python学习【159】:揭秘文件上传下载与断点续传原理:从HTTP Range到Flask实战
一、学前花絮
在日常使用网盘、迅雷等工具时,我们常惊叹于“断点续传”的便捷——即使下载中途断开,再次点击仍能从上次中断处继续。这背后的核心技术是什么?本文将深入解析文件传输原理,并通过Python Flask实现一个带断点续传功能的简易系统,带你亲手揭开其神秘面纱。。二、Python实现文件的上传下载及断点续传
2.1 文件传输的基石:HTTP协议与Socket
无论是上传还是下载,底层均依赖TCP/IP协议,而HTTP协议则定义了数据传输的规则:上传:客户端通过PUT或POST请求将文件数据发送至服务器(如表单上传)。下载:客户端通过GET请求获取服务器文件,数据以二进制流形式传输。Socket作为网络通信的端点,负责建立客户端与服务器的连接,确保数据有序传输。但当传输大文件时,网络波动可能导致连接中断,此时“断点续传”便成为刚需。2.2 断点续传的核心原理:HTTP Range请求
1. 传统下载的痛点
若不使用断点续传,客户端每次下载都会从头请求文件。一旦中断,需重新传输全部数据,浪费带宽和时间。2. Range请求的魔法
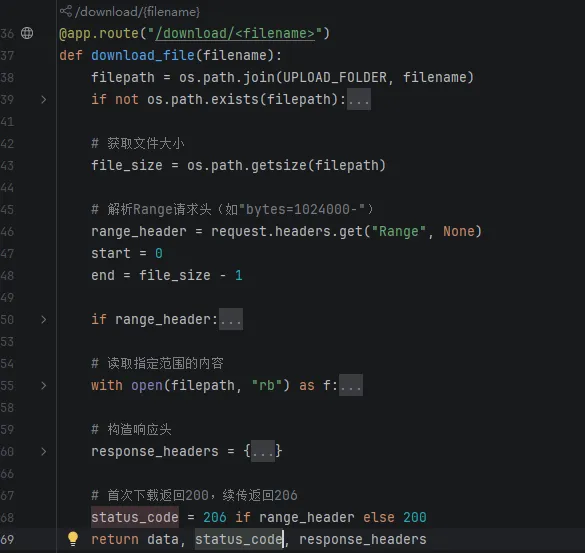
HTTP/1.1引入的Range头部解决了这一问题:客户端:发送请求时指定Range: bytes=起始字节-结束字节(如Range: bytes=1024000-表示从1MB处开始下载)。服务器:若支持断点续传,返回206 Partial Content状态码,并通过Content-Range头部告知当前传输范围(如Content-Range: bytes 1024000-2047999/2048000表示传输了第1MB到第2MB的数据,总大小2MB)。- 客户端首次请求:GET /file.zip → 服务器返回200 OK(完整文件)
- 中断后再次请求:GET /file.zip + Range: bytes=已下载大小- → 服务器返回206 Partial Content(剩余文件)
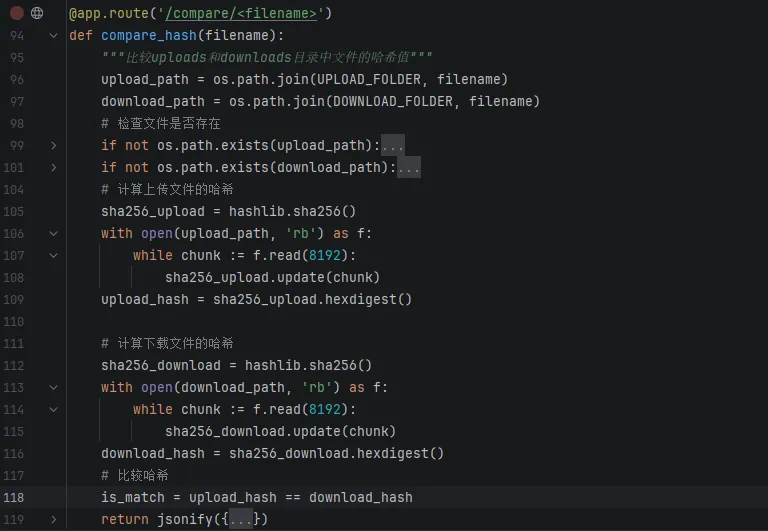
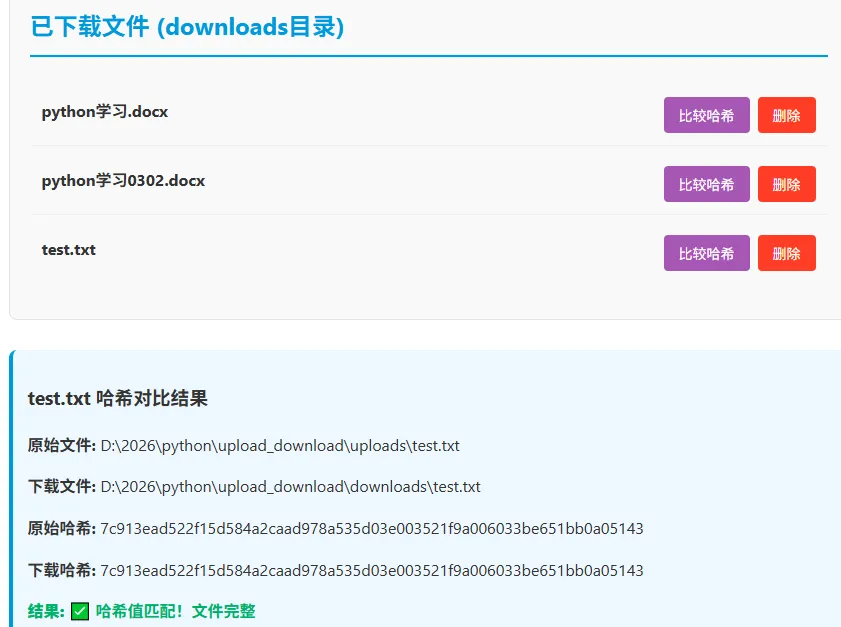
2.3 文件完整性校验:哈希值的妙用
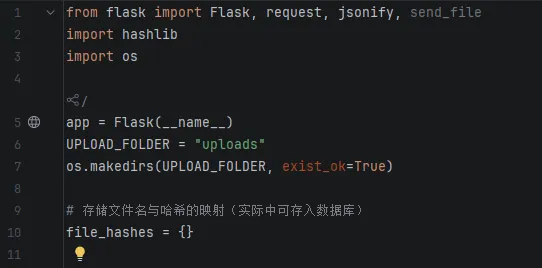
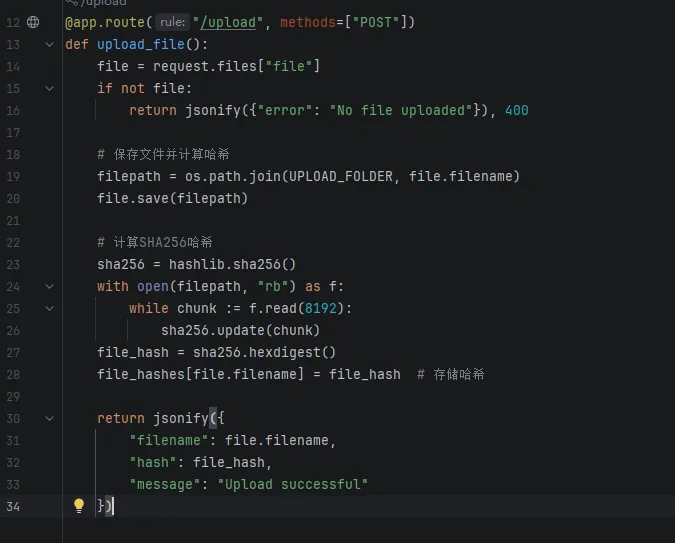
生成哈希:上传文件时,服务器计算文件哈希值(如SHA256)并存储。下载校验:客户端下载完成后,重新计算哈希值并与服务器存储的原始哈希比对。哈希算法特点:相同文件哈希值必相同,不同文件哈希值几乎不可能相同(雪崩效应)。2.4 Flask实战:实现上传下载与断点续传
下面通过Python Flask构建一个简易系统,包含以下功能:1. 系统设计
- 前端:HTML表单(上传/下载按钮)+ 哈希对比结果显示
- 存储:本地文件系统暂存上传文件,内存存储文件名与哈希映射
2. 核心代码实现
(1)上传文件与计算哈希
上面的代码是模块导入及上传文件夹的初始化定义,下面是逻辑实现:(2)断点续传下载
(3)哈希对比接口
(4) 前端界面(简化版)
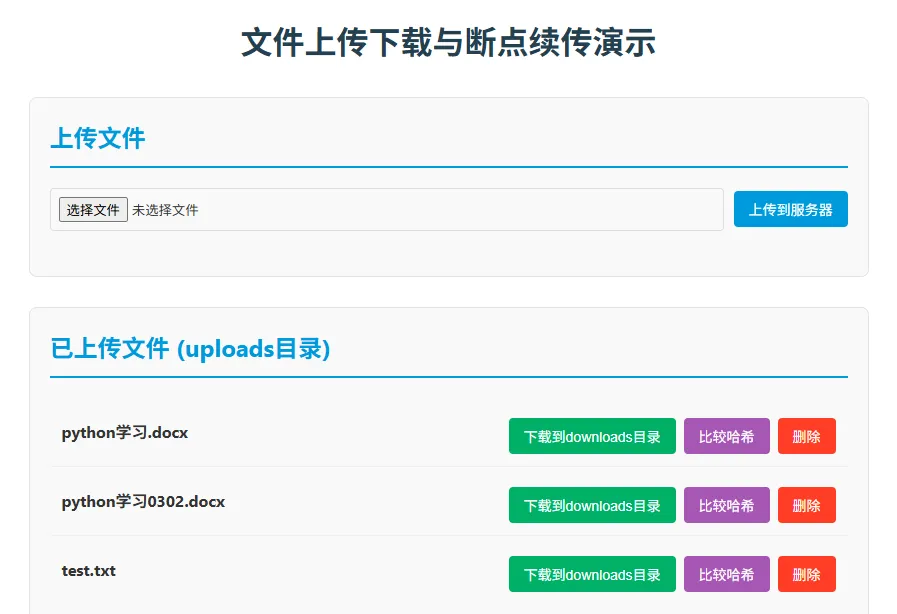
运行结果,在浏览器上输入http://127.0.0.1:5000/:上述代码实现了从本机选择文件上传到服务器uploads目录,然后从服务器下载到本机downloads目录。最后比较两个目录中相应文件的hash值确认下载完整。2.5 总结与思考
- HTTP Range请求:实现断点续传的关键,通过指定字节范围避免重复传输。
- 哈希校验:确保文件完整性,防止传输过程中数据损坏。
三、小结
今天学习了用python实现文件的上传下载及断点续传。这种功能在实际生活、工作中经常遇到,有很多的应用可以实现此类功能。我们只是从原理上了解其实现原理,让python学习更贴近实际。在实际开发中,还需考虑服务器兼容性、并发控制、安全性(如校验文件类型)等问题。但万变不离其宗,掌握上述原理后,即可灵活应对各类文件传输场景。让我们保持学习的热情,2026年一马当先、马到成功!