在 Linux 里,用户态与内核态之间的数据传递是一项高频且基础的操作,你或许会疑惑,为啥数据从用户态进入内核态,不能简单粗暴地直接访问,而非得借助copy_from_user呢?接下来我们将围绕这两个关键问题展开深入讲解。
第一个问题,数据从用户态传递到内核态时,为什么一定要进行拷贝,难道就不能不拷贝吗?
第二个问题,就算明确了需要拷贝,那又为什么非得使用 copy_from_user 函数,而不能用看似功能相似的 memcpy 函数替代呢?
这两个问题,是理解 Linux 内核数据传递机制的核心,也是每一个 Linux 开发者必须掌握的关键知识点 。
一、 数据交互为啥非要拷贝?不拷贝不行吗?
在深入探讨这个问题之前,我们先明确一个概念:用户态和内核态处于不同的虚拟地址空间 ,这是 Linux 操作系统内存管理的基础设定。
用户态进程有着自己独立的虚拟地址空间,其内存布局和访问权限与内核态截然不同,这种隔离机制保障了系统的稳定性和安全性。
那么,为什么在数据交互时,我们不能打破这种隔离,直接使用用户态的指针,而非得大费周章地进行数据拷贝呢?原因主要有以下几点。
1.1 用户态指针的局限性
1.1.1 进程切换导致用户态地址失效
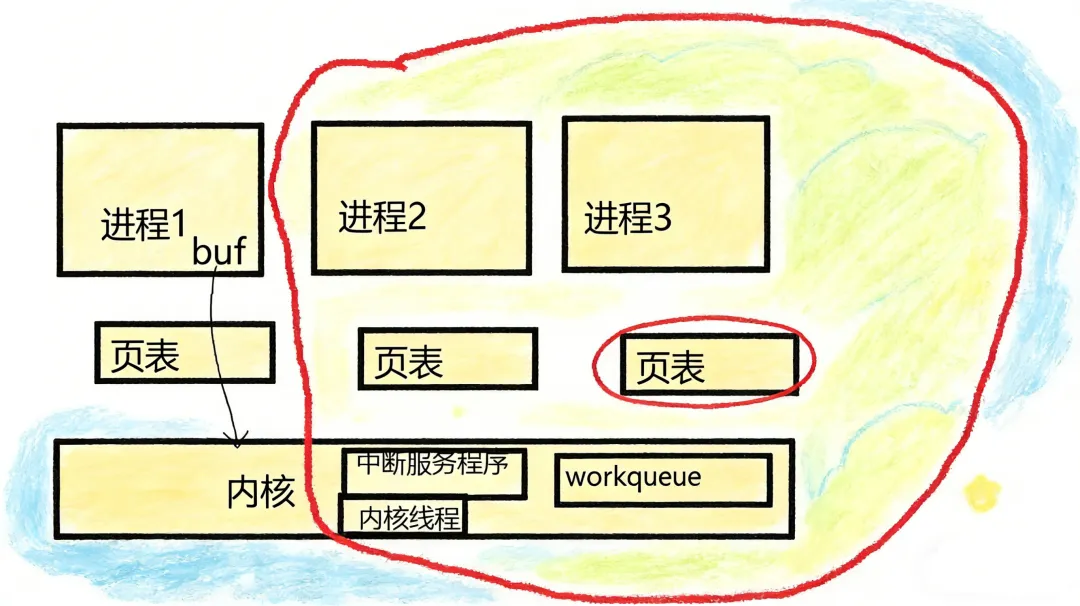
用户态传入的 buffer 地址本质上是虚拟地址,这个地址的有效性完全依赖于当前进程的页表。每个进程都有自己专属的页表,它就像是一本地址翻译字典,负责将虚拟地址映射到实际的物理地址。当我们处于用户态时,进程 A 中的某个函数向内核传递了一个 buffer 地址,此时这个地址在进程 A 的页表中能够准确地找到对应的物理内存。但一旦发生进程切换 ,情况就会变得截然不同。
内核中存在着各种各样的异步场景,比如中断、workqueue、内核线程等,这些场景随时可能导致进程切换。当中断发生时,内核会暂停当前进程的执行,转而处理中断服务程序。在这个过程中,如果内核直接使用了进程 A 传递过来的用户态地址,而此时进程已经切换到了进程 B,那么这个地址在进程 B 的页表中就会变得毫无意义,因为进程 B 的页表中并没有与这个地址对应的映射关系,这就好比拿着一本错误的字典去查单词,必然会导致数据访问错误 。
以 globalmem_write 驱动函数为例,假设我们有如下一段错误示范代码:
struct globalmem_dev { struct cdev cdev; unsigned char *mem; struct mutex mutex;};staticssize_tglobalmem_write(struct file *filp, constchar __user *buf, size_t size, loff_t *ppos){ struct globalmem_dev *dev = filp->private_data; dev->mem = buf; // 这是错误的做法,直接将用户态buf指针赋值给内核态mem return 0;}
在这段代码中,我们直接将用户态的 buf 指针赋值给了内核态的 dev->mem。如果此时有其他进程访问 dev->mem,或者中断服务程序中访问 dev->mem,由于页表已经发生了变化,就会导致严重的数据访问错误,进而可能引发内核崩溃。
1.1.2 内核数据稳定性要求,临时指针不可靠
用户态传入的参数很多时候是栈上的临时变量,它们的生命周期极其短暂。当用户态函数执行时,这些临时变量在栈上被创建,一旦函数执行完毕,栈空间就会被释放,这些临时变量也随之消失。
以 kobject 结构体的 name 设置为例,kobject 结构体在 Linux 内核中用于管理设备对象,其中的 name 指针用于标识设备的名称。假设我们有如下一段错误的代码:
struct device { struct kobject kobj; // 其他成员};voiddriver_func() { char name[100]; // 给name赋值 dev_set_name(&device, name);}voiddev_set_name(struct device *dev, char *name) { dev->kobj.name = name; // 这是错误的做法,直接将name指针指向用户态栈变量}
在这段代码中,dev_set_name 函数直接将 name 指针指向了用户态栈上的临时变量 name。当 driver_func 函数执行完毕,栈上的 name 变量被释放,此时 dev->kobj.name 指向的就是一块已经被释放的内存,设备名也就变成了随机乱码,这对于内核中设备的管理是致命的错误。
正确的做法是,内核必须为这些数据申请一块自己管理的内存区域,这块内存区域是跨进程长期有效的,然后将用户态的数据拷贝到这块内存中,这样才能确保数据的稳定性和可靠性 。
1.2 安全刚需
用户态程序是不可信的,它可能会因为编程错误或者恶意攻击,向内核传入一些非法的地址。这些非法地址可能是越界的,指向了内核空间或者其他进程的敏感区域;也可能是完全错误的,根本没有对应的物理内存映射。如果内核直接使用这些非法地址,就像是打开了一扇毫无防备的大门,让用户态程序可以随意篡改内核的关键数据,这将对整个系统的安全造成极大的威胁 。
拷贝操作的核心作用之一就是进行安全校验。在 Linux 内核中,当处理像 preadv/pwritev 这样的系统调用时,用户会传入一个 iovec 数组,数组中的每个成员描述了一个 buffer 的基地址和长度。内核在接收到这个数组后,并不会直接使用其中的地址,而是会通过 access_ok 函数检查每个 buffer 的地址合法性 。只有在确认地址合法后,内核才会将数据从用户态拷贝到内核空间。这个过程就像是在进入一个重要场所之前,先进行严格的安检,只有通过安检的人才能进入,从而从源头上拦截了非法地址的入侵。
1.3 特殊场景
并非所有场景都需要进行数据拷贝,零拷贝技术就是一种特殊的存在,它为数据交互提供了一条 “绿色通道”。零拷贝技术主要包括 mmap、sendfile、splice 等,它们在特定条件下可以实现用户态与内核态之间的数据零拷贝交互 。
以 sendfile 系统调用为例,它主要用于文件传输场景,当我们需要将文件数据从磁盘发送到网络套接字时,sendfile 可以直接将页缓存中的数据传输到网卡,而无需将数据先拷贝到用户态,再从用户态拷贝到内核态的 socket 缓冲区。
具体过程如下:首先,磁盘数据通过 DMA(Direct Memory Access,直接内存访问)被拷贝到内核缓冲区,也就是页缓存;然后,内核直接将页缓存中的数据描述符(包含内存地址和长度等信息)传递给 socket 缓冲区;最后,网卡的 DMA 控制器根据这些描述符直接从内核缓冲区读取数据并发送出去。
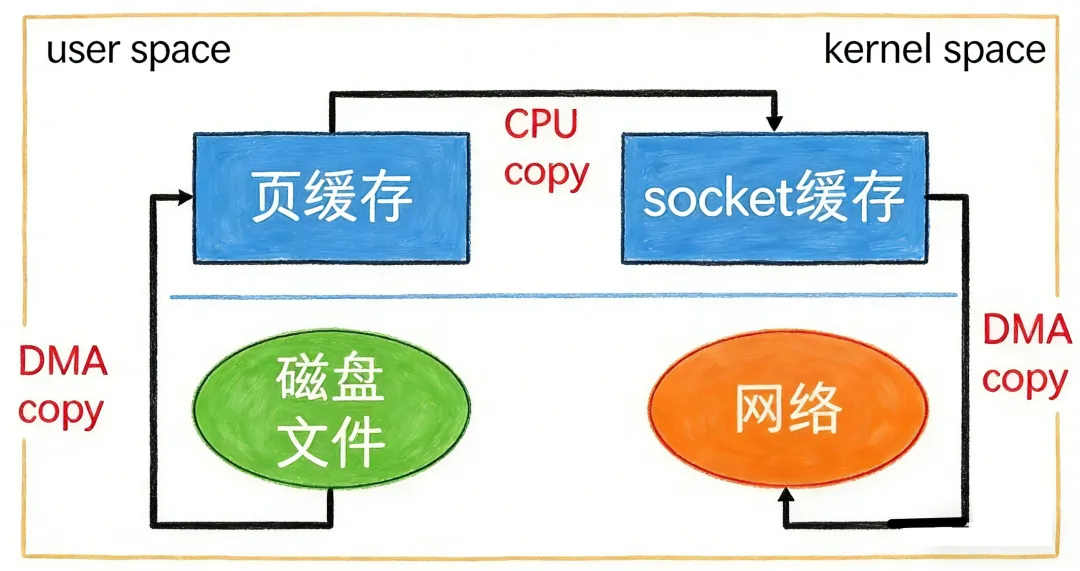
在这个过程中,数据始终在内核空间流转,避免了用户态与内核态之间的数据拷贝,大大提高了数据传输效率 。
零拷贝技术虽然强大,但它仅适用于 “数据无需内核或用户态处理” 的场景。在大多数常规的驱动开发中,我们仍然需要通过拷贝操作来保证数据的安全和稳定传输,零拷贝技术并不能完全替代传统的拷贝方式。
二、 为啥选 copy_from_user,而非 memcpy?
经过前面的分析,我们已经明确了数据从用户态传递到内核态时,拷贝操作是必不可少的。那么接下来,我们就要探讨一下,在众多的拷贝方式中,为什么 Linux 内核要选择使用 copy_from_user 函数,而不是看似更简单直接的 memcpy 函数呢?这背后其实有着深刻的原因,关乎内核的稳定性、安全性以及系统的整体性能 。
2.1 memcpy的固有缺陷:缺乏安全校验机制
memcpy 是 C 标准库中提供的一个通用内存拷贝函数,它的功能非常简单直接,就是将一块内存区域的数据逐字节地拷贝到另一块内存区域。其函数原型为void *memcpy(void *dest, const void *src, size_t n),其中dest是目标内存地址,src是源内存地址,n是要拷贝的字节数。在用户态编程中,memcpy 是一个非常常用的函数,它简单高效,能够满足大多数的内存拷贝需求 。
然而,当我们将 memcpy 函数应用到内核态与用户态的数据拷贝场景时,就会暴露出严重的问题。memcpy 函数设计时并没有区分内核态地址和用户态地址,它只是机械地按照给定的地址进行数据拷贝。这就意味着,如果用户态程序不小心传入了一个非法的地址,比如一个指向内核空间的地址,或者是一个越界的用户态地址,memcpy 函数并不会察觉到这些问题,而是会继续执行拷贝操作 。
这种行为会带来极大的风险。如果拷贝的源地址是一个非法的内核空间地址,memcpy 函数可能会将内核空间中的关键数据覆盖,导致内核数据结构被破坏,从而引发系统崩溃。如果源地址是一个越界的用户态地址,memcpy 函数可能会访问到未分配的内存区域,这同样会导致内核出现错误,引发 oops 错误,使系统陷入不稳定状态 。
2.2 copy_from_user的核心优势
与 memcpy 函数不同,copy_from_user 函数是专门为内核态与用户态之间的数据拷贝设计的,它具备了一系列的安全机制,能够有效地避免上述风险,主要体现在以下两个关键步骤。
2.2.1 第一步:access_ok 地址安检,过滤非法指针
从 copy_from_user 的源码逻辑来看,它采用了 “先检查,后拷贝” 的策略。在进行实际的数据拷贝之前,copy_from_user 会先通过 access_ok 宏对用户态传入的源地址进行合法性检查 。access_ok 宏的作用是判断给定的用户态地址是否在当前进程的合法地址范围内,即是否在current_thread_info()->addr_limit所限定的地址范围内。如果地址超出了这个范围,就说明该地址是非法的 。
具体的实现方式如下,在include/asm/uaccess.h文件中,access_ok宏的定义如下:
#define access_ok(type,addr,size) (__range_ok(addr,size) ==0)#define __range_ok(addr,size) ({ \ unsigned long flag, roksum; \ __chk_user_ptr(addr); \ __asm__("adds %1, %2, %3; sbcccs %1, %1, %0; movcc %0, #0" \ : "=&r" (flag), "=&r" (roksum) \ : "r" (addr), "Ir" (size), "0" (current_thread_info()->addr_limit) \ : "cc"); \ flag; })
这段代码通过汇编指令,将源地址addr加上要拷贝的长度size,然后与current_thread_info()->addr_limit进行比较,如果相加后的结果超过了addr_limit,则说明地址越界,返回非零值,表示地址非法;否则返回零,表示地址合法 。
如果access_ok检查发现地址非法,copy_from_user 函数会直接返回错误码,并将目标内存区域置零,以防止内核访问到危险的地址,从而保护了内核的安全。这种地址合法性检查机制是 memcpy 函数所不具备的,它为内核与用户态之间的数据传输提供了第一道安全防线 。
2.2.2 第二步:缺页异常优雅处理,避免内核 oops
除了地址合法性检查之外,copy_from_user 函数还具备处理缺页异常的能力,这是它的另一个重要优势。在用户态,虚拟地址到物理地址的映射是通过页表来实现的,当一个虚拟地址尚未被分配对应的物理页时,访问该地址就会触发缺页异常 。
在使用 memcpy 函数进行数据拷贝时,如果遇到源地址对应的虚拟页尚未分配物理页的情况,由于 memcpy 函数本身没有处理缺页异常的机制,它会直接导致内核 oops 错误,使系统崩溃 。而 copy_from_user 函数则不同,它的汇编实现中包含了针对缺页异常的处理逻辑 。
以 ARM 架构为例,在arch/arm/lib/copy_from_user.S文件中,我们可以看到如下代码:
ENTRY(__copy_from_user) stmfd sp!, {r4 - r7, lr} mov r7, r0 @ destination mov r6, r1 @ source mov r5, r2 @ nbytes sub r4, r0, r1 @ difference1: cmp r5, #0 @ if nbytes == 0, we're done ble 9f ldr r3, [r6], #4 @ load word from source str r3, [r7], #4 @ store word to destination subs r5, r5, #4 @ subtract 4 from nbytes b 1b9: ldmfd sp!, {r4 - r7, pc}.poolENDPROC(__copy_from_user).pushsection .fixup,"ax".align 0copy_abort_preamble ldmfd sp!, {r1, r2} sub r3, r0, r1 rsb r1, r3, r2 str r1, [sp] bl __memzero ldr r0, [sp], #4copy_abort_end.popsection
在这段代码中,.pushsection .fixup,"ax"和.popsection之间的部分就是用于处理缺页异常的fixup段。当发生缺页异常时,程序会跳转到fixup段中预设的修复地址继续执行,通过一系列的操作,如将未拷贝的数据清零等,确保内核的稳定运行,而不会因为缺页异常而导致系统崩溃 。
2.3 常见误区:memcpy正常运行并非安全,而是偶然现象
在某些情况下,直接使用 memcpy 函数来拷贝用户态数据到内核态,并没有出现死机等问题,于是就产生了一种误解,认为 memcpy 函数也可以用于这种场景 。但实际上,这种情况往往只是一种偶然,是因为在这些特定的情况下,用户态地址恰好已经分配了对应的物理页,并且没有发生地址越界等非法情况,所以 memcpy 函数才能够 “侥幸” 地正常工作 。
这种 “运气好” 的情况并不能代表 memcpy 函数在这种场景下是安全可靠的。一旦系统的运行状态发生变化,比如系统负载增加导致内存页被频繁换出和换入,或者用户态程序出现错误传入了非法地址,memcpy 函数的缺陷就会立刻暴露出来,导致系统出现严重的问题 。
从内核开发的严谨性和系统的稳定性角度考虑,绝不能依赖这种 “运气” 来编写代码,而应该始终使用像 copy_from_user 这样专门为内核与用户态数据传输设计的函数,以确保系统的安全和稳定 。
 10个月宝宝每天需要喝多少奶粉?
10个月宝宝每天需要喝多少奶粉?
