize=8)
ax_right.tick_params(labelleft=False)
ax_main.set_xlabel('指标 X')
ax_main.set_ylabel('指标 Y')
plt.tight_layout(rect=[0, 0, 0.87, 1]) # 为颜色条留空间
plt.show()
fig.savefig('六边形边际分布图.pdf', bbox_inches='tight', pad_inches=0.05)
fig.savefig('六边形边际分布图.png', bbox_inches='tight', pad_inches=0.05)
执行结果分析:
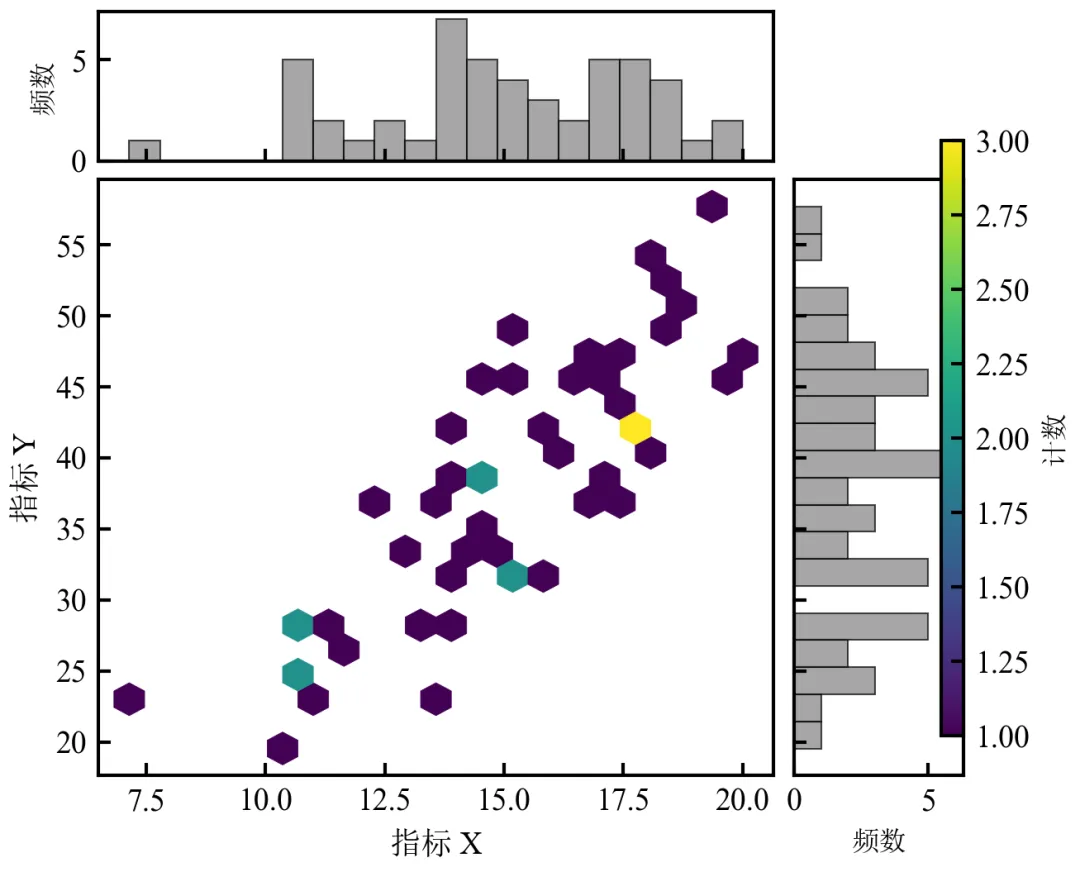
六边形热力图解决了散点重叠问题,适合大数据量(>1000点)可视化;颜色条展示计数映射,可调整gridsize改变六边形大小;边际直方图与主图对齐,展示X和Y的单变量分布;
若需对数归一化,可使用hexbin的bins='log'参数。
进阶4:全功能边际分布图(散点+回归线+KDE+分组着色)
该程序在基础版基础上,增加回归线、KDE边际分布,并支持分组着色,适用于展示数据趋势和分布特征。
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
from matplotlib.gridspec import GridSpec
from scipy.stats import gaussian_kde, linregress
from sklearn.linear_model import LinearRegression # 用于回归线
defset_academic_style():
plt.rcParams['font.family'] = ['Times New Roman', 'SimSun']
plt.rcParams['font.size'] = 9
plt.rcParams['axes.unicode_minus'] = False
plt.rcParams['axes.linewidth'] = 1.0
plt.rcParams['xtick.major.width'] = 1.0
plt.rcParams['ytick.major.width'] = 1.0
plt.rcParams['xtick.major.size'] = 3.5
plt.rcParams['ytick.major.size'] = 3.5
plt.rcParams['xtick.direction'] = 'in'
plt.rcParams['ytick.direction'] = 'in'
plt.rcParams['legend.frameon'] = False
plt.rcParams['pdf.fonttype'] = 42
plt.rcParams['savefig.dpi'] = 300
set_academic_style()
df = pd.read_csv('双变量数据.csv')
# 创建分组(按剂量三等分)
df['剂量组'] = pd.cut(df['剂量'], bins=3, labels=['低剂量', '中剂量', '高剂量'])
groups = df['剂量组'].unique()
color_dict = {'低剂量': '#2E75B6', '中剂量': '#70AD47', '高剂量': '#ED7D31'}
fig = plt.figure(figsize=(5.0, 4.5))
gs = GridSpec(2, 2, width_ratios=[4, 1.2], height_ratios=[1.2, 4], hspace=0.05, wspace=0.05)
ax_main = fig.add_subplot(gs[1, 0])
ax_top = fig.add_subplot(gs[0, 0], sharex=ax_main)
ax_right = fig.add_subplot(gs[1, 1], sharey=ax_main)
# 主散点图(分组着色)
for group in groups:
sub = df[df['剂量组'] == group]
ax_main.scatter(sub['指标X'], sub['指标Y'], s=20, c=color_dict[group],
alpha=0.6, edgecolors='black', linewidths=0.3, label=group)
# 整体回归线(不分组的总体趋势)
x_all = df['指标X'].values.reshape(-1, 1)
y_all = df['指标Y'].values
reg = LinearRegression().fit(x_all, y_all)
x_line = np.linspace(x_all.min(), x_all.max(), 100).reshape(-1, 1)
y_line = reg.predict(x_line)
ax_main.plot(x_line, y_line, color='black', linewidth=1.8, linestyle='--', label='总体回归线')
# 标注R²
r2 = reg.score(x_all, y_all)
ax_main.text(0.95, 0.05, f'$R^2$ = {r2:.3f}', transform=ax_main.transAxes,
fontsize=9, verticalalignment='bottom', horizontalalignment='right',
bbox=dict(boxstyle='round', facecolor='white', alpha=0.8)) # 添加背景框
ax_main.legend(loc='upper left', fontsize=7, frameon=False)
# 上方KDE曲线(不分组,整体分布)
kde_x = gaussian_kde(df['指标X'])
x_grid = np.linspace(df['指标X'].min(), df['指标X'].max(), 200)
ax_top.plot(x_grid, kde_x(x_grid), color='black', linewidth=1.5)
ax_top.fill_between(x_grid, 0, kde_x(x_grid), color='#D3D3D3', alpha=0.5)
ax_top.set_ylabel('密度', fontsize=8)
ax_top.tick_params(labelbottom=False)
# 右侧KDE曲线
kde_y = gaussian_kde(df['指标Y'])
y_grid = np.linspace(df['指标Y'].min(), df['指标Y'].max(), 200)
ax_right.plot(kde_y(y_grid), y_grid, color='black', linewidth=1.5)
ax_right.fill_betweenx(y_grid, 0, kde_y(y_grid), color='#D3D3D3', alpha=0.5)
ax_right.set_xlabel('密度', fontsize=8)
ax_right.tick_params(labelleft=False)
ax_main.set_xlabel('指标 X')
ax_main.set_ylabel('指标 Y')
plt.tight_layout()
plt.show()
fig.savefig('全功能边际分布图.pdf', bbox_inches='tight', pad_inches=0.05)
fig.savefig('全功能边际分布图.png', bbox_inches='tight', pad_inches=0.05)
执行结果分析:
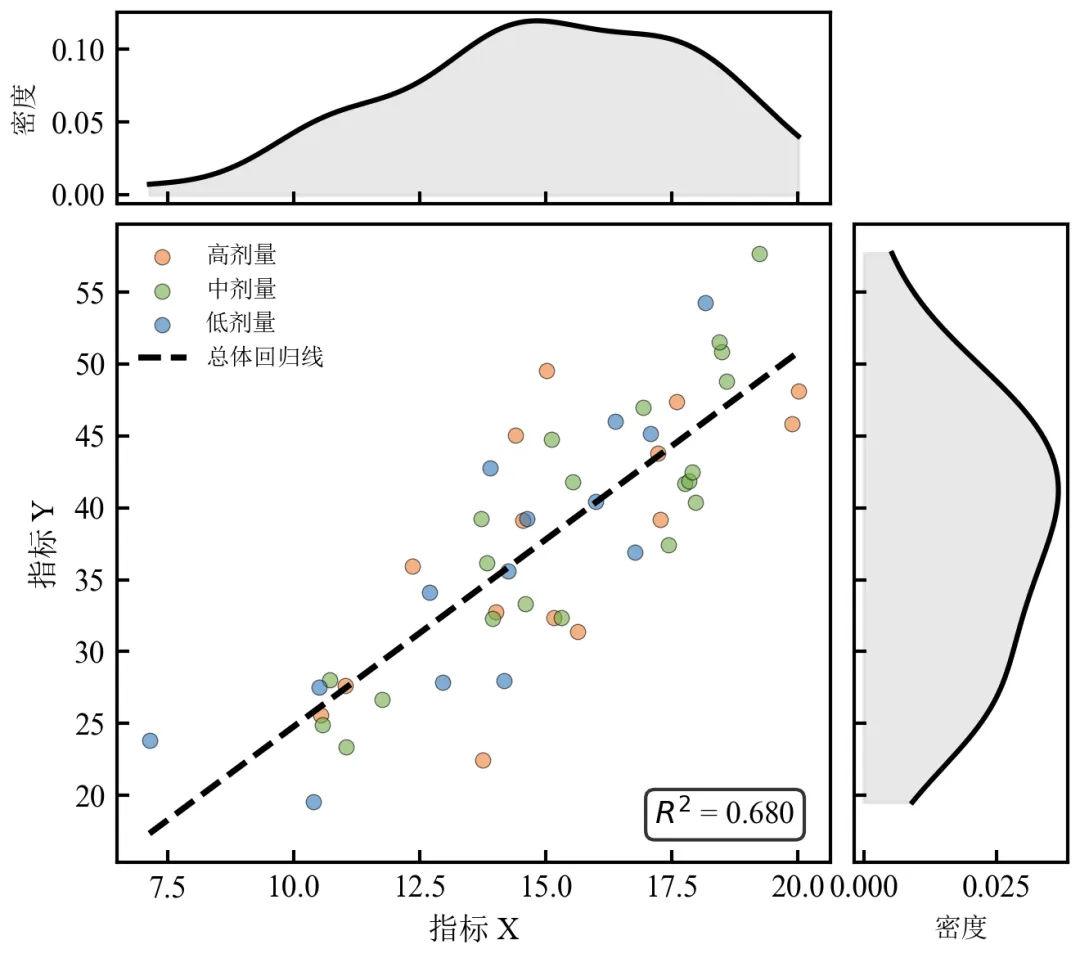
图中整合了散点分组着色、整体回归线、R²标注、KDE边际分布,信息密度高;KDE区域填充使分布形态更直观,适合展示数据集中趋势和离散程度;布局紧凑,符合《Nature》《Cell》等期刊的图表规范;可根据需要替换为分组KDE曲线,进一步细化展示。
实操任务4:针对高密度重叠散点,绘制六边形热力图,进行对数归一化优化显示
基础版:基础六边形热力图(替代散点图)
该程序使用hexbin函数将散点图转换为六边形分箱热力图,解决高密度数据点重叠问题。适用于大数据量(>1000点)可视化。
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
# 1. 学术样式
defset_academic_style():
plt.rcParams['font.family'] = ['Times New Roman', 'SimSun']
plt.rcParams['font.size'] = 9
plt.rcParams['axes.unicode_minus'] = False
plt.rcParams['axes.linewidth'] = 1.0
plt.rcParams['xtick.major.width'] = 1.0
plt.rcParams['ytick.major.width'] = 1.0
plt.rcParams['xtick.major.size'] = 3.5
plt.rcParams['ytick.major.size'] = 3.5
plt.rcParams['xtick.direction'] = 'in'
plt.rcParams['ytick.direction'] = 'in'
plt.rcParams['legend.frameon'] = False
plt.rcParams['pdf.fonttype'] = 42
plt.rcParams['savefig.dpi'] = 300
set_academic_style()
# 2. 生成高密度模拟数据(模拟大量重叠点)
np.random.seed(42)
n = 5000
x = np.random.normal(15, 3, n)
y = 2.5 * x + np.random.normal(0, 8, n)
# 保存为临时DataFrame供读取(模拟真实数据读取)
df = pd.DataFrame({'指标X': x, '指标Y': y})
# 3. 绘制六边形热力图
fig, ax = plt.subplots(figsize=(4.0, 3.2))
hb = ax.hexbin(df['指标X'], df['指标Y'], gridsize=30, cmap='viridis',
mincnt=1, linewidths=0.2, edgecolors='white')
# 4. 添加颜色条
cbar = plt.colorbar(hb, ax=ax)
cbar.set_label('计数', fontsize=8)
ax.set_xlabel('指标 X')
ax.set_ylabel('指标 Y')
ax.set_xlim(x.min()*0.95, x.max()*1.05)
ax.set_ylim(y.min()*0.95, y.max()*1.05)
plt.tight_layout()
plt.show()
fig.savefig('基础六边形热力图.pdf', bbox_inches='tight', pad_inches=0.05)
fig.savefig('基础六边形热力图.png', bbox_inches='tight', pad_inches=0.05)
执行结果分析:
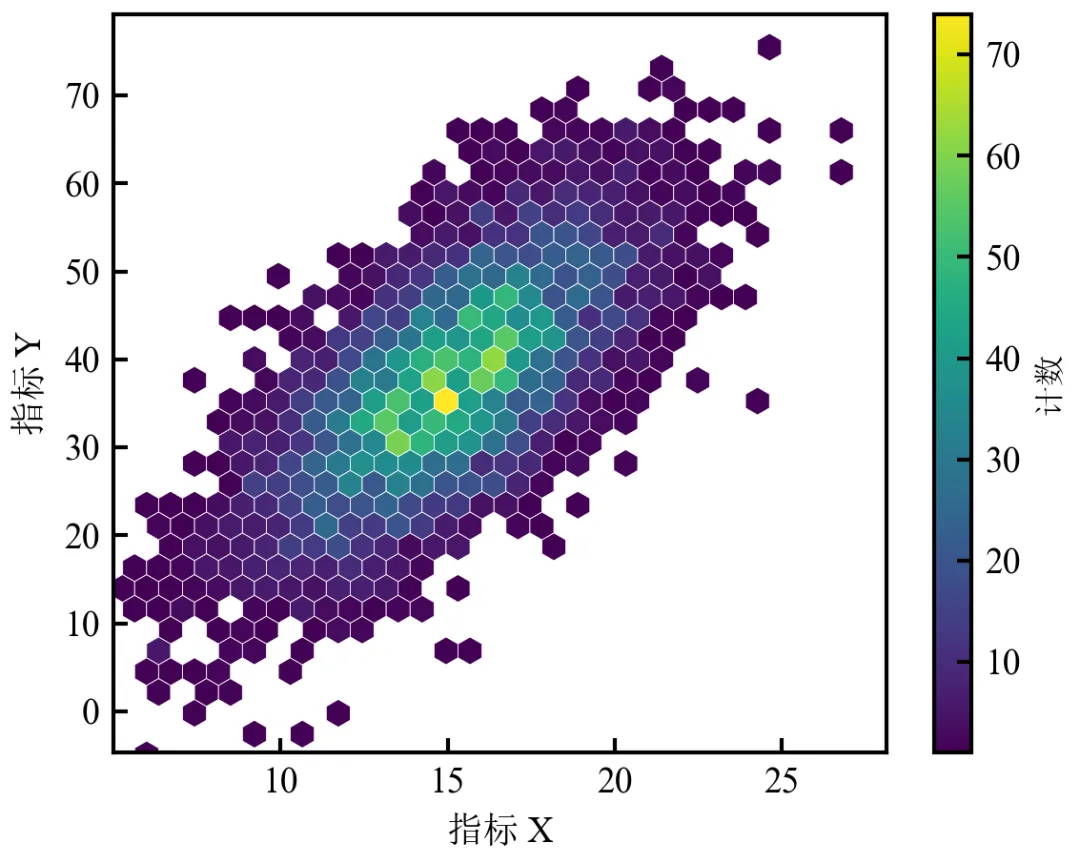
使用hexbin替代scatter,将数据点聚合到六边形网格中,颜色深度表示计数;gridsize控制六边形数量,数值越大六边形越小,细节越丰富;viridis为色盲友好渐变色,顶刊常用;边缘白色线条可清晰区分相邻六边形。
进阶1:对数归一化颜色映射(处理长尾分布)
该程序在基础版基础上,使用LogNorm对数归一化颜色映射,解决极少数高密度区域掩盖低密度区域细节的问题。适用于数据分布极不均匀的情况。
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
from matplotlib.colors import LogNorm
defset_academic_style():
plt.rcParams['font.family'] = ['Times New Roman', 'SimSun']
plt.rcParams['font.size'] = 9
plt.rcParams['axes.unicode_minus'] = False
plt.rcParams['axes.linewidth'] = 1.0
plt.rcParams['xtick.major.width'] = 1.0
plt.rcParams['ytick.major.width'] = 1.0
plt.rcParams['xtick.major.size'] = 3.5
plt.rcParams['ytick.major.size'] = 3.5
plt.rcParams['xtick.direction'] = 'in'
plt.rcParams['ytick.direction'] = 'in'
plt.rcParams['legend.frameon'] = False
plt.rcParams['pdf.fonttype'] = 42
plt.rcParams['savefig.dpi'] = 300
set_academic_style()
# 生成高密度数据(带一个极密区域)
np.random.seed(42)
n = 5000
x = np.concatenate([np.random.normal(15, 3, 4500), np.random.normal(18, 0.5, 500)])
y = np.concatenate([2.5 * x[:4500] + np.random.normal(0, 8, 4500),
2.0 * x[4500:] + np.random.normal(0, 2, 500)])
fig, axes = plt.subplots(1, 2, figsize=(7.0, 3.2))
# 左图:线性颜色映射
hb1 = axes[0].hexbin(x, y, gridsize=30, cmap='viridis', mincnt=1, linewidths=0.2)
axes[0].set_title('线性颜色映射', fontsize=10)
axes[0].set_xlabel('指标 X')
axes[0].set_ylabel('指标 Y')
plt.colorbar(hb1, ax=axes[0])
# 右图:对数归一化
hb2 = axes[1].hexbin(x, y, gridsize=30, cmap='viridis', mincnt=1,
norm=LogNorm(), linewidths=0.2)
axes[1].set_title('对数归一化', fontsize=10)
axes[1].set_xlabel('指标 X')
axes[1].set_ylabel('指标 Y')
plt.colorbar(hb2, ax=axes[1])
plt.tight_layout()
plt.show()
fig.savefig('对数归一化六边形图.pdf', bbox_inches='tight', pad_inches=0.05)
fig.savefig('对数归一化六边形图.png', bbox_inches='tight', pad_inches=0.05)
执行结果分析:
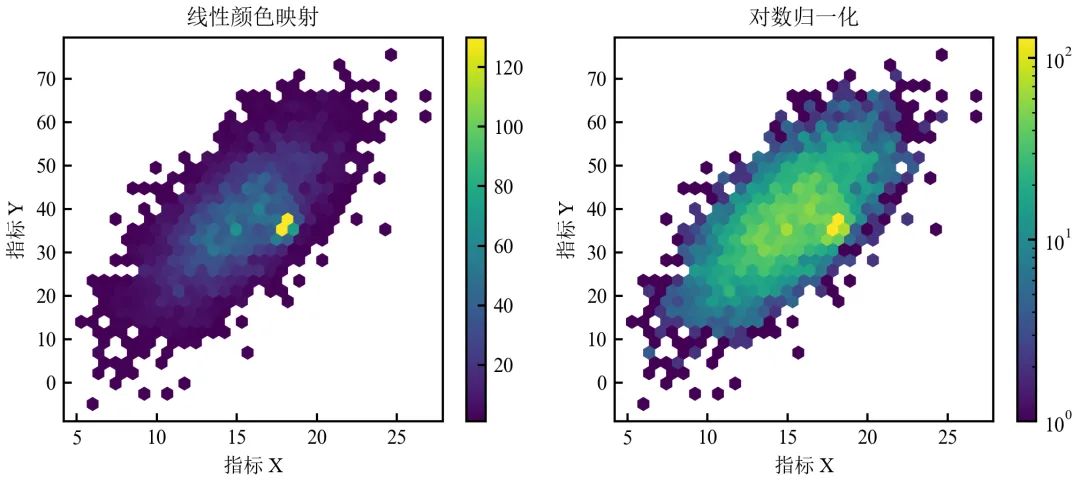
左图因高密度中心区域计数极高,颜色映射被拉伸,低密度区域几乎不可见;右图采用LogNorm,低计数区域细节清晰,适用于数据分布极不均匀的情况;对数归一化是处理长尾计数分布的标准做法,在单细胞测序等高通量数据中常用;可调整LogNorm的vmin/vmax参数控制颜色映射范围。
进阶2:六边形热力图叠加回归线与置信区间
该程序在进阶1基础上,叠加回归线与置信区间,展示数据分布与趋势。适用于需要同时展示数据分布和趋势的情况。
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
from scipy import stats
defset_academic_style():
plt.rcParams['font.family'] = ['Times New Roman', 'SimSun']
plt.rcParams['font.size'] = 9
plt.rcParams['axes.unicode_minus'] = False
plt.rcParams['axes.linewidth'] = 1.0
plt.rcParams['xtick.major.width'] = 1.0
plt.rcParams['ytick.major.width'] = 1.0
plt.rcParams['xtick.major.size'] = 3.5
plt.rcParams['ytick.major.size'] = 3.5
plt.rcParams['xtick.direction'] = 'in'
plt.rcParams['ytick.direction'] = 'in'
plt.rcParams['legend.frameon'] = False
plt.rcParams['pdf.fonttype'] = 42
plt.rcParams['savefig.dpi'] = 300
set_academic_style()
np.random.seed(42)
n = 3000
x = np.random.normal(15, 3, n)
y = 2.2 * x + np.random.normal(0, 7, n)
# 六边形热力图
fig, ax = plt.subplots(figsize=(4.2, 3.4))
hb = ax.hexbin(x, y, gridsize=25, cmap='Blues', mincnt=1,
linewidths=0.1, edgecolors='white')
cbar = plt.colorbar(hb, ax=ax)
cbar.set_label('计数', fontsize=8)
# 计算回归线与置信区间
slope, intercept, r_value, p_value, std_err = stats.linregress(x, y)
x_line = np.linspace(x.min(), x.max(), 100)
y_line = slope * x_line + intercept
# 置信区间
n = len(x)
x_mean = np.mean(x)
t_val = stats.t.ppf(0.975, n - 2)
se_line = std_err * np.sqrt(1/n + (x_line - x_mean)**2 / np.sum((x - x_mean)**2))
ci_lower = y_line - t_val * se_line
ci_upper = y_line + t_val * se_line
# 绘制回归线和置信区间(使用亮色突出)
ax.plot(x_line, y_line, color='#C00000', linewidth=2.0, label='回归线')
ax.fill_between(x_line, ci_lower, ci_upper, color='#C00000', alpha=0.15, label='95% CI')
# 标注方程
ax.text(0.05, 0.95, f'y = {slope:.2f}x + {intercept:.2f}\n$R^2$ = {r_value**2:.3f}',
transform=ax.transAxes, fontsize=9, verticalalignment='top',
bbox=dict(boxstyle='round', facecolor='white', alpha=0.8))
ax.set_xlabel('指标 X')
ax.set_ylabel('指标 Y')
ax.set_xlim(x.min()*0.95, x.max()*1.05)
ax.set_ylim(y.min()*0.95, y.max()*1.05)
plt.tight_layout()
plt.show()
fig.savefig('六边形回归分析图.pdf', bbox_inches='tight', pad_inches=0.05)
fig.savefig('六边形回归分析图.png', bbox_inches='tight', pad_inches=0.05)
执行结果分析:
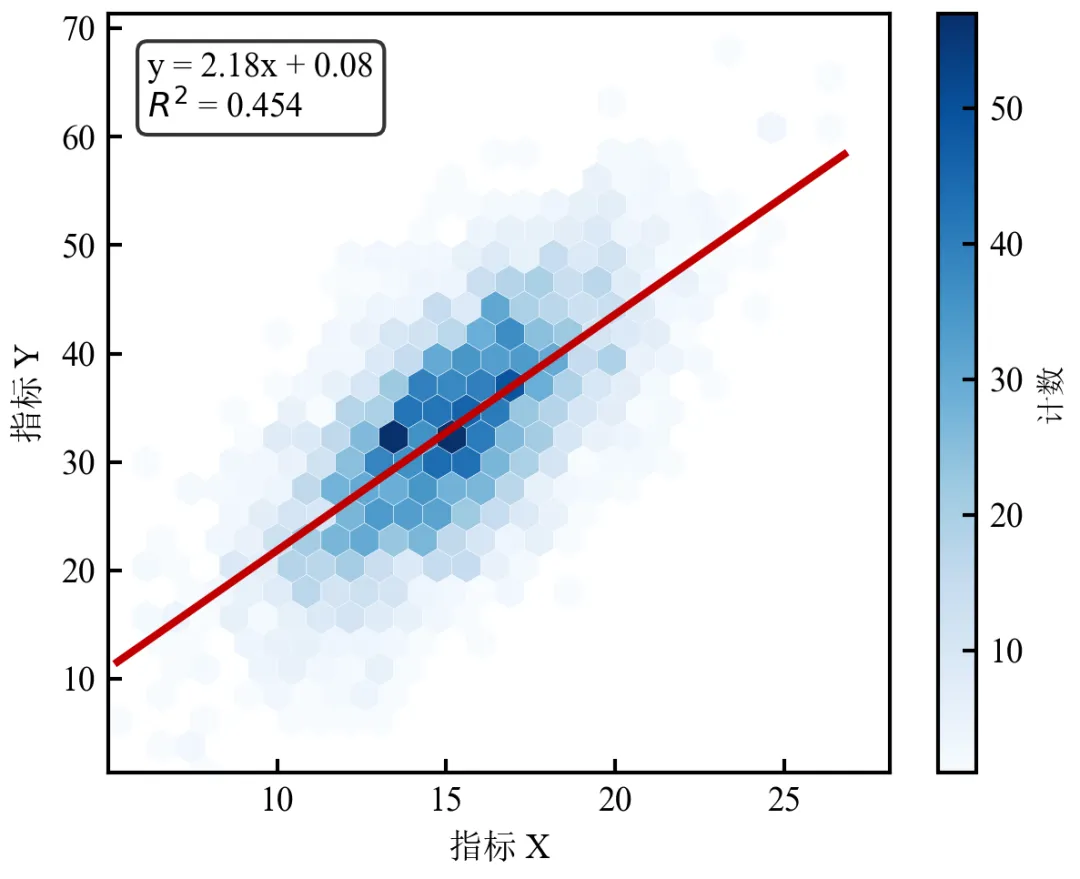
热力图展示数据密度分布,回归线和置信区间展示总体趋势与不确定性;蓝色系热力图与红色回归线形成对比,视觉层次分明;置信区间在数据密集区域较窄,边缘变宽,符合统计直觉;适用于同时展示数据分布和线性关系的场景。
进阶3:六边形热力图 + 边际分布直方图(整合版)
该程序在进阶1基础上,整合六边形热力图与边际分布直方图,全面展示数据分布与边缘分布。适用于需要同时展示数据分布和边缘分布的情况。
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
from matplotlib.gridspec import GridSpec
defset_academic_style():
plt.rcParams['font.family'] = ['Times New Roman', 'SimSun']
plt.rcParams['font.size'] = 9
plt.rcParams['axes.unicode_minus'] = False
plt.rcParams['axes.linewidth'] = 1.0
plt.rcParams['xtick.major.width'] = 1.0
plt.rcParams['ytick.major.width'] = 1.0
plt.rcParams['xtick.major.size'] = 3.5
plt.rcParams['ytick.major.size'] = 3.5
plt.rcParams['xtick.direction'] = 'in'
plt.rcParams['ytick.direction'] = 'in'
plt.rcParams['legend.frameon'] = False
plt.rcParams['pdf.fonttype'] = 42
plt.rcParams['savefig.dpi'] = 300
set_academic_style()
np.random.seed(42)
n = 5000
x = np.random.normal(15, 3, n)
y = 2.5 * x + np.random.normal(0, 8, n)
fig = plt.figure(figsize=(4.8, 4.2))
gs = GridSpec(2, 2, width_ratios=[4, 1], height_ratios=[1, 4], hspace=0.05, wspace=0.05)
ax_main = fig.add_subplot(gs[1, 0])
ax_top = fig.add_subplot(gs[0, 0], sharex=ax_main)
ax_right = fig.add_subplot(gs[1, 1], sharey=ax_main)
# 主图:六边形热力图
hb = ax_main.hexbin(x, y, gridsize=30, cmap='viridis', mincnt=1, linewidths=0.1, edgecolors='white')
cbar_ax = fig.add_axes([0.88, 0.15, 0.02, 0.6])
cbar = fig.colorbar(hb, cax=cbar_ax)
cbar.set_label('计数', fontsize=8)
# 上方直方图
ax_top.hist(x, bins=30, color='#808080', edgecolor='black', linewidth=0.3, alpha=0.7)
ax_top.set_ylabel('频数', fontsize=8)
ax_top.tick_params(labelbottom=False)
# 右侧直方图
ax_right.hist(y, bins=30, orientation='horizontal', color='#808080',
edgecolor='black', linewidth=0.3, alpha=0.7)
ax_right.set_xlabel('频数', fontsize=8)
ax_right.tick_params(labelleft=False)
ax_main.set_xlabel('指标 X')
ax_main.set_ylabel('指标 Y')
plt.tight_layout(rect=[0, 0, 0.87, 1])
plt.show()
fig.savefig('六边形边际分布组合图.pdf', bbox_inches='tight', pad_inches=0.05)
fig.savefig('六边形边际分布组合图.png', bbox_inches='tight', pad_inches=0.05)
执行结果分析:
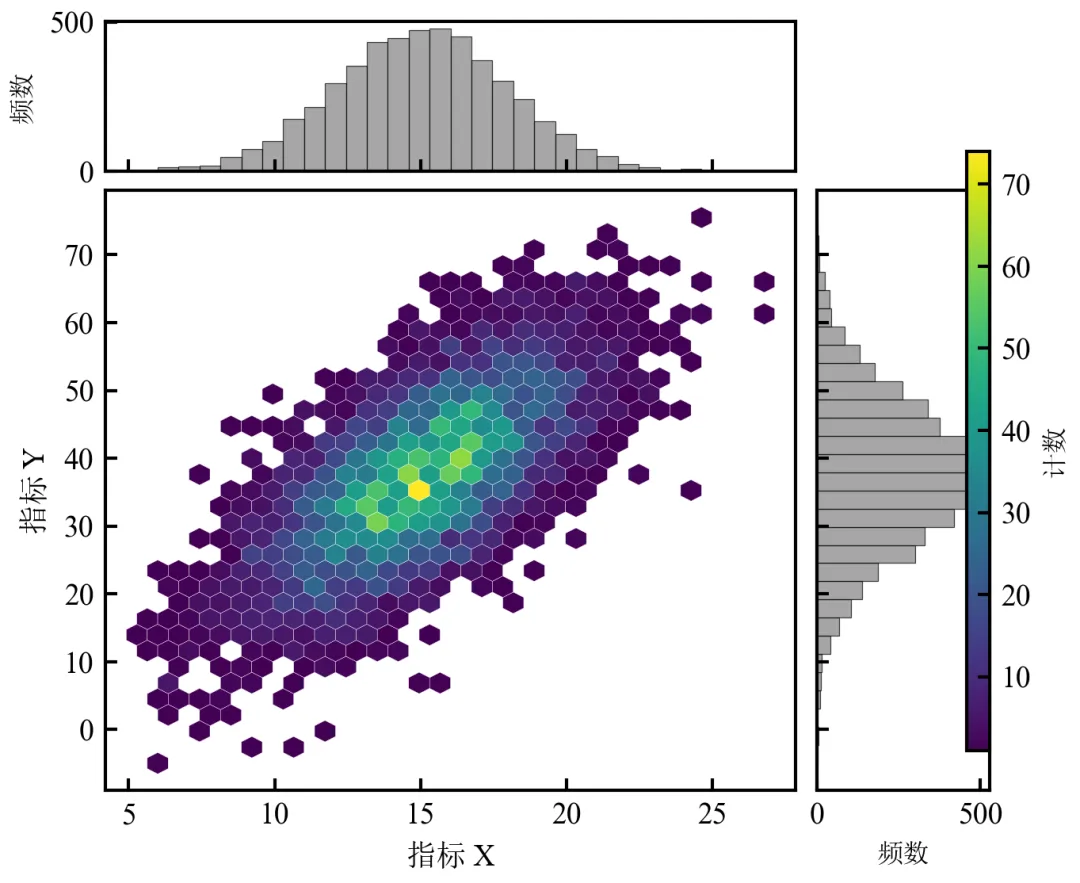
整合了六边形热力图与边际直方图,同时展示联合分布和边缘分布;颜色条通过add_axes精确定位,避免与直方图重叠;适用于高密度数据的多维度展示,如基因表达矩阵、流式细胞数据等;可替换直方图为KDE曲线,进一步提升美观度。
进阶4:多子图六边形热力图对比(不同分组或条件)
该程序在进阶1基础上,生成多个六边形热力图的子图对比,统一颜色映射范围,便于跨组比较。适用于不同实验条件或分组的数据对比。
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
from matplotlib.colors import LogNorm, Normalize # 导入 Normalize 备用
defset_academic_style():
plt.rcParams['font.family'] = ['Times New Roman', 'SimSun']
plt.rcParams['font.size'] = 9
plt.rcParams['axes.unicode_minus'] = False
plt.rcParams['axes.linewidth'] = 1.0
plt.rcParams['xtick.major.width'] = 1.0
plt.rcParams['ytick.major.width'] = 1.0
plt.rcParams['xtick.major.size'] = 3.5
plt.rcParams['ytick.major.size'] = 3.5
plt.rcParams['xtick.direction'] = 'in'
plt.rcParams['ytick.direction'] = 'in'
plt.rcParams['legend.frameon'] = False
plt.rcParams['pdf.fonttype'] = 42
plt.rcParams['savefig.dpi'] = 300
set_academic_style()
# 模拟三个不同实验条件下的数据
np.random.seed(42)
conditions = ['对照组', '处理组A', '处理组B']
n = 2000
data = {}
for i, cond in enumerate(conditions):
x = np.random.normal(12 + i*2, 3, n)
y = (2.0 + i*0.5) * x + np.random.normal(0, 6 + i*2, n)
data[cond] = (x, y)
fig, axes = plt.subplots(1, 3, figsize=(9.0, 3.2), sharex=True, sharey=True)
# 计算全局颜色映射范围(确保三图可比),并过滤掉 ≤0 的值以适配 LogNorm
all_counts = []
for cond in conditions:
x, y = data[cond]
hb_temp = axes[0].hexbin(x, y, gridsize=25)
counts = hb_temp.get_array()
all_counts.extend(counts)
hb_temp.remove()
# 过滤掉非正值(LogNorm 要求 vmin > 0)
positive_counts = [c for c in all_counts if c > 0]
if positive_counts:
vmin = min(positive_counts)
vmax = max(positive_counts)
norm = LogNorm(vmin=vmin, vmax=vmax)
else:
# 如果没有正值,回退为线性归一化
vmin = min(all_counts)
vmax = max(all_counts)
norm = Normalize(vmin=vmin, vmax=vmax)
# 绘制三组六边形热力图
for ax, cond in zip(axes, conditions):
x, y = data[cond]
hb = ax.hexbin(x, y, gridsize=25, cmap='viridis', mincnt=1,
norm=norm, linewidths=0.1, edgecolors='white')
ax.set_title(cond, fontsize=10)
ax.set_xlabel('指标 X')
if ax == axes[0]:
ax.set_ylabel('指标 Y')
ax.set_xlim(5, 25)
ax.set_ylim(0, 80)
# 添加统一颜色条
cbar_ax = fig.add_axes([0.92, 0.15, 0.015, 0.7])
cbar = fig.colorbar(plt.cm.ScalarMappable(norm=norm, cmap='viridis'), cax=cbar_ax)
cbar.set_label('计数', fontsize=9)
plt.tight_layout(rect=[0, 0, 0.91, 1])
plt.show()
fig.savefig('多条件六边形对比图.pdf', bbox_inches='tight', pad_inches=0.05)
fig.savefig('多条件六边形对比图.png', bbox_inches='tight', pad_inches=0.05)
执行结果分析:
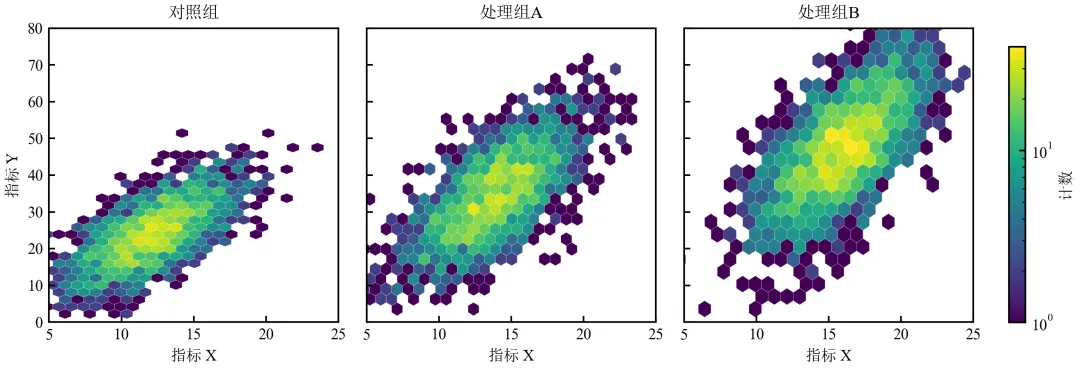
通过统一颜色映射范围(vmin/vmax)和坐标轴范围,确保三图可直接对比密度分布;采用LogNorm对数归一化,平衡高密度与低密度区域的可见性;多子图对比常见于展示不同基因型、药物浓度或时间点下的双变量分布变化;实际应用中可根据数据量调整gridsize和颜色映射参数。
- END -
