tsfresh 是一个Python包。专门用于构建时间序列特征(包含均值、方法、偏度和自相关性等)。此外,该包还可用于在分类或回归任务中解释特征重要性。
tsfresh的主要特点:
- 与Python库pandas和scikit-learn兼容
tsfresh的局限性:
- 在线操作的数据不适用(也称流式数据),时间序列数据通常用于离线操作
- 不包含模型训练的功能(训练模型请使用其他包,如scikit-learn)
- 仅考虑时序的顺序性,对时间间隔差异较大的情况不适用
1 安装
如果处理的数据量太大,不适合放入内存处理,安装tsfresh Dask
pip install tsfresh[dask]
大型时间序列数据面临的最重要两个问题是:①特征提取执行时间过长(一般可以采用“并行化”处理),②内存消耗巨大,可能超出单台机器的处理能力
tsfresh的 tsfresh.extract_features() 函数接受dask dataframe作为输入,允许将计算扩展到本地内存之外。可以直接替代pandas dataframe
2 使用
提取所有特征,执行操作:
from tsfresh import extract_featuresextract_features_res = extract_features(dataframe,column_id="id",column_sort="time")
最终得到一个名为extract_features_res的dataframe。剔除所有NaN值,然后仅选择与目标变量y相关的特征
from tsfresh import select_featuresfrom tsfresh.utilities.dataframe_functions import imputeimpute(extract_features_res)features_filtered = select_features(extract_features_res,y)
甚至可以同时执行提取、插补、过滤操作:
from tsfresh import extract_relevant_featuresfeatures_filitered_direct = extract_relevant_features(dataframe,y, column_id="id",column_sort="time")
利用提取的特征训练一个随机森林分类器代码示例:https://github.com/blue-yonder/tsfresh/blob/main/notebooks/01%20Feature%20Extraction%20and%20Selection.ipynb
3 tsfresh支持的数据格式
tsfresh提供了三种不同的选项来指定要与该函数一起使用的时间序列数据的格式,但无论输入数据格式如何,tsfresh始终以相同输出格式返回计算出的特征
3.1 输入数据
在调用tsfresh包中的特征工程构建时,需要指定四个关键参数:column_id(必需), column_sort(必需), column_value(可选), column_kind(可选)。以机器人故障数据集为例进行说明:
这种情况下,column_id对应机器人的唯一编号(此列指时间序列所属的实体),column_sort每个机器人传感器测量值的时间戳(此列包含用于对时间序列进行排序的值),column_value对应机器人上不同传感器的测量值,column_kind对应传感器的类型。
【重要】这些列均不允许包含NaN、Inf或-Inf值
tsfresh支持三种不同的时间序列数据格式:
1.Flat DataFrame or Wide DataFrame(宽数据框)
column_id="id", column_sort="time", column_kind=None, column_value=None` #column_kind,column_value可省略不写
2.Stacked DataFrame or Long DataFrame(长数据框)
column_id="id", column_sort="time", column_kind="kind", column_value="value"
3.Dictionary of flat DataFrames
格式如下:
{'x':DataFrame(x),'y':DataFrame(y)}
其中 DataFrame(x) 具体如下所示:
其中 DataFrame(y) 具体如下所示:
column_id="id", column_sort="time", column_kind=None, column_value="value" #column_kind不需要指定,就是相应的字典键
3.2 输出特征
对于三种输入数据格式,最终得到的特征矩阵都是相同的。始终是一个pandas.DataFrame,示例如下:
特征命名规则:
{time_series_name}__{feature_name}__{parameter name 1}_{parameter value 1}__[..]__{parameter name k}_{parameter value k}
特征命名示例:
temperature__quantile__q_0.6
4 功能
4.1 特征提取
tsfresh提供2种方式进行特征提取:
- 默认方式:直接调用
tsfresh.extract_features() 而不传递参数(default_fc_parameters 和 kind_to_fc_parameters ),将使用 ComprehensiveFCParameters ,提取所有可以默认返回的特征 - 自定义方式:通过一个字典(
fc_parameters)精确控制。字典的键是特征函数名,值是该函数的参数列表(无参数则为None)
# 示例:提取 length 特征,以及两个不同参数的 large_standard_deviation 特征fc_parameters = { "length": None, "large_standard_deviation": [{"r": 0.05}, {"r": 0.1}] }
预定义设置:
ComprehensiveFCParametersMinimalFCParametersEfficientFCParameters
高级用法:使用 kind_to_fc_parameters 参数,为不同类型的时间序列(如“temperature”、“pressure”)分别指定特征
实用技巧:通过 from_columns() 方法,可以从已筛选的特征矩阵的列名反向生成设置字典,避免重复计算无用特征
11121314# 示例X_tsfresh = extract_features(...) # 提取全量特征X_filtered = some_feature_selection(X_tsfresh) # 特征筛选# 自动生成设置,只计算筛选后需要的特征kind_to_fc_parameters = from_columns(X_filtered)
tsfresh内置特征的详细列表:https://tsfresh.readthedocs.io/en/v0.17.0/text/list_of_features.htmltsfresh内置特征的详细源码:https://github.com/blue-yonder/tsfresh/blob/v0.17.0/tsfresh/feature_extraction/feature_calculators.py
当内置特征不满足需求时,可通过编写自己的特征计算函数,实现扩展自定义特征:
- combiner:返回多个特征值(效率更高,可共享中间计算)
- 步骤2:编写函数:使用
@set_property("fctype","...") 装饰器声明类型,并按模板编写
1.无参数的simple特征
from tsfresh.feature_extraction.feature_calculators import set_property@set_property("fctype", "simple")def your_feature_calculator(x): # x时pandas.Series类型的时间序列 result = ... #计算逻辑,结果为float、int或bool return result
2.带参数的simple特征
@set_property("fctype", "simple")def your_feature_calculator(x, p1, p2): # x: 时间序列, p1, p2: 参数 result = ... return result
3.combiner特征(返回多个值)
from tsfresh.utilities.string_manipulation import convert_to_output_format@set_property("fctype", "combiner")def your_feature_calculator(x, param): # param: 参数列表,每个元素是一个字典,对应一组参数组合 results = [] for config in param: value = ... # 计算该组参数对应的特征值 # convert_to_output_format 将参数字典转为字符串标识 results.append((convert_to_output_format(config), value)) return results
特殊类型:基于时间的特征如果特征计算需要用到时间序列的时间索引(例如DatetimeIndex),需要额外设置两个属性:
@set_property("input", "pd.Series") # 声明输入是含索引的 Series@set_property("index_type", pd.DatetimeIndex) # 声明索引类型def timespan(x, param): # 可以直接使用 x.index 获取时间索引进行计算 times_seconds = (x.index[-1] - x.index[0]).total_seconds() return times_seconds / 3600.0
- 步骤3:加入设置:将自定义函数作为键添加到设置字典中,并传递给
extract_features() ,否则不会被调用
from tsfresh.feature_extraction import extract_featuresfrom tsfresh.feature_extraction.settings import ComprehensiveFCParameters# 创建设置对象(可选用 ComprehensiveFCParameters 等)settings = ComprehensiveFCParameters()# 将你的函数加入设置字典# 若无参数:值为 Nonesettings[your_feature_calculator] = None# 若有参数:值为一个列表,包含你想使用的所有参数组合(字典形式)# settings[your_feature_calculator] = [{"p1": 1, "p2": 2}, {"p1": 3, "p2": 4}]# 调用提取函数时传入 custom settingsextract_features(df, default_fc_parameters=settings)
4.2 特征过滤
特征选择的核心问题时识别所有强相关和弱相关特征,为了限制不相干特征的数量,tsfresh部署了fresh算法,该算法由 tsfresh.feature_selection.relevance.calculate_relevance() 调用。它是一种高效、可扩展的特征提取算法,在机器学习流程的早期阶段,根据特征对分类或回归任务的重要性对可用特征进行筛选,同时控制所选但不相关特征的预期百分比。
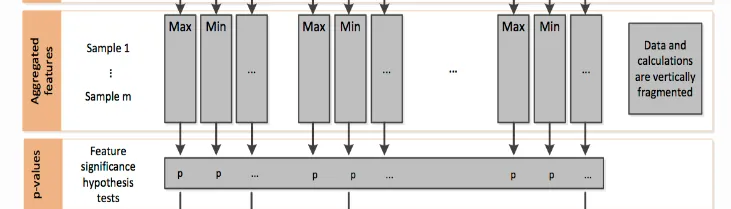
对提取的每个特征进行单独且独立的评估,确定该特征对预测目标的重要性。这些测试位于子模块 tsfresh.feature_selection.significance_tests 中,测试结果是一个p值向量,用于量化每个特征对预测标签/目标的重要性。(如下图)
计算出每个特征对应的p值后,在基于Benjamini-Yekutieli 方法对p值向量进行评估,以确定保留哪些特征。该多重检验方法来自statsmodel包
tsfresh内置假设检验的源码:https://github.com/blue-yonder/tsfresh/blob/v0.17.0/tsfresh/feature_selection/significance_tests.py
4.3 进阶:大型时间序列数据处理
大型时间序列数据存在问题:
解决方案:
- 使用分布式计算框架(如Dask、Spark),将数据分块、计算分布式化,同时关闭高开销的“透视”操作,实现在有限资源下处理大型时间序列数据
tsfresh解决方案:使用Dask
Dask DataFrame的API与pandas类似,可直接将Dask DataFrame传给 tsfresh.extract_features()
import dask.dataframe as ddfrom tsfresh import extract_features# 读取数据(例如从 Parquet 文件)df = dd.read_parquet("your_large_data.parquet")# 进行特征提取,关键参数 pivot=False 可避免性能瓶颈X = extract_features(df, column_id="id", # 标识时间序列的列 column_sort="time", # 排序用的时间列 pivot=False) # 推荐关闭透视,节省计算# 触发实际计算result = X.compute()
【注】特征提取的最后一步是将结果转为表格形式(pivot),这对大数据集时性能瓶颈,若不需要完整表格,设置 pivot=False ,以未透视的格式处理数据
若需要优化计算图,可使用底层绑定函数,手动控制数据格式:
from tsfresh.convenience.bindings import dask_feature_extraction_on_chunk# 注意:df_grouped 必须已经是 tsfresh 所需的正确格式features = dask_feature_extraction_on_chunk(df_grouped, column_id="id", column_kind="kind", column_sort="time", column_value="value")# 此模式下不会进行透视操作
其他方案:PySpark
官方文档提到也支持PySpark,可以通过类似 tsfresh.convenience.bindings.spark_feature_extraction_on_chunk() 的函数,将特征提取整合到Spark计算图中,适合已在使用Spark生态系统的用户
相关资源
- 官方文档:https://tsfresh.readthedocs.io/en/latest
- 官方代码:https://github.com/blue-yonder/tsfresh/tree/main/tsfresh
- tsfresh特征模块翻译:https://github.com/SimaShanhe/tsfresh-feature-translation

 10个月宝宝每天需要喝多少奶粉?
10个月宝宝每天需要喝多少奶粉?
