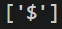一、re模块
import re # 导入内置的re模块
二、元字符
1. 常用
(1). - 匹配任意单个字符(除换行符)
print(re.findall(r'a.b', 'acba+ba b a\nb'))
(2)^ - 匹配字符串开头
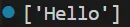
print(re.findall(r'^Hello', 'Hello world'))
print(re.findall(r'^Hello', 'Say Hello'))
(3)$ - 匹配字符串结尾
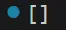
print(re.findall(r'world$', 'Hello world'))
(4)* - 匹配前一个字符0次或多次(贪婪)
print(re.findall(r'ca*t', 'ctcat caat caaat'))
(5)+ - 匹配前一个字符1次或多次(贪婪)
print(re.findall(r'ca+t', 'ct cat caat'))
(6)? - 匹配前一个字符0次或1次
print(re.findall(r'colou?r', 'color colour'))
(7){n} - 匹配前面的子表达式恰好n次
print(re.findall(r'a{3}', 'a aa aaa aaaa cat caat caaat caaaat'))
(8){n,} - 匹配前面的子表达式至少n次
print(re.findall(r'a{3,}', 'a aa aaa aaaa cat caat caaat caaaat'))
(9){n,m} - 匹配前面的子表达式n到m次
print(re.findall(r'a{2,3}', 'a aa aaa aaaa cat caat caaat caaaat'))
(10)| - 或关系,匹配左边或右边的内容
print(re.findall(r'cat|dog', 'I like cats and dogs'))
2. 字符类
(1)[] - 匹配括号内任意一个字符 # [abc] - 匹配a或b或c
print(re.findall(r'[aeiou]', 'hello world'))
(2)[^] - 匹配未包含的任意字符# [^abc] - 匹配除了a,b,c的字符
print(re.findall(r'[^aeiou]', 'hello'))
(3)[a-z] - 匹配小写字母
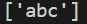
print(re.findall(r'[a-z]+', 'Hello123World'))
(4)\d - 匹配数字 # [0-9]
print(re.findall(r'\d+', 'age: 25, year: 2024'))
(5)\D - 匹配非数字 # [^0-9]
print(re.findall(r'\D+', '123abc456'))
(6)\w - 匹配字母、数字、下划线# [a-zA-Z0-9_]
print(re.findall(r'\w+', 'hello_world 123!'))
(7)\W - 匹配非字母、数字、下划线部分 # [^a-zA-Z0-9_]
print(re.findall(r'\W+', 'helloworld!'))
(8)\s - 匹配空白字符(空格、制表符、换行等)
print(re.findall(r'\s+', 'hello\tworld\n!'))
(9)\S - 匹配非空白字符
print(re.findall(r'\S+', 'hello world'))
(10)\b - 单词边界(匹配单词开头或结尾)
print(re.findall(r'\bcat\b', 'cat catalog cat'))
注:
\d+ 表示匹配一个或多个连续的数字(比如提取文本中的所有数字)
\w+ 表示匹配一个或多个单词字符(比如提取英文单词)
\s+ 表示匹配一个或多个空白字符(比如用来分割字符串)
3. 转义字符
# 特殊字符需要转义:. ^ $ * + ? { } [ ] \ | ( )
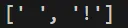
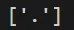
print(re.findall(r'\.', 'hello.world'))
print(re.findall(r'\$', 'price: $100'))
print(re.findall(r'\\', r'path\to\file')) # \t和\f不会被视为制表符和换页符
# 输出是 ['\\', '\\'] 是因为 Python 在显示列表时,会把反斜杠字符 \ 表示为 \\三、贪婪与非贪婪
(1)贪婪匹配(默认)- 尽可能多匹配
print(re.findall(r'<.*>', '<a>content</a>')) # 贪婪(2)非贪婪匹配(加?)- 尽可能少匹配
print(re.findall(r'<.*?>', '<a>content</a>')) # 非贪婪
(3)其他非贪婪形式
print(re.findall(r'\w+?\d', 'a1b2c3')) # 非贪婪
四、前瞻与后顾
(1)正向前瞻 (?=...) - 匹配后面跟随特定模式的位置
# \w+ 会尽可能多地匹配单词字符(贪婪匹配)
# (?!\s+is) 检查当前位置后面是否跟着 \s+is
print(re.findall(r'\w+(?=\s+is)', 'Pythonis great, Javais also great'))
(2)负向前瞻 (?!...) - 匹配后面不跟随特定模式的位置
print(re.findall(r'\w+(?!\s+is)', 'Pythonis great, Javais also great'))
(3)正向后顾 (?<=...) - 匹配前面是特定模式的位置
# \d+ 匹配一个或多个数字(0-9)(贪婪匹配)
# (?<=\$):正向后顾断言,要求当前位置前面是 $ 字符
print(re.findall(r'(?<=\$)\d+', '$100, $200, 300'))
(4)负向后顾 (?<!...) - 匹配前面不是特定模式的位置
print(re.findall(r'(?<!\$)\d+', '$100, $200, 300'))
五、常用标志
(1)re.I 或 re.IGNORECASE - 忽略大小写
print(re.findall(r'python', 'Python PYTHON', re.I))
(2)re.M 或 re.MULTILINE - 多行模式(^和$匹配每行)
print(re.findall(r'^line\d', 'line1\nline2\nline3', re.M))
(3)re.S 或 re.DOTALL - 点匹配所有字符包括换行
print(re.findall(r'hello.world', 'hello\nworld'))
print(re.findall(r'hello.world', 'hello\nworld', re.S))
(4)re.X 或 re.VERBOSE - 允许注释和空格
pattern = re.compile(r'''
\d{4} # 年份
- # 分隔符
\d{2} # 月份
''', re.VERBOSE)
print(pattern.findall('2024-01 2023-12'))
(5)组合多个标志
pattern = re.compile(r'^python', re.IGNORECASE | re.MULTILINE)
text = """Python is great
Java is good
python is also good
PYTHON is the best
But python at line start? No, here it's not at beginning
python with spaces at line start"""
matches = pattern.findall(text)
print(matches)