90%运维人员生产上会遇到的Linux问题
- 2026-06-23 11:33:41
作为一名Linux运维人员,在生产上必定会遇到各种各样的运维问题,在恢复业务过程中,花费大量时间进行排错。为了提升故障处理效率,今天本文给大家分享生产上常见的Linux问题和解决思路,看看大家踩中几条。
一、/etc/fstab配置编写错误,重启后进入不了系统
在生产中,不可避免的会涉及新增块设备和逻辑卷、自动挂载ISO镜像或NFS服务。fstab配置如写的有问题,就会出现重启无法进入系统。尤其是生产环境,服务器一般都不重启,当时修改配置并不会影响系统正常运行。但是重启后会重新加载配置,造成系统挂死。修改这个配置可能是星期、月甚至更久之前的事,在后续在排查问题时,需要花费很长时间才能定位出来。
常见的错误:
(1)defaults写成default
(2)挂载点路径不存在或写错。
配置详解:
/etc/fstab里每一行共6个字段,用空格或Tab分隔,格式固定:
<设备> <挂载点> <文件系统> <挂载选项> <dump备份> <fsck检查顺序>

(1)第1个字段:要挂载的设备(必填)
可以写这几种:
/dev/sda1、/dev/vdb1 #裸设备挂载UUID=xxx-xxx-xxx-xxx-xxx #UUID挂载,一般/boot路径使用此挂载方式/dev/mapper/ #逻辑卷 逻辑卷挂载
(2)第2字段:挂载点(必填)
磁盘要挂载到哪个目录:
根目录:/
引导:/boot
交换分区:swap
数据盘:/data、/www 等自定义目录
(3)第3字段:文件系统类型(必填)
xfs:CentOS7+默认
ext4:通用Linux分区
swap:交换分区
iso9660:镜像
nfs:共享文件
写错就会挂载失败,进不了系统。
(4)第4字段:挂载参数(必填)
多个参数用逗号分隔:
defaults:默认
loop:表示把文件当成块设备挂载,一般用于ISO镜像
nofail:磁盘不存在或者连不上也不阻止开机(强烈推荐NFS服务、自己新增挂载配置加上这个)
(5)第5字段:是否备份
一般就两个值:
0:不备份(绝大多数场景)
1:需要 dump 备份(几乎不用)
生产统一写0 即可。
(6)第6字段:开机检测
开机fsck 磁盘检查顺序,决定开机要不要自检、谁先检查:
0:不检查(数据盘、U 盘、移动硬盘都写0)
1:根分区/专用,只允许根写1
2:其他需要检查的 Linux 分区(如 /boot,/home等)
二、服务器路由丢失或异常
常见错误:
(1)通过route add添加临时路由,重启后丢失
(2)双网卡均配置网关,产生2条默认路由。一个操作系统里面,只允许有一个网段,其它网卡只能配置明细。否则,会引发路由异常。
解决思路:
(1)查看当前系统的网卡配置,执行命令:
ip a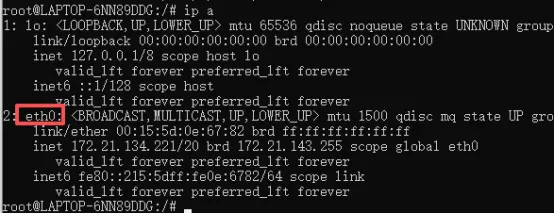
在/etc/sysconfig/network-scripts/文件夹下,新增“route-网卡名”文件,例如:route-eth0
(2)添加路由配置
10.0.0.0/24 via 192.168.1.1 dev eth0#表示到10.0.0.0/24,通过网卡eth0
三、SSH登录不上,服务器拒绝登录
常见原因:
(1)hosts.allow和hosts.deny配置异常
(2)SSH配置文件,禁用root登录
(3)账号过期被锁定
解决思路:
(1)针对第一个问题,系统默认先检查hosts.allow文件,再检查hosts.deny文件。allow文件里面是允许的IP,deny文件里面是拒绝的IP,如果都没有配置默认允许。
配置格式:
sshd:IP地址或者IP网段例如,sshd:192.168.1.0/24,如果在hosts.allow表示允许这个地址段登录,在hosts.deny表示拒绝这个地址段登录。
(2)针对第二个问题,编辑SSH配置文件/etc/ssh/sshd_config,查看如下配置是否设置为no,然后重启下ssh服务。强烈建议不允许root登录。
PermitRootLogin nosystemctl restart sshd
(2)针对第三个问题,需要进入到root账号下,重置过期账户。如果root账户也过期,就需要进入单用户模式下,重置root账户过期问题,重置方式见之前公众号文章。国产操作系统 root 密码丢失?欧拉龙蜥一篇搞定进入到系统里面后,执行如下命令解决账号过期:
chage -E -1 用户名#账号永不过期四、已删除文件占用磁盘空间不释放
删除了文件,但句柄没释放,空间不还回磁盘。主要原因是Linux文件有2种属性,一个是目录项(也就是文件名称)、一个是索引节点(inode)。执行rm命令只是删除了目录项,但是inode还在。所以,df -h空间不释放,而执行du -sh看到的inode已经变小。
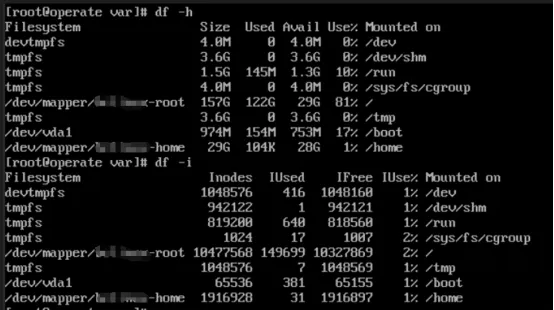
常见原因:
进程还在持有被删除文件的句柄→ 文件不会真正删除 → 空间不释放。
解决思路:
(1)查看是哪个进程占用已删除文件
lsof | grep deleted
如有输出内容,表示有进程占用
(2)杀掉占用对应进程的ID
kill -9 PID
(3)执行df -h查看空间是否有变化。
五、进程被OOM杀死(Out of Memory)
系统内存不够用了,内核为了保系统不宕机,挑了个进程杀掉。
排查思路:
(1)执行命令:dmesg | grep -i "oom",如果看到类似如下内容,表示被OOM杀死。
Out of memory: Killed process 1234 (java)(2)临时增加swap内存,缓解内存压力
# 创建 4G swap
dd if=/dev/zero of=/swapfile bs=1G count=4chmod 600 /swapfilemkswap /swapfileswapon /swapfile
(3)调整OOM优先级,保护重点进程
echo -1000 > /proc/[PID]/oom_score_adj #替换[PID]为真实需要保护的ID(4)排查内存泄露原因,并针对应用进行限制内存上限。
六、文件句柄、进程数不足
常见原因:
(1)文件句柄不足,报错信息:too many open files,进程打开的文件/连接太多,超过系统限制。
(2)进程数不足,报错信息:fork: retry: Resource temporarily unavailable,
用户能创建的进程/线程数超限。
解决思路:
(1)进入到/etc/security/文件夹下,编辑limits.conf文件,末尾添加如下内容:
# 全局软硬限制* soft nproc 65535* hard nproc 65535* soft nofile 65535* hard nofile 65535# root 单独加强root soft nproc 65535root hard nproc 65535root soft nofile 65535root hard nofile 65535
解释:
nproc:最大进程 / 线程数
nofile:最大文件句柄数
soft:警告线
hard:天花板
(2)修改系统全局句柄限制,编辑/etc/sysctl.conf文件。
fs.file-max = 1000000
(3)生效配置
sysctl -p
七、Linux文件系统损坏
产生原因:
异常掉电,文件系统正在写元数据(目录项、inode、分配块)时中断,导致:目录错乱、文件大小不对、孤儿文件、inode 位图不一致。
解决思路:
(1)磁盘进行解挂载,避免对数据产生影响。以sda1为例:
umount /dev/sda1
(2)修复前预检查
fsck.ext4 -n /dev/sda1
(3)对分区进行修复,使用fsck命令。如果是根目录故障或者xfs文件系统故障,则需要使用xfs_repair命令修复。
#非根目录fsck.ext4 -y /dev/sdb1#xfs文件系统或根目录xfs_repair /dev/sda1
(4)重新挂载硬盘
mount /dev/sda1 /data
八、网络服务不通
产生原因:
(1)firewalld未放行网络服务;
(2)iptables未放行网络服务;
注意,iptables和firewalld不要同时出现,避免出现安全策略混乱问题。推荐Linux7和7之前版本之前使用iptables,Linux8及以上使用firewalld。
解决思路:
(1)firewalld放行网络服务
firewall-cmd --permanent --add-port=80/tcpfirewall-cmd --permanent --add-port=443/tcpfirewall-cmd --permanent --add-port=22/tcpfirewall-cmd --permanent --add-port=8080/tcp
(2)重载生效配置
firewall-cmd --reload(3)iptables放行网络策略
iptables -A INPUT -p tcp --dport 80 -j ACCEPTiptables -A INPUT -p tcp --dport 443 -j ACCEPTiptables -A INPUT -p tcp --dport 22 -j ACCEPTiptables -A INPUT -p tcp --dport 8080 -j ACCEPT
(4)保存iptables策略,避免重启后失效
iptables-save > /etc/sysconfig/iptables九、内核态CPU高,频繁切换上下文
产生原因:
(1)多线程抢同一把锁或线程数高
(2)网卡进行大量网络收发、短连接;
(3)磁盘 IO 密集
解决思路:
(1)查看整体CPU使用率,执行命令:top
重点关注us、sy和si三个指标

(2)查看上下文切换,重点关注cswch/s和vncswch/s这两列数值,执行指令:
pidstat -w
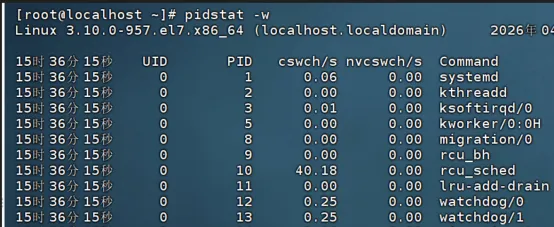
(3)执行iostat查看磁盘IO情况
iostat
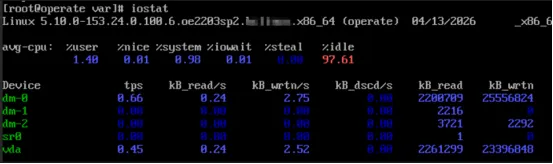
问题判定:
(1)锁竞争激烈和网络风暴
表现:
sy 高(内核态 CPU)
cswch/s 极高
软中断si也高
us 不高、iowait不高
(2)高频磁盘IO/大量小文件读写
表现:
sy高
cswch/s高
wa (iowait)高
pidstat -d看到读写很高
(3)线程/进程数量过多,或服务器CPU配置不足
表现:
sy 明显高
cs 系统上下文切换几十万
cswch/s + nvcswch/s 双高
【结束语】
评论区有文章总结!觉得好可以关注、点赞、推荐、转发,谢谢!

