今天我们来思考一个既简单又深奥的问题:当你按下回车键,一个程序是如何从磁盘文件变成进程,在Linux系统中跑起来的?
有没有停下来想过:
从你写下的那行printf/cout/println!,到终端输出字符,这中间到底发生了什么?
为什么少个分号就直接编译失败,而死循环代码却能顺利生成可执行文件?
为什么明明本地跑的好好的代码,放到服务器上就报一堆undefined reference?
为什么程序好好的突然就Segmentation fault了?
为了贴近现代开发,我们不拿简单的C语言“Hello World”举例,而是选择全宇宙最安全的Rust语言程序来作为我们的剖析对象。
// main.rsfn main() { println!("Hello, Rustacean!");}
我们在写完代码后,Cargo(Rust的构建系统)会帮我们搞定编译链接的所有细节——这一点和C语言手动调用gcc不同,Cargo会自动处理依赖、调用编译器(rustc)和链接器(ld),然后在shell命令行下把它启动起来。
# cargo build --release# ./target/release/hello_rustHello, Rustacean!
这两行简单的命令背后,操作系统到底做了哪些操作?
当我们的Rust代码经过编译器(rustc)和链接器(ld)的处理后,最终生成了一个可执行文件。和C语言一样,在Linux的世界里,这个文件遵循一种名为ELF的格式标准——这是Linux下二进制文件的事实标准,无论你用C、C++还是Rust编写代码,最终生成的可执行文件、目标文件(.o)、动态链接库(.so)、核心转储文件(Core Dump),都遵循ELF格式规范。
我们首先使用file命令来看一下这个文件的格式:
# file hello_rusthello_rust: ELF 64-bit LSB executable, x86-64, version 1 (SYSV), dynamically linked, interpreter /lib64/ld-linux-x86-64.so.2, for GNU/Linux 3.2.0, BuildID[sha1]=xxxxxx, not stripped
file命令的输出和C语言生成的ELF文件高度相似,核心信息一致:这是一个64位、小端序(LSB)的ELF可执行文件,运行在x86-64架构上,采用动态链接方式,依赖的动态链接器是/lib64/ld-linux-x86-64.so.2。唯一的细微差异在于Rust生成的ELF文件会包含BuildID等额外标识,用于区分不同的构建版本,这是Cargo构建系统自动添加的。
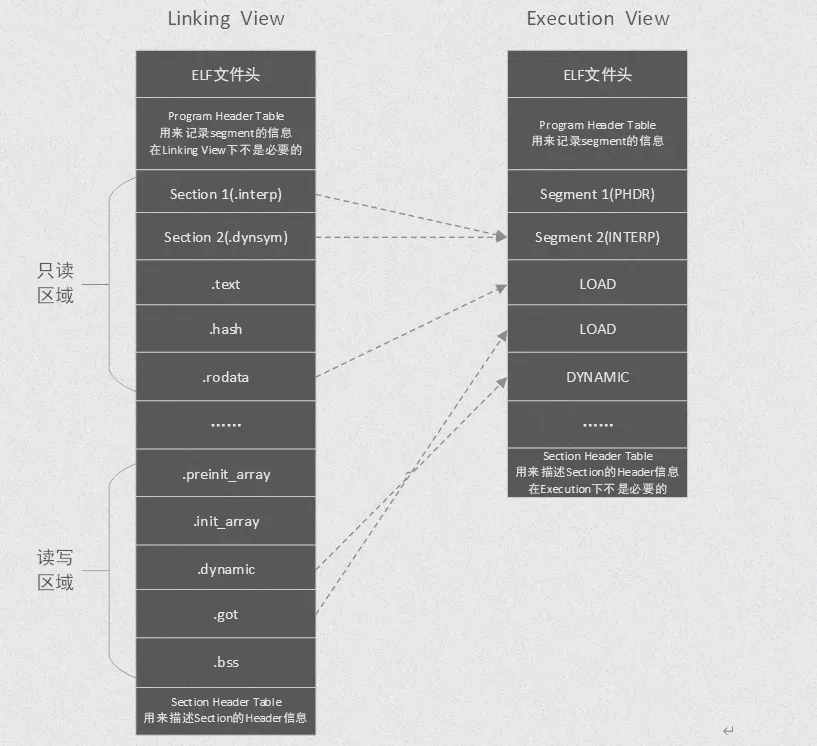
一个ELF文件主要由四部分组成,这一点和C语言生成的ELF完全一致,也是内核能够加载并执行它的核心基础:ELF文件头(ELF Header)、程序头表(Program Header Table)、节区(Sections)和节区头表(Section Header Table)。这四部分共同构成了可执行文件的“骨架”。
1.1 ELF文件头
ELF文件头位于文件的最开头,固定大小(64位系统下为64字节),记录了整个文件的核心属性,是内核识别并加载这个文件的第一手依据——内核在加载文件时,会先读取这部分内容,确认文件的合法性和基本信息,再决定是否继续加载。和C语言一样,我们可以使用readelf -h命令来查看它的详细内容:
# readelf -h hello_rustELF Header: Magic: 7f 45 4c 46 02 01 01 00 00 00 00 00 00 00 00 00 Class: ELF64 Data: 2's complement, little endian Version: 1 (current) OS/ABI: UNIX - System V ABI Version: 0 Type: EXEC (Executable file) Machine: Advanced Micro Devices X86-64 Version: 0x1 Entry point address: 0x555555559190 # 关键:程序入口 Start of program headers: 64 (bytes into file) Start of section headers: 158736 (bytes into file) Flags: 0x0 Size of this header: 64 (bytes) Size of program headers: 56 (bytes) Number of program headers: 11 Size of section headers: 64 (bytes) Number of section headers: 35 Section header string table index: 34
对比C语言生成的ELF文件头,大部分字段完全一致,但有几个细节需要重点关注(也是Rust与C在ELF层面的细微差异):
Magic魔数:7f 45 4c 46,对应的ASCII码就是\x7FELF,这是ELF文件的唯一标识——无论是C还是Rust生成的ELF,魔数都完全相同,内核正是通过这4个字节,快速判断一个文件是不是ELF格式,相当于文件的“身份证号”。
Entry point address(程序入口地址):这里是0x555555559190,和C语言一样,这个地址并不是我们写的fn main()函数的地址,而是程序真正的入口(_start函数)地址。不同的是,Rust的_start函数由Rust运行时(Runtime)提供,而非C语言中的glibc库。
Number of section headers(节头表数量):Rust生成的ELF文件节头表数量(35个)通常比C语言多,这是因为Rust会生成一些额外的节区,用于存储Rust特有的信息,比如.rustc_metadata(Rust元数据)、.eh_frame(异常处理帧)等。
其中最关键的两个字段,和C语言一致:
1.2 程序头表与Segment
在讲解程序头表之前,我们先区分下这2个概念:Segment(段) 和 Section(节),很多人会把这他俩混为一谈:
Section(节)是链接器视角的最小单元,编译器把代码、数据、字符串等不同内容,分门别类放到不同的节里,比如代码放.text、初始化全局变量放.data、未初始化全局变量放.bss、字符串常量放.rodata。链接器在链接过程中,需要处理各个节的重定位、符号解析等工作。
Segment(段)是内核加载视角的单元,内核根本不关心每个节的具体用途,它只关心这块内容加载到内存后,应该有什么权限(可读/可写/可执行)。所以内核会把权限相同的多个节,打包成一个Segment,一次性映射到内存,既减少内存碎片,又提升加载效率。
简单来说:Section是给链接器看的,Segment是给内核加载器看的,一个Segment对应一个或多个Section。
而程序头表(Program Header Table),就是所有Segment的描述信息集合,相当于内核加载ELF文件的“导航图”,告诉内核每个Segment要映射到内存的哪个位置、有多大、什么权限。
操作系统在启动程序时,并不关心代码具体是哪个函数,它只关心:“这块内存要不要加载到物理内存?”“这块内存能不能被执行?”。
因此,ELF文件中将具有相同权限(如可读、可执行)的节区(Sections)打包成一个个“段”(Segment)。程序头表就是这些段的目录。
使用readelf -l可以查看:
# readelf -l hello_rustProgram Headers: Type Offset VirtAddr PhysAddr FileSiz MemSiz Flags Align PHDR 0x0000000000000040 0x0000555555555040 0x0000555555555040 0x0000000000000268 0x0000000000000268 R 0x8 INTERP 0x00000000000002a8 0x00005555555552a8 0x00005555555552a8 0x000000000000001c 0x000000000000001c R 0x1 [Requesting program interpreter: /lib64/ld-linux-x86-64.so.2] LOAD 0x0000000000000000 0x0000555555555000 0x0000555555555000 0x000000000000bde0 0x000000000000bde0 R E 0x1000 LOAD 0x000000000000c000 0x0000555555562000 0x0000555555562000 0x00000000000011d8 0x00000000000011d8 RW 0x1000 DYNAMIC 0x000000000000c8f8 0x00005555555628f8 0x00005555555628f8 0x00000000000001f0 0x00000000000001f0 RW 0x8 NOTE 0x00000000000002c4 0x00005555555552c4 0x00005555555552c4 0x0000000000000044 0x0000000000000044 R 0x4 GNU_EH_FRAME 0x000000000000b8f8 0x00005555555608f8 0x00005555555608f8 0x00000000000004e8 0x00000000000004e8 R 0x4 GNU_STACK 0x0000000000000000 0x0000000000000000 0x0000000000000000 0x0000000000000000 0x0000000000000000 RW 0x10 GNU_RELRO 0x000000000000c000 0x0000555555562000 0x0000555555562000 0x00000000000008f8 0x00000000000008f8 R 0x1
这里有几个关键的Segment类型:
LOAD:表示这个段需要被加载到内存中,是最核心的Segment类型。标志位R E表示这块内存是可读且可执行的(通常存放代码,包括Rust的.text节和.eh_frame节);另一块RW表示可读写(通常存放数据,包括Rust的.data、.bss节)。Rust的安全特性在这里也有体现——代码段只有可读可执行权限,没有写权限,防止恶意代码篡改程序指令;数据段只有可读可写权限,没有执行权限,防止缓冲区溢出攻击,这和C语言的安全设计逻辑一致,但Rust在编译期会进一步强化这种安全限制。
INTERP:这是一个非常特殊的段,和C语言完全一致。它告诉内核:“嘿,别直接运行这个文件,先去把/lib64/ld-linux-x86-64.so.2(动态链接器)加载进来,让它来处理后续的事情。”——这意味着Rust程序默认也是动态链接的,依赖系统的动态链接器和相关共享库。
DYNAMIC:动态链接所需的信息,存放了动态符号表、重定位表等的位置,供动态链接器使用。Rust程序依赖的libstd(Rust标准库)、libc(C标准库)等共享库,都会通过这个段的信息被动态链接器解析和加载。
GNU_STACK:指定栈的权限,这里是RW(可读可写),没有可执行权限——这是Linux的安全防护机制,Rust程序也会继承这一机制,防止栈上的代码被执行,进一步提升程序安全性。
Rust程序(以及大多数现代C/C++程序)并不是完全独立的,它们依赖动态链接库——和C语言依赖glibc不同,Rust程序默认依赖两个核心共享库:一是Rust的标准库(libstd.so),二是系统的C标准库(libc.so)。这是因为Rust的很多底层操作(比如println!最终会调用系统调用write),都会通过libc间接实现,而libstd则提供了Rust的核心语法和功能支持。
当内核看到INTERP段时,它会暂停当前的加载流程,转而去加载动态链接器(ld-linux.so)。这个链接器才是真正的“幕后操盘手”,它的核心任务和C语言中的动态链接器一致,但会额外处理Rust特有的符号和依赖,具体分为三步:
2.1. 依赖
动态链接器会首先读取可执行文件的.dynamic节区,这个节区中存储了程序所有的动态依赖信息。对于我们的hello_rust程序,依赖的共享库主要包括:
libstd-xxxx.so:Rust标准库,提供println!、内存分配、线程管理等核心功能;
libc.so.6:C标准库,提供系统调用封装、字符串处理等底层功能;
libpthread.so.0:线程库,用于Rust的线程相关操作(即使程序中没有显式使用线程,libstd也会依赖它);
ld-linux-x86-64.so.2:动态链接器本身,也是程序的依赖之一。
我们可以使用ldd命令查看Rust程序的具体依赖:
# ldd hello_rust linux-vdso.so.1 (0x00007fffxxxxxxx) libstd-xxxx.so => /usr/lib64/rustlib/x86_64-unknown-linux-gnu/lib/libstd-xxxx.so (0x00007ffff7xxxxxx) libc.so.6 => /lib64/libc.so.6 (0x00007ffff7xxxxxx) libpthread.so.0 => /lib64/libpthread.so.0 (0x00007ffff7xxxxxx) /lib64/ld-linux-x86-64.so.2 (0x00007ffff7xxxxxx)
可以看到,Rust程序比C语言的“Hello World”多了一个核心依赖——libstd,这是Rust程序能够正常运行的基础;而C语言程序的核心依赖只有libc。
2.2 加载库
动态链接器解析完所有依赖后,会按照和加载主程序相同的逻辑,将每个共享库(.so文件)也映射到当前进程的虚拟内存空间中。这里的映射机制和C语言完全一致:通过mmap系统调用,建立共享库文件与虚拟内存的关联,此时并不会将共享库的全部内容加载到物理内存,而是采用“请求调页”机制——只有当程序执行到需要共享库中的代码或数据时,才会触发缺页中断,内核再将对应的内容加载到物理内存。
这里有一个关键细节:Rust的libstd本身也是一个ELF格式的动态链接库,它的结构和我们的主程序完全一致,也包含ELF文件头、程序头表、节区等内容。动态链接器加载libstd时,会按照同样的流程解析它的程序头表,映射对应的Segment,初始化它的BSS段和堆区。
2.3 重定位(Relocation)
这是动态链接器最核心的工作,也是解决“undefined reference”错误的关键——无论是C还是Rust,编译期间,编译器并不知道共享库中函数的真实地址(因为共享库是独立编译的,地址是相对的),所以会在代码中留下一些“占位符”(重定位条目)。动态链接器的任务,就是将这些“占位符”替换成共享库加载到内存后的真实地址。
对于Rust程序来说,重定位过程有一个独特的点:Rust的函数名会经过“名字修饰”(Name Mangling)——因为Rust支持函数重载、泛型、 trait 等特性,需要通过名字修饰来区分不同的函数。比如,我们写的fn main(),经过名字修饰后,会变成类似_ZN4main20hxxxxxxxxx17hxxxxxxxxxE的形式。动态链接器在重定位时,需要识别这些经过修饰的符号,将其与共享库中的符号对应起来。
举个例子:我们的println!("Hello, Rustacean!"),最终会调用libstd中的std::io::stdio::println函数,而这个函数又会调用libc中的write系统调用。编译期间,println!的调用地址是一个占位符;动态链接器加载完libstd和libc后,会找到println函数和write函数的真实内存地址,替换掉代码中的占位符。
只有当动态链接器完成了这些繁琐的工作,并初始化好了Rust运行时环境(比如内存分配器、线程环境)后,它才会把控制权交还给我们的Rust程序。这也是为什么“本地跑的好好的代码,放到服务器上就报undefined reference”——本质上是服务器上缺少了Rust程序依赖的共享库(比如libstd或特定版本的libc),动态链接器无法完成重定位,导致程序无法启动。
execve系统调用。它的作用,就是把我们的可执行文件,加载到子进程的地址空间中,替换掉原来的shell程序的内容,然后跳转到程序入口执行。
通常,shell是这样工作的:
fork():复制一个全新的子进程(此时子进程和父shell长得一模一样)。
execve():在这个子进程中执行我们的hello_rust文件。
// 简化版shell核心逻辑(Rust实现)use std::process::{fork, execvp};use std::env;fn main() { let args: Vec<String> = env::args().collect(); if args.len() < 2 { eprintln!("请输入要执行的程序路径"); return; } // fork创建子进程 match fork() { Ok(Some(child_pid)) => { // 父进程(shell):等待子进程执行结束 waitpid(child_pid, None).unwrap(); } Ok(None) => { // 子进程:加载并执行hello_rust程序 let program = &args[1]; let argv: Vec<&str> = args.iter().map(|s| s.as_str()).collect(); execvp(program, &argv).unwrap(); } Err(e) => { eprintln!("fork失败: {}", e); } }}
execve系统调用进入内核后,大致会经历以下几个阶段:
1). 准备阶段
内核会为新进程准备一个新的mm_struct结构体,用来描述这个进程的虚拟内存空间——这是进程地址空间的“总管家”,记录了进程的代码段、数据段、堆、栈等所有虚拟内存区域的信息。同时,内核会为进程的用户态栈分配一页内存(通常是4KB),并把程序的参数(argv,比如./hello_rust)和环境变量(envp,比如系统的PATH、HOME等)拷贝到栈底。
这里有一个关键优化:和C语言一样,fork创建子进程时,采用“写时复制(Copy-On-Write, COW)”机制——子进程并不会复制父进程(shell)的全部物理内存,只是复制父进程的页表,并且把页表的权限设置为只读。只有当父进程或子进程尝试修改某一块内存时,才会触发缺页中断,内核才会把这块内存复制一份,让父子进程各自拥有独立的副本。这一机制极大地提升了fork的效率,避免了大量无用的内存拷贝。
而execve的核心作用之一,就是“替换”子进程的地址空间——子进程原本共享父进程的地址空间(写时复制),execve会清空这个旧的地址空间,为Rust程序创建一个全新的地址空间,用于加载Rust程序的ELF文件。
2). 读取文件头
内核会打开我们指定的hello_rust文件,读取文件的前128个字节(这是ELF文件头的最大长度,足够包含魔数、文件类型、架构等核心识别信息),确认这是一个合法的ELF文件。然后,内核会从这128个字节中读取ELF文件头的核心字段,找到程序头表的位置(Start of program headers),为后续的Segment映射做准备。
如果读取到的魔数不是7f 45 4c 46,或者文件类型不是可执行文件(EXEC),或者架构不匹配(比如32位ELF文件运行在64位系统上),内核会直接返回错误,程序无法启动——这就是为什么有些Windows下的可执行文件(.exe),在Linux上无法运行的原因(格式不匹配)。
3). 布局内存(mmap映射)
内核会遍历程序头表,对于每一个PT_LOAD类型的Segment,它会调用elf_map函数(本质上是封装了mmap系统调用),在进程的虚拟内存空间中预留一段区域,并建立虚拟地址到物理磁盘文件的映射。
这里有一个非常关键的知识点:和C语言一样,mmap映射只是建立虚拟地址和文件的关联,并不会把文件内容读取到物理内存中。只有当程序执行时,访问到某一块虚拟地址,发现对应的物理内存不存在,才会触发缺页中断,内核才会把对应的文件内容读取到物理内存中,这就是请求调页机制。
这也是为什么一个几百MB的大Rust程序,启动速度依然很快的原因:内核不会把整个程序都读到内存里,只会在用到的时候,才加载对应的页。对于Rust程序来说,libstd虽然体积不小,但启动时只会加载其中最核心的部分(比如println!相关的代码),其余部分会在后续执行时按需加载。
4). 设置入口(跳转准备)
内核从ELF文件头中取出e_entry字段(程序入口地址),然后调用start_thread函数,将这个入口地址设置到进程的寄存器上下文(x86-64架构下,是指令指针寄存器RIP)中。同时,内核会将栈指针寄存器(RSP)设置为用户栈的指针,确保程序启动时,栈能正常使用。
需要注意的是:这个入口地址,对于动态链接的Rust程序来说,并不是_start函数的地址,而是动态链接器的入口地址——因为动态链接器需要先完成依赖加载和重定位,再把控制权交给Rust程序的_start函数。只有静态链接的Rust程序(使用cargo build --static编译),入口地址才是_start函数的地址。
5). 执行(缺页中断与程序启动)
当execve系统调用执行完成后,内核会从内核态返回到用户态,CPU开始执行新进程——此时,CPU会从RIP寄存器指向的入口地址开始执行(动态链接器的入口)。
由于动态链接器还没有被加载到物理内存(只是建立了虚拟内存映射),CPU访问动态链接器的入口地址时,会触发第一次缺页中断。内核介入,将动态链接器的对应代码加载到物理内存,然后恢复执行。动态链接器完成依赖加载、重定位后,会跳转到Rust程序的_start函数,此时又会触发一次缺页中断(_start函数的代码还没加载到物理内存),内核加载对应的代码,程序继续执行。
当控制权真正交接到我们的程序时,最先运行的并不是fn main(),而是一段由编译器生成的启动代码(Startup Code),通常标记为_start。
对于C语言程序,_start函数由glibc提供,主要负责初始化libc、设置全局变量、注册进程退出函数,然后调用main函数;而对于Rust程序,_start函数由Rust运行时(libstd)提供,它的核心任务是初始化Rust的运行时环境,然后再调用main函数。具体来说,Rust的_start函数主要做了以下几件事:
4.1 初始化Rust运行时(Runtime)
这是Rust与C语言最核心的差异之一。Rust的运行时包含了很多核心组件,必须在main函数执行前完成初始化:
内存分配器初始化:Rust的默认内存分配器是jemalloc(或系统默认分配器),_start会初始化这个分配器,确保Box、Vec等动态内存分配类型能正常使用。
线程环境初始化:Rust的线程模型依赖系统线程,_start会初始化线程调度器,设置主线程的属性,确保后续的线程操作(即使程序中没有显式使用线程)能正常进行。
异常处理机制初始化:Rust的panic!机制需要依赖异常处理帧(.eh_frame节),_start会初始化异常处理框架,确保程序发生panic时,能正确打印错误信息、释放资源,而不是直接崩溃。
全局变量初始化:初始化Rust程序中的全局变量(包括static变量和const变量),确保它们在main函数执行前就有正确的值。
而C语言的_start函数,只需要初始化libc的基础环境,不需要处理这些Rust特有的组件——这也是Rust程序的启动流程比C语言更复杂的原因之一。
4.2 调用初始化函数
和C语言一样,Rust程序的ELF文件中也有.init_array节区,这个节区中注册了一些需要在main函数执行前调用的初始化函数。_start函数会遍历这个节区,依次调用这些初始化函数,完成一些额外的初始化工作(比如第三方库的初始化)。
4.3 调用main函数
当所有初始化工作完成后,_start函数会调用我们熟悉的fn main()函数——这才是我们写的Rust代码的入口。此时,Rust的运行时环境已经完全初始化,println!、Vec等功能都能正常使用。
在main函数执行完毕后,启动代码还会负责调用析构函数(比如Drop trait实现的析构逻辑)、释放内存分配器资源,并通过exit系统调用通知操作系统:“我跑完了,请回收我的尸体(进程资源)”。这一点和C语言类似,但Rust的析构机制更严谨——即使程序发生panic,析构函数也会被调用,确保资源不会泄漏,这是Rust内存安全特性的重要体现。
我们可以通过nm命令查看Rust程序的符号表,找到_start和main函数的地址,验证它们的先后顺序(和C语言一致):
# nm -n hello_rust | grep -E "_start|main"0000555555559190 T _start00005555555591c0 T _ZN4main20hxxxxxxxxx17hxxxxxxxxxE # 经过名字修饰的main函数
可以清晰地看到:_start函数的地址(0x555555559190)和ELF文件头中的入口地址完全一致,而main函数的地址(0x5555555591c0)在_start之后——这证明了_start确实是程序的真正入口,main函数是被_start调用的。
总结
我们把整个流程从头到尾串一遍,完整复盘从一行Rust代码到程序运行的全链路:
代码编写:我们在编辑器中写好Rust代码(main.rs),定义fn main()函数和println!宏。
编译链接:执行cargo build --release,Cargo会自动调用rustc(编译器)和ld(链接器),经过预处理、编译、汇编、链接四个步骤,生成ELF格式的可执行文件。这一步中,rustc会生成Rust特有的节区(如.rustc_metadata),ld会将Rust的目标文件和libstd、libc等共享库链接起来,生成最终的可执行文件。
shell执行命令:我们在终端输入./target/release/hello_rust,shell进程调用fork系统调用,创建一个子进程(通过写时复制共享父进程的地址空间)。
子进程调用execve:子进程被调度执行后,调用execve系统调用,开始加载hello_rust可执行文件。
execve初始化上下文:内核申请linux_binprm结构体(加载上下文),初始化全新的mm_struct地址空间和用户栈,读取可执行文件的前128字节(ELF文件头),拷贝参数和环境变量到用户栈。
查找匹配的加载器:内核遍历formats全局加载器链表(Linux的插件化加载器框架),调用ELF加载器的load_elf_binary函数,开始加载ELF文件。
ELF文件加载:内核校验ELF文件头合法性,读取程序头表,解析INTERP段找到动态链接器,清空旧进程资源,把LOAD类型的Segment映射到虚拟地址空间,初始化BSS段和堆区,加载动态链接器。
动态链接器工作:动态链接器解析Rust程序的依赖(libstd、libc等),加载这些共享库,完成符号重定位(修正println!等函数的地址),初始化Rust运行时环境。
跳转到用户态执行:内核设置CPU寄存器(RIP指向动态链接器入口),从系统调用返回到用户态,触发缺页中断加载动态链接器代码;动态链接器完成工作后,跳转到_start函数,再次触发缺页中断加载_start代码;_start函数初始化Rust运行时,调用main函数。
程序运行与输出:main函数调用println!,println!宏经过编译展开,最终调用libc的write系统调用,将字符串写入到标准输出,终端驱动把字符串打印到屏幕上,我们就看到了“Hello, Rustacean!”。
程序退出:main函数执行完毕,_start函数调用析构函数、释放资源,通过exit系统调用通知内核回收进程资源,进程终止。
虽然过程复杂,但Linux通过虚拟内存和按需分页(Demand Paging)机制,保证了程序启动的高效性——只有真正用到的代码才会被加载到内存;而Rust则通过严谨的编译检查、内存安全机制、运行时初始化,保证了程序的安全性和稳定性,这也是Rust很少出现Segmentation fault(段错误)的原因之一(段错误通常是内存越界、空指针访问等问题导致,而Rust在编译期就会阻止这些问题)。
最后,和C语言一样,你可以通过/proc文件系统来观察正在运行的Rust进程的内存布局,验证我们上面讲到的一切:
# 先运行hello_rust,让它暂停(比如在main函数中加入std::io::stdin().read_line(&mut s).unwrap();)# 查看进程PIDps aux | grep hello_rust# 假设PID是1234,查看内存布局cat /proc/1234/maps
运行结果会清晰地显示,Rust进程的虚拟地址空间中,包含以下几个核心部分(和C语言进程的布局类似,但多了libstd的映射):