基于栈的虚拟机执行分析,以Python为例
- 2026-07-04 02:36:31
基于栈的虚拟机执行分析,以Python为例C语言编译到执行,前面已有系列文章,最终编译为基于寄存器的机器码。 一、语言执行模型 1.基于寄存器,比如C语言。 2.基于栈的虚拟机,比如Python。 3.混合寄存器和栈的虚拟机,比如Java。 基于栈是基于寄存器的高层抽象,前者用虚拟机模拟了处理器。 栈位于进程虚拟地址空间,最终会在具体的处理器上执行。寄存器在处理器内部,执行速度最快。 基于栈的虚拟机,屏蔽了具体机器指令集,可以跨平台、动态执行,执行速度相对慢些。这种抽象,正是架构设计的“银弹法则”——再加一层。 本文关注CPython这个Python解释器(虚拟机)。 二、进程地址空间 先回顾一下进程内存布局,注意堆和栈的位置,以下是Linux x86_64进程地址空间布局: 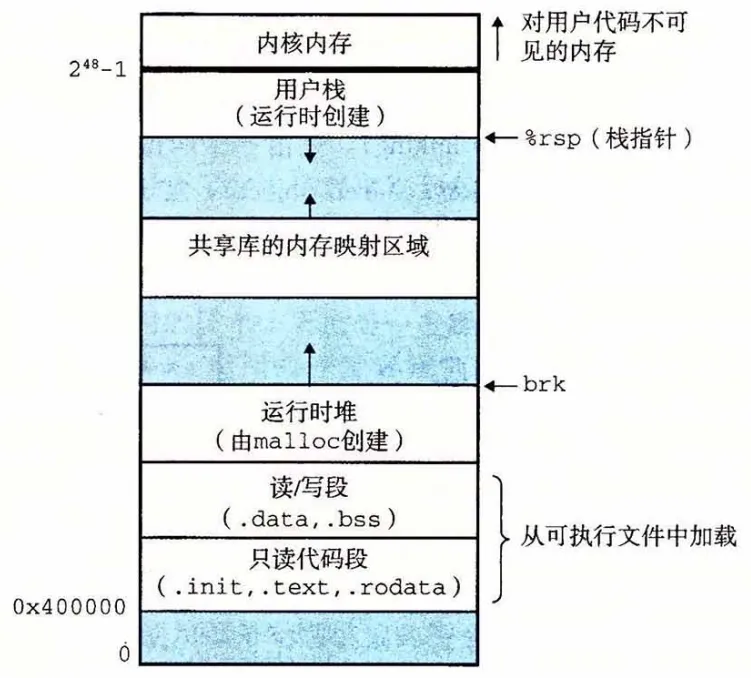
三、Python堆 在Python中,一切都是对象,数字、字符串、变量、函数、类,都是对象,都存放在堆中;这也是Python自动内存管理的重点,暂时忽略内存管理细节,本文关注执行过程。 Python3.11之前,执行时分配的函数栈也分配在堆中。 上面的图可以看到,栈分配通过栈指针移动实现,快速高效。堆分配通过malloc函数调用,再到brk系统调用,相对慢些。 四、Python栈 Python栈涉及:线程栈——>虚拟机栈——>函数栈——>操作栈 1.操作系统线程栈 首先,Python解释器启动,操作系统分配线程栈,维护CPython执行。CPython处在一个执行循环中: 这简直就是CPU的取指-译码-执行的翻版!可以回顾对比一下CPU的执行循环,本质一样:程序运行时,CPU在干什么 其中字节码,由Python源码编译生成,这个过程动态执行,也会经历词法-语法-语义、AST和优化,编译为Python字节码。每条字节码的功能,都由C语言实现。比如: 2.Python虚拟机栈 Python3.11以后,CPython在栈中分配了一个虚拟机栈,维护后续的函数栈和操作栈,这是一个较大优化。 Python3.11之前,这个虚拟机栈不存在,后续的函数栈和操作栈其实分配在堆上。 3.函数栈 每次函数调用时分配,保存函数参数、局部变量,退出时自动销毁,底层通过栈指针移动实现。但是Python3.11版本之前,其实分配在堆上。 4.操作栈 具体运算发生的地方,解释器CPython(虚拟机)模拟处理器,操作栈模拟寄存器。 五、Python字节码执行 1.完整流程 源代码——编译——pyc字节码——执行 2.操作栈执行示例 一个简单Python代码: Python字节码执行过程,分析见注释: 2026年4月13日
_Py_CODEUNIT *first_instr = code->co_code_adaptive;_Py_CODEUNIT *next_instr = first_instr;while (1) {_Py_CODEUNIT word = *next_instr++;//下一条字节码unsigned char opcode = _Py_OPCODE(word);//操作码unsigned int oparg = _Py_OPARG(word);//操作数switch (opcode) {// 根据操作码选择指令实现,实现由C语言完成}
LOAD_CONST 1#常量池索引1项加入操作栈def add():a = 1b = 2c = a + b
LOAD_CONST 1 (1)#常量池索引1项加入操作栈STORE_FAST 0 (a)#弹出操作栈栈顶,存入局部变量表索引0项LOAD_CONST 2 (2)STORE_FAST 1 (b)LOAD_FAST 0 (a)#局部变量表索引0项加入操作栈LOAD_FAST 1 (b)#局部变量表索引1项加入操作栈BINARY_ADD #弹出操作栈中的两项,相加,结果加入操作栈STORE_FAST 2 (c)#弹出操作栈栈顶,放入局部变量表索引2项
本文来自网友投稿或网络内容,如有侵犯您的权益请联系我们删除,联系邮箱:wyl860211@qq.com 。

